从爱上自己那天起,人生才真正开始
—— 24.5.6
为什么学习pandas
numpy已经可以帮助我们进行数据的处理了,那么学习pandas的目的是什么呢?
numpy能够帮助我们处理的是数值型的数据,当然在数据分析中除了数值型的数据还有好多其他类型的数据(字符串时间序列),那么pandas就可以帮我们很好的处理除了数值型的其他数据!
什么是pandas?
首先先来认识pandas中的两个常用的类
Series
DataFrame
Series类
Series是一种类似与一维数组的对象,由下面两个部分组成:
values:一组数据(ndarray类型)
index:相关的数据索引标签Series的创建
由列表创建
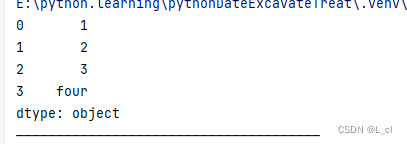
from pandas import Series # Series的创建 # 由列表创建 s1 = Series(data=[1,2,3,"four"]) print(s1) print("——————————————————————————————————————")
由numpy数组创建
# 由numpy数组创建 import numpy as np s2 = Series(data=np.random.randint(0,100,size=(3))) print(s2) print("——————————————————————————————————————")
index参数用来指定显示索引的 默认的0,1,2,3为隐式索引
# index参数用来指定显示索引的 默认的0,1,2,3为隐式索引 s3 = Series(data=[1,2,3,"four"],index=['a','b','c','d']) print(s3) print("——————————————————————————————————————")
由字典创建为什么需要有显示索引?
显示索引可以增强series的可读性
# 由字典创建 dic = { '语文':99, '数学':100, '英语':100 } s4 = Series(data=dic) print(s4) print("——————————————————————————————————————")
Seires的索引和切片
dic = { '语文':99, '数学':100, '英语':100 } s4 = Series(data=dic) print(s4) print("——————————————————————————————————————") # 索引 print(s4[0]) print(s4.语文) # 切片 print(s4[0:2])
Series的常用属性
shape:返回数组的形状
size:返回数组元素的个数
index:返回数组的索引
values:返回存储的元素值
# shape:返回数组的形状 ize:返回数组元素的个数 index:返回数组的索引 values:返回存储的元素值 s = Series(data=[1,1,4,"一切都会好的","我一直相信"]) print(f"s.shape={s.shape}") print(f"s.size={s.size}") print(f"s.index={s.index}") print(f"s.values={s.values}") print(f"s.dtype={s.dtype}")
Series的常用方法
head(),tail()
# 导包 import numpy as np from pandas import Series # 创建Series数组对象 s = Series(data=np.random.randint(60,100,size=(10,))) # head() 显示前n个数组元素,n默认为5 print(f"s={s}") print(f"s.head()={s.head()}") # 显示数组中前n个对象,默认n是5 print("s.head(2)={s.head(2)}") print("——————————————————————————————————————") # tail() 显示后n个数组元素,n默认为5 print(f"s={s}") print(f"s.tail()={s.tail()}") # 显示数组中后n个对象,默认n是5 print("s.tail(2)={s.tail(2)}") print("——————————————————————————————————————")
unique()
# 导包 import numpy as np from pandas import Series # 创建Series数组对象 s = Series(data=np.random.randint(60,100,size=(10,))) # unique()去重,去除重复的数据 print(f"s={s}") print(f"s.unique()={s.unique()}") print("——————————————————————————————————————")
isnull(),notnull()
# 导包 import numpy as np from pandas import Series # 创建Series数组对象 s = Series(data=np.random.randint(60,100,size=(10,))) # isnull 用于判断每个元素是否为空 如果为空返回true,否则返回false print(f"s.isnull()={s.isnull()}") print("——————————————————————————————————————") # notnull 用于判断每个元素是否不为空 如果不为空返回true,否则返回false print(f"s.notnull()={s.notnull()}") print("——————————————————————————————————————")
add()加法、 sub()减法、 mul()乘法、 div()除法
Seriese的算术法则
—— 法则:索引一致的元素进行算术运算否则补空
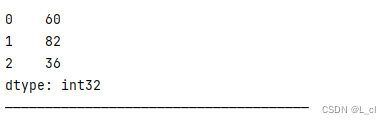
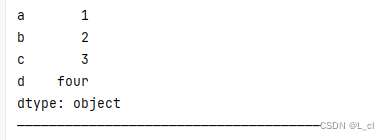
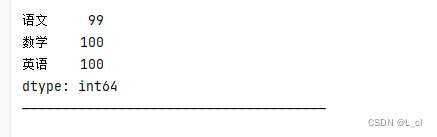






DataFrame类
DataFrame是一个【表格型】的数据结构。DataFrame由按一定顺序排列的多列数据组成。设计初衷是将Series的使用场景从一维拓展到多维。DataFrame既有行索引,也有列索引。
行索引:index
列索引:columns
索引所对的值:valuesDataFrame的创建
ndarray创建
# 导包 from pandas import DataFrame import numpy as np # DataFrame的创建 # ndarray创建 df1 = DataFrame(data=[[1,2,3],[4,5,6]]) print(df1) df2 = DataFrame(data=np.random.randint(0,100,size=(6,4))) print(df2)
字典创建
# DataFrame的创建 # 字典创建 dic = { 'name':["张三","李四","王老五"], "salary":[1000,2000,3000] } df3 = DataFrame(data=dic) print(df3)
DataFrame的属性
values: 二维数组存储的数据
columns:返回列索引
index:返回行索引
shape:返回形状(几行几列)
# 导包 from pandas import DataFrame import numpy as np # DataFrame的创建 # ndarray创建 df = DataFrame(data=np.random.randint(0,100,size=(6,4))) print(df) print(df.values) print(df.index) print(df.columns) print(df.shape) print(df.dtypes)
练习
根据以下考试成绩表,创建一个DataFrame,命名为df:
张三 李四语文 150 0
数学 150 0
英语 150 0
理综 300 0# 导包 from pandas import DataFrame import numpy as np dic = { "张三":[150,150,150,300], "李四":[0,0,0,0] } df = DataFrame(data=dic,index=["语文","数学","英语","理综"]) print(df)
DataFrame索引操作
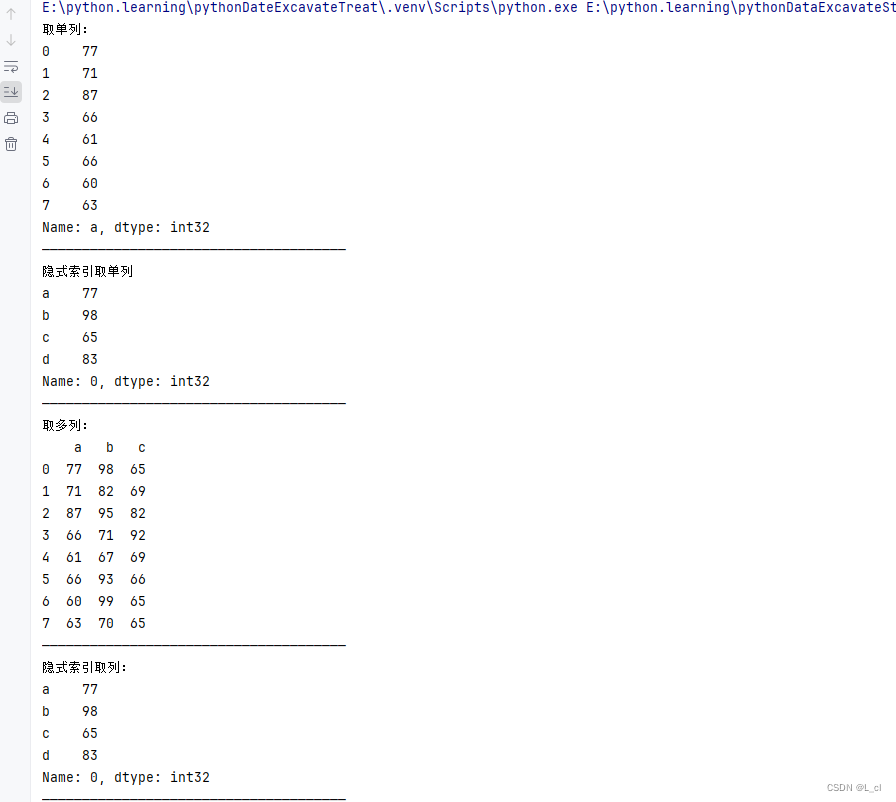
对行进行索引,取列
# 导包 from pandas import DataFrame import numpy as np # DataFrame索引操作 # 创建数据源 # 行索引是显示的,列索引是隐式的 列索引是显示的:a、b、c、d df = DataFrame(data=np.random.randint(60,100,size=(8,4)),columns=['a','b','c','d']) print("取单列:") # 对行进行索引 # 取单列,如果df有显示的索引,通过索引机制取行或者列的时候只能使用显示索引 print(df['a']) print("——————————————————————————————————————") # 用隐式索引取单列 print("隐式索引取单列") print(df.iloc[0]) print("——————————————————————————————————————") # 取多列 需要两个中括号 print("取多列:") print(df[['a','b','c']]) print("——————————————————————————————————————") # 通过隐式索引取列 print("隐式索引取列:") print(df.iloc[0]) print("——————————————————————————————————————")
对列进行索引,取行
# 导包 from pandas import DataFrame import numpy as np # DataFrame索引操作 # 创建数据源 # 行索引是显示的,列索引是隐式的 列索引是显示的:a、b、c、d df = DataFrame(data=np.random.randint(60,100,size=(8,4)),columns=['a','b','c','d']) # 对列进行索引 # 隐式索引取单行 print("隐式索引取单行:") print(df.iloc[0]) print("——————————————————————————————————————") # 取多行 需要两个中括号 # 隐式索引取多行 print("隐式索引取多行:") print(df.iloc[[0,3,5]]) print("——————————————————————————————————————") # 显示索引取单行 print("显式索引取单行:") print(df.loc[0]) # 显示索引取多行 # 由于数组没有显示索引,所以iloc和loc都可以求隐式索引,如果数组中有显示索引,loc后面只能跟显示索引不能跟隐式索引 print("显式索引取多行:") print(df.iloc[[0,3,5]]) print("——————————————————————————————————————")
对元素进行索引
# 导包 from pandas import DataFrame import numpy as np # DataFrame索引操作 # 创建数据源 # 行索引是显示的,列索引是隐式的 列索引是显示的:a、b、c、d df = DataFrame(data=np.random.randint(60,100,size=(8,4)),columns=['a','b','c','d']) # 对元素进行索引 print("对元素进行索引") print("取单个元素") print(df.iloc[0,2]) print(df.loc[0,'a']) print("——————————————————————————————————————") print("取多个元素") print(df.iloc[[1, 3, 5], 2])
—— iloc:
通过隐式索引取行
—— loc:
通过显示索引取行
总结
df索引和切片操作
索引:
df[col]:取列
df.loc[index]:取行
df.iloc[index,col]:取元素切片:
df[index1:index3]:切行df.iloc[:,col1:col3]:切列
DataFrame的运算
—— 同Series运算一致
—— 法则:索引一致的元素进行算术运算否则补空
add()加法、 sub()减法、 mul()乘法、 div()除法
练习
1.假设ddd是期中考试成绩,ddd2是期末考试成绩,请自由创建ddd2,并将其与ddd相加,求期中期末平均值。
2.假设张三期中考试数学被发现作弊,要记为0分,如何实现?
3.李四因为举报张三作弊立功,期中考试所有科目加100分,如何实现?
4.后来老师发现有一道题出错了,为了安抚学生情绪,给每位学生每个科目都加10分,如何实现?# 导包 from pandas import DataFrame dic = { "张三":[150,150,150,150], "李四":[0,0,0,0] } # 根据字典创建数组 df=DataFrame(data=dic,index=["语文","数学","英语","理综"]) # 期中考试 MidTest = df # 期末考试 LastTest = df # 期中+期末的平均值 print((MidTest+LastTest)/2) # 张三期中作弊了,将数学分数改为0 MidTest.loc["数学","张三"] = 0 print(MidTest) # 李四举报张三,将李四所有成绩+100 MidTest["李四"] += 100 print(MidTest) # 后来老师发现有一道题出错了,为了安抚学生情绪,给每位学生每个科目都加10分 MidTest += 10 print(MidTest)
时间数据类型的转换
pd.to_datetime(col)将某一列
# 导包 from pandas import DataFrame import pandas as pd dic = { 'time':["2010-10-10","2011-11-20","2020-1-10"], "temp":[33,31,30] } df = DataFrame(data=dic) print(df) # 查看time列的类型 print(df["time"].dtype) print("————————————————————————————————————") # 将time列的数据类型转换成时间序列类型 df['time'] = pd.to_datetime(df["time"]) print(df) print(df['time'].dtype) print("————————————————————————————————————")
设置为行索引
df.set_index(
# 导包 from pandas import DataFrame import pandas as pd dic = { 'time':["2010-10-10","2011-11-20","2020-1-10"], "temp":[33,31,30] } df = DataFrame(data=dic) print(df) # 将time列作为原数据的行索引,替换10,1,2 df.set_index('time', inplace=True) print(df)
















![【Osek网络管理测试】[TG3_TC1]Limphome复位_NM报文](https://img-blog.csdnimg.cn/direct/bb629041c7714bfd9a0ca34f2fe0c1a4.png)