看到京东的一段开场白,觉得很有道理:
2023年,大语言模型以前所未有的速度和能力改变我们对智能系统的认知,成为技术圈最被热议的话题。但“百模大战”终将走向“落地为王”,如何将大语言模型的强大能力融入实际业务、产生业务价值成为致胜关键。
在零售场,大模型应用面临的核心挑战包括以下三点:
(1)模型缺乏零售领域的专业知识,建设业务专属大模型训练成本高
(2)模型内容生产伴有幻觉,而检索海量业务信息又缺乏有效技术,检索成本高
(3)在商家问答等多流程复杂业务场景下,模型缺乏自主规划能力,需要大量人工干预
为了应对上述三点挑战,九数算法中台推出了一整套大语言模型应用解决方案,一种融合基于ReAct框架的AI Agent、SFT(指令微调)与RAG(检索增强生成)技术的应用框架,不仅赋予大模型学习领域知识的能力,还显著提升了模型的自主决策和信息处理精确度,为业务人员高效落地大模型的微调、部署和应用提供了落地保障。
SFT(Supervised Fine-Tuning),高效微调
通用大模型虽然在处理通用知识方面表现出色,但缺乏针对零售垂直领域的知识理解。为此,需要引入经过人工标注的领域数据,对已完成预训练的通用大模型进行微调,从而得到具有该领域知识的零售垂域大模型。这个过程就是“有监督微调(Supervised Fine-Tuning)”,简称SFT。
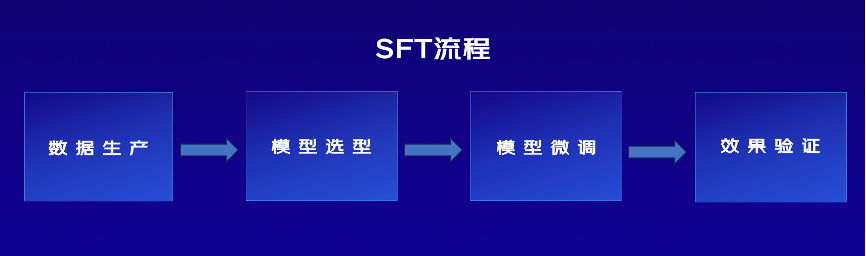
SFT流程介绍
SFT的流程包括数据生产、模型选型、模型微调、效果验证几个环节,每一步都存在相应的技术挑战:
(1)数据生产:创建用于微调预训练模型的高质量数据集,数据集质量对模型训练的效果至关重要。在零售场,沉淀了丰富的领域数据,比如电商营销策略、消费者行为数据、商品信息数据等,这些数据往往格式不统一、噪声多,如何以这些业务数据为基础,高效构建可用于微调训练的数据集,是数据生产环节的痛点。
(2)模型选型:根据对中文的支持程度、参数量级、性能等选择合适的预训练模型作为微调的起点。高速发展的开源社区为业务方提供了大量可供选择的预训练模型,但不同模型擅长不同任务,需要实验对比模型表现。而开源模型存在样本标注、模型标准不统一的问题,将开源方案应用在企业环境中也需要一定的适配工作量,给业务方带来了较高的模型选型成本。
(3)模型微调:使用准备好的数据集对选定的预训练模型进行微调。训练时需要设置适当的学习率、批次大小和训练周期等参数,同时监控模型的性能,如损失函数和准确率等指标。在算力资源紧缺的背景下,不少业务方面临算力资源不足的问题,如何用最小的算力资源实现最优的模型训练性能至关重要。
(4)效果验证:使用独立的验证数据集对模型进行测试,评估模型训练效果。关键是建立系统的模型评估指标,并选择合适的方法高效进行效果评估。
SFT流程介绍
模型微调:
①支持方法广:支持对LLM模型的预训练(Pretrain)和高效微调(SFT),微调方面支持全参微调(Full-Parameter Fine-Tuning)和LoRA等参数高效微调PEFT方法(Parameter-Efficient Fine-Tuning )。支持人类反馈强化学习RLHF训练(Reinforcement Learning from Human Feedback),支持PPO(Proximal Policy Optimization)、DPO(Direct Preference Optimization)等强化学习算法。
②训练性能高:通过编译优化、算子优化、网络和IO优化等方法,相比纯开源的代码性能提升40%左右;支持70B+超大规模模型微调;
③支持SFT模型蒸馏:建设模型知识蒸馏组件,在模型效果无损或损失较小的同时缩小模型规模,降低模型线上运行的成本,帮助业务方节约算力资源,未来可在端上使用。
(4)效果验证:支持高性能批量离线推理与客观+主观评估方式。通过手动融合kernel、triton编译优化、通信压缩等手段,提升批量离线推理性能。通过建立客观评估维度与用户自定义主观维度,实现生成效果验证。
目前,九数算法中台自研SFT框架已于京东(不得不打个广告,虽然我不喜欢博客中给人打广告,更何况不收费的广告,但从他们的文章上看,确实很不错)内部多个业务试点应用,实现SFT技术的低成本应用。
监督微调的特点
监督式微调能够利用预训练模型的参数和结构,避免从头开始训练模型,从而加速模型的训练过程,并且能够提高模型在目标任务上的表现。监督式微调在计算机视觉、自然语言处理等领域中得到了广泛应用。然而监督也存在一些缺点。首先,需要大量的标注数据用于目标任务的微调,如果标注数据不足,可能会导致微调后的模型表现不佳。其次,由于预训练模型的参数和结构对微调后的模型性能有很大影响,因此选择合适的预训练模型也很重要
SFT 监督微调的主流方法
随着技术的发展,涌现出越来越多的大语言模型,且模型参数越来越多,比如 GPT3 已经达到 1750 亿的参数量,传统的监督微调方法已经不再能适用现阶段的大语言模型。为了解决微调参数量太多的问题,同时也要保证微调效果,急需研发出参数高效的微调方法(Parameter Efficient Fine Tuning, PEFT)。目前,已经涌现出不少参数高效的微调方法,其中主流的方法包括:
- LoRA(学的东西多了,知识就串联起来了,LLM的第一篇)
- P-tuning v2
- Freeze
参考:
1.京东文章
2.SFT的主流方法详情介绍
3.这里是一个详细的例子








![buuctf[pwn]](https://img-blog.csdnimg.cn/img_convert/78d9bf23c6bbd690522e9eba59b26f93.png)