目录
Nginx
nginx如何配置负载均衡
负载均衡有哪些策略
1、轮询(默认)
2、指定权重
3、ip_hash(客户端ip绑定)
4、least_conn(最少连接)
5、fair
6、url_hash
Nginx为什么效率高
gateway
使用gateway都做了那些事情
Spring Cloud Gateway实战案例(限流、熔断回退、跨域、统一异常处理和重试机制)
在gateway身份认证,权限认证是怎么去做的
路由的断言有那些(路由策略)
如何做动态路由
限流的策略有那些
链路追踪zipkin
链路追踪zipkin的原理是啥
Zipkin 的原理
1. ZipKin 架构
2. Zipkin 核心组件
3. Zipkin 核心结构
4. Zipkin 的工作流程
TraceId spanId是怎么生成的
如何保证微服务之间接口的幂等性?
Nginx
nginx如何配置负载均衡
所谓负载均衡就是:就是把大量的请求按照我们指定的方式均衡的分配给集群中的每台服务器,从而不会产生集群中大量请求只请求某一台服务器,从而使该服务器宕机的情况。
实现负载均衡之前要先实现反向代理,即请求到某个域名,默认该请求被nginx接收到,然后nginx根据配置,类似DNS解析,nginx会根据配置把特定的请求转发到对应的服务器
通过upstream这个配置,写一组被代理的服务器地址,然后配置负载均衡的算法。
upstream mysvr {
server 192.168.10.121:3333;
server 192.168.10.122:3333;
}
server {
....
location ~*^.+$ {
proxy_pass http://mysvr; #请求转向mysvr 定义的服务器列表
}
}

nginx配置文件详解及其负载均衡; - 笑~笑 - 博客园 (cnblogs.com)
负载均衡有哪些策略

1、轮询(默认)
每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,会自动剔除;
upstream test {
server 10.0.0.7:80;
server 10.0.0.8:80;
}
2、指定权重
指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况;
upstream test {
server 10.0.0.7:80 weight=2;
server 10.0.0.8:80 weight=1;
}
3、ip_hash(客户端ip绑定)
每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端的服务器,可以解决session问题;
upstream test {
ip_hash;
server 10.0.0.7:80;
server 10.0.0.8:80;
}
4、least_conn(最少连接)
把请求转发给连接数较少的后端服务器。
轮询算法是把请求平均的转发给各个后端,使它们的负载大致相同;但是,有些请求占用的时间很长,会导致其所在的后端负载较高。这种情况下,least_conn这种方式就可以达到更好的负载均衡效果。
#动态服务器组
upstream dynamic_zuoyu {
least_conn; #把请求转发给连接数较少的后端服务器
server localhost:8080 weight=2; #tomcat 7.0
server localhost:8081; #tomcat 8.0
server localhost:8082 backup; #tomcat 8.5
server localhost:8083 max_fails=3 fail_timeout=20s; #tomcat 9.0
}
2、随机法
通过系统的随机算法,根据后端服务器的列表大小值来随机选取其中的一台服务器进行访问。由概率统计理论可以得知,随着客户端调用服务端的次数增多,
第三方策略
第三方的负载均衡策略的实现需要安装第三方插件。(5、fair 6、url_hash)
5、fair
按后端服务器的响应时间来请求分配,响应时间短的优先分配;
upstream test {
fair;
server 10.0.0.7:80;
server 10.0.0.8:80;
}
6、url_hash
按访问url的hash结果来分配请求,按每个url定向到同一个后端服务器,后端服务器为缓存时比较有效;
upstream test {
server 10.0.0.7:80;
server 10.0.0.8:80;
hash $request_uri;
hash_method crc32;
}Nginx为什么效率高
Nginx采用了先进的异步非阻塞IO模型,高度可定制性等特点
Nginx 实现了对epoll的封装,是多进程单线程的典型代表。使用多进程模式,不仅能提高并发率,而且进程之间是相互独立的,一 个worker进程挂了不会影响到其他worker进程。
-
Nginx 采用多进程 + 异步非阻塞方式(IO 多路复用 Epoll)。
gateway
使用gateway都做了那些事情
跨域,路由,限流(一般是sentinel),
(身份认证,权限认证),
熔断回退、统一异常处理和重试机制
Spring Cloud Gateway实战案例(限流、熔断回退、跨域、统一异常处理和重试机制)
在gateway身份认证,权限认证是怎么去做的
1.使用Session,可使用spring security来实现Session的管理 ,使用redis来存储会话状态,客户端的sessionID需要cookie来存储

2.使用Token,由服务端签发,并将用户信息存储在redis中,客户端每次请求都带上进行验证

3.使用JWT,由服务端签发且不保存会话状态,客户端每次请求都需要验证合法性

路由的断言有那些(路由策略)

如何做动态路由

限流的策略有那些
1,计数器算法
计数器算法为最简答的限流算法,其实现原理是为维护一个单位时间内的计数器。在单位时间内,开始计数器为0,每次通过一个请求计数器+1。如果单位时间内 计数器的数量大于了预先设定的阈值,则在此刻到单位时间的最后一刻范围内的请求都将被拒绝。单位时间结束计数器归零,重新开始计数。
2,漏桶算法
漏桶算法实际为一个容器请求队列,关键要素为 桶大小(队列大小),流出速率(出队速率)。即无论请求并发多高,如果桶内的队列满了,多余进来的请求都将被舍弃。由于桶的流出速率固定,所以可以保证限流后的请求并发数可以固定在一个范围内。
3,令牌桶算法
令牌桶算法为漏桶算法的一种改进。漏桶算法能够控制调用服务的速率,而令牌桶算法不仅能控制调用服务的速率,还能在短时间内允许一个超并发的调用。其实现原理为,存在一个令牌桶,并且有一个持续不断地产生令牌的机制,
Ribbon 7种负载均衡策略
1.轮询策略
轮询策略:RoundRobinRule,按照一定的顺序依次调用服务实例。比如一共有 3 个服务,第一次调用服务 1,第二次调用服务 2,第三次调用服务3,依次类推。 此策略的配置设置如下:

2.权重策略
权重策略:WeightedResponseTimeRule,根据每个服务提供者的响应时间分配一个权重,响应时间越长,权重越小,被选中的可能性也就越低。 它的实现原理是,刚开始使用轮询策略并开启一个计时器,每一段时间收集一次所有服务提供者的平均响应时间,然后再给每个服务提供者附上一个权重,权重越高被选中的概率也越大。 此策略的配置设置如下:

3.随机策略
随机策略:RandomRule,从服务提供者的列表中随机选择一个服务实例。 此策略的配置设置如下:

4.最小连接数策略
最小连接数策略:BestAvailableRule,也叫最小并发数策略,它是遍历服务提供者列表,选取连接数最小的⼀个服务实例。如果有相同的最小连接数,那么会调用轮询策略进行选取。 此策略的配置设置如下:

5.重试策略
重试策略:RetryRule,按照轮询策略来获取服务,如果获取的服务实例为 null 或已经失效,则在指定的时间之内不断地进行重试来获取服务,如果超过指定时间依然没获取到服务实例则返回 null。 此策略的配置设置如下:

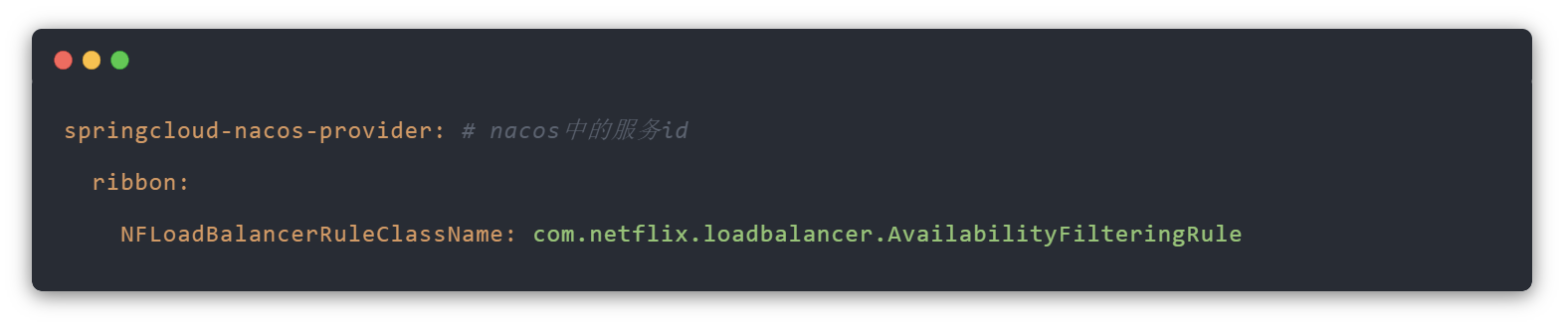
6.可用性敏感策略
可用敏感性策略:AvailabilityFilteringRule,先过滤掉非健康的服务实例,然后再选择连接数较小的服务实例。 此策略的配置设置如下:
7.区域敏感策略
区域敏感策略:ZoneAvoidanceRule,根据服务所在区域(zone)的性能和服务的可用性来选择服务实例,在没有区域的环境下,该策略和轮询策略类似。 此策略的配置设置如下:

链路追踪zipkin
链路追踪zipkin的原理是啥
Zipkin 每一个调用链路通过一个 trace id 来串联起来,只要你有一个 trace id ,就能够直接定位到这次调用链路,并且可以根据服务名、标签、响应时间等进行查询,过滤那些耗时比较长的链路节点。
ZipKin 可以分为两部分:
- ZipKin Server :用来作为数据的采集存储、数据分析与展示;
- ZipKin Client :基于不同的语言及框架封装的一些列客户端工具,这些工具完成了追踪数据的生成与上报功能。
整体架构如下:

Zipkin 的原理
基本思路是在服务调用的请求和响应中加入ID,标明上下游请求的关系。利用这些信息,可以可视化地分析服务调用链路和服务间的依赖关系。
1. ZipKin 架构
ZipKin 可以分为两部分:
- ZipKin Server :用来作为数据的采集存储、数据分析与展示;
- ZipKin Client :基于不同的语言及框架封装的一些列客户端工具,这些工具完成了追踪数据的生成与上报功能。
整体架构如下:
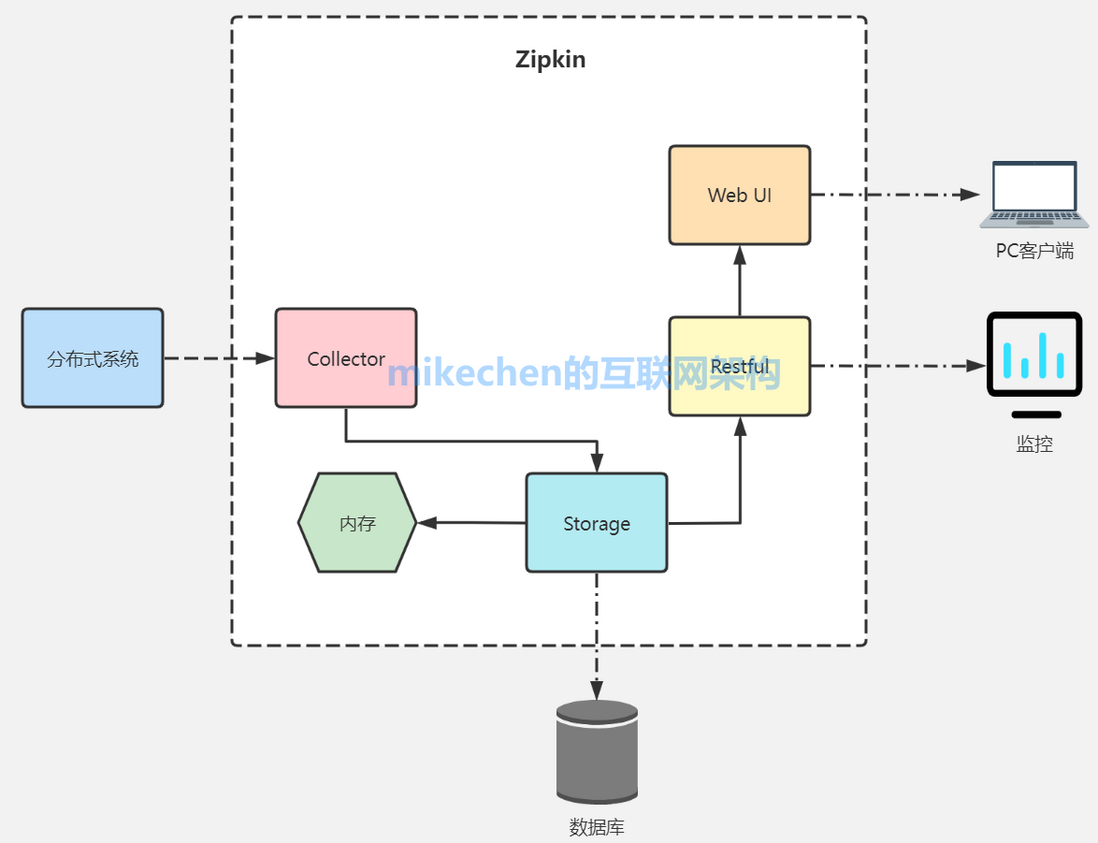
2. Zipkin 核心组件
Zipkin (服务端)包含四个组件,分别是 collector、storage、search、web UI。

1) collector 信息收集器
collector 接受或者收集各个应用传输的数据。
2) storage 存储组件
zipkin 默认直接将数据存在内存中,此外支持使用 Cassandra、ElasticSearch 和 Mysql 。
3) search 查询进程
它提供了简单的 JSON API 来供外部调用查询。
4) web UI 服务端展示平台
主要是提供简单的 web 界面,用图表将链路信息清晰地展示给开发人员。
3. Zipkin 核心结构
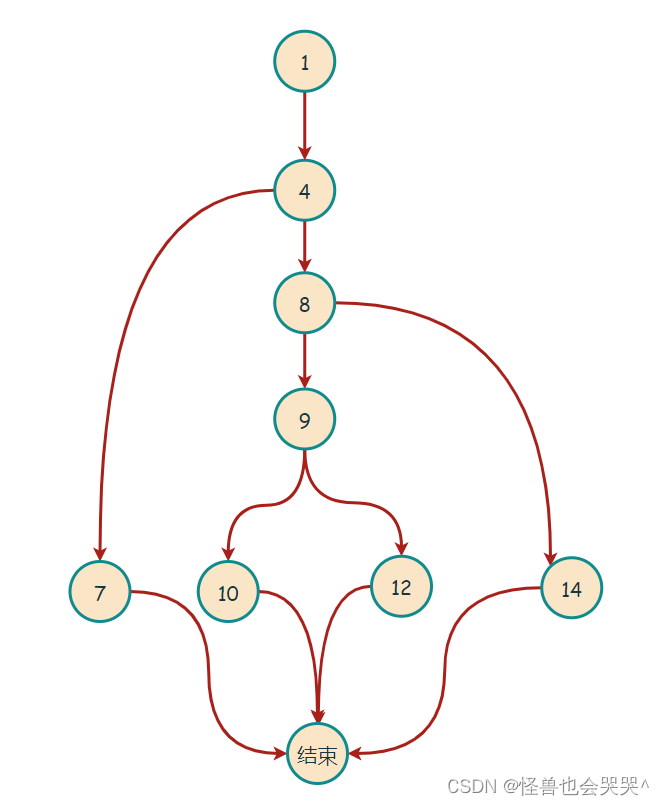
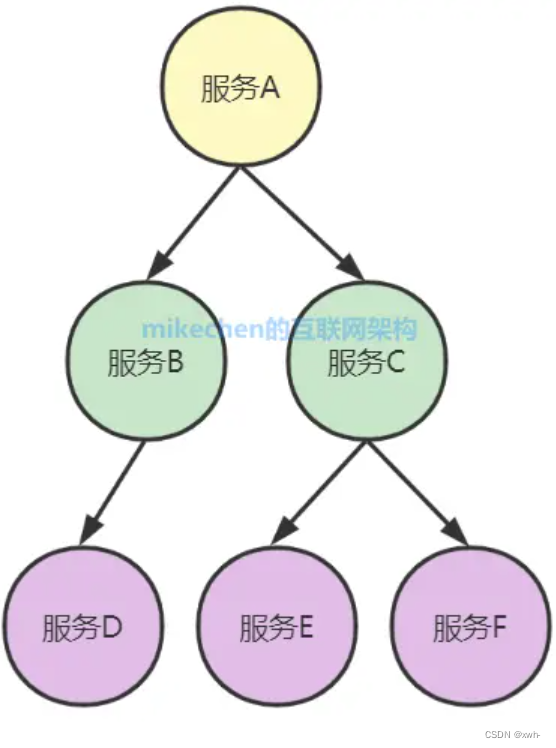
当用户发起一次调用时,Zipkin 的客户端会在入口处为整条调用链路生成一个全局唯一的 trace id,并为这条链路中的每一次分布式调用生成一个 span id。
一个 trace 由一组 span 组成,可以看成是由 trace 为根节点,span 为若干个子节点的一棵树,如下图所示:
4. Zipkin 的工作流程
一个应用的代码发起 HTTP get 请求,经过 Trace 框架拦截,大致流程如下图所示:

1)把当前调用链的 Trace 信息,添加到 HTTP Header 里面;
2)记录当前调用的时间戳;
3)发送 HTTP 请求,把 trace 相关的 header 信息携带上;
4)调用结束之后,记录当前调用话费的时间;
5)把上面流程产生的信息,汇集成一个 span,再把这个 span 信息上传到 zipkin 的 Collector 模块。
TraceId spanId是怎么生成的
● traceId,用于标识某一次具体的请求ID。当用户的请求进入系统后,会在RPC调用网络的第一层生成一个全局唯一的traceId,并且会随着每一层的RPC调用,不断往后传递,这样的话通过traceId就可以把一次用户请求在系统中调用的路径串联起来。
● spanId,用于标识一次RPC调用在分布式请求中的位置。当用户的请求进入系统后,处在RPC调用网络的第一层A时spanId初始值是0,进入下一层RPC调用B的时候spanId是0.1,继续进入下一层RPC调用C时spanId是0.1.1,而与B处在同一层的RPC调用E的spanId是0.2,这样的话通过spanId就可以定位某一次RPC请求在系统调用中所处的位置,以及它的上下游依赖分别是谁。
● annotation,用于业务自定义埋点数据,可以是业务感兴趣的想上传到后端的数据,比如一次请求的用户UID。
上面这三段内容用通俗语言小结一下,traceId是用于串联某一次请求在系统中经过的所有路径,spanId是用于区分系统不同服务之间调用的先后关系,而annotation是用于业务自定义一些自己感兴趣的数据,在上传traceId和spanId这些基本信息之外,添加一些自己感兴趣的信息。
TraceId 生成规则
SOFATracer 通过 TraceId 来将一个请求在各个服务器上的调用日志串联起来,TraceId 一般由接收请求经过的第一个服务器产生。
产生规则是: 服务器 IP + ID 产生的时间 + 自增序列 + 当前进程号 ,比如:
0ad1348f1403169275002100356696
前 8 位 0ad1348f 即产生 TraceId 的机器的 IP,这是一个十六进制的数字,每两位代表 IP 中的一段,我们把这个数字,按每两位转成 10 进制即可得到常见的 IP 地址表示方式 10.209.52.143,您也可以根据这个规律来查找到请求经过的第一个服务器。
后面的 13 位 1403169275002 是产生 TraceId 的时间。之后的 4 位 1003 是一个自增的序列,从 1000 涨到 9000,到达 9000 后回到 1000 再开始往上涨。最后的 5 位 56696 是当前的进程 ID,为了防止单机多进程出现 TraceId 冲突的情况,所以在 TraceId 末尾添加了当前的进程 ID。
说明
TraceId 目前的生成的规则参考了阿里的鹰眼组件。
SpanId 生成规则
SOFATracer 中的 SpanId 代表本次调用在整个调用链路树中的位置。
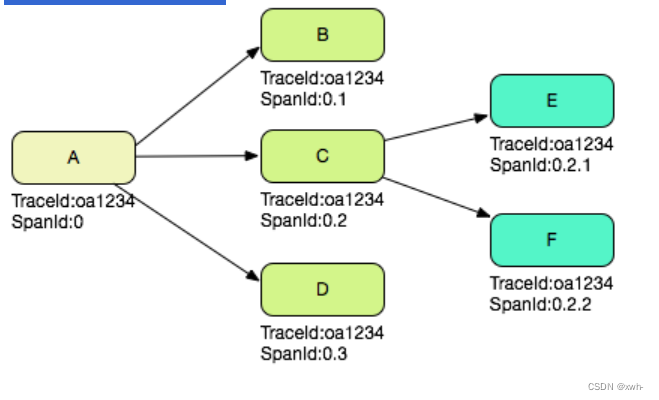
假设一个 Web 系统 A 接收了一次用户请求,那么在这个系统的 SOFATracer MVC 日志中,记录下的 SpanId 是 0,代表是整个调用的根节点,如果 A 系统处理这次请求,需要通过 RPC 依次调用 B、C、D 三个系统,那么在 A 系统的 SOFATracer RPC 客户端日志中,SpanId 分别是 0.1,0.2 和 0.3,在 B、C、D 三个系统的 SOFATracer RPC 服务端日志中,SpanId 也分别是 0.1,0.2 和 0.3;如果 C 系统在处理请求的时候又调用了 E,F 两个系统,那么 C 系统中对应的 SOFATracer RPC 客户端日志是 0.2.1 和 0.2.2,E、F 两个系统对应的 SOFATracer RPC 服务端日志也是 0.2.1 和 0.2.2。
根据上面的描述可以知道,如果把一次调用中所有的 SpanId 收集起来,可以组成一棵完整的链路树。
假设一次分布式调用中产生的 TraceId 是 0a1234(实际不会这么短),那么根据上文 SpanId 的产生过程,如下图所示:
如何保证微服务之间接口的幂等性?
幂等性:
【接口的幂等性实际上就是接口可重复调用,在调用方多次调用的情况下,接口最终得到的结果是一致的】
利用唯一事务ID:
为每个操作请求分配一个唯一的事务ID。服务端检查该ID,如果之前已经处理过,就直接返回原来的处理结果,否则进行处理并存储该ID与结果的关联。
乐观锁:
使用乐观锁可以在更新数据时检查数据版本。每次数据修改时,版本号增加。如果请求中的版本号与服务器上的不匹配,则意味着有其他操作已经修改了数据,当前操作将被拒绝。
Token机制:
在操作开始前,客户端请求一个操作令牌(token),并在随后的操作中使用该token。服务器对每个token只允许一次有效的操作,从而防止重复处理。
指纹机制:
根据请求的特征(如参数、时间戳等)生成请求指纹。服务端检查指纹是否已存在,存在则认为是重复请求。
幂等框架支持:
一些现代框架和组件(如消息队列、数据库等)提供了内建的支持来处理幂等性,例如Kafka的Exactly-once语义,或者数据库的unique constraint。