一、选择、填空知识点整理
1. fork() 函数
fork() 函数通过系统调用创建一个与原来进程相同的进程(如果初始参数或者传入的变量不同,两个进程也可以做不同的事)
示例 ——
#include <stdio.h>
int main() {
for(int i=0; i<2; i++){
fork();
printf("输出 %d 次 \n" , i);
}
return 0;
}
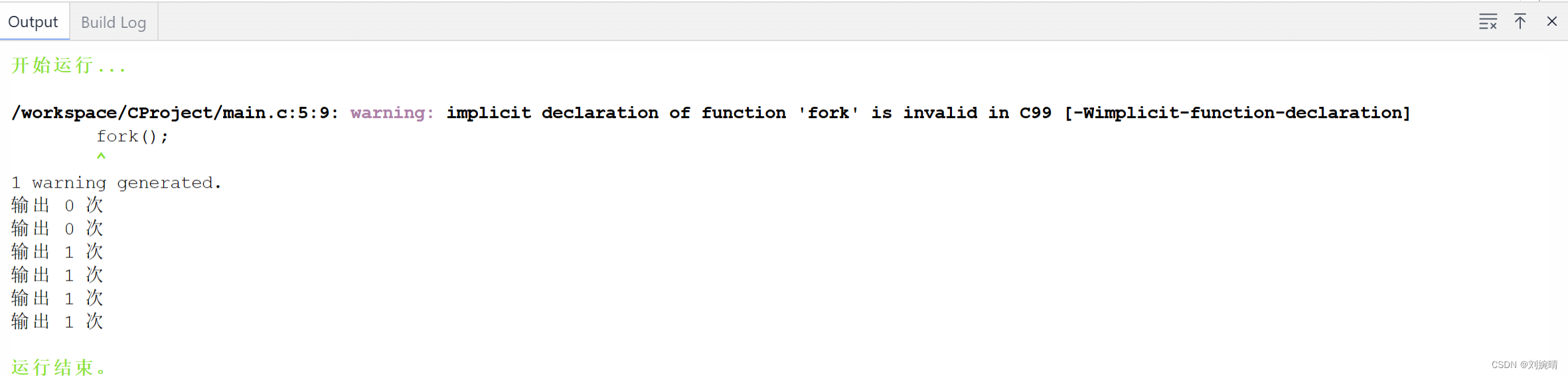
解释: 程序每次进入一个 for 循环,就执行一次 fork() 函数,开启一个新的 main 线程。因为,for 循环一共循环 2 次,因此重新开启了两个 main 线程 。所以加上本身的一个线程,一共 3 个相同的 main 线程,因此输出 6 次。
2. 如何提升哈希表查询效率
哈希表的查找性能在 “没有冲突” 的情况下是最高的,时间复杂度 O(1)。但是实际情况下,冲突是不可避免的,因此散列表的平均查找长度取决于如下因素:
- 散列表是否均匀 —— 由散列函数的好坏决定
- 处理冲突的方法 —— 是否会产生堆积
- 线性探测:产生堆积;
- 链址处理:不会产生任何堆积
- 散列表的装填因子 —— 装填因子标志着散列表的装满的程度,其计算方式如下:
装填因子 = 填入表中的记录个数 / 散列表的长度
由上述公式可得出,记录越多,装载因子越大,那么产生冲突的可能性就越大
3. kill -15 进程号
15 的含义 —— 进程信号,15 表示 正常关闭进程,当操作系统认为该关闭进程行为对系统有不良影响时,就无法关闭。
进程信号 signal:
进程信号有很多,除了默认的正常关闭的 15 外,比较常用的还有 :
- 9 强制中止进程
- 19 暂停进程
4. DNS 协议
- DNS 是什么 ?
域名系统(DNS)是一种用于TCP/IP应用程序的分布式数据库。它提供主机名和IP地址之间的转换及有关电子邮件的选路信息。 - DNS 中的域 ?
5. HTTP 请求方法
HTTP1.0 : GET, POST HEAD
HTTP1.1 :+ OPTIONS、PUT、PATCH、DELETE、TRACE 、CONNECT
6. 稳定排序
稳定排序: 插入排序、基数排序、归并排序、冒泡排序
不稳定的排序: 快速排序、希尔排序、简单选择排序、堆排序
7. 线程 & 线程
- 本质区别:进程是资源分配的基本单位,线程是CPU调度的基本单位。
- 内存消耗:进程有独立的虚拟地址空间,而同一个进程的线程之间共享进程的资源,自身只有栈和寄存器等少量独立的空间。
- 切换开销:进程和线程切换时,需要切换上下文,进程的上下文切换时间开销远远大于线程上下文切换时间,各种页表、打开的文件等都需要切换,耗费资源较大,效率要差一些。
- 并发性:进程的并发性较低,线程的并发性较高。
- 健壮性:一个进程崩溃后,在保护模式下不会对其他进程产生影响,但是一个线程崩溃导致整个进程都死掉。所以多进程要比多线程健壮。
8. 僵尸线程 & 孤儿线程
- 僵尸进程
僵尸进程是指当前进程运行结束后,其父进程仍在运行并且父进程没有清理已经结束的子进程,导致子进程的进程描述符仍然保存在系统中。
僵尸进程的危害:
如果父进程不调用wait / waitpid清理子进程的话, 那么子进程的进程号就会一直被占用,但是系统所能使用的进程号是有限的,如果大量的产生僵死进程,将因为没有可用进程号而导致系统不能产生新的进程。 - 孤儿进程
当前进程仍在运行时其父进程运行结束了,或者一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。
孤儿进程的处理:
孤儿进程将被init进程( 进程号为1) 所收养,并由内核init进程对它们完成状态收集工作,因此孤儿进程并不会有什么危害。
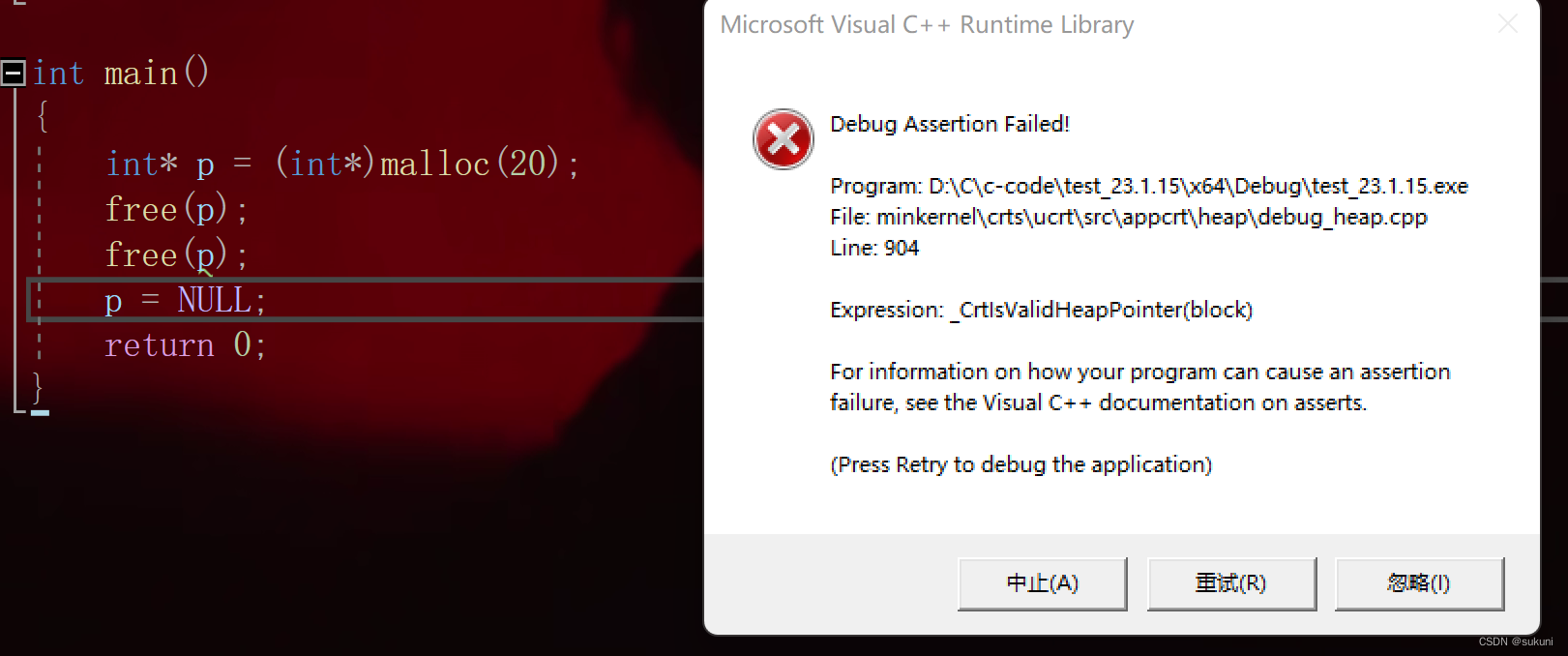
9. 动态分配内存
内存分为两部分:
- 栈:在函数内部声明的所有变量都将占用栈内存。
- 堆:这是程序中未使用的内存,在程序运行时可用于动态分配内存。
在无法提前预知需要多少内存来存储某个定义变量中的特定信息,即所需内存的大小需要在运行时才能确定时,我们就需要进行动态内存分配
10. epoll 和 select
略 —— 后面单独写一个文章讲这个问题
11. 单例模式
略 —— 后面单独写一个文章讲这个问题
二、算法题
- 找出不同的数字是那个
- 删除链表中倒数第 n 个元素