文章目录
- 源代码
- 项目简介
- 导入相关库
- __file_exists 装饰器
- 函数的签名和注释
- 主要功能的实现
- 运行演示
- 读取 Excel 文件
源代码
https://github.com/ma0513207162/PyPrecip。pyprecip\reading\read_api.py 路径下。
项目简介
PyPrecip 是一个专注于气候数据处理的 Python 库,旨在为用户提供方便、高效的气候数据处理和分析工具。该库致力于处理各种气候数据,并特别关注于降水数据的处理和分析。

导入相关库
在这里,读取 csv 和 excel 文件分别使用 csv 库和 openpyxl 库。utits 路径下是笔者自定义的一些工具函数,在源码中可以找到。
import os, csv
from openpyxl import load_workbook
from ..utits.except_ import RaiseException as exc
from ..utits.warn_ import RaiseWarn as warn
from ..utits.sundries import check_param_type
__file_exists 装饰器
一个简易的 python 装饰器 __file_exists,用于检测 path 参数有无正常输入,否则抛出自定义异常。
def __file_exists(func):
def wrapper(*args, **kwargs):
if not args and not kwargs:
exc.raise_exception("The file path is required.", TypeError)
return func(*args, **kwargs)
return wrapper
函数的签名和注释
- 以 read_csv 函数为示例,定义了一些必要的参数。
- by_row 参数表示是否按行读取数据。
- 其中 row_indices 和 column_indices 参数为 tuple 类型时,表示指定行索引或列索引。指定为 list 类型时,表示指定行范围或列范围。
- check_param_type 函数负责检查参数的类型。
@__file_exists
def read_csv(path: str, by_row: bool = False,
row_indices: (tuple|list) = (), column_indices: (tuple|list) = ()):
"""
Reads data for specified rows and columns from a CSV file.
Parameters:
- path: indicates the path of the CSV file
- row_indices: Specifies the read row range (list length 2) or row index (tuple)
- column_indices: specifies the read column range (list length 2) or column index (tuple)
- by_row: If True, read the file by rows (default). If False, read the file by columns.
Returns:
- Dictionary. The key indicates the file name and the value indicates the read data
"""
# 检查参数类型
check_param_type(path, str, "path");
check_param_type(row_indices, (tuple|list), "row_indices");
check_param_type(column_indices, (tuple|list), "column_indices");
主要功能的实现
根据传入的 row_indices 和 column_indices 参数搭配 zip 函数进行行列的转换, 使用切片和索引操作从原始 CSV 数据中提取指定的行列数据区域。这里最大的特点就是避免了使用大量的 for 循环进行同样功能的实现。
read_csv_result: dict = {};
with open(path, "r", encoding="gbk") as csv_file:
reader_csv = list(csv.reader(csv_file))
# 指定行范围
if isinstance(row_indices, list) and row_indices != []:
if len(row_indices) == 2:
start, end = row_indices[0], row_indices[1]
reader_csv = reader_csv[start-1: end]
else:
warn.raise_warning("The row_indices parameter must contain only two elements, otherwise it is invalid.")
# 指定行索引
if isinstance(row_indices, tuple) and row_indices != ():
row_idx_list = []
for idx in row_indices:
if idx >= 1 and idx <= len(reader_csv):
row_idx_list.append(reader_csv[idx-1])
else:
exc.raise_exception("The index must be greater than 0 and less than the sequence length.", IndexError)
reader_csv = row_idx_list;
# list 类型指定行范围
reader_csv = list(zip(*reader_csv))
if isinstance(column_indices, list) and column_indices != []:
if len(column_indices) == 2:
start, end = column_indices[0], column_indices[1];
reader_csv = reader_csv[start-1: end]
else:
warn.raise_warning("The column_indices parameter must contain only two elements, otherwise it is invalid.")
# tuple 类型指定列索引
if isinstance(column_indices, tuple) and column_indices != ():
col_idx_list = []
for idx in column_indices:
if idx >= 1 and idx <= len(reader_csv):
col_idx_list.append(reader_csv[idx-1]);
else:
exc.raise_exception("The index must be greater than 0 and less than the sequence length.", IndexError)
reader_csv = col_idx_list;
# 按行读取
if by_row:
reader_csv = list(zip(*reader_csv))
# 封装 dict 对象
file_name = os.path.splitext(os.path.basename(path))[0];
read_csv_result[file_name] = reader_csv;
return read_csv_result;
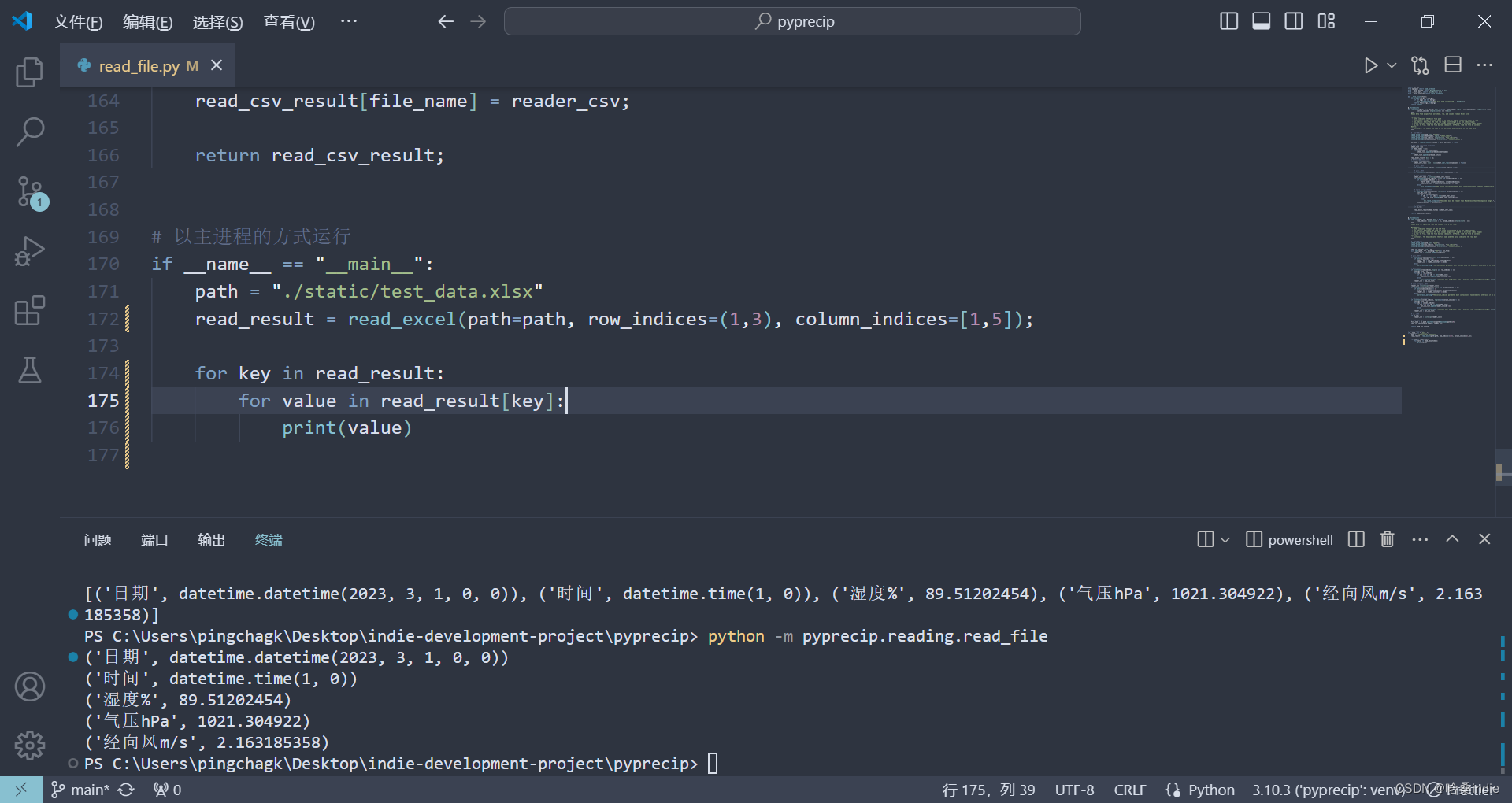
运行演示
# 以主进程的方式运行
if __name__ == "__main__":
path = "./static/test_data.xlsx"
read_result = read_excel(path=path, row_indices=(1,3), column_indices=[1,5]);
for key in read_result:
for value in read_result[key]:
print(value)
读取 Excel 文件
同样的逻辑,也适用于读取 Excel 文件。
@__file_exists
def read_excel(path: str, by_row: bool = False, sheet_names: tuple = (), row_indices: (tuple|list) = (),
column_indices: (tuple|list) = ()) -> dict:
"""
Reads data from a specified worksheet, row, and column from an Excel file.
Parameters:
- path: indicates the Excel file path
- sheet_names: A tuple of sheet names to be read. If empty, the active sheet is read
- row_indices: Specifies the read row range (list length 2) or row index (tuple)
- column_indices: specifies the read column range (list length 2) or column index (tuple)
- by_row: If True, read the file by rows (default). If False, read the file by columns.
Return:
- Dictionary. The key is the name of the worksheet and the value is the read data
"""
# 检查参数类型
check_param_type(path, str, "path");
check_param_type(sheet_names, tuple, "sheet_names");
check_param_type(row_indices, (tuple|list), "row_indices");
check_param_type(column_indices, (tuple|list), "column_indices");
workbook = load_workbook(filename = path, data_only = True)
# Gets the specified worksheet
sheet_list = []
if sheet_names != ():
for sheet_name in sheet_names:
sheet_list.append(workbook[sheet_name])
else:
sheet_list.append(workbook.active)
read_excel_result: dict = {};
# 遍历工作簿 sheet_list
for sheet in sheet_list:
sheet_iter_rows: list = list(sheet.iter_rows(values_only = True))
# 指定行范围
if isinstance(row_indices, list) and row_indices != []:
if len(row_indices) == 2:
start, end = row_indices[0], row_indices[1]
sheet_iter_rows = sheet_iter_rows[start-1: end]
else:
warn.raise_warning("The row_indices parameter must contain only two elements, otherwise it is invalid.")
# 指定行索引
if isinstance(row_indices, tuple) and row_indices != ():
temp_iter_rows = []
for idx in row_indices:
if idx >= 1 and idx <= len(sheet_iter_rows):
temp_iter_rows.append(sheet_iter_rows[idx-1])
else:
exc.raise_exception("The index must be greater than 0 and less than the sequence length.", IndexError)
sheet_iter_rows = temp_iter_rows
# list 类型指定行范围
sheet_iter_cols = list(zip(*sheet_iter_rows))
if isinstance(column_indices, list) and column_indices != []:
if len(column_indices) == 2:
start, end = column_indices[0], column_indices[1];
sheet_iter_cols = sheet_iter_cols[start-1: end]
else:
warn.raise_warning("The column_indices parameter must contain only two elements, otherwise it is invalid.")
# tuple 类型指定列索引
if isinstance(column_indices, tuple) and column_indices != ():
col_idx_list = []
for idx in column_indices:
if idx >= 1 and idx <= len(sheet_iter_cols):
col_idx_list.append(sheet_iter_cols[idx-1]);
else:
exc.raise_exception("The index must be greater than 0 and less than the sequence length.", IndexError)
sheet_iter_cols = col_idx_list;
# 是否按行读取
if by_row:
sheet_iter_cols = list(zip(*sheet_iter_cols))
read_excel_result[sheet.title] = sheet_iter_cols;
return read_excel_result;