目录
1. list 的实现框架
2. push_back
3. 迭代器
4. constructor
4.1. default
4.2. fill
4.3. range
4.4. initializer list
5. insert
6. erase
7. clear 和 destructor
8. copy constructor
9. operator=
10. const_iterator
10.1. 普通人的处理方案
10.2. SGI-STL的处理方案
11. operator->
12. reverse_iterator
1. list 的实现框架
namespace Xq
{
template <class T>
struct list_node
{
T _data;
list_node<T>* _left;
list_node<T>* _right;
// default
list_node(const T& x = T())
:_data(x)
, _prev(nullptr)
, _next(nullptr)
{}
};
// 带头双向循环链表
template<class T>
class list
{
private:
typedef list_node<T> Node;
public:
private:
Node* _head; // 哨兵位头节点
};
}2. push_back
先搭个架子,跑起来再说,push_back 的实现很简单,如下:
// 构造新节点
Node* BuildNewNode(const T& val)
{
Node* newnode = new Node(val);
return newnode;
}
// 尾插
void push_back(const T& val)
{
// 1. 构造新节点
Node* newnode = BuildNewNode(val);
// 2. 找尾
Node* tail = _head->_prev;
// 3. 添加新节点
tail->_next = newnode;
newnode->_prev = tail;
newnode->_next = _head;
_head->_prev = newnode;
}测试代码如下:
void Test1(void)
{
Xq::list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
}可是我们发现一个问题,这咋遍历呢? 难道说,像C语言一样,写个 Print 函数,这也太挫了,因此,我们用容器统一访问元素的方式,通过迭代器访问,如下:
void Test1(void)
{
Xq::list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
Xq::list<int>::iterator it = lt.begin();
while (it != lt.end())
{
std::cout << *it << " ";
++it;
}
std::cout << std::endl;
}那么这个迭代器如何实现呢?
3. 迭代器
首先,在 string 和 vector 的模拟实现中,我们也使用过迭代器,但是它们两个的迭代器很特殊,因为它们存储的元素的地址是连续的,因此,它们的迭代器本质上就是原生指针,那 list 这里能不能也是原生指针呢?
答案:不可以,因为 list 底层的元素的地址可不是连续的,因此,不能是原生指针。
对于 string 和 vector, 因为存储的元素是连续存储的,故可以使用原生指针,同时,原生指针可以满足需求。
对于 list 来说,存储的元素的地址不是连续的,因此,不能使用原生指针,但是 list 又要求能够遍历元素,而元素就是一个一个的节点,即Node*,要遍历元素本质上就是要从当前节点去到下一个节点,既要重载 ++,-- 等操作,可是我们知道,指针属于内置类型,无法重载,因此只能将 Node* 封装到一个类中,这个类,人们起了一个名字,叫迭代器,通过重载迭代器这个类的 ++、-- 等操作,使得可以遍历节点,一般而言,这个自定义类型 (迭代器) 需要满足下面的操作:
加加 (++)、减减 (--)、解引用 (*)、访问成员 (->)、等于 (==)、不等于 (!=) 。
首先这个迭代器的框架如下:
template <class T>
struct list_iterator
{
typedef list_node<T> Node;
Node* _node;
// 下面就是迭代器所要支持的操作:
// 加加 (++)、减减 (--)、解引用 (*)、
// 访问成员 (->)、等于 (==)、不等于 (!=)
};实现如下:
template <class T>
struct list_iterator
{
typedef list_node<T> Node;
Node* _node;
list_iterator(Node* node = nullptr): _node(node) {}
// 前置++, ++it
list_iterator& operator++()
{
_node = _node->_next;
return *this;
}
// 后置++, it++
list_iterator operator++(int)
{
// 后置++返回调用前的状态, 因此这里需要构造一个临时对象, 故只能传值返回
// a. 可以使用构造一个迭代器
// list_iterator ret(_node);
// b. 也可以使用拷贝构造, 在这里, 默认生成的拷贝构造就满足需求
// 因为在list_iterator类中,不需要释放这些资源 (_node),默认的析构不会对内置做处理
list_iterator ret(*this);
_node = _node->_next;
return ret;
}
// 前置--, --it;
list_iterator& operator--()
{
_node = _node->_prev;
return *this;
}
// 后置--, it--
list_iterator operator--(int)
{
// 与后置++一个思路, 但在这里使用构造函数
list_iterator ret(_node);
_node = _node->_prevc;
return ret;
}
// *this != it;
bool operator!=(const list_iterator& it)
{
return _node != it._node;
}
// *this == it;
bool operator==(const list_iterator& it)
{
return _node == it._node;
}
// 返回对象的引用
T& operator*()
{
return _node->_data;
}
// 返回对象的地址
T* operator->()
{
// 复用 operator*
return &(operator*());
}
};有了上面,还不足以支持用迭代器遍历数据,容器 (list) 自身也需要提供 begin、end等一些列函数,begin 和 end 在 list 中的位置如下:
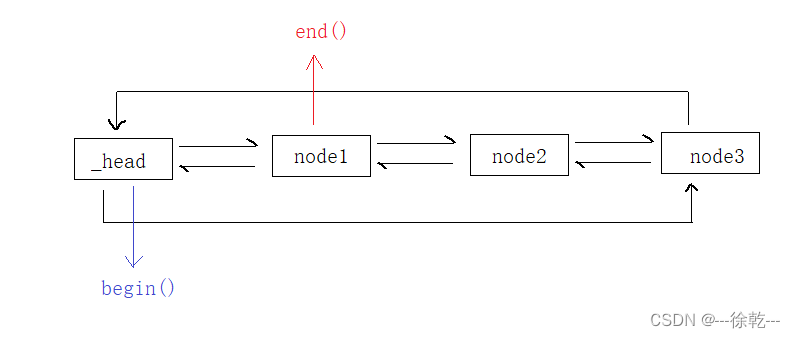
下面是一些 list::begin 和 list::end 的相关实现:
iterator begin()
{
// 用第一个有效元素构造 begin 迭代器
// 这里是单参数隐式类型转换
// 先用节点构造迭代器, 在进行拷贝构造
// 编译器优化为直接构造
return _head->_next;
}
iterator end()
{
// 用最后一个有效元素的下一个位置构造 end 迭代器
// 本质就是 _head
// 这里是单参数隐式类型转换
// 先用节点构造迭代器, 在进行拷贝构造
// 编译器优化为直接构造
return _head;
}有了上面的支持,此时我们就可以用迭代器遍历链表了,测试用例如下:
void Test1(void)
{
Xq::list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
Xq::list<int>::iterator it = lt.begin();
while (it != lt.end())
{
std::cout << *it << " ";
++it;
}
std::cout << std::endl;
}现象如下:

上面是迭代器的初步实现的版本,后续还会有改进。
走到这里,转换一下思路,来实现一些简单的函数,诸如 insert,通过 insert 来实现 push_back,push_front。
4. constructor
4.1. default
// 构造一个哨兵位的头节点
void empty_initialize()
{
_head = BuildNewNode(T());
_head->_next = _head->_prev = _head;
}
// defalut
list()
{
empty_initialize();
}4.2. fill
list(size_t n, const T& val)
{
// 构造哨兵位头节点
empty_initialize();
// 复用push_back
while (n--)
{
push_back(val);
}
}
// 避免和 range constructor 冲突
list(int n, const T& val)
{
// 构造哨兵位头节点
empty_initialize();
// 复用push_back
while (n--)
{
push_back(val);
}
}4.3. range
template<class InputIterator>
list(InputIterator first, InputIterator last)
{
// 构造哨兵位头节点
empty_initialize();
// 通过一段区间构造一个list对象
while (first != last)
{
push_back(*first);
++first;
}
}4.4. initializer list
list(const std::initializer_list<T>& lt)
{
// 构造哨兵位头节点
empty_initialize();
// 复用push_back
for (auto& it : lt)
push_back(it);
}5. insert
实现这种函数,建议通过画图来进行编写代码,这样会事半功倍的,即便出错了,也能通过画图和调试很快锁定错误。

iterator insert(iterator position, const T& val);insert 在 position 位置之前插入特定节点,假如 position 是node3 的位置,先找到 position 位置之前的节点,在链入新节点,同时,返回值就是插入的新节点,如图所示:

代码如下:
iterator insert(iterator pos, const T& val)
{
// 得到pos位置的节点
Node* cur = pos._node;
// 找到pos节点之前的一个节点
Node* cur_prev = cur->_prev;
// 构造新节点
Node* newnode = BuildNewNode(val);
// 将新节点链入到list中
cur_prev->_next = newnode;
newnode->_prev = cur_prev;
newnode->_next = cur;
cur->_prev = newnode;
// 返回新插入的节点
return newnode;
}有了insert,我们就可以通过 insert 实现 push_back 和 push_front。
push_back 是尾插,那么 position 就是在最后一个有效节点的下一个节点,最后一个有效节点的下一个节点不就是 end() 吗?如下所示:
void push_back(const T& val)
{
insert(end(), val);
}push_front是头插,那么 position 就是第一个有效节点,第一个有效节点不就是 begin() 吗?如下所示:
void push_front(const T& val)
{
insert(begin(), val);
}6. erase
iterator erase (iterator position);erase 是删除 position 位置的特定节点,并返回删除节点的下一个节点, 假如 position 是 node2,如下所示:
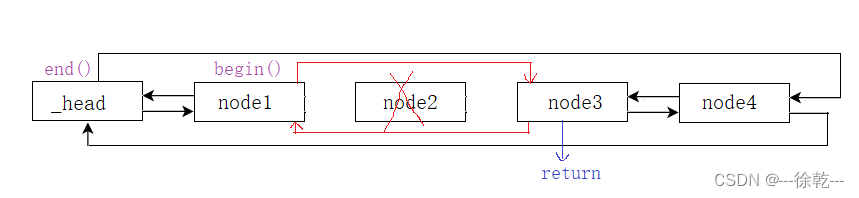
代码如下:
iterator erase(iterator pos)
{
// pos 不能是哨兵位头节点
assert(pos != end());
// 找到要删除的节点
Node* del = pos._node;
// 找到删除节点的前一个节点
Node* del_prev = del->_prev;
// 找到删除节点的后一个节点
Node* del_next = del->_next;
// 将删除节点从list移除
del_prev->_next = del_next;
del_next->_prev = del_prev;
// 释放删除节点, 此时pos就迭代器失效了
delete del;
// 隐式类型转换
return del_next;
}有了erase,pop_back,pop_front 就简单多了。
pop_back,删除最后一个有效节点,那么最后一个有效节点不就是哨兵位头节点的前一个节点吗?如下所示:
void pop_back()
{
// 删除最后一个有效节点
// 隐式类型转换
erase(_head->_prev);
}pop_front,删除第一个有效节点,那么第一个有效节点不就是哨兵位头节点的后一个节点吗?如下所示:
void pop_front()
{
// 删除第一个有效节点
// 隐式类型转换
erase(_head->_next);
}7. clear 和 destructor
clear 就是删除 list 的所有有效节点 (不包括哨兵位头节点),实现如下:
void clear(void)
{
Node* del = _head->_next;
if (del == _head) return;
while (del != _head)
{
Node* next = del->_next;
erase(del);
del = next;
}
}我们也可以用迭代器删除,如下:
void clear(void)
{
iterator it = begin();
while (it != end())
erase(it++);
}destructor 在有了 clear 就简单多了,本质上就是调用 clear 释放所有有效节点,并将 list 的哨兵位头节点释放掉即可,实现如下:
~list()
{
clear();
delete _head;
_head = nullptr;
}8. copy constructor
我们知道,如果我们没有显示定义copy constructor,那么编译器就会默认生成一份,默认生成的对内置类型和自定义类型都会处理,对内置类型按照浅拷贝的方式进行拷贝,对自定义类型会去调用它的copy constructor;对于list<T>来说,编译器默认生成的是不符合需求的的,它会带来两个问题:
- 其中一个对象发生修改,另一个对象也会发生改变;
- 当这两个对象生命周期结束时,会调用析构函数,同一空间被析构两次,进程crash。
其中一个对象发生修改,另一个对象也会发生改变,如下 demo :
void Test4(void)
{
Xq::list<int> lt{ 1, 2, 3, 4 };
Xq::list<int> copy(lt);
std::cout << "original lt:";
for (auto it : lt)
std::cout << it << " ";
std::cout << "\n";
std::cout << "copy modify: ";
for (auto& it : copy)
std::cout << (it *= 2) << " ";
std::cout << "\n";
std::cout << "new lt:";
for (auto it : lt)
std::cout << it << " ";
std::cout << "\n";
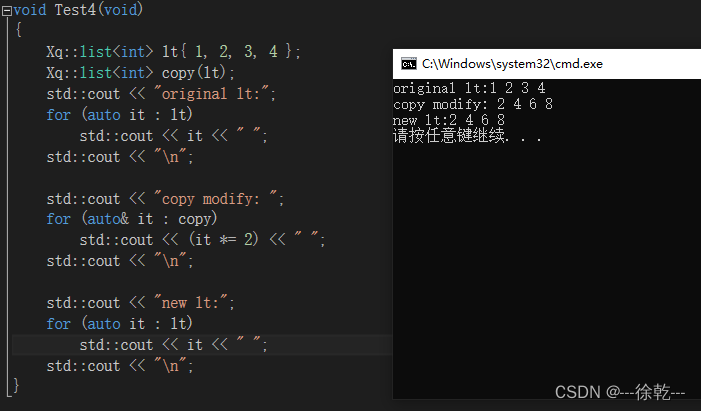
}lt {1, 2, 3, 4},通过 it 拷贝构造得到 copy, copy {1, 2, 3, 4},copy 遍历一遍,每个元素 *= 2,即 copy {2, 4, 6, 8},那么此时 lt 是什么呢?
预期:因为是浅拷贝,此时 lt 也会变为 {2, 4, 6, 8},之所以这里没有崩溃,是因为我将析构给屏蔽了 (即此时析构什么事也不做),现象如下:
符合预期,如果我此时恢复析构函数,那么当这两个对象生命周期结束时,先后调用析构函数,同一空间被析构两次,进程崩溃,现象如下:
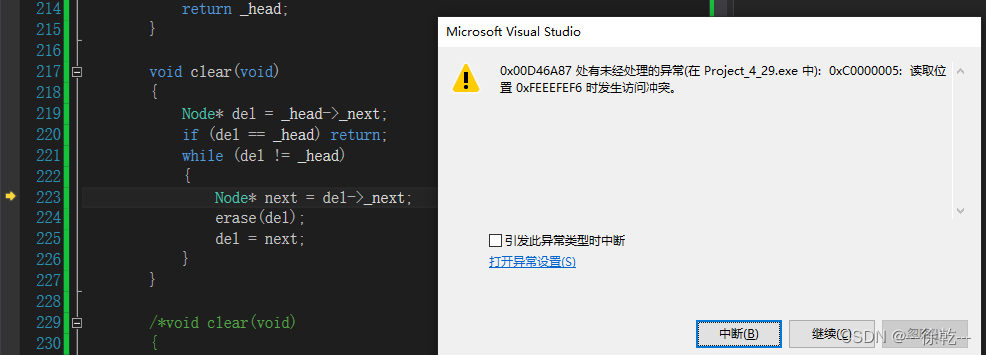
因此,针对 list ,用户需要自身以深拷贝的方式实现拷贝构造,实现如下:
void swap(list<T>& tmp)
{
// 交换两个哨兵位头节点
// 即交换两个list对象
std::swap(_head, tmp._head);
}
template<class InputIterator>
list(InputIterator first, InputIterator last)
{
// 构造哨兵位头节点
empty_initialize();
// 通过一段区间构造一个list对象
while (first != last)
{
push_back(*first);
++first;
}
}
list(const list<T>& copy)
{
// 构造哨兵位头节点
empty_initialize();
// 通过 copy 构造 tmp
list<T> tmp(copy.begin(), copy.end());
// 再和tmp交换哨兵位的头节点
swap(tmp);
// tmp 生命周期结束, 自动调用析构, 释放哨兵位的头节点
}上面这套方案,是不是有点繁琐? 用户也可以采用下面的方案:
list(const list<T>& copy)
{
// 构造哨兵位头节点
empty_initialize();
// 通过迭代器直接复用 push_back
for (const auto& it : copy)
{
push_back(it);
}
}之所以上面可以,是因为有我们之前所做的努力,无非就是复用罢了。
9. operator=
同理,operator=是不是也存在着和拷贝构造同样的问题,因此我们也需要以深拷贝的方式实现operator=,实现如下:
// 在类里面可以不写模板参数,
// 但是建议不管是类外还是类内都把模板参数加上
// void swap(list& copy) // 不建议
// 交换两个list的哨兵位的头节点
void swap(list<T>& copy)
{
std::swap(_head, copy._head);
}
// 利用传值传参的特性 --- 会进行拷贝构造
list<T>& operator=(list<T> copy)
{
// 交换 copy 和 *this 两个list的头节点
swap(copy);
// 返回赋值后的list对象
return *this;
// copy出了函数作用域, 会自动调用析构函数, 释放资源
}10. const_iterator
我们上面不是已经实现了一个迭代器吗,为什么还要有 const_iterator 呢?
上面我们所实现的迭代器称之为普通迭代器,而在一些场景下,普通迭代器不能满足需求,比如下面这个例子:
void print_list(const Xq::list<int>& tmp)
{
Xq::list<int>::iterator it = tmp.begin();
while (it != tmp.end())
{
cout << *it << " ";
++it;
}
cout << endl;
}
void Test5(void)
{
Xq::list<int> lt{ 1, 2, 3, 4 };
print_list(lt);
}因为我们目前没有提供 const 迭代器,上面的代码会编译报错,如下:

那么如何解决呢? 很简单,我们提供一个const迭代器就OK了,但是不同的人会有不同的处理,在这里有两种处理方案:普通人的处理方案和SGI-STL的处理方案,具体如下:
10.1. 普通人的处理方案
作为普通人的我 (🐂🐎),我想到的就是这种方案 (惭愧~~~)。
处理很简单,照着普通迭代器的模样,再写一份 const 迭代器就OK了,如下:
template <class T>
struct const_list_iterator
{
typedef list_node<T> Node;
Node* _node;
const_list_iterator(Node* node = nullptr) : _node(node) {}
// 前置++, ++it
const_list_iterator& operator++()
{
_node = _node->_next;
return *this;
}
// 后置++, it++
const_list_iterator operator++(int)
{
const_list_iterator ret(*this);
_node = _node->_next;
return ret;
}
// 前置--, --it;
const_list_iterator& operator--()
{
_node = _node->_prev;
return *this;
}
// 后置--, it--
const_list_iterator operator--(int)
{
const_list_iterator ret(_node);
_node = _node->_prevc;
return ret;
}
bool operator!=(const const_list_iterator& it)
{
return _node != it._node;
}
bool operator==(const const_list_iterator& it)
{
return _node == it._node;
}
// 返回const 对象的引用
const T& operator*()
{
return _node->_data;
}
// 返回对象的地址
const T* operator->()
{
// 复用 operator*
return &(operator*());
}
};上面是一份 const 迭代器,同时,容器自身也需要提供相应的begin和end,如下:
const_iterator begin() const
{
// 用第一个有效元素构造 begin 迭代器
return _head->_next;
}
const_iterator end() const
{
// 用最后一个有效元素的下一个位置构造 end 迭代器
// 本质就是 _head
return _head;
}可能会有人有这样的疑惑,我们以 begin 举例,如下:
iterator begin()
{
return _head->_next;
}
const_iterator begin() const
{
return _head->_next;
}这两个函数构成函数重载吗,答案,构成,为什么呢? 因为它们参数的类型不一样,因为每一个非静态的成员函数都有一个 this 指针。
- 作为普通类型的 this 指针类型为:iterator* const this;
- 作为const类型的 this 指针类型为: const const_iterator* const this。
因此,两个函数的this指针类型不一样,即参数类型不一样,故构成函数重载,end 同理。
这就是普通处理 const 迭代器的方案,粗暴的复用 (大量相同重复的逻辑),没有一点技术含量,非常挫,下面来看看高手怎么玩的呢?
10.2. SGI-STL的处理方案
就普通迭代器和const 迭代器,我们发现,这两个类除了类名不一样,其实核心点就在两个地方放生了改变,那两个地方呢?
一个就是 operator*()、另一个就是 operator->();
如果是普通迭代器的 operator* 和 operator->,如下:
// 返回普通对象的引用
T& operator*()
{
return _node->_data;
}
// 返回普通对象的地址
T* operator->()
{
// 复用 operator*
return &(operator*());
}如果是 const 迭代器的 operator* 和 operator->(),如下:
// 返回const 对象的引用
const T& operator*()
{
return _node->_data;
}
// 返回 const 对象的地址
const T* operator->()
{
// 复用 operator*
return &(operator*());
}可以发现,它们的主要区别就在于返回值的类型不同罢了,因此,高手们就想到了用模板参数来解决这个问题,通过类模板参数,来进行泛型化,如下:
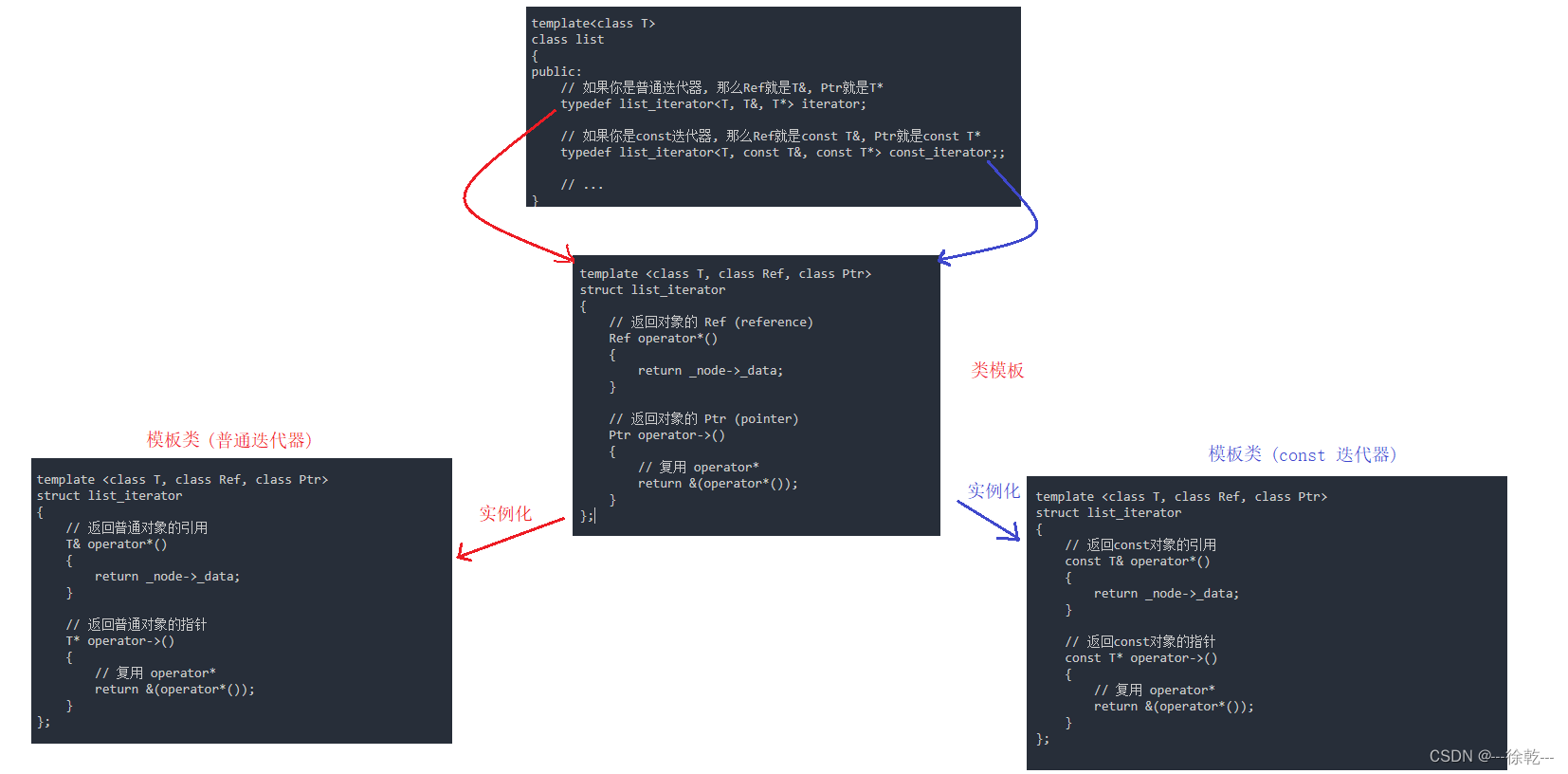
template <class T, class Ref, class Ptr>
struct list_iterator
{
// 返回对象的 Ref (reference)
Ref operator*()
{
return _node->_data;
}
// 返回对象的 Ptr (pointer)
Ptr operator->()
{
// 复用 operator*
return &(operator*());
}
};在 list 容器中,通过迭代器的类型决定 Ref 和 Ptr 是什么,进而决定这个 list_iterator 类模板实例化成什么具体的模板类,具体来说:
- 如果是普通类型的迭代器,那么Ref 就是 T&,Ptr 就是 T*;
- 如果是 const 类型的迭代器,那么 Ref 就是 const T&, Ptr 就是 const T*。
用代码来说,如下所示:
template<class T>
class list
{
public:
// 如果你是普通迭代器, 那么Ref就是T&, Ptr就是T*
typedef list_iterator<T, T&, T*> iterator;
// 如果你是const迭代器, 那么Ref就是const T&, Ptr就是const T*
typedef list_iterator<T, const T&, const T*> const_iterator;;
// ...
}可以看到, iterator 和 const_iterator 这两个类,通过通过模板参数达到泛型化,进而解决了大量相符重复代码的问题,这就是高手的处理方案,很神奇。
我们也可以用下图来理解一下这个过程:
11. operator->
在这里需要强调一下operator->。
首先,为什么需要 operator-> 呢? -> 这个操作费我们是经常使用的,称之为访问成员操作符,在有些场景下,我们是需要通过 -> 访问成员的。
假如有这样的一个类型,如下:
struct A
{
A(int a = 0, int b = 0) :_a(a), _b(b) {}
int _a;
int _b;
};场景如下:
void Test6(void)
{
Xq::list<A> lt{ { 1, 1 }, { 2, 2, }, { 3, 3, }, { 4, 4, } };
for (const auto& it : lt)
{
std::cout << *it << std::endl;
}
}如果这个类型 (struct A),没有实现 operator<<,那么这里就会编译报错,因为 A 是一个自定义类型,如下:
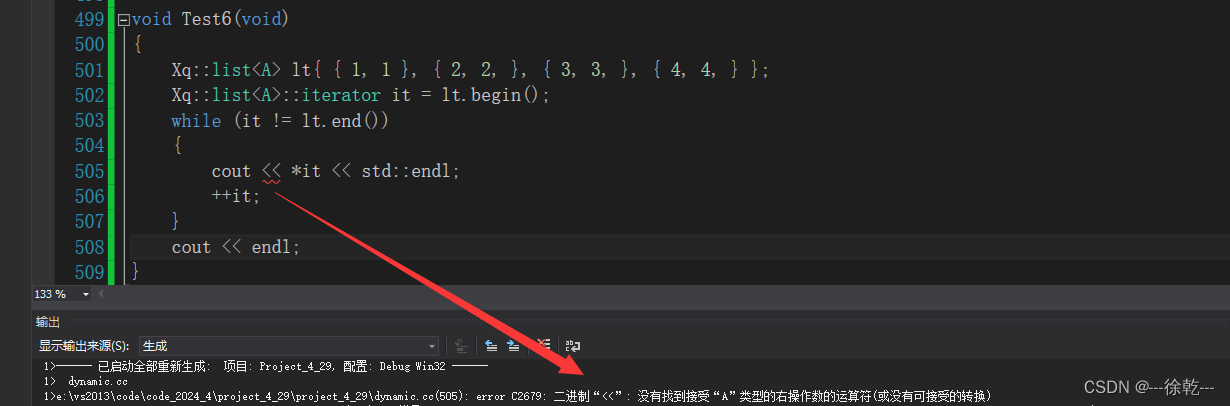
如果不想实现 operator<< ,那么这里就可以用 ->,如下:
void Test6(void)
{
Xq::list<A> lt{ { 1, 1 }, { 2, 2, }, { 3, 3, }, { 4, 4, } };
Xq::list<A>::iterator it = lt.begin();
while (it != lt.end())
{
cout << it->_a << " " << it->_b << endl;
++it;
}
cout << endl;
}那么 operator-> 如何实现呢?
operator-> 返回的是当前数据的指针,因此,我们可以复用 operator*,如下:
template<class T, class Ref, class Ptr>
struct list_iterator
{
// 返回数据的指针
Ptr operator->()
{
return &(operator*());
//等价于return &(_node->_data);
}
// ...
};
不过要在这里解释一下,这里的 -> 是如何调用的:
std::cout << it->_a << " " << it->_b << std::endl;
// 上面也可以这样写:
std::cout << it.operator->()->_a << " " << it.operator->()->_b << std::endl;
// it->_a 实际上是 it->->_a, 第一个 -> 是调用operator->, 第二个 -> 才是访问成员属性
// it-> 相当于 operator->, 返回一个Ptr, 返回迭代器里面数据的地址 (T* 或者 const T*)
// Ptr->_a 或者 Ptr->_b, 因此说 it->_a 实际上是 it->->_a
// 但是语法为了可读性, 编译器进行了特殊处理, 省略了一个->, 即 it->_a12. reverse_iterator
反向迭代器也称之为迭代器适配器,它的底层采用的是正向迭代器,将正向迭代器类的接口转换为反向迭代器类的接口。
在实现反向迭代器之前,我们需要搞清楚反向迭代器的 rbegin 和 rend 的位置,我们采用 STL 标准库的实现,具体如下:
反向迭代器的位置:

我们再看看正向迭代器的位置:
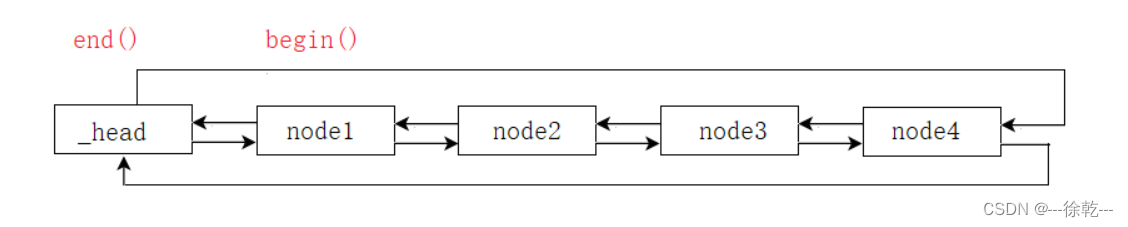
可以看到,正向迭代器和反向迭代器的位置是对称的。具体来说, 正向迭代器的begin() 正好是反向迭代器 rend() 的位置,而正向迭代器的 end() 这是反向迭代器 rbegin() 的位置。至于 STL 为什么这样设计,是有它的原因的,后面解释。
因为反向迭代器底层采用了正向迭代器,因此它的框架如下:
// 这里的 Ref 和 Ptr 是为了解决 const 反向迭代器, 这不重要
// 重要的是, 这里的Iterator, 它代表着是一个正向迭代器
template<class Iterator, class Ref, class Ptr>
class reverse_list_iterator
{
public:
// 用一个正向迭代器来构造反向迭代器
reverse_list_iterator(Iterator it) :_it(it) {}
private:
Iterator _it; // 一个正向迭代器
};既然是迭代器,它是需要实现如下功能的:
加加 (++)、减减 (--)、解引用 (*)、访问成员 (->)、等于 (==)、不等于 (!=) 。
在这里,由于反向迭代器是一个迭代器适配器,因此,上面的接口逻辑不需要反向迭代器自己实现,而是通过正向迭代器的接口来实现上面的接口。
不过需要注意的是,正向迭代器是正向访问容器 (list) 元素,而反向迭代器需要逆向访问容器 (list) 元素,故在复用正向迭代器的接口时,需要作出一些更改,具体如下:
我们先来两个简单的, 等于 (==)、不等于 (!=) ,实现如下:
template<class Iterator, class Ref, class Ptr>
class reverse_list_iterator
{
public:
// 用一个正向迭代器来构造反向迭代器
reverse_list_iterator(Iterator it) :_it(it) {}
// 复用正向迭代器的 operator==
bool operator==(const reverse_list_iterator& cmp)
{
return _it == cmp._it;
}
// 复用正向迭代器的 operator!=
bool operator!=(const reverse_list_iterator& cmp)
{
return _it != cmp._it;
}
private:
Iterator _it; // 需要一个正向迭代器
};接下来实现 ++、以及 -- 操作。
因为是逆向打印,因此这里的 ++ 操作对于容器中的元素而言是逆着走的。
举个例子:
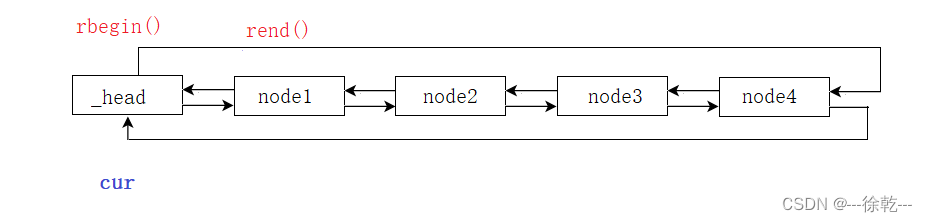
cur++ ,会指向哪里呢? 注意,它是逆着走的,如下:
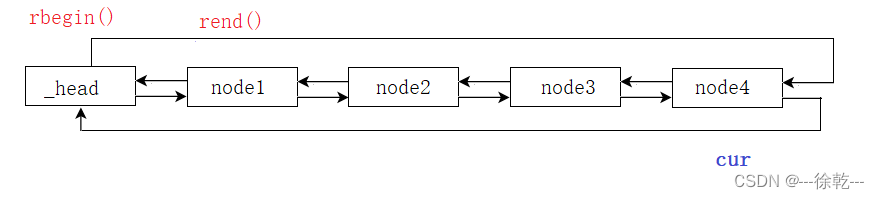
因此,我们发现,反向迭代器的 ++ 操作,正好对应正向迭代器的 -- 操作,因此,在实现反向迭代器的 ++ 操作时,我们就完全可以复用正向迭代器的 -- 操作。反向迭代器的--操作也是同理,也正因此,所以 STL 在设计 rbegin 和 rend 的位置时,才会采取和 begin 和 end 对称的方案。
有了上面的理解,那么 ++ 操作和 -- 操作的实现就自然而然出来了,如下:
template<class Iterator, class Ref, class Ptr>
class reverse_list_iterator
{
public:
// 用一个正向迭代器来构造反向迭代器
reverse_list_iterator(Iterator it) :_it(it) {}
// 前置++, 复用正向迭代器的--操作
reverse_list_iterator& operator++()
{
--_it;
return *this;
}
// 后置++, 复用正向迭代器的--操作
reverse_list_iterator operator++(int)
{
reverse_list_iterator ret(_it);
--_it;
return ret;
}
// 前置--, 复用正向迭代器的++操作
reverse_list_iterator operator--()
{
++_it;
return *this;
}
// 后置--, 复用正向迭代器的++操作
reverse_list_iterator operator--(int)
{
reverse_list_iterator ret(_it);
++_it;
return ret;
}
private:
Iterator _it; // 需要一个正向迭代器
};接下来就只剩 operator*() 和 operator-> 操作的实现了。
在这之前,我们再来看看 rbegin() 和 rend() 的初始位置,如下:

我们发现一个事实,rbegin() 的初始位置,是指向哨兵位的头节点的。
而我们反向迭代器的遍历操作是如何进行的呢,如下:
void Test8(void)
{
std::list<int> lt{ 1, 2, 3, 4, 5 };
std::list<int>::reverse_iterator rit = lt.rbegin();
while (rit != lt.rend())
{
std::cout << *rit << " ";
++rit;
}
std::cout << "\n";
}我们发现,我们是解引用了 rbegin() 这个迭代器,但是,客观事实告诉我们,哨兵位的头节点不可以解引用,就算解引用了也没有任何意义,那么这里是如何实现的呢?
很简单,在调用 operator* 时,解引用的位置是当前位置的前一个位置。
举个例子:
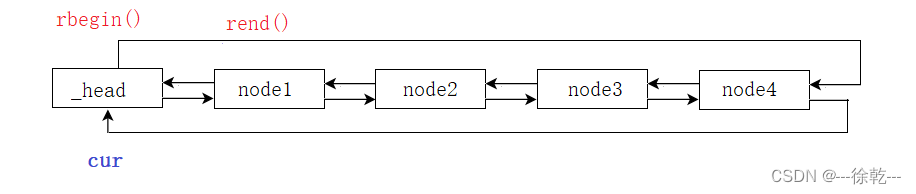
此时解引用cur (*cur),而事实上,解引用的是 node4 这个节点, 因此,在 operator*() 内部实现中,我们需要先锁定位置 (当前节点的前一个节点),在进行解引用,实现如下:
template<class Iterator, class Ref, class Ptr>
class reverse_list_iterator
{
public:
// 用一个正向迭代器来构造反向迭代器
reverse_list_iterator(Iterator it) :_it(it) {}
// 返回数据的引用
Ref operator*()
{
// 构造一个临时的正向迭代器
Iterator tmp(_it);
// 解引用的是当前位置的前一个节点
return *--tmp;
}
// 返回数据的地址
Ptr operator->()
{
return &(operator*());
}
private:
Iterator _it; // 需要一个正向迭代器
};至于这里为什么要用 Ref,Ptr 就不再解释了,至此,我们的反向迭代器的完整实现如下:
template<class Iterator, class Ref, class Ptr>
class reverse_list_iterator
{
public:
// 用一个正向迭代器来构造反向迭代器
reverse_list_iterator(Iterator it) :_it(it) {}
// 前置++, 复用正向迭代器的--操作
reverse_list_iterator& operator++()
{
--_it;
return *this;
}
// 后置++, 复用正向迭代器的--操作
reverse_list_iterator operator++(int)
{
reverse_list_iterator ret(_it);
--_it;
return ret;
}
// 前置--, 复用正向迭代器的++操作
reverse_list_iterator operator--()
{
++_it;
return *this;
}
// 后置--, 复用正向迭代器的++操作
reverse_list_iterator operator--(int)
{
reverse_list_iterator ret(_it);
++_it;
return ret;
}
// 复用正向迭代器的 operator==
bool operator==(const reverse_list_iterator& cmp)
{
return _it == cmp._it;
}
// 复用正向迭代器的 operator!=
bool operator!=(const reverse_list_iterator& cmp)
{
return _it != cmp._it;
}
// 返回数据的引用
Ref operator*()
{
// 构造一个临时的正向迭代器
Iterator tmp(_it);
// 解引用的是当前位置的前一个节点
return *--tmp;
}
// 返回数据的地址
Ptr operator->()
{
return &(operator*());
}
private:
Iterator _it; // 需要一个正向迭代器
};反向迭代器实现好后,容器 (list) 自身也需要提供相关接口,诸如 rbegin、rend 函数,实现如下:
template<class T>
class list
{
public:
// 如果你是普通反向迭代器, 那么Ref就是T&, Ptr就是T*
typedef reverse_list_iterator<iterator, T&, T*> reverse_iterator;
// 如果你是 const 反向迭代器, 那么Ref就是const T&, Ptr就是 const T*
typedef reverse_list_iterator<const_iterator, const T&, const T*> const_reverse_iterator;
reverse_iterator rbegin()
{
// 用哨兵位头节点构造的正向迭代器进而构造反向迭代器
return iterator(_head);
}
const_reverse_iterator rbegin() const
{
// 用哨兵位头节点构造的正向迭代器进而构造反向迭代器
return iterator(_head);
}
reverse_iterator rend()
{
// 用哨兵位头节点的下一个节点构造正向迭代器进而构造反向迭代器
return iterator(_head->_next);
}
const_reverse_iterator rend() const
{
// 用哨兵位头节点的下一个节点构造正向迭代器进而构造反向迭代器
return iterator(_head->_next);
}
private:
Node* _head
}