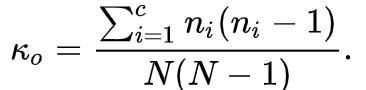Python实现生产者消费者模式的多线程爬虫
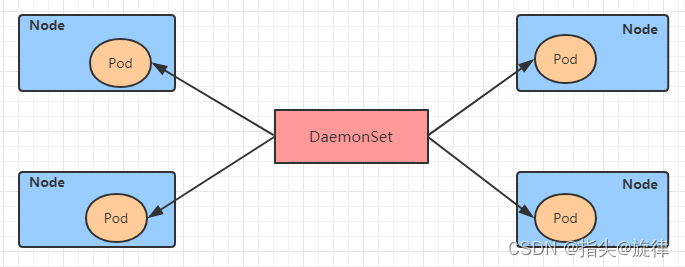
- 1. 多组件的Pipeline技术架构
- 2. 生产者消费者爬虫的架构
- 3.多线程数据通信的queue.Queue
- 4. 代码编写实现生产者消费者爬虫
1. 多组件的Pipeline技术架构
- 复杂的事情一般都不会一下子做完,而是会分很多中间步骤一步步完成。
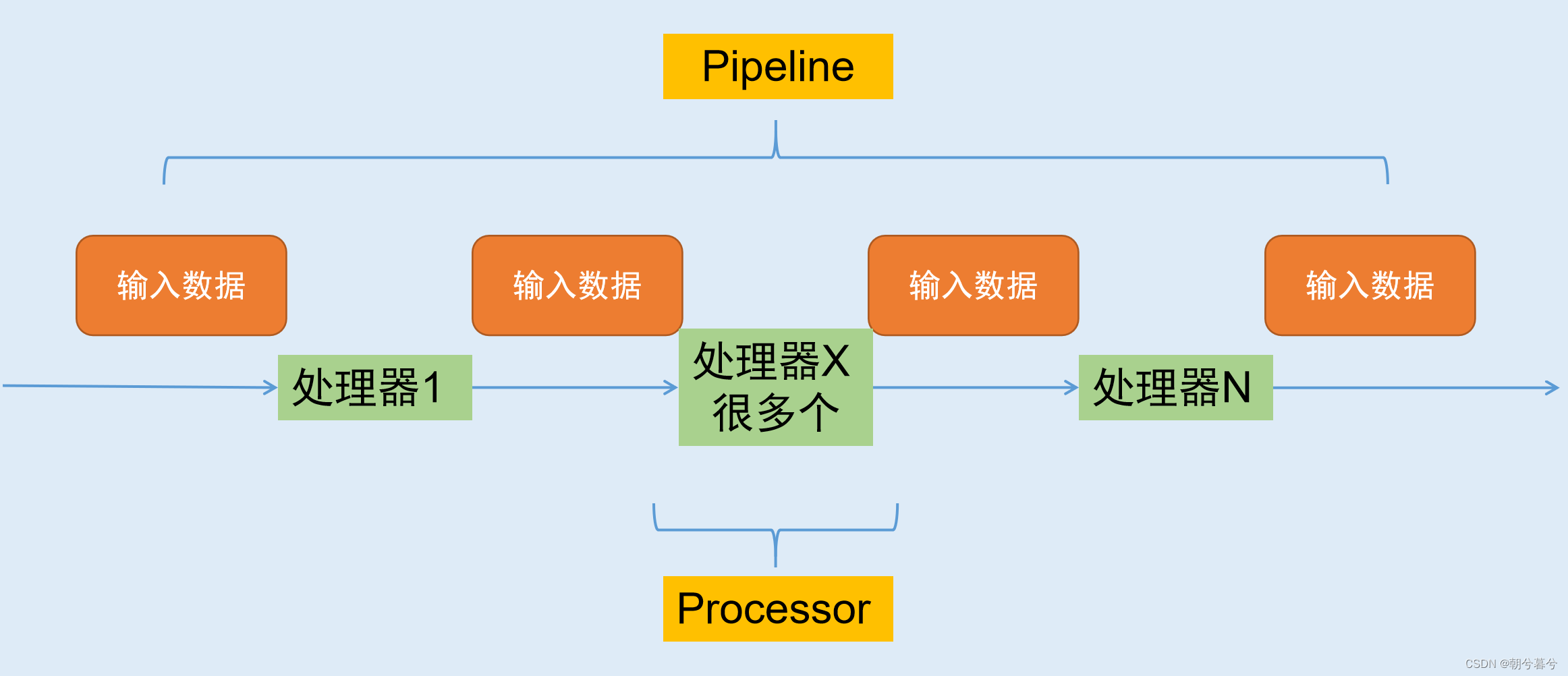
2. 生产者消费者爬虫的架构
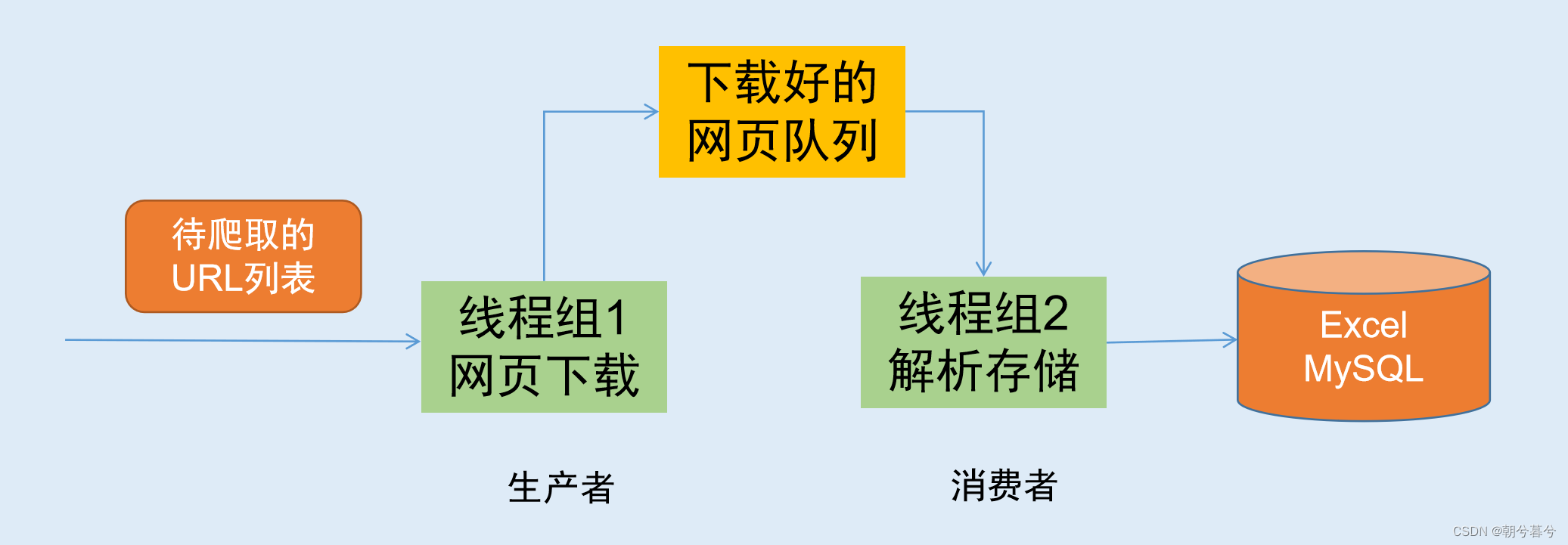
- 根据需求,按照上面设计的架构,程序可以由两拨人开发,生产者组和消费者组,这样的架构设计,可以大大提高效率。
3.多线程数据通信的queue.Queue
- queue.Queue可以用于多线程之间的、线程安全的数据通信
1.导入类库 import queue 2.创建Queue q = queue.Queue() 3. 添加元素 q.put(item) 4. 获取元素 item = q.get() 5. 查询状态 # 查看元素的多少(个数) q.size() # 判断是否为空 q.empty() # 判断是否已满 q.full()
4. 代码编写实现生产者消费者爬虫
-
还是抓取博客信息,包括两部分内容:网址链接和标题内容。
-
下面第一步,先建立一个包含生产者和消费者的模型,对某博客信息进行分析。
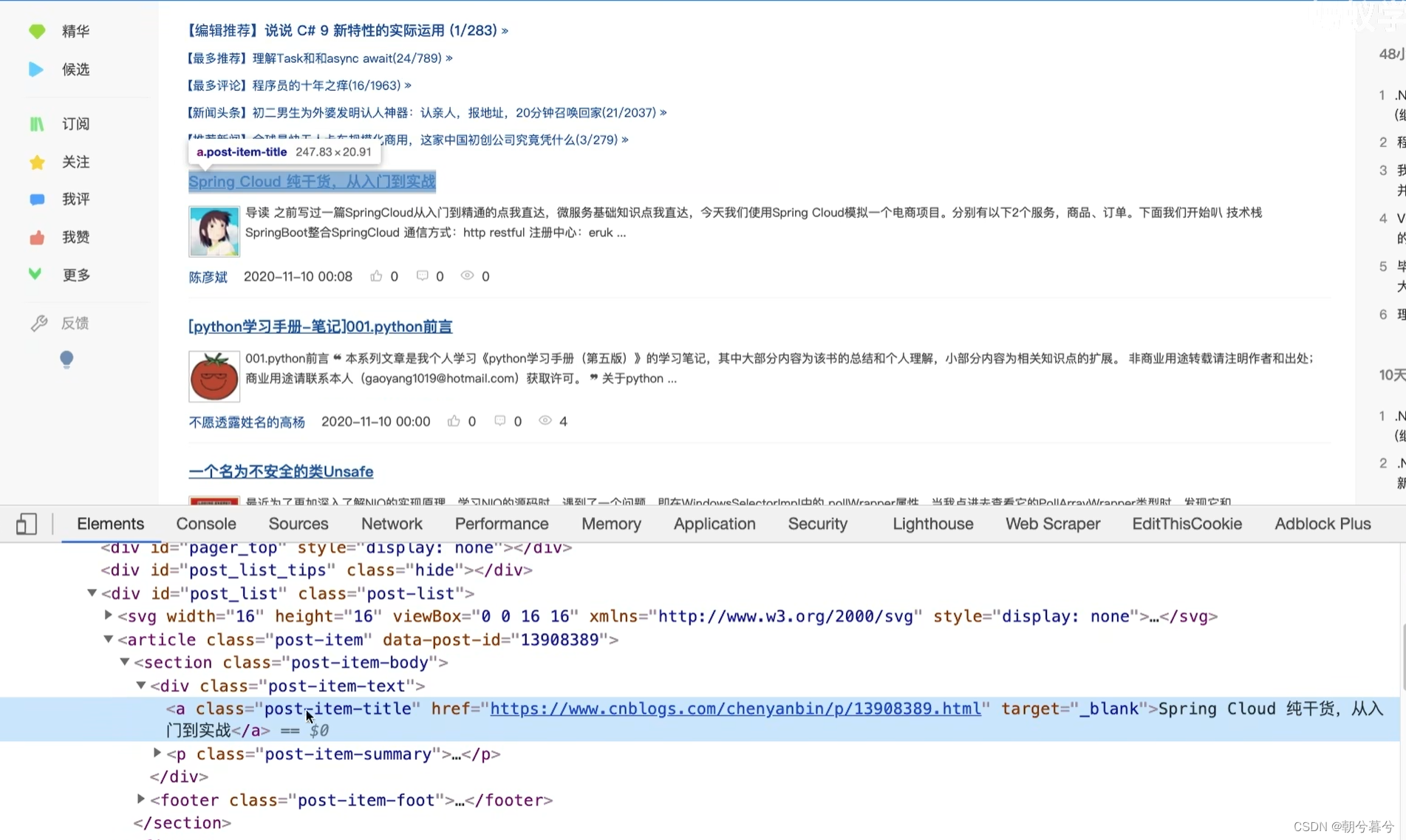
# 这是blogSpider.py import requests from bs4 import BeautifulSoup urls = [ f"https://www.cnblogs.com/#p{page}" for page in range(1,51) ] # 生产者 def draw(url): r = requests.get(url) return r.text # 消费者 def parse(html): # class="post-item-title" # html.parser类似lxml的一个解析库的功能模块 soup = BeautifulSoup(html, "html.parser") links = soup.find_all("a", class_="post-item-title") # 用推导式收集博客文章的链接href和标题内容,并返回 return [(link["href"],link.get_text()) for link in links ] if __name__ == "__main__": # for循环遍历解析(parse)所有爬取(draw)的网页信息,得到文章链接与标题 for result in parse(draw(urls[2])): print(result)- 运行结果如下。
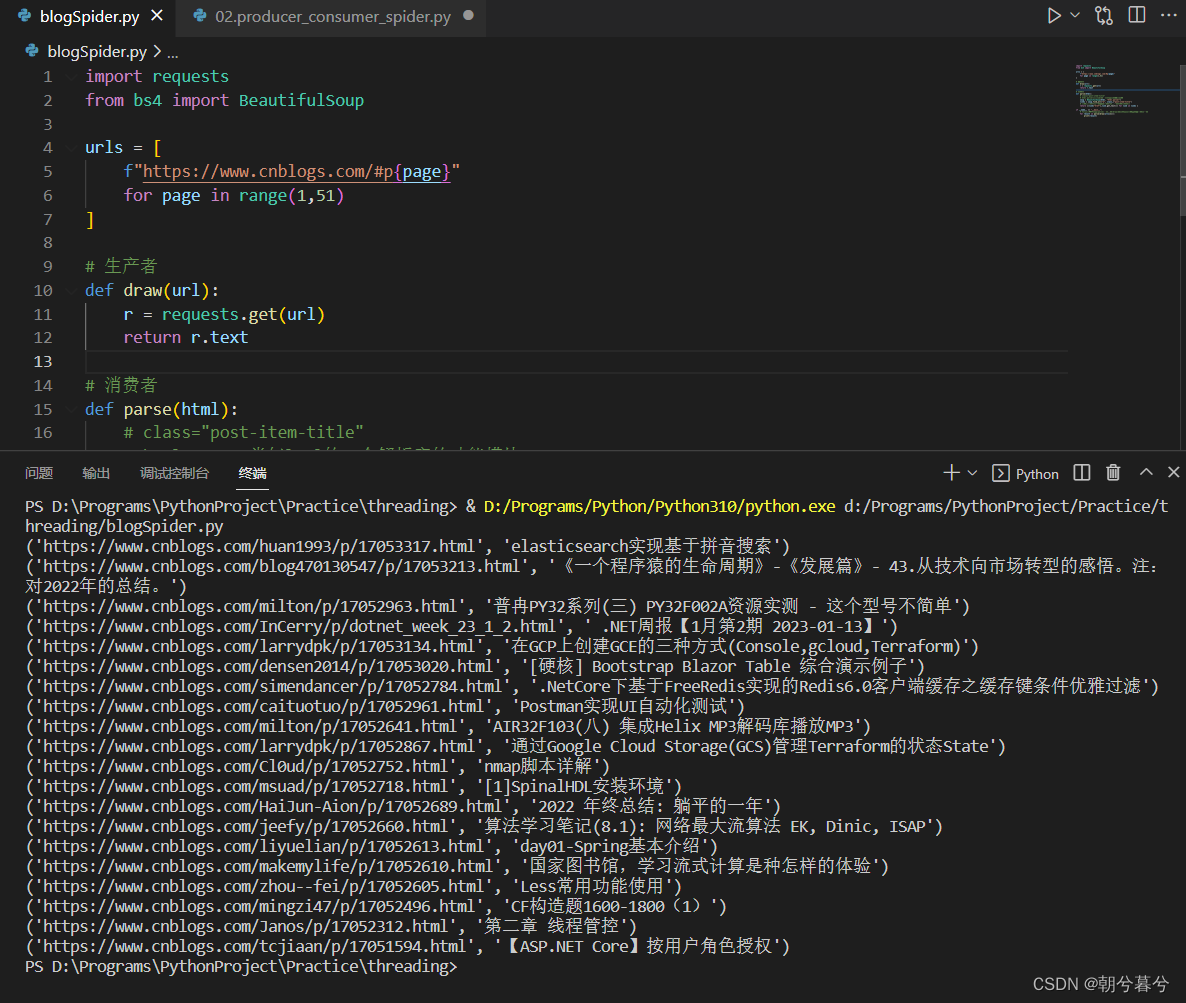
- 运行结果如下。
-
接着第二步,再建立队列,来进一步控制线程通信
import queue import blogSpider import time import random import threading ''' 1、生产者使用队列控制线程通信 # 定义生产者线程用函数的同时,设置两个参数并表明都是Queue队列类型 # url_queue里面放了网址,html_queue里面放了网页源代码 # 这里get相当于生产,然后用html_queue.put(html)为后面消费做了准备 ''' def do_draw(url_queue: queue.Queue, html_queue: queue.Queue): while True: # 从总网页源代码中爬取并得到网址(从队列中取出一个元素) url = url_queue.get() # 调用前面blogSpider模块里面的draw方法得到网页内容(源代码) html = blogSpider.draw(url) # 把源代码放入html_queue队列,以备后面的消费者使用 html_queue.put(html) # 打印显示线程名字、网址、和网址长度信息,随着后面的消费显示越来越少 print(threading.current_thread().name, f"{url}", "url_queue.size=", url_queue.qsize()) # 在1秒到2秒时间内随机休眠 time.sleep(random.randint(1, 2)) ''' 2、消费者使用队列控制线程通信 # 定义消费者线程用函数的同时,设置两个参数并表明都是Queue队列类型 # 参数html_queue里面放了网址源代码(这是由生产者代码里面放入的),形成了放有网页源代码的列表 # 参数fout是存放文本的文件,放了解析出来的结果,并以字符串的形式写入 # 下面parse一组等于消费一个 ''' def do_parse(html_queue: queue.Queue, fout): while True: # 从所有解析出来的网页源代码中获取一份(从队列中取出一个元素) html = html_queue.get() # 调用前面blogSpider模块里面的parse方法得到网页地址和网页内容(标题信息) results = blogSpider.parse(html) # 遍历results列表并写入fout磁盘文本文件 for result in results: fout.write(str(result) + "\n") # 打印输出包含“网页地址和网页内容”的结果集的个数和长度,显示越来越少 print(threading.current_thread().name, f"results.size=", len(results), "html_queue.size=", html_queue.qsize()) # 在1秒到2秒时间内随机休眠 time.sleep(random.randint(1, 2)) if __name__ == "__main__": url_queue = queue.Queue() html_queue = queue.Queue() # 这一步很重要,是整个程序的入口,必须遍历网页地址(urls列表),并逐个把url地址放入url_queue队列 for url in blogSpider.urls: url_queue.put(url) # 建立三个线程作为生产者开始生产 for i in range(3): t = threading.Thread(target=do_draw, args=(url_queue, html_queue), name=f"draw{i}") t.start() # 建立三个线程作为消费者开始消费 fouts = open("02.data.txt", "w") for i in range(2): t = threading.Thread(target=do_parse, args=(html_queue, fouts), name=f"parse{i}") t.start()- 运行结果
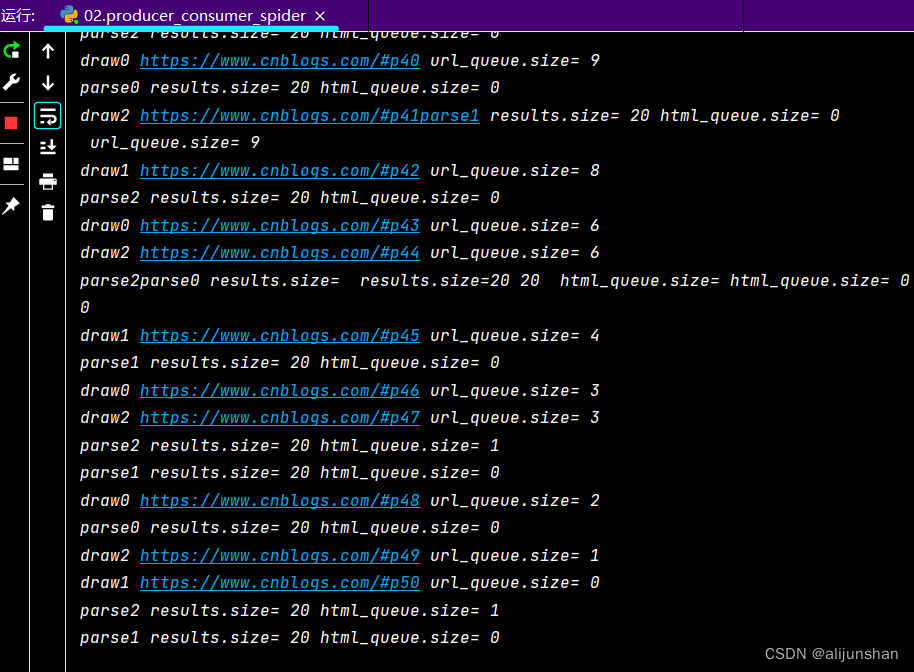
- 上面代码主程序中,有3个生产者线程和2个消费者线程,这两个数字可以分别改动一下看看,会出现什么效果,结合程序代码中的注释,慢慢理解。
- 运行结果