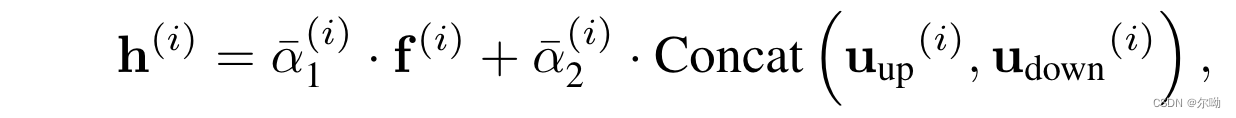
案例目的
寻找一个良好的函数表达式,该函数表达式能够很好的描述上面数据点的分布,即对上面数据点进行拟合。
求解逻辑步骤
- 使用Sklearn生成数据集
- 定义线性模型
- 定义损失函数
- 定义优化器
- 定义模型训练方法(正向传播、计算损失、反向传播、梯度清空)
- 模型训练
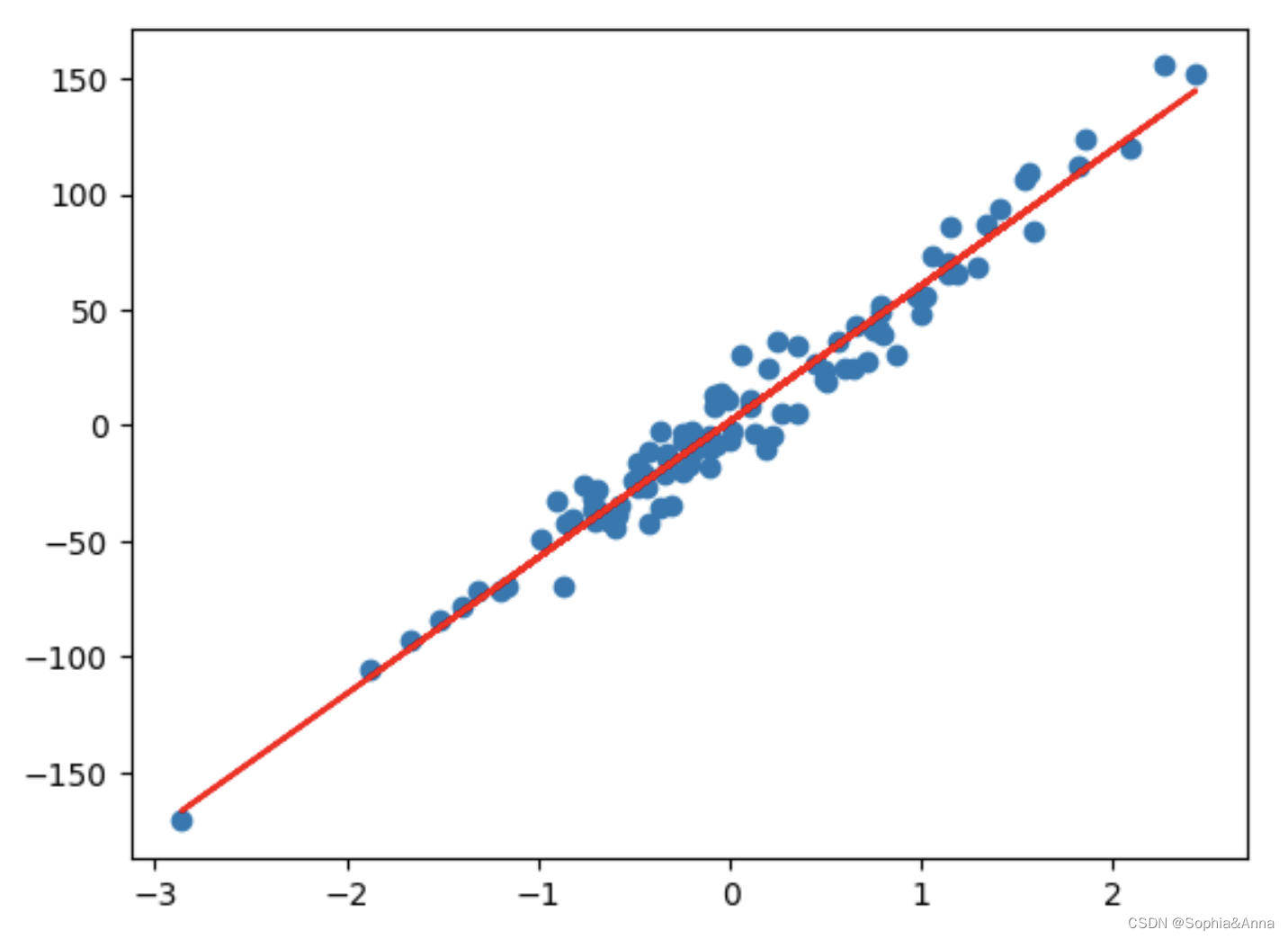
- 模型预测与线性关系展示
代码实现
import numpy as np
from sklearn import datasets
import matplotlib.pyplot as plt
import torch
# 生成数据集 n_samples-样本数量,n_features-自变量数量,random_state-随机种子,noise-噪声
data = datasets.make_regression(n_samples=100,n_features=1,random_state=5,noise=10)
X,Y = data
# 数据集转换成张量
X = torch.from_numpy(X.astype(np.float32))
Y = torch.from_numpy(Y.astype(np.float32))
# 行列形状要相同
Y = Y.view(100,1)
# 线性模型函数的定义
n_samples,n_features = X.size()
model = torch.nn.Linear(n_features,1)
# 定义损失函数
loss = torch.nn.MSELoss()
# 定义优化器
learn_rate = 0.01
optimizer = torch.optim.SGD(model.parameters(),lr=learn_rate)
# 实现梯度下降函数
def gradient_descent():
# 正向传播
pre_y = model(X)
# 计算损失
l = loss(pre_y,Y)
# 反向传播
l.backward()
# 梯度更新
optimizer.step()
# 梯度清空
optimizer.zero_grad()
return l,list(model.parameters())
# 模型训练
for i in range(500):
l,parameters = gradient_descent()
print(l,parameters)
# 模型预测
predect = model(X)
# X,Y线性拟合效果展示
plt.scatter(X,Y)
plt.plot(X,predect.detach().numpy(),color="r")