文章目录
- 第1关:多级索引的取值与切片
- 第2关:多级索引的数据转换与累计方法
第1关:多级索引的取值与切片
编程要求
本关的编程任务是补全右侧上部代码编辑区内的相应代码,要求实现如下功能:
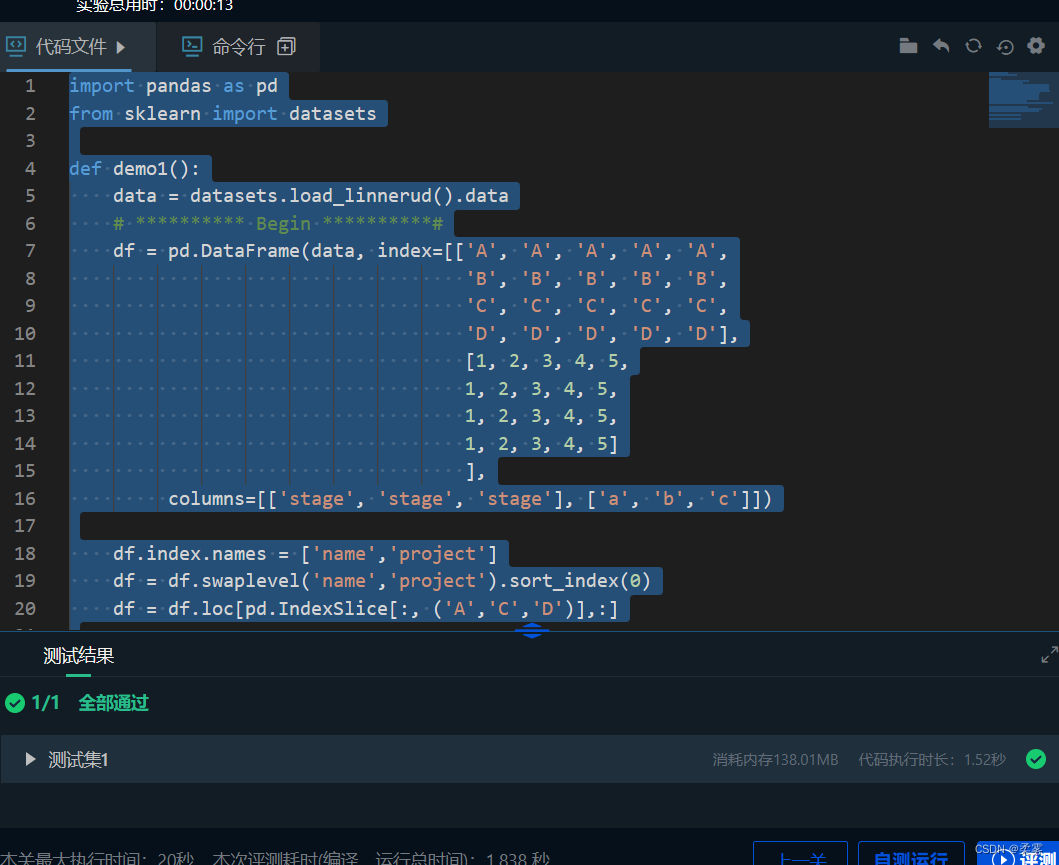
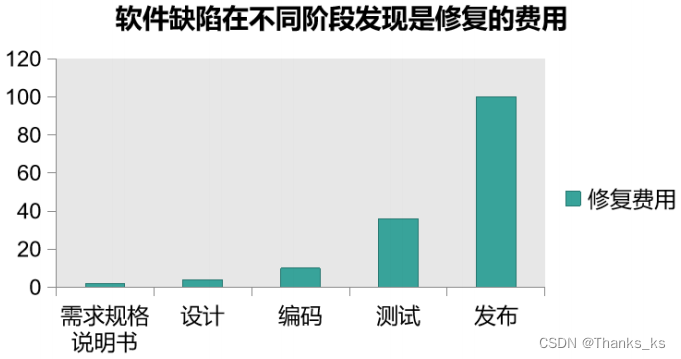
使用MultiIndex创建如下DataFrame多级索引:
然后通过转置、stack()方法得到以下数据:
最后通过取值和切片得到目标数据:
具体要求请参见后续测试样例。
请先仔细阅读右侧上部代码编辑区内给出的代码框架,再开始你的编程工作!
测试说明
平台会对你编写的代码进行测试,对比你输出的数值与实际正确的数值,只有所有数据全部计算正确才能进入下一关。
测试输入:
无测试输入
平台会对你编写的代码进行测试:
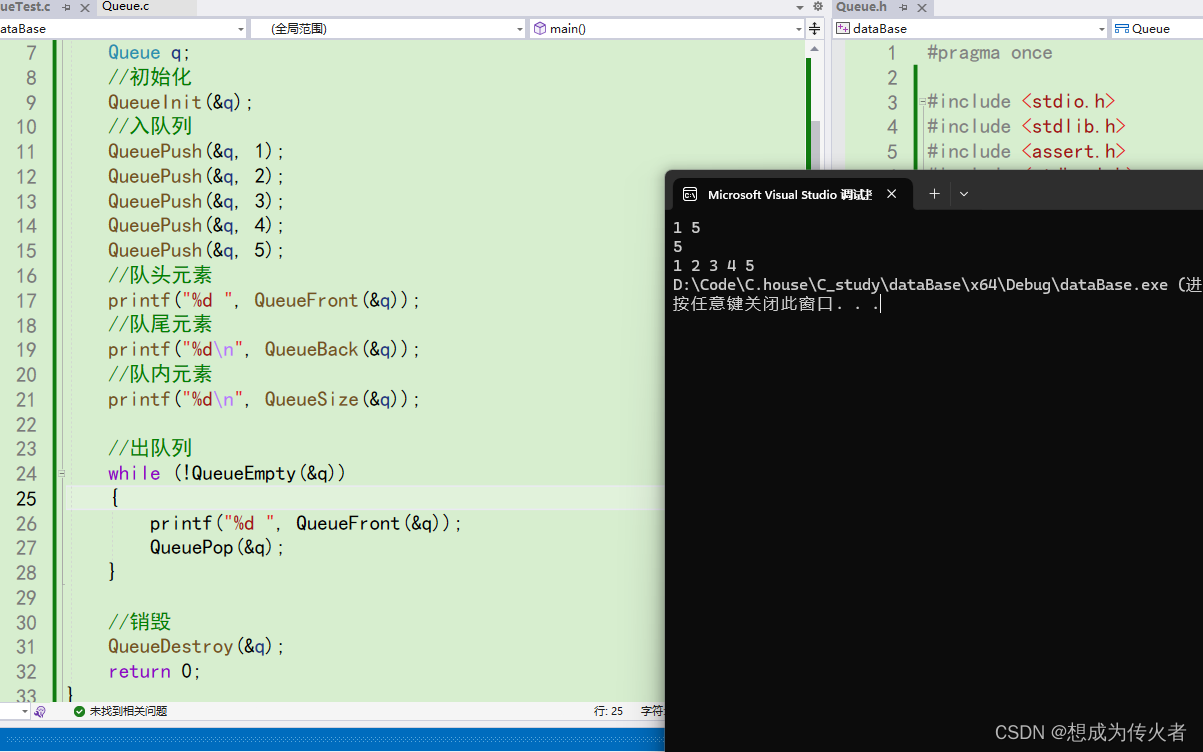
预期输出:
开始你的任务吧,祝你成功!
示例代码如下:
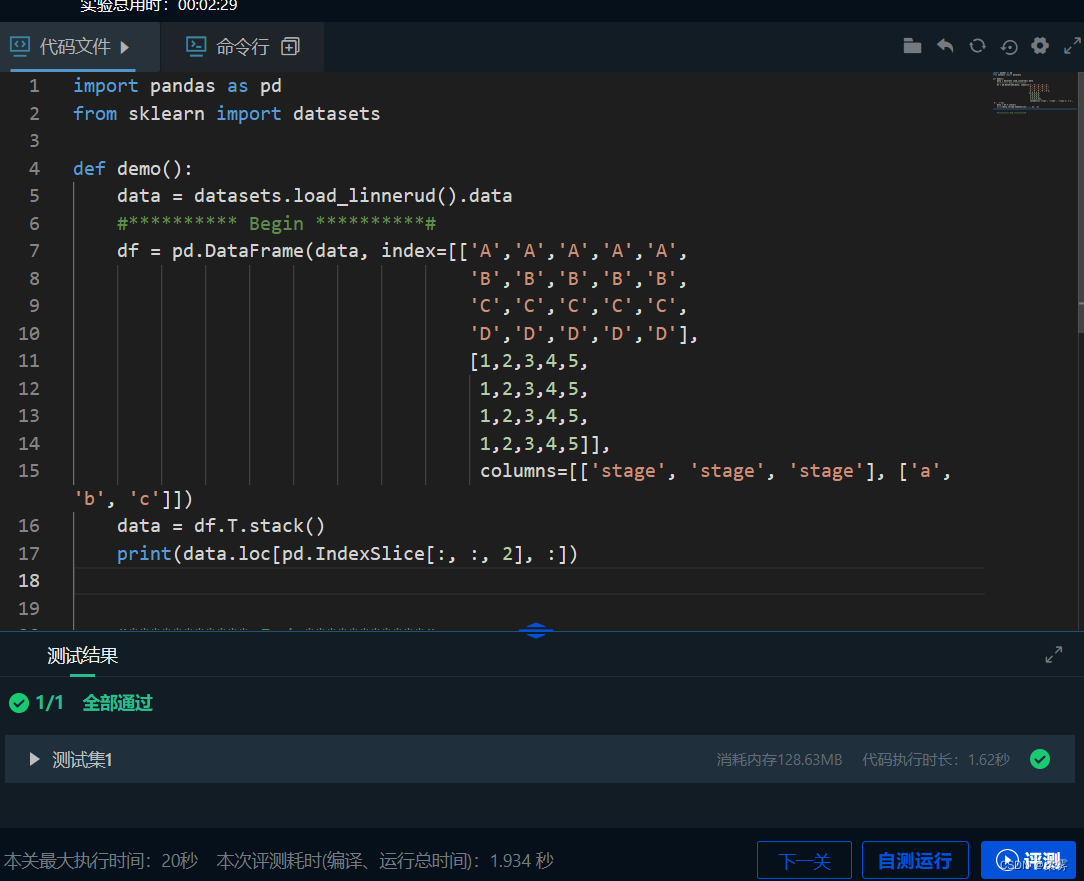
import pandas as pd
from sklearn import datasets
def demo():
data = datasets.load_linnerud().data
#********** Begin **********#
df = pd.DataFrame(data, index=[['A','A','A','A','A',
'B','B','B','B','B',
'C','C','C','C','C',
'D','D','D','D','D'],
[1,2,3,4,5,
1,2,3,4,5,
1,2,3,4,5,
1,2,3,4,5]],
columns=[['stage', 'stage', 'stage'], ['a', 'b', 'c']])
data = df.T.stack()
print(data.loc[pd.IndexSlice[:, :, 2], :])
#*********** End ***********#
第2关:多级索引的数据转换与累计方法
编程要求
本关的编程任务是补全右侧上部代码编辑区内的相应代码,要求实现如下功能:
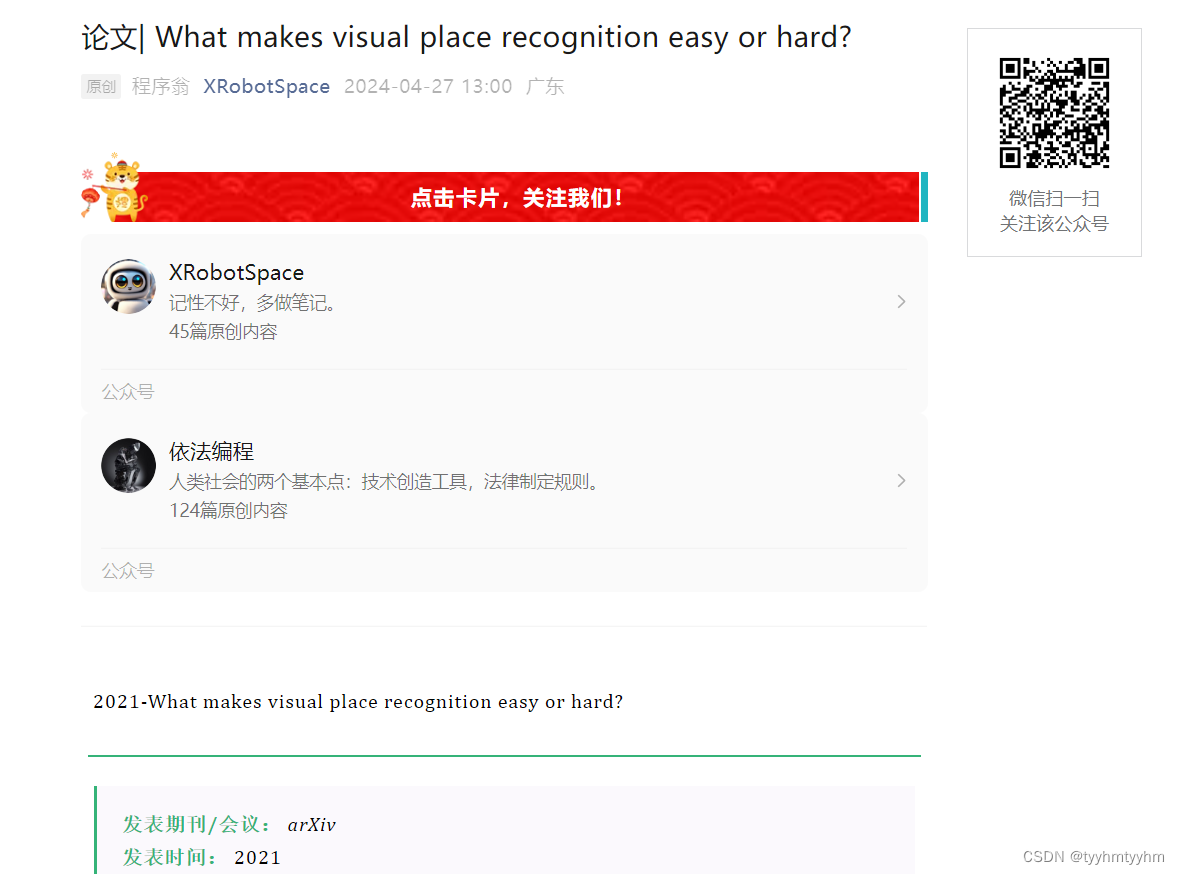
创建如下图所示DataFrame多级索引:
给索引设置等级名称name为[“name”,“project”];
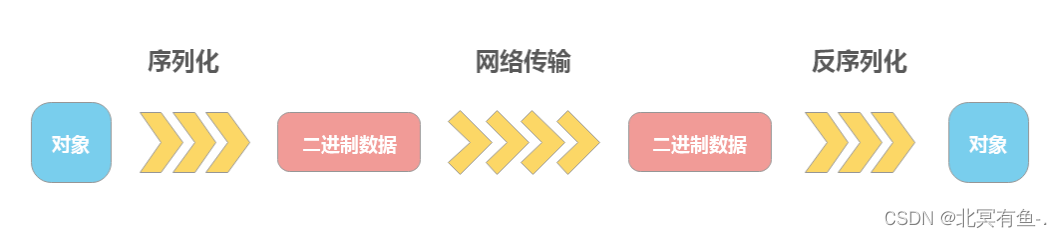
然后交换多级索引的等级顺序,得到如下多级索引:
取二级索引为A、C、D的行,得到以下数据:
最后获取level="name"的均值,并输出;
具体要求请参见后续测试样例。
请先仔细阅读右侧上部代码编辑区内给出的代码框架,再开始你的编程工作!
测试说明
平台会对你编写的代码进行测试,对比你输出的数值与实际正确的数值,只有所有数据全部计算正确才能进入下一关。
测试输入:
无测试输入
预期输出:
stage
a b c
name
A 8.8 126.6 63.2
C 10.2 133.0 67.8
D 8.8 167.0 68.2
开始你的任务吧,祝你成功!
示例代码如下:
import pandas as pd
from sklearn import datasets
def demo1():
data = datasets.load_linnerud().data
# ********** Begin **********#
df = pd.DataFrame(data, index=[['A', 'A', 'A', 'A', 'A',
'B', 'B', 'B', 'B', 'B',
'C', 'C', 'C', 'C', 'C',
'D', 'D', 'D', 'D', 'D'],
[1, 2, 3, 4, 5,
1, 2, 3, 4, 5,
1, 2, 3, 4, 5,
1, 2, 3, 4, 5]
],
columns=[['stage', 'stage', 'stage'], ['a', 'b', 'c']])
df.index.names = ['name','project']
df = df.swaplevel('name','project').sort_index(0)
df = df.loc[pd.IndexSlice[:, ('A','C','D')],:]
print(df.mean(level='name'))
# ********** End **********#