前言
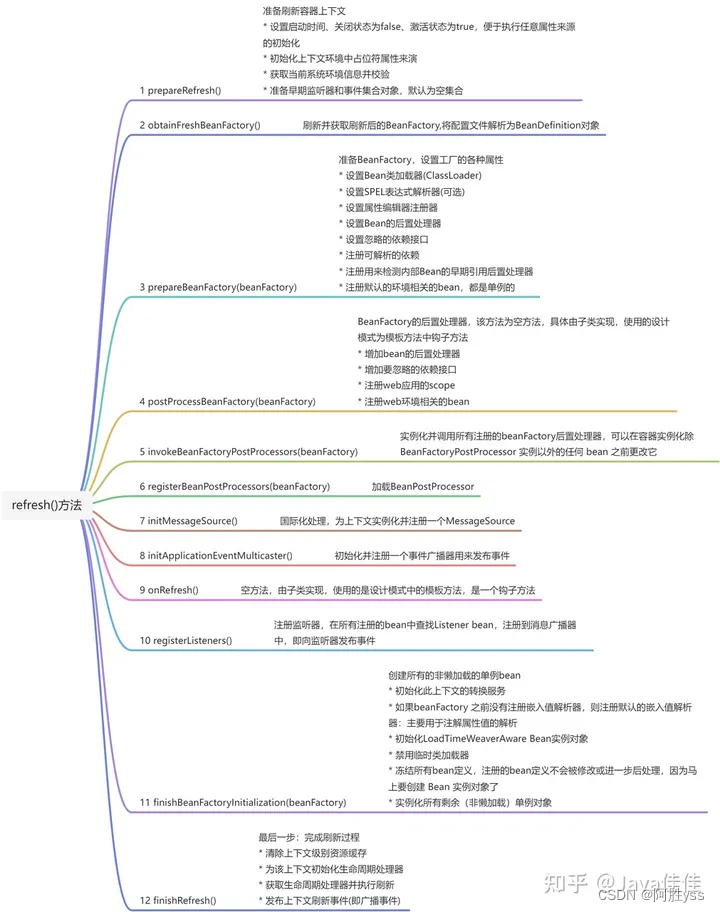
本文介绍6D位姿估计的方法ZebraPose,也可以称为六自由度物体姿态估计,输入单张图片,输出物体的三维位置和三维方向。
它来自CVPR2022的论文,通过层次化分组策略,高效地编码物体表面的信息。
ZebraPose提出了一种从粗糙到精细的训练策略,使得模型能够预测更为精细的2D-3D对应关系。
论文地址:ZebraPose: Coarse to Fine Surface Encoding for 6DoF Object Pose Estimation
代码地址:https://github.com/suyz526/ZebraPose
一、核心创新点——层次化分组
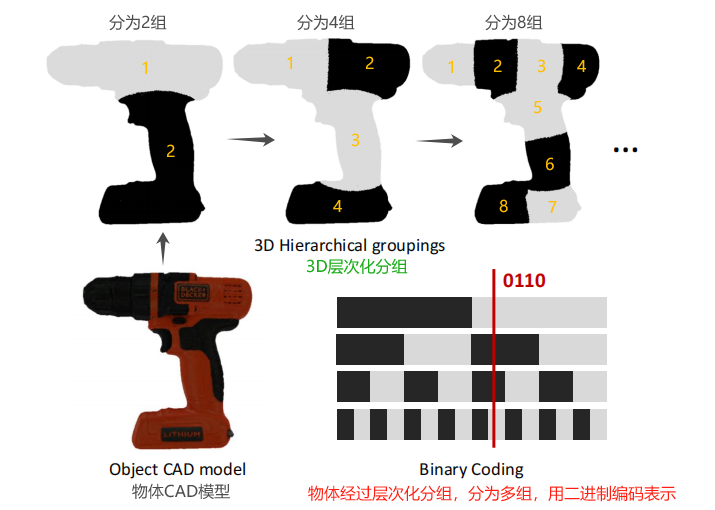
ZebraPose通过层次化分组,将物体分为多组,逐渐细化,精准表达物体表面信息。
如下图所示,一物体的CAD模型,采用逐渐层次化分组,将物体表面分为2、4、8。
- 使用二进制编码,来标识3D模型的每一个顶点。
- 这种编码为模型的每个表面顶点赋予一个唯一的标识符,编码的每个部分代表了模型的一个特定面。
- 红线标出的编码“0110”对应于模型上的一个特定特征。
- 通过这种方法,每个顶点的表面属性可以被精确地编码和学习,而无需复杂的几何处理。
- 这种编码策略通过深度神经网络来学习,使每个顶点的表面都有一个唯一的对应编码,从而实现精确的姿态估计。
- 这种密集的编码策略有助于在存在遮挡的情况下进行更准确的姿态估计,因为即便部分顶点被遮挡,其他顶点的编码仍然可以为姿态估计提供信息。
二、模型框架
模型的框架结构,如下图所示。
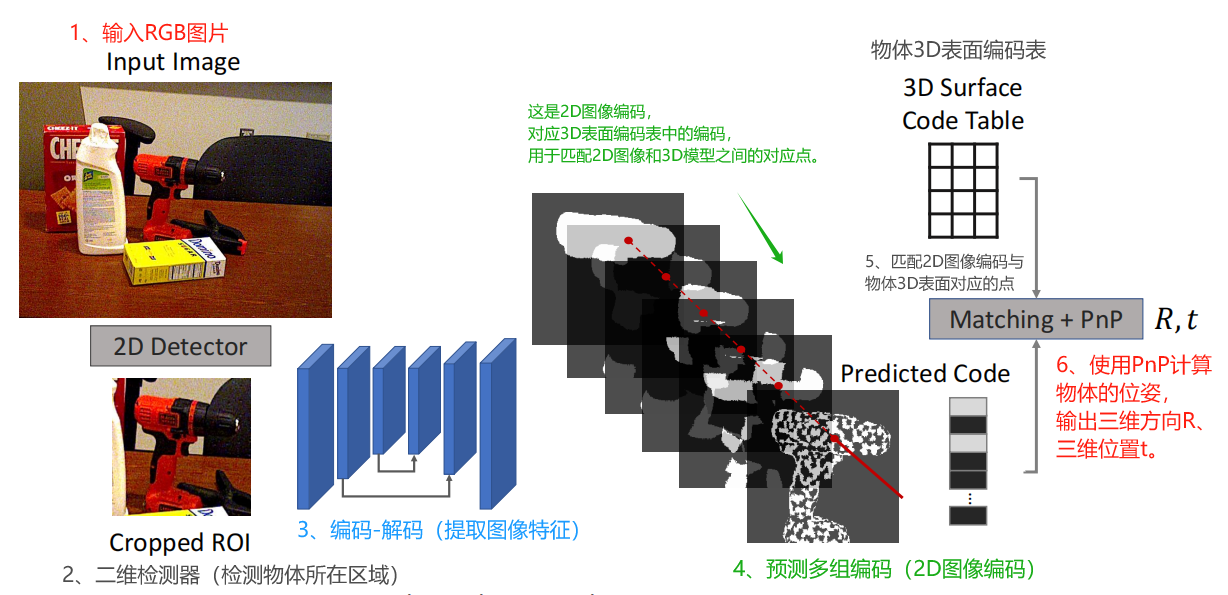
- 输入单张图像,普通的彩色图片,即RGB图片。
- 通过2D检测器,检测物体所在区域,得到ROI区域图像。
- 将物体所在区域,送入到编码器-解码器中提取图像特征。
- 预测出多组编码特征,这是2D图像编码,对应于3D表面编码表中的编码,用于匹配2D图像和3D模型之间的对应点。
- 结合2D图像编码和3D表面编码表,进行对应点匹配;实现2D图像中的点与3D模型中的顶点匹配。
- 输出位姿信息,使用RANSAC和PnP来估计物体的姿态,三维方向R和三维位置t。
关键点:
- 表面编码方法:提出了一种从粗到细的表面编码方法,这种方法不仅为每个顶点分配了一个高效的密集顶点描述符,还充分利用了计算机视觉任务中常用的传统异常值过滤器。
- 层次化训练损失:采用了一种新颖的层次化训练损失和策略,自动地调整训练过程,以更有效地处理密集的2D-3D对应关系的预测。
三、深入分析——层次化学习策略
- 采用了一种层次化学习策略,初期重点是大范围的粗略区域,随后逐渐细化到更精确的位置。
- 这种方法利用了多标签分类问题的策略,提高了学习的效率和精度。
- 这种分层的学习策略允许模型在早期阶段快速学习大致的结构,然后逐步细化到具体的表面细节,这有助于提高整体的学习速度和精度。
模型层次化分组,如下图所示:

1)物体顶点编码方式
- 使用二进制数对每个顶点进行编码,vi表示CAD模型的一个顶点, ci 为该顶点的编码
- ci 属于
,其中d是编码的长度。
- 通过这种编码方式,可以将顶点属性简化为一个数值序列,便于后续的处理和分组。
2)分组迭代
- 首先将所有顶点分为一个初始组 G0。
- 随后进行d次迭代分组,每次迭代都将前一次的组进一步细分,每个组被分成
个小组(𝑟是基数设置为2,𝑗是当前的迭代次数)
- 即每个组被分成
个小组,1,2,4,8,16,32,64等等。
- 这种分组策略使得每个顶点都能逐渐被划分到越来越具体的小组中。
3)顶点分类
- 在每次迭代中,每个顶点都根据其所在的组被赋予一个类别标签 𝑚𝑖,𝑗,其中 𝑚𝑖,𝑗是一个0到1的二进制数。
- 这个过程从全局到局部逐步精细化顶点的分类。
4)顶点编码生成
- 最终,每个顶点的编码 ci 是通过叠加每次迭代中顶点的类别标签来生成的,形成一个包含d位的编码。
- 这种编码策略的应用在构建2D-3D对应关系和解决姿态问题中。
- 其中,使用k-means算法进行分组,以及利用每个组的质心来进一步构建2D-3D对应关系,这是进行姿态估计的关键步骤。
总结 :
- 这种从粗到细的表面编码方法非常适合处理复杂的3D对象表面,它通过分层精细化的方式允许算法逐步识别和适应对象的细节特征。
- 此外,这种方法在处理大规模顶点数据时能够提高处理速度和准确性。
- 在学习过程中,粗略级别的编码会被共享到更广泛的物体区域,而当网络学会区分这些粗略分割后,会集中在更细的位置编码上。
- 这种策略确保了学习过程的高效性,并最终实现了对细粒度表面对应关系的精确预测。
四、3D模型中顶点类别ID渲染到2D图像
在3D对象的每个顶点上,通过先前描述的层次化分组方法,网络为每个顶点预测一个类别ID。
在训练期间,这些3D顶点的类别信息需要被映射到2D图像平面上,以便网络可以学习从2D图像预测3D顶点类别的关系。
-
3D模型中顶点类别ID渲染到2D图像:
- 渲染过程包括将3D模型中顶点的类别ID转移到2D图像中对应的像素上。
- 为了实现这一点,需要模型预测一个的姿态,来将3D信息投影到2D平面。
- 对于3D模型的每个面(由顶点组成),如果面的两个顶点拥有相同的类别ID,则该面被赋予这个类别ID。
- 如果顶点的类别ID不同,则选择第一个顶点的类别ID作为整个面的类别。
-
迭代渲染过程:
- 这个过程需要重复d次,对应于在顶点编码中提到的每一层分组。
- 每个分组迭代都有自己的一组类别ID,这些ID需要被独立地渲染到2D图像上。
- 这种方法确保了训练数据中类别标签的一致性和准确性,允许网络学习如何从2D图像有效地推断出对应3D顶点的精确类别。
五、模型细节设计
- 详细模型参数:
-
类别数量匹配:为了和DPOD方法保持一致,实验首先通过每个面的中点细分来上采样网格,直到顶点数量超过256²,以确保类别数K=256²。
-
顶点分组:使用二进制编码(基数𝑟=2,深度𝑑=16)对3D模型的顶点进行分组。通过多次迭代分组,直到不能再细分为止。为了解决分组大小不均匀的问题,采用改进的k-means++聚类算法确保输出组的点数均匀。
-
网络架构调整:使用修改过的DeepLabv3作为主干网络,增加了跳跃连接以提高特征传递效率。同时,调整了ROI至256x256x3的形状,并设置CNN输出的分辨率为128x128。
-
训练细节:应用动态缩放策略生成噪声ROI,用于训练阶段。此外,设置层次化损失的参数σ=0.5 和α=3,以平衡掩码和顶点编码预测的训练。
-
优化器和训练周期:使用Adam优化器,批量大小为32,学习率为0.0002,总共训练了380k步。
- 在推理阶段:使用Faster R-CNN和FCOS检测的边界框来提取ROI。
-
网络架构和输出:
- 网络采用编码器-解码器架构,可以生成d+1 个输出,其中 d 代表二进制顶点编码的长度,额外的一个输出用于预测物体的可见性掩模(object mask)。
- 这样的设计允许网络同时学习顶点编码和物体的边界,有助于更精确地估计姿态。
- 输出的概率值在网络的最终阶段被四舍五入,从而表示离散的顶点编码,这一步骤是为了从网络预测中得到清晰的分类结果。
-
训练数据的渲染:
- 利用物体姿态标注,训练标签被渲染为分层的黑白图,这些图对应于图像坐标中的位置。
- 这种方法确保了每个像素点都有一个明确的顶点编码,以及一个指示该点是否属于物体的二进制掩模。
- 这些分层标签(d 个顶点编码层加上一个可见性掩模层)为网络提供了必要的地面真值(ground truth),使其能够有效学习如何将2D图像映射到3D顶点上。
-
区域兴趣(ROI)处理:
- 网络训练和预测集中于图像中检测到的物体的ROI。
- 通过使用现有的2D检测器确定ROI,然后将这些ROI裁剪并调整到固定的维度H×W。
- 这种处理方式确保了网络只关注物体本身,减少了背景噪声的干扰,同时也减小了处理的数据量,提高了运算效率。
六、模型效果
使用二进制顶点编码进行3D顶点预测,在LM-O数据集测试,看一下实验分析:
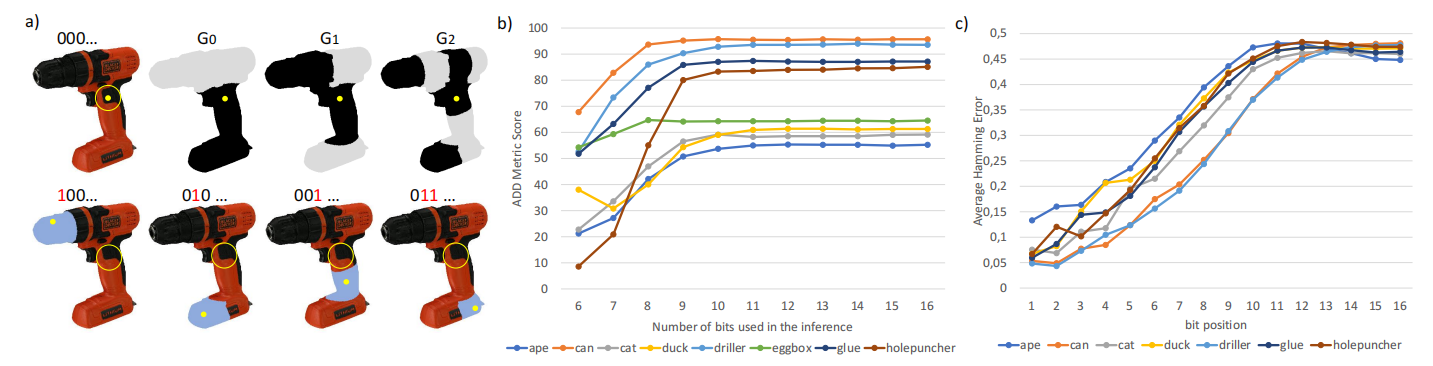
a) 二进制顶点编码的可视化和错误示例
- 左边图顶部行展示了钻机模型上一个特定的顶点(黄点),这个顶点有一个预定的二进制编码(例如000)。
- 如果预测的编码错误(例如100,如红色标记所示),那么黄点的位置会错误地估计在钻机的头部(蓝色标记位置),远离其原始相邻位置。
- 这显示了二进制编码预测的敏感性和精确性,即一个小的错误(一个位的错误)可能导致顶点位置的显著偏差。
b) ADD评分的比较
- 中间图显示了不同位数(从6位到16位)在二进制顶点编码中用于推断时的ADD得分。
- 得分越高,表示姿态估计的精度越高。
- 可以看出,随着位数的增加,大部分对象的ADD得分逐渐趋于稳定,这表明更多的位数能提供更精确的3D顶点预测。
c) 不同位位置的平均错误率
- 右侧图展示了LM-O数据集上不同位位置的平均错误率。
- 图中显示,随着位数的增加,错误率逐渐减少并趋于稳定,这反映了更高位在编码中的增加对于准确性的贡献。
“鸭子”模型在LM-O数据集中的二进制顶点编码,可视化以及预测姿态的实际效果


在LM-O数据集的检测效果:

与 YCB-V数据集上进行比较。以 % 为单位报告 ADD(-S) 的平均召回率,并与最新成果进行比较。
(*) 表示对称对象,(-) 表示原始论文中缺失的结果。
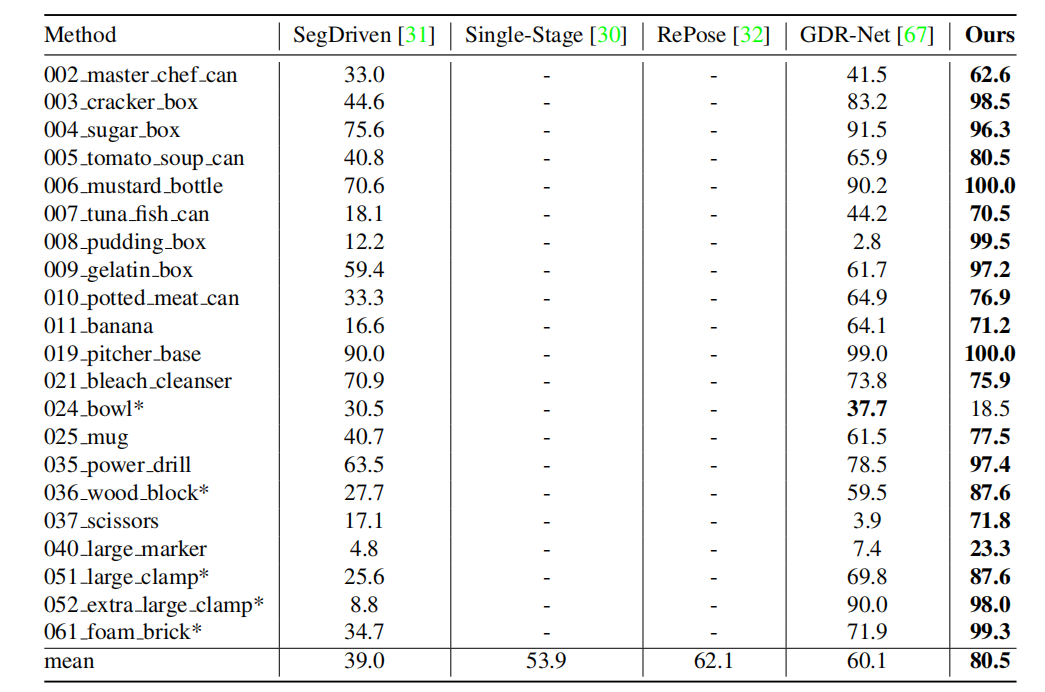
在YCB-V数据集的检测效果:

分享完成~
本文先介绍到这里,后面会分享“6D位姿估计”的其它数据集、算法、代码、具体应用示例。