摘要
深度学习工具在应用机器学习领域受到了极大的关注。然而,这些用于回归和分类的工具并没有捕捉到模型的不确定性。相比之下,贝叶斯模型提供了一个基于数学的框架来推理模型的不确定性,但通常会带来令人望而却步的计算成本。本文提出了一种新的理论框架,将深度神经网络中的dropout训练作为深度高斯过程中的近似贝叶斯推理。该理论的一个直接结果是为我们提供了用dropout神经网络来模拟不确定性的工具——从现有的模型中提取信息,这些信息到目前为止已经被抛弃了。这在不牺牲计算复杂性或测试准确性的情况下减轻了深度学习中表示不确定性的问题。我们对dropout不确定性的性质进行了广泛的研究。以MNIST为例,对回归和分类任务的各种网络结构和非线性进行了评估。与现有的最先进的方法相比,我们在预测对数似然和RMSE方面取得了相当大的进步,并通过消除深度强化学习中dropout的不确定性来完成。
论文:
Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning
作者:Yarin Gal Yarin Gal
单位:University of Cambridge
摘要
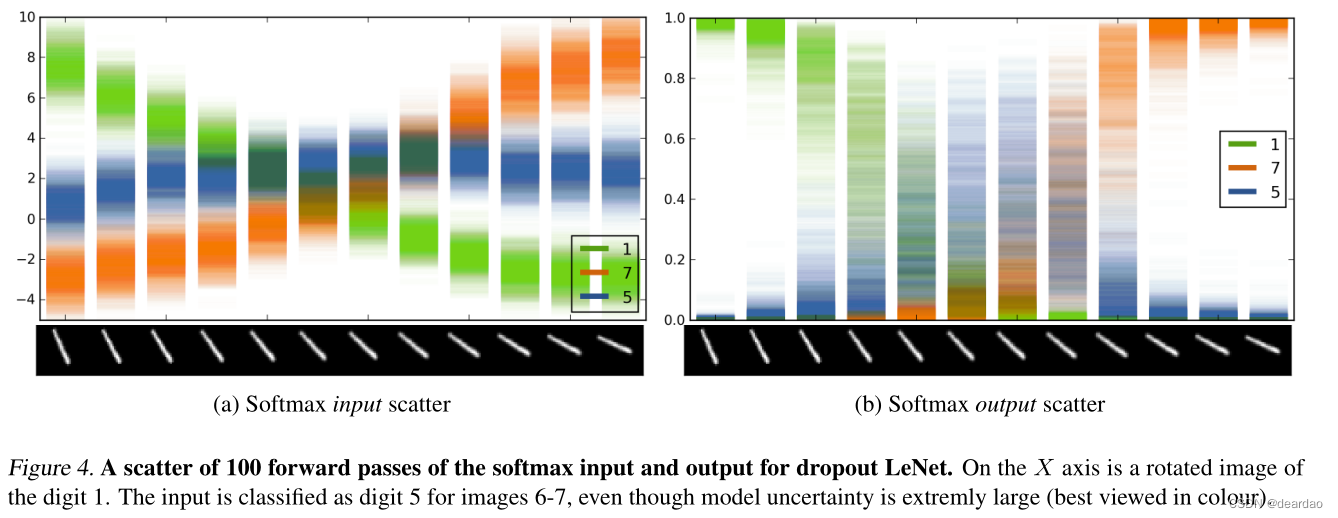
用于回归和分类的标准深度学习工具不能捕捉模型的不确定性。在分类中,在网络末端获得的预测概率(softmax输出)经常被错误地解释为模型置信度。即使具有很高的softmax输出,模型的预测也可能是不确定的。1).通过softmax(实线1b)传递函数的点估计(实线1a)会导致对远离训练数据的点进行不合理的高置信度外推。例如,X 将被分类为概率为1的第1类。然而,通过softmax(阴影区域1b)传递分布(阴影区域1a)可以更好地反映远离训练数据的分类不确定性。
模型不确定性对于深度学习从业者来说也是必不可少的。有了模型置信度,我们可以明确地处理不确定输入和特殊情况。例如,在分类的情况下,模型可能返回一个具有高度不确定性的结果。在这种情况下,我们可能决定将输入传递给人工进行分类。这可能发生在邮局,根据邮政编码分拣信件,或在核电厂的系统负责关键基础设施(琳达等人,2009)。不确定性在强化学习(RL)中也很重要(Szepesvari´,2010)。有了不确定性信息,智能体可以决定何时开发和何时探索其环境。RL的最新进展是利用神经网络进行q值函数逼近。这些函数用来估计代理可以采取的不同行动的质量。贪心搜索通常用于智能体以一定概率选择其最佳行为,并以其他方式进行探索。通过对智能体q值函数的不确定性估计,可以使用诸如汤普森抽样(Thompson - son, 1933)之类的技术来更快地学习。
贝叶斯概率论为我们提供了基于数学的工具来推断模型的不确定性,但这些通常伴随着令人望而却步的计算成本。我们表明,在神经网络中使用dropout(及其变体)可以被解释为一个众所周知的概率模型的贝叶斯近似:高斯过程(GP) (Rasmussen & Williams, 2006)。深度学习中的许多模型都使用Dropout来避免过拟合(Srivastava et al., 2014),我们的解释表明Dropout近似地集成了模型的权重。我们开发了工具来表示现有的dropout神经网络的模型不确定性-提取迄今为止被丢弃的信息。这在不牺牲计算复杂性和测试精度的情况下,减轻了深度学习中表示模型不确定性的问题。
在本文中,我们给出了一个完整的理论处理高斯过程和dropout之间的联系,并开发了必要的工具来表示深度学习中的不确定性。我们对dropout神经网络和convnets在回归和分类任务上获得的不确定性的性质进行了广泛的探索性评估。我们比较了不同模型结构和非线性回归中得到的不确定性,并以MNIST为具体例子说明了模型不确定性对于分类任务是必不可少的。然后,与现有的最先进的方法相比,我们展示了预测对数似然和RMSE的相当大的改进。最后,我们在一个类似于深度强化学习的实际任务中,对强化学习环境下的模型不确定性进行了定量评估。
作为贝叶斯近似的Dropout
我们表明,具有任意深度和非线性的神经网络,在每个权重层之前应用dropout,在数学上相当于概率深度高斯过程的近似值(Damianou & Lawrence, 2013)(在其协方差函数参数上被边缘化)。我们要强调的是,在文献中没有对dropout的使用进行简化假设,并且推导出的结果适用于任何使用dropout的网络架构,正如它在实际应用中出现的那样。此外,我们的研究结果也适用于其他类型的dropout。我们表明,dropout目标实际上最小化了近似分布和深度高斯过程的后验之间的Kullback-Leibler散度(在其有限秩协方差函数参数上被边缘化)。由于篇幅限制,我们请读者参阅附录,以深入回顾dropout、高斯过程和变分推理(第2节),以及dropout及其变化的主要推导(第3节)。这里总结了结果,下一节我们将获得dropout神经网络的不确定性估计。
让y为具有L层和损失函数E(·,·)的NN模型的输出,如softmax损失或欧几里得损失(平方损失)。我们用W_i表示神经网络的权重矩阵Ki × Ki-1,通过bi得到每一层i =1的Ki维偏置向量,…, l .对于1≤i≤N个数据点,我们用yi表示观察到的输出对应于输入xi,输入和输出集为X, y .在NN优化过程中经常添加正则化项。我们经常使用由一些权重衰减λ加权的L2正则化,从而产生最小化目标(通常称为成本),
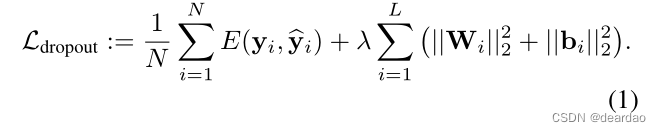
对于dropout,我们对每个输入点和每层(除了最后一层)的每个网络单元的二进制变量进行采样。对于第1层,每个二进制变量的取值为1,概率为pi。对于给定的输入,如果对应的二进制变量的取值为0,则丢弃一个单位(即其值设置为0)。我们在反向传递中使用相同的值将导数传播到参数。
与非概率神经网络相比,深度高斯过程是统计学中一个强大的工具,它允许我们对函数上的分布进行建模。假设我们有这样的协方差函数
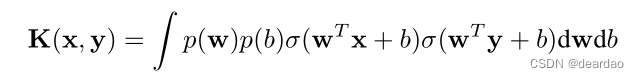
具有一些单元非线性σ(·)和分布p(w),p(b)。
在附录的第3节和第4节中,**我们展示了具有L层和协方差函数K(x, y)的深度高斯过程可以通过在gp协方差函数的谱分解的每个分量上放置变分分布来近似。**这种光谱分解将深度GP的每一层映射到显式表示的隐藏单元层,下面将简要解释。
让每一行Wi按照上面的p(w)分布。假设每个GP层的维数为Ki的向量mi。当精度参数τ> 0时,深度GP模型(有限秩协方差函数参数ω)的预测概率可参数化为
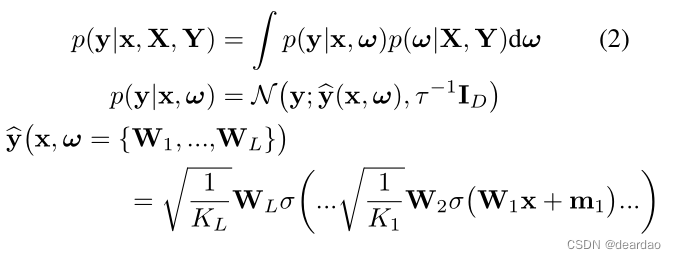
方程(2)中的后验分布p(ω|X, Y)是不可处理的。我们使用q(ω),一个列随机设为零的矩阵上的分布,来近似可处理后验。我们定义q(ω)为:
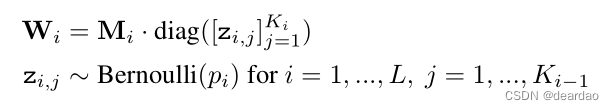
给出一些概率pi和矩阵Mi作为变分参数。二进制变量z_i,j =0对应于第i层的单位j 变分分布q(ω)是高度多模态的,在矩阵Wi的行(对应于稀疏频谱GP近似中的频率)上引起强联合相关性。
我们最小化上面的近似后验q(ω)和全深度GP的后验p(ω|X, Y)之间的KL散度。这个KL是我们的最小化目标
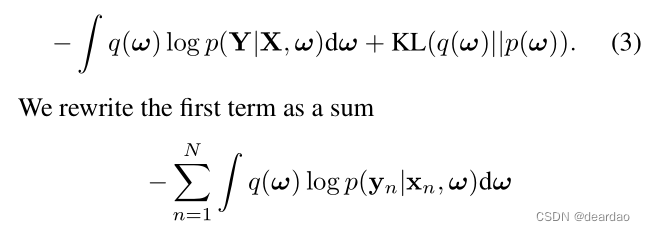
用蒙特卡罗单样本积分法近似求和中的每一项N ~ q(ω)得到一个无偏估计。
给定模型精度τ,我们将结果按常数1/τ N缩放以获得目标
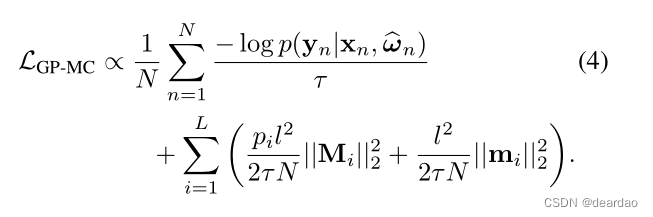
对于精度超参数τ和长度尺度L的适当设置,我们恢复了eq.(1)。n的结果实现了伯努利分布
z
i
,
j
n
z^n_{i,j}
zi,jn等价于dropout情况下的二进制变量。
获取模型不确定性
在此基础上,我们得到了模型不确定性可以从dropout神经网络模型中得到的结果。根据附录2.3节,我们的近似预测分布由式给出
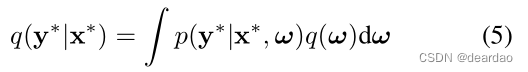
我们将进行矩匹配,并根据经验估计预测分布的前两个矩。更具体地说,我们从伯努利分布中抽取了T组实现向量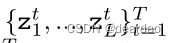
我们估计

在附录中的C项之后。我们把这个蒙特卡罗估计称为MC dropout。在实践中,这相当于在网络中执行T次随机正向传递并平均结果。
这一结果已在以前的文献中作为模型平均提出。对于这个结果,我们给出了一个新的推导,它也允许我们推导出基于数学的不确定性估计。Srivastava等人(2014,第7.5节)通过经验推导得出,MC dropout可以通过平均网络的权重来近似(在测试时将每个Wi乘以pi,称为标准dropout)。
我们用同样的方法来估计第二个原始矩:
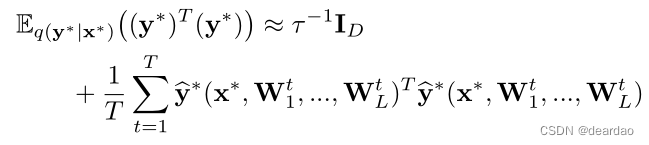
为了得到模型的预测方差,我们有:
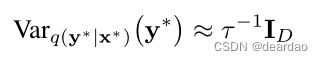
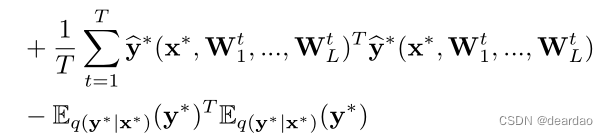
它等于T的样本方差随机正向通过神经网络加上逆模型精度。
注意y *是一个行向量,因此和是外积的和。给定权重衰减λ(和我们的先验长度尺度l),我们可以从恒等式中找到模型精度
我们可以通过eq.(2)的蒙特卡罗积分来估计我们的预测对数似然。这是对模型拟合平均值和不确定性的程度的估计(参见附录中的4.4节)。对于回归,这是由:
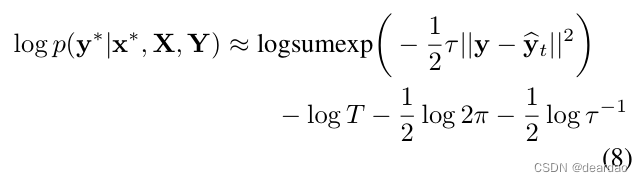
我们的预测分布q(y∗|x∗)预计是高度多模态的,上面的近似只是对其性质的一瞥。这是因为每个权重矩阵列上的近似变分分布是双峰的,因此每层权重的联合分布是多峰的附录3.2)。
注意dropout NN模型本身没有改变。为了估计预测均值和预测不确定性,我们简单地收集随机正演通过模型的结果。因此,该信息可以用于使用dropout训练的现有NN模型。此外,前向传递可以同时进行,从而使其恒定的运行时间与标准dropout相同。
实验
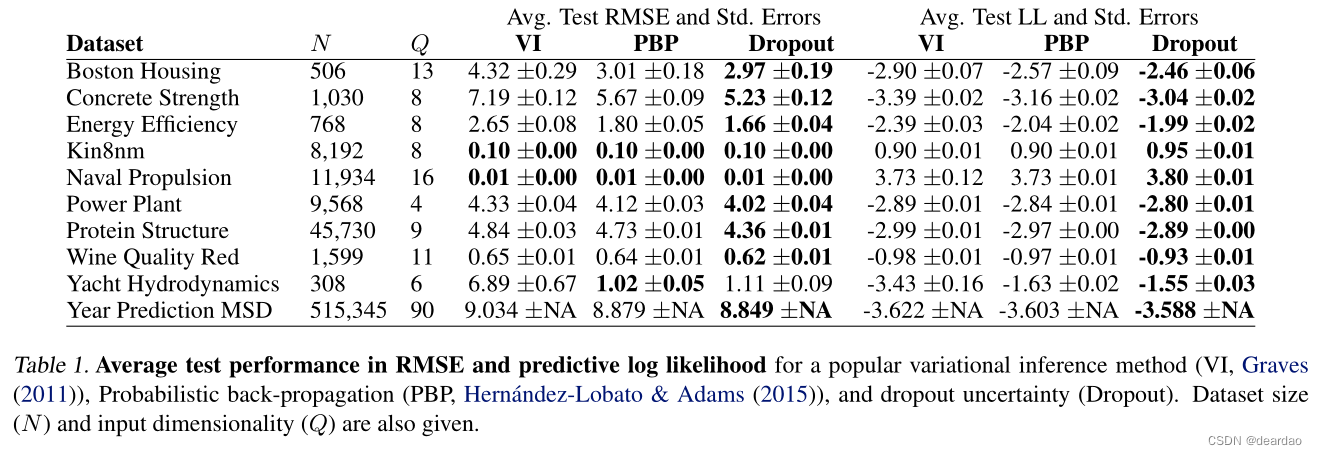
接下来,我们对dropout神经网络和convnets在回归和分类任务上获得的不确定性估计的性质进行了广泛的评估。我们比较了从不同模型架构和非线性中获得的不确定性,都是在额外的任务上,并以MNIST (LeCun & Cortes, 1998)为例表明模型不确定性对分类任务很重要。然后,我们表明,与现有的最先进的方法相比,使用dropout的不确定性,我们可以在预测对数似然和RMSE方面获得相当大的改进。
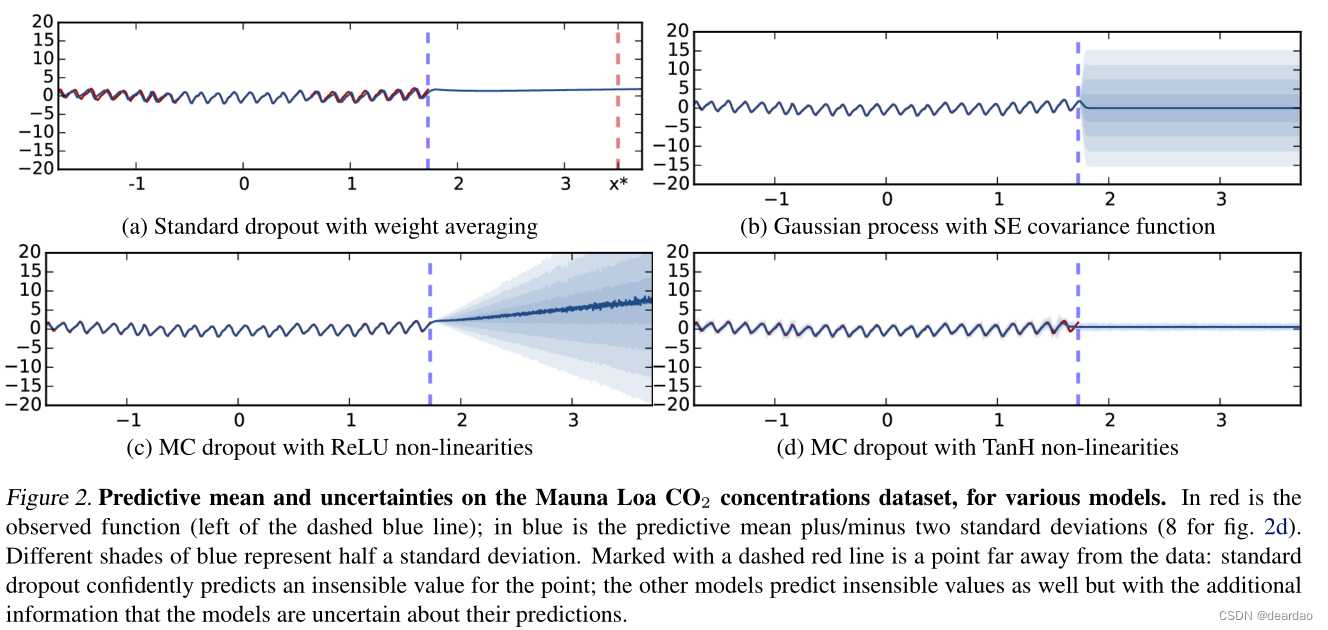
莫纳罗亚火山不同模式二氧化碳浓度数据集的预测平均值和不确定性。红色是观察到的函数(蓝色虚线的左边);蓝色是预测平均值±两个标准差(图8)。2 d)。不同深浅的蓝色代表半个标准差。用红色虚线标记的是远离数据的点:标准dropout自信地预测了该点的一个不合理的值;其他模型也预测了不敏感的值,但附加了模型对其预测不确定的信息。