文章目录
- 数据导入和数据可视化
- 数据集制作以及预处理
- 模型结构
- 低阶 API 构建模型
- 中阶 API 构建模型
- 高阶 API 构建模型
- 保存和导入模型
这里以实际项目CIFAR-10为例,分别使用低阶,中阶,高阶 API 搭建模型。
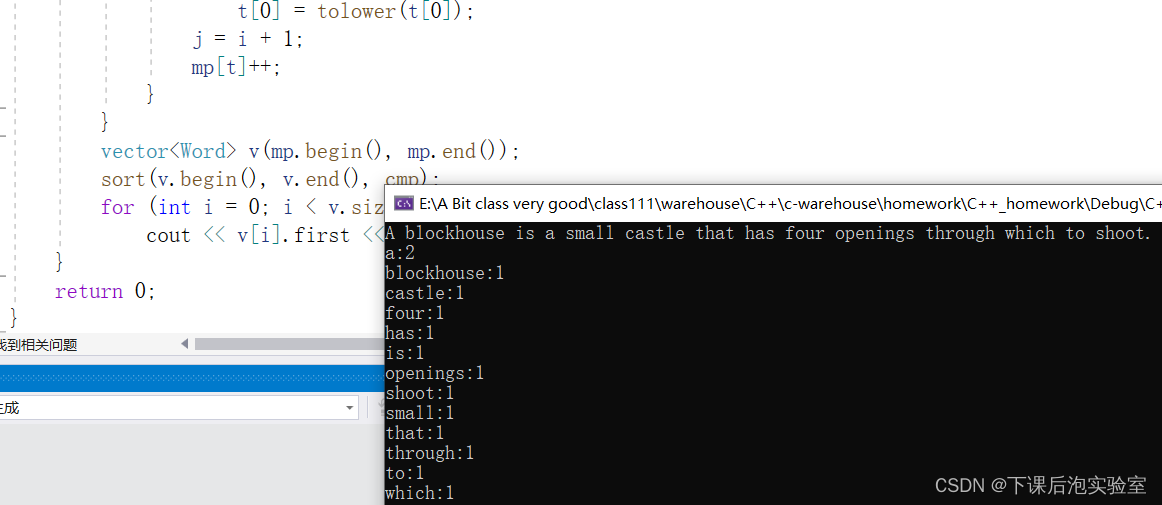
这里以CIFAR-10为数据集,CIFAR-10为小型数据集,一共包含10个类别的 RGB 彩色图像:飞机(airplane)、汽车(automobile)、鸟类(bird)、猫(cat)、鹿(deer)、狗(dog)、蛙类(frog)、马(horse)、船(ship)和卡车(truck)。图像的尺寸为 32×32(像素),3个通道 ,数据集中一共有 50000 张训练圄片和 10000 张测试图像。CIFAR-10数据集有3个版本,这里使用Python版本。
数据导入和数据可视化
这里不用书中给的CIFAR-10数据,直接使用TensorFlow自带的玩意导入数据,可能需要魔法,其实TensorFlow中的数据特别的经典。
![![[Pasted image 20240506194103.png]]](https://img-blog.csdnimg.cn/direct/9c9c049d535c44c888ffb3cd14fbb40f.png)
接下来导入cifar10数据集并进行可视化展示
import matplotlib.pyplot as plt
import tensorflow as tf
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
# x_train.shape, y_train.shape, x_test.shape, y_test.shape
# ((50000, 32, 32, 3), (50000, 1), (10000, 32, 32, 3), (10000, 1))
index_name = {
0:'airplane',
1:'automobile',
2:'bird',
3:'cat',
4:'deer',
5:'dog',
6:'frog',
7:'horse',
8:'ship',
9:'truck'
}
def plot_100_img(imgs, labels):
fig = plt.figure(figsize=(20,20))
for i in range(10):
for j in range(10):
plt.subplot(10,10,i*10+j+1)
plt.imshow(imgs[i*10+j])
plt.title(index_name[labels[i*10+j][0]])
plt.axis('off')
plt.show()
plot_100_img(x_test[:100])
![![[Pasted image 20240506200312.png]]](https://img-blog.csdnimg.cn/direct/23ed0ee4b8a749cfb7dadc3e0c31749b.png)
数据集制作以及预处理
数据集预处理很简单就能实现,直接一行代码。
train_data = tf.data.Dataset.from_tensor_slices((x_train, y_train))
# 提取出一行数据
# train_data.take(1).get_single_element()
这里接着对数据预处理操作,也很容易就能实现。
def process_data(img, label):
img = tf.cast(img, tf.float32) / 255.0
return img, label
train_data = train_data.map(process_data)
# 提取出一行数据
# train_data.take(1).get_single_element()
这里对数据还有一些存储和提取操作
dataset 中 shuffle()、repeat()、batch()、prefetch()等函数的主要功能如下。
1)repeat(count=None) 表示重复此数据集 count 次,实际上,我们看到 repeat 往往是接在 shuffle 后面的。为何要这么做,而不是反过来,先 repeat 再 shuffle 呢? 如果shuffle 在 repeat 之后,epoch 与 epoch 之间的边界就会模糊,出现未遍历完数据,已经计算过的数据又出现的情况。
2)shuffle(buffer_size, seed=None, reshuffle_each_iteration=None) 表示将数据打乱,数值越大,混乱程度越大。为了完全打乱,buffer_size 应等于数据集的数量。
3)batch(batch_size, drop_remainder=False) 表示按照顺序取出 batch_size 大小数据,最后一次输出可能小于batch ,如果程序指定了每次必须输入进批次的大小,那么应将drop_remainder 设置为 True 以防止产生较小的批次,默认为 False。
4)prefetch(buffer_size) 表示使用一个后台线程以及一个buffer来缓存batch,提前为模型的执行程序准备好数据。一般来说,buffer的大小应该至少和每一步训练消耗的batch数量一致,也就是 GPU/TPU 的数量。我们也可以使用AUTOTUNE来设置。创建一个Dataset便可从该数据集中预提取元素,注意:examples.prefetch(2) 表示将预取2个元素(2个示例),而examples.batch(20).prefetch(2) 表示将预取2个元素(2个批次,每个批次有20个示例),buffer_size 表示预提取时将缓冲的最大元素数返回 Dataset。
![![[Pasted image 20240506201344.png]]](https://img-blog.csdnimg.cn/direct/537beb2425ed45f5a6d5949ea3385224.png)
最后我们对数据进行一些缓存操作
learning_rate = 0.0002
batch_size = 64
training_steps = 40000
display_step = 1000
AUTOTUNE = tf.data.experimental.AUTOTUNE
train_data = train_data.map(process_data).shuffle(5000).repeat(training_steps).batch(batch_size).prefetch(buffer_size=AUTOTUNE)
目前数据准备完毕!
模型结构
模型的结构如下,现在使用低阶,中阶,高阶 API 来构建这一个模型
![![[Pasted image 20240506202450.png]]](https://img-blog.csdnimg.cn/direct/1984f35550ae458baa1343ea5194e236.png)
低阶 API 构建模型
import matplotlib.pyplot as plt
import tensorflow as tf
## 定义模型
class CustomModel(tf.Module):
def __init__(self, name=None):
super(CustomModel, self).__init__(name=name)
self.w1 = tf.Variable(tf.initializers.RandomNormal()([32*32*3, 256]))
self.b1 = tf.Variable(tf.initializers.RandomNormal()([256]))
self.w2 = tf.Variable(tf.initializers.RandomNormal()([256, 128]))
self.b2 = tf.Variable(tf.initializers.RandomNormal()([128]))
self.w3 = tf.Variable(tf.initializers.RandomNormal()([128, 64]))
self.b3 = tf.Variable(tf.initializers.RandomNormal()([64]))
self.w4 = tf.Variable(tf.initializers.RandomNormal()([64, 10]))
self.b4 = tf.Variable(tf.initializers.RandomNormal()([10]))
def __call__(self, x):
x = tf.cast(x, tf.float32)
x = tf.reshape(x, [x.shape[0], -1])
x = tf.nn.relu(x @ self.w1 + self.b1)
x = tf.nn.relu(x @ self.w2 + self.b2)
x = tf.nn.relu(x @ self.w3 + self.b3)
x = tf.nn.softmax(x @ self.w4 + self.b4)
return x
model = CustomModel()
## 定义损失
def compute_loss(y, y_pred):
y_pred = tf.clip_by_value(y_pred, 1e-9, 1.)
loss = tf.keras.losses.sparse_categorical_crossentropy(y, y_pred)
return tf.reduce_mean(loss)
## 定义优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=0.0002)
## 定义准确率
def compute_accuracy(y, y_pred):
correct_pred = tf.equal(tf.argmax(y_pred, axis=1), tf.cast(tf.reshape(y, -1), tf.int64))
correct_pred = tf.cast(correct_pred, tf.float32)
return tf.reduce_mean(correct_pred)
## 定义一次epoch
def train_one_epoch(x, y):
with tf.GradientTape() as tape:
y_pred = model(x)
loss = compute_loss(y, y_pred)
accuracy = compute_accuracy(y, y_pred)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
return loss.numpy(), accuracy.numpy()
## 开始训练
loss_list, acc_list = [], []
for i, (batch_x, batch_y) in enumerate(train_data.take(1000), 1):
loss, acc = train_one_epoch(batch_x, batch_y)
loss_list.append(loss)
acc_list.append(acc)
if i % 10 == 0:
print(f'第{i}次训练->', 'loss:' ,loss, 'acc:', acc)
中阶 API 构建模型
## 定义模型
class CustomModel(tf.Module):
def __init__(self):
super(CustomModel, self).__init__()
self.flatten = tf.keras.layers.Flatten()
self.dense_1 = tf.keras.layers.Dense(256, activation='relu')
self.dense_2 = tf.keras.layers.Dense(128, activation='relu')
self.dense_3 = tf.keras.layers.Dense(64, activation='relu')
self.dense_4 = tf.keras.layers.Dense(10, activation='softmax')
def __call__(self, x):
x = self.flatten(x)
x = self.dense_1(x)
x = self.dense_2(x)
x = self.dense_3(x)
x = self.dense_4(x)
return x
model = CustomModel()
## 定义损失以及准确率
compute_loss = tf.keras.losses.SparseCategoricalCrossentropy()
train_loss = tf.keras.metrics.Mean()
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
## 定义优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=0.0002)
## 定义一次epoch
def train_one_epoch(x, y):
with tf.GradientTape() as tape:
y_pred = model(x)
loss = compute_loss(y, y_pred)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
train_loss(loss)
train_accuracy(y, y_pred)
## 开始训练
loss_list, accuracy_list = [], []
for i, (batch_x, batch_y) in enumerate(train_data.take(1000), 1):
train_one_epoch(batch_x, batch_y)
loss_list.append(train_loss.result())
accuracy_list.append(train_accuracy.result())
if i % 10 == 0:
print(f"第{i}次训练: loss: {train_loss.result()} accuarcy: {train_accuracy.result()}")
高阶 API 构建模型
## 定义模型
model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[32,32,3]),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax'),
])
## 定义optimizer,loss, accuracy
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.0002),
loss = tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy']
)
## 开始训练
model.fit(train_data.take(10000))
保存和导入模型
保存模型
tf.keras.models.save_model(model, 'model_folder')
导入模型
model = tf.keras.models.load_model('model_folder')









![[安全开发]如何搭建一款自己的网安微信机器人](https://img-blog.csdnimg.cn/img_convert/23ca4c151bc9fd030631f39cc0eb8fed.png)