制芰荷以为衣兮
集芙蓉以为裳
不吾知其亦已兮
苟余情其信芳
目录
字符串的头部插入insert
<1>头部插入一个字符串:
<2>头部插入一个字符:
<3>迭代器的插入
总结:
字符串的头部删除 erase
<1>头部插入删除一个字符:
<2>头部插入删除一个字符串:
编辑
<3>指定位置的删除:
字符串的替换 replace
字符串中关于容量的库函数
计算一个字符串最大能开多大空间:max_size
查看一个字符串的当前容量:capacity
字符串容量的调整 reserve
总结
字符串大小的调整:resize
字符串的缩容:shrink_to_fit


字符串的头部插入insert
还是老样子,我们先来参考一下文档在进行分析:
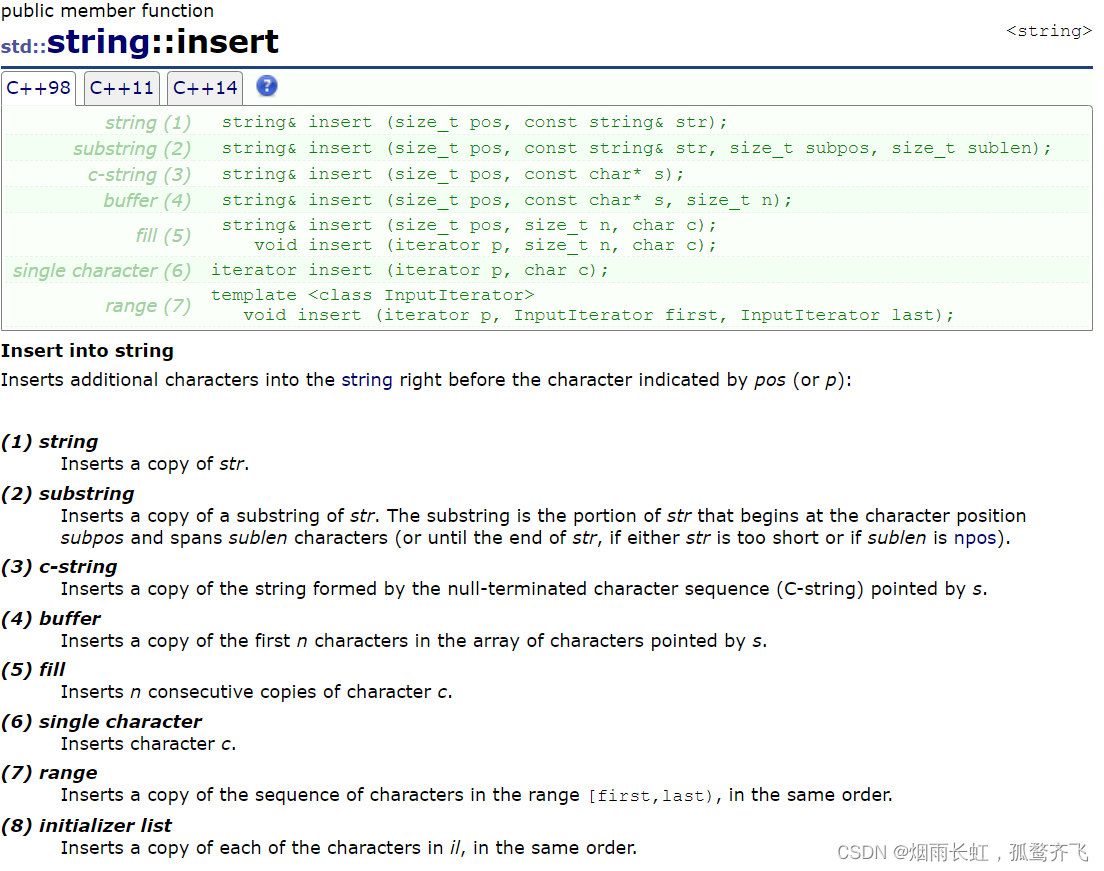
<1>头部插入一个字符串:
string& insert (size_t pos, const string& str);根据文档我们可以得知是在目标字符串的 pos 位置(注意下标从 0 开始)插入字符串 str
不过我们经常用来头插
#include<iostream>
#include<string>
using namespace std;
void TestString()
{
string s1("hello");
s1.insert(0, "world ");
cout << s1 << endl;
}
int main()
{
TestString();
return 0;
}
指定位置也是可以哒(后面都以实现头插为主)
void TestString()
{
string s1("hello");
s1.insert(2, "world ");
cout << s1 << endl;
}
<2>头部插入一个字符:
string& insert (size_t pos, size_t n, char c);这里我(疯狂吐槽):我们想在 pos 位置插入字符 c 还需要填写字符的数量 n
void TestString()
{
string s1("hello");
s1.insert(0, 1, 'x');
cout << s1 << endl;
}
肯定有老铁跟我一样吐槽,这样设计实在是有些冗余,那能不能不写插入字符的个数呢?
--- 这就要借助我们的迭代器啦 ~
<3>迭代器的插入
template <class InputIterator>
void insert (iterator p, InputIterator first, InputIterator last);如果是迭代器的话,刚刚插入一个字符还需填写个数的形式就可以解决了
void TestString()
{
string s1("hello");
s1.insert(s1.begin(), 'x');
cout << s1 << endl;
}
我们还可以这么玩 ~
void TestString()
{
string s1("hello");
string s2("world ");
s1.insert(s1.begin(), s2.begin(), s2.end());
cout << s1 << endl;
}
总结:
我们学过顺序表的都知道,数组在头部插入要挪动数据,效率是 O(N)
所以我们在使用 insert 还需要考虑时间复杂度的问题,因为这个效率属实不高 ~ 慎用 !!!
字符串的头部删除 erase
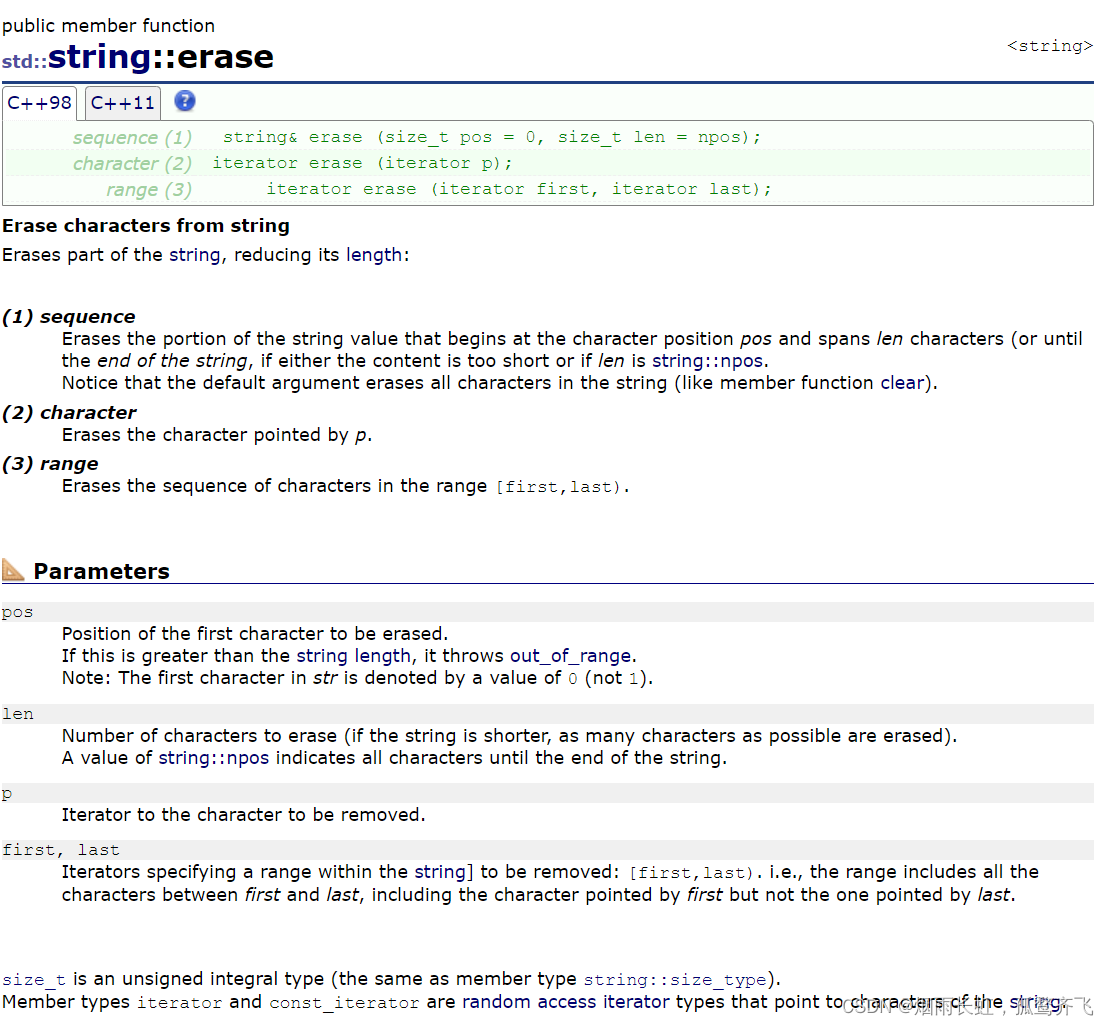
string& erase (size_t pos = 0, size_t len = npos);结合文档我们不难理解:
删除从 pos 位置开始的 len 个字符,如果 len 超过字符串剩下的值或者不写则全部删除
( pos 现在是缺省值,默认 pos 值是零,也就是从头开始删除,当然我们可以传其他参数)
<1>头部插入删除一个字符:
#include<iostream>
#include<string>
using namespace std;
void TestString()
{
string s1("hello world");
s1.erase(0,1);
cout << s1 << endl;
}
int main()
{
TestString();
return 0;
}
<2>头部插入删除一个字符串:
void TestString()
{
string s1("hello world");
s1.erase(0,5);
cout << s1 << endl;
}
<3>指定位置的删除:
void TestString()
{
string s1("hello world");
s1.erase(6,2);
cout << s1 << endl;
}
注意:铁铁们如果我们 erase 什么也不传会发生什么呢? -- 全部删完
因为 pos 缺省值默认从 0 开始,而默认的 npos 是一个 42 亿的数,所以全都删完噜 ~
总结:我们这里的头删与顺序表的也是一样,后一个覆盖前一个需要挪动数据,所以吃时间,我们用的是要还有斟酌一下(不要让程序跑的太慢哦)
字符串的替换 replace
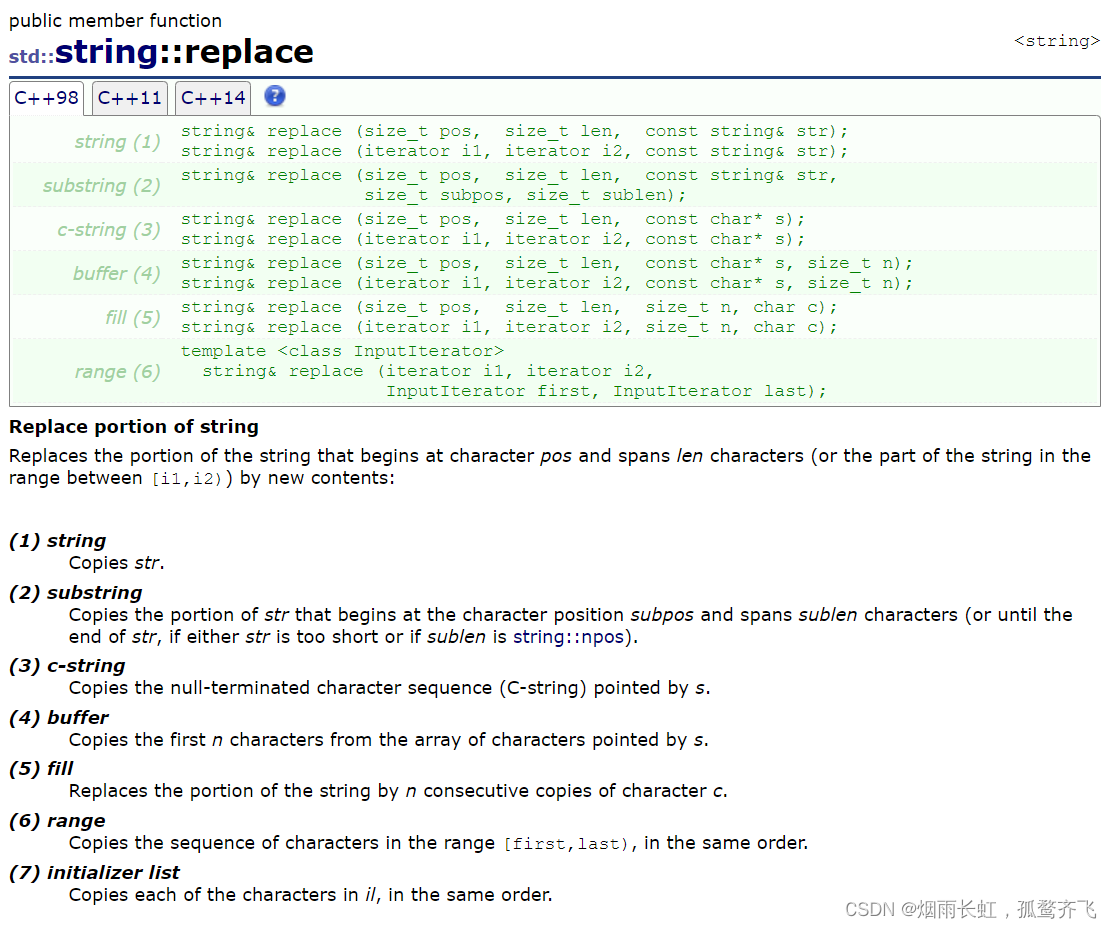
string& replace (size_t pos, size_t len, const string& str);结合文档我们不难理解:
把从 pos 开始的 len 个字符替换成字符串 str
我们可以来测试一下 ~ 我们将空格位置替换成 %20
void TestString()
{
string s1("hello world");
s1.replace(5, 1, "%20");
cout << s1 << endl;
}
注意:以上做法有没有什么弊端呢?-- 吃时间
因为我的一个字符的位置容不下 %20 ,所以位置要进行挪动,空间能容纳之后才能进行替换
我们替换最好控制在相等的长度内,不要让数据发生挪动
字符串中关于容量的库函数
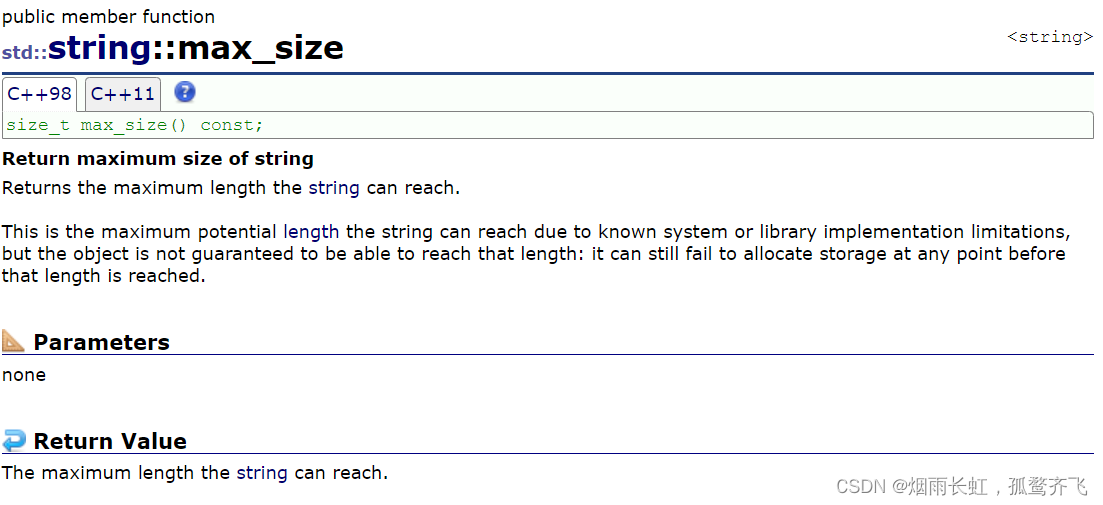
计算一个字符串最大能开多大空间:max_size
max_size 计算的是字符串最大能开多少空间,但是真的能开那么大吗
我们可以先来看看这个空间有多大:
void TestString()
{
string s1;
cout << s1.max_size() << endl;
}在 x64 环境下 :

在 x86 环境下:

我们虽然它的潜力空间很大(大概几个G),但是计算机真的愿意给一个字符串开那么大空间吗
-- 还真不愿意,就如一个富豪总资产才 8 个亿你叫他给你 4 个亿,你觉得他答应不答应
这个接口只需了解一下即可,平时基本没怎么用到
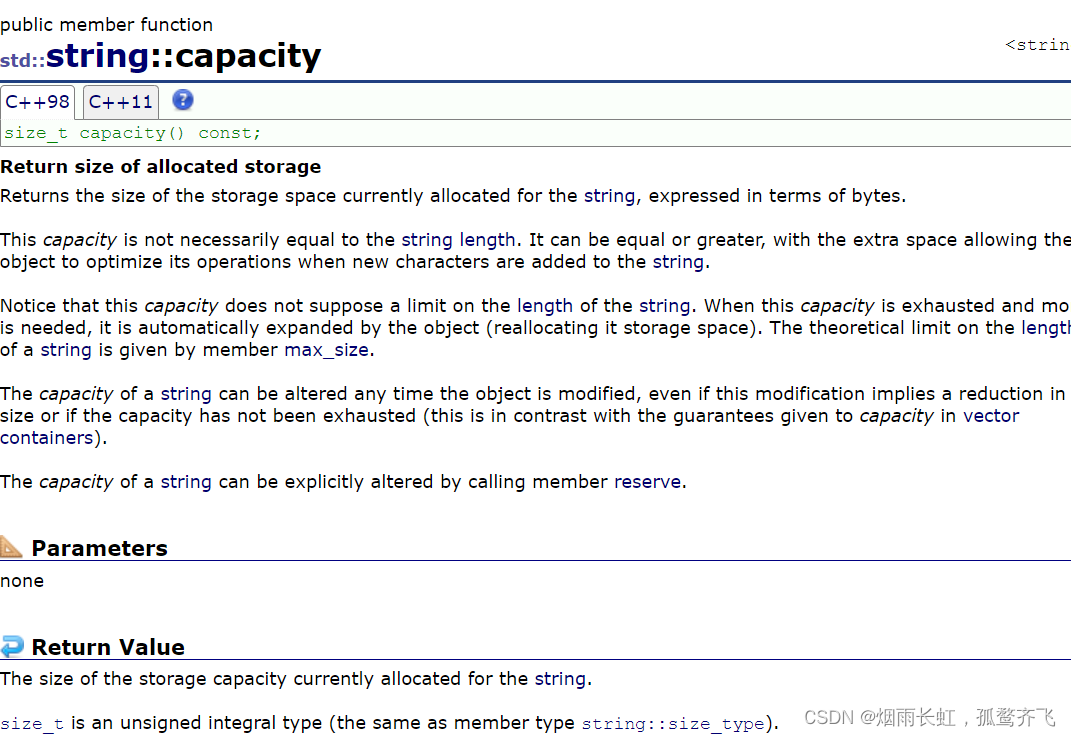
查看一个字符串的当前容量:capacity
根据文档我们可以得知:capacity 计算的是当前容量的大小,并以字节的形式返回
有了这个知识点,我们可以先来看一下 VS 下的扩容:
void TestString()
{
string s1;
size_t sz = s1.capacity();
cout << "capacity changed:" << sz << endl;
cout << "making s grow:" << endl;
for (int i = 0; i < 100; i++)
{
s1.push_back('c');
if (sz != s1.capacity())
{
sz = s1.capacity();
cout << "capacity changed:" << sz << endl;
}
}
} 我先来了解一下 VS 存储的逻辑:
我先来了解一下 VS 存储的逻辑:
首先我们在创建 对象s1 时用的是类中的空间 _Buf
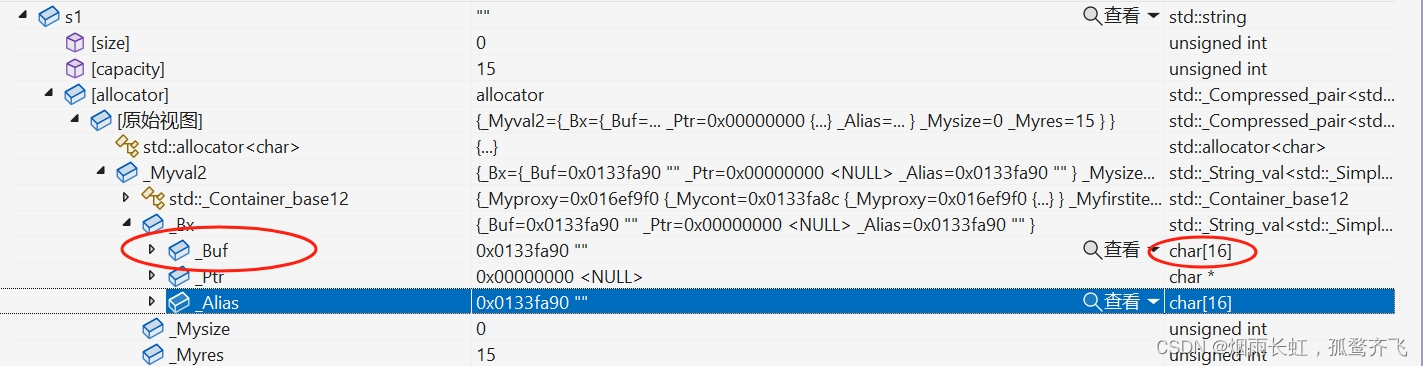
然后我们了解到我们实际开的空间是 16 ,但是我们打印的 capacity 是15
说明 VS 编译器给 \0 预留了一个位置,这块空间不算在 capacity 里面
当 _Buf 不够用时就在堆上扩容并将其拷贝到新开辟的空间,事后不再使用这块 _Buf 空间

所以 s1 真正的扩容是在 making s grow 中开始的(之前的那块空间是类中存在的空间 _Buf)
属于 1.5 倍扩容
我们再看一下 Linux 下的扩容:
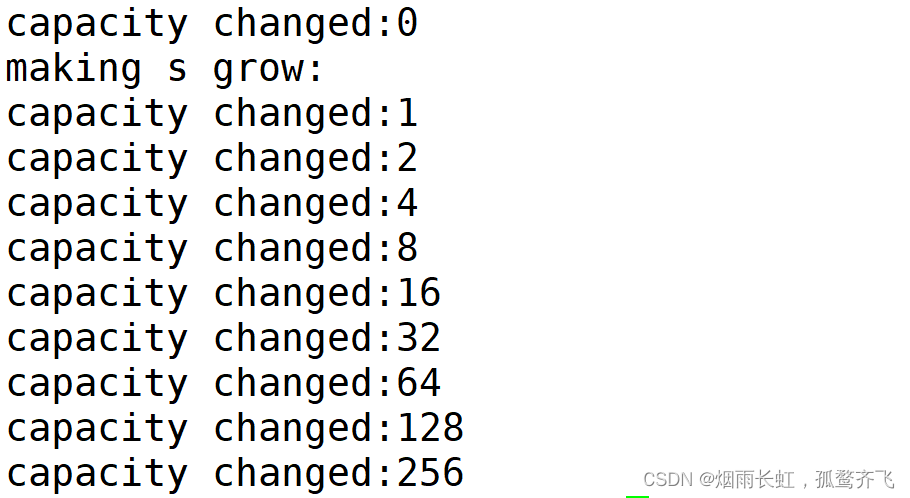
我们可以看到 Linux 环境下没有 _Buf 数组,而且显示了 \0 的空间,很直观 ~
属于 2 倍扩容
以后我们可以借助 capcacity 来了解编译器扩容的规则
字符串容量的调整 reserve
根据文档我们可以得知:reserve 为容器预留足够的空间,避免不必要的重复分配,分配空间大于等于函数的参数,影响 capacity
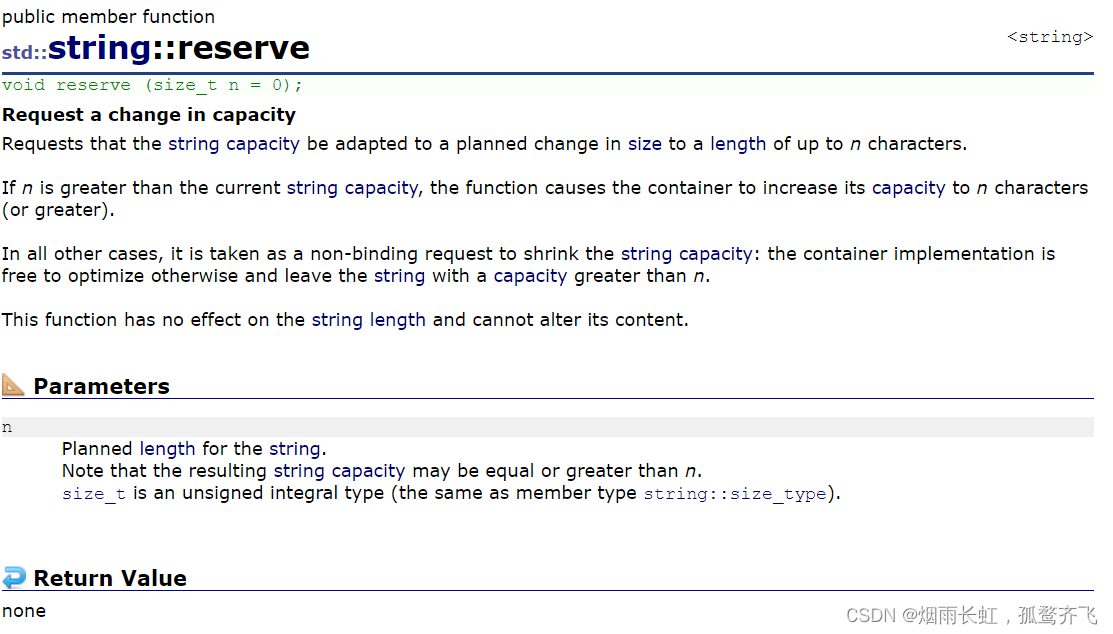
我们先来看一下 VS 下的 reserve:
void TestString()
{
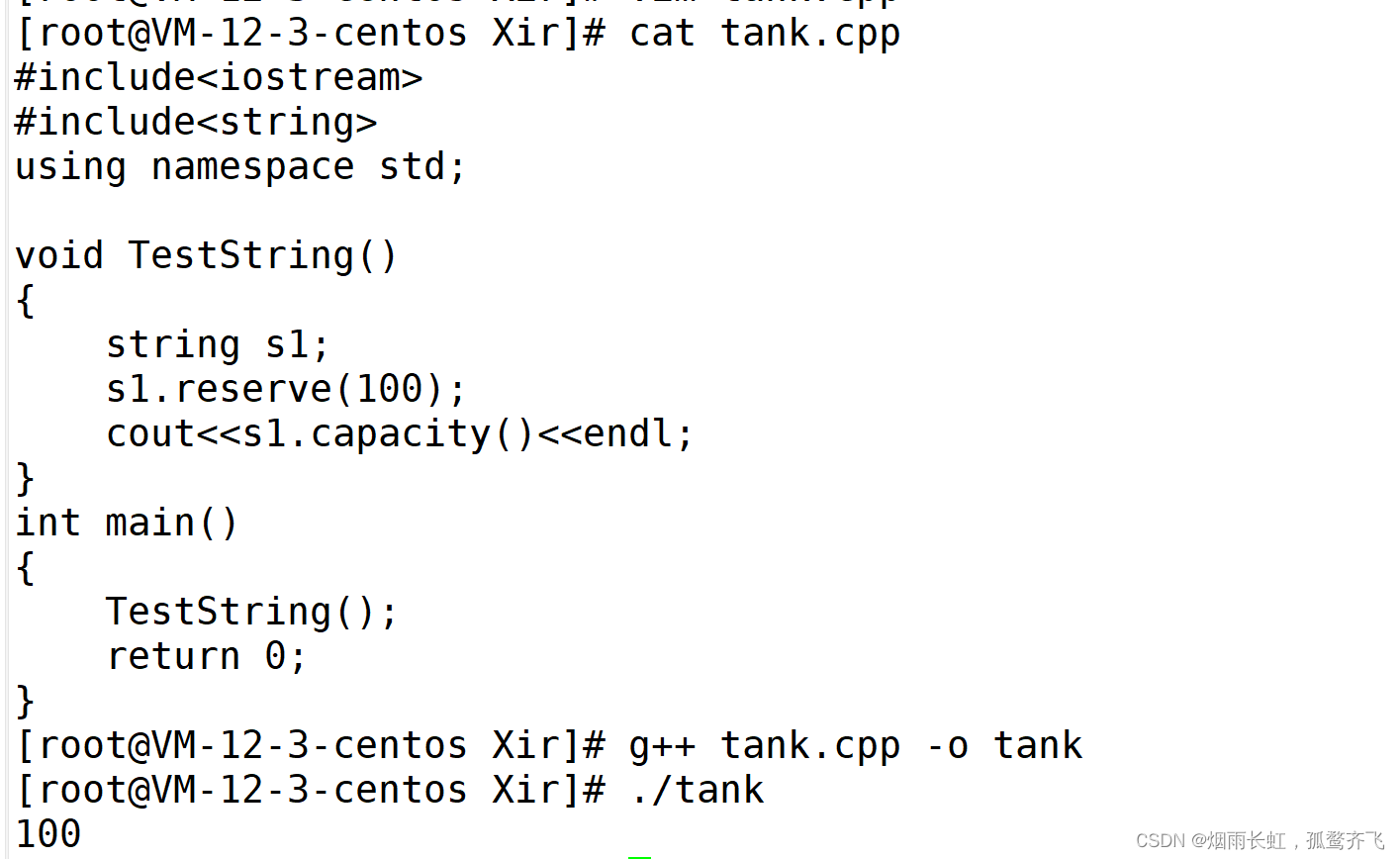
string s1;
s1.reserve(100);
cout << s1.capacity() << endl;
}
我们发现我们预留了 100 的空间,但是编译器开了 111
我们再来看看 Linux 环境下的 reserve:
如果是 Linux 环境下则是设置多少就开多少
reserve 还有一点作用就是缩容,但是 VS 环境下是不缩容的:

可能有些老铁会疑惑 -- 为什么 reserve 小于15就会缩容到15呢?
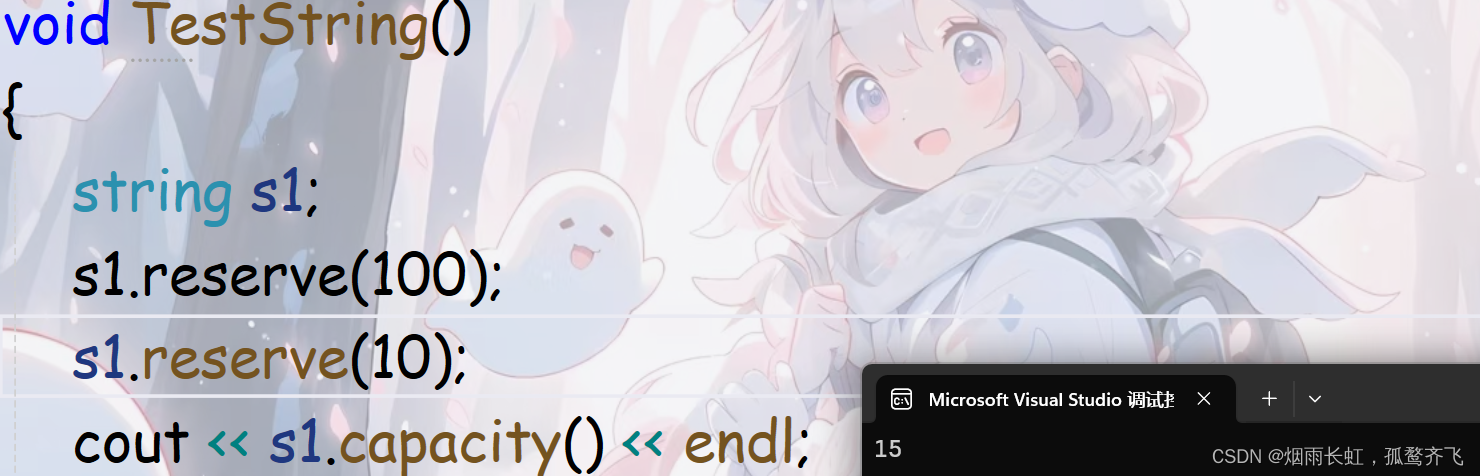 其实这不是缩容而是用了类中的 _Buf 空间
其实这不是缩容而是用了类中的 _Buf 空间
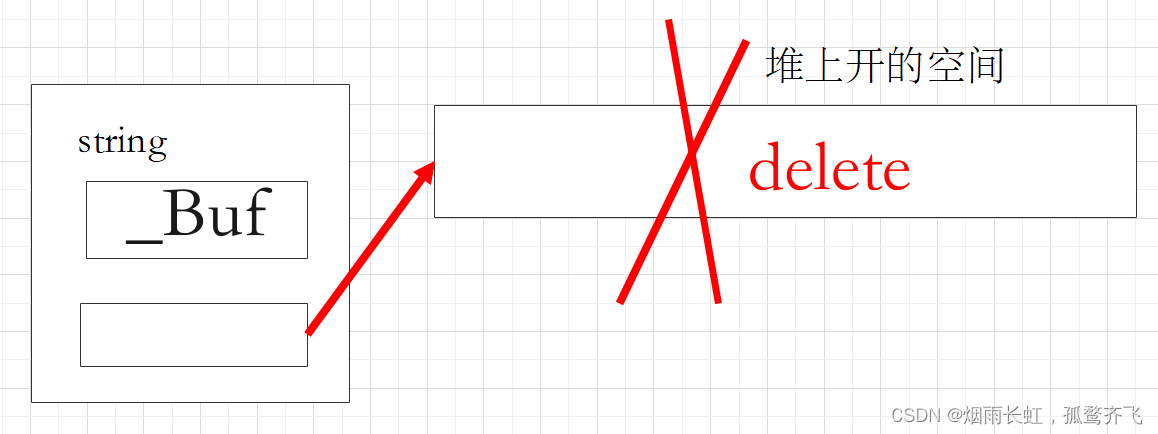
如果 reserve 小于 _Buf 则会释放在堆上开辟的空间,从而用 _Buf 的空间,这就说明为什么容量是 15 而不是 10 的问题
Linux 环境下是缩容的:

而且是按照我们指定的容量缩容
运用场景:
举个栗子 -- 栈的扩容,如果我们刚开始没有预留空间,数据量大的话就要频繁扩容,而频繁扩容对我们的程序是不好的,系统会产生大量的内存碎片 -- 导致空间的浪费
注意:
有些老铁以为开了空间就能对空间所有位置进行访问:
void TestString()
{
string s1;
s1.reserve(100);
s1[55] = 'x';
cout << s1.capacity() << endl;
}
这里就发生越界访问了 -- 原因是:虽然你的空间开好了,但是你的数据个数 size 依然是 0
我们数组访问的不是容量,而是你计入的数据量

总结
在使用 reserve、capacity 需要先了解编译器的环境(每个编译器的环境是不一样的),不然容易出错
字符串大小的调整:resize
根据文档我们可以得知:resize 可以改变容器的大小,使得其包含n个元素

我们这里讲讲常见 resize 三种用法 :
<1>直接改变 size 的大小,注意这里会间接改变 capacity 容量

此时我们就可以访问我们 size 计入的空间(不会发生越界访问):
s1[15] = 'x';
而其他没有被初始化的空间则全部用 \0 代替 ~
<2>改变 size 的大小的同时初始化
void TestString()
{
string s1;
s1.resize(10, 'x');
cout << s1 << endl;
}
<3>假设 n 是 resize 的容器元素大小 -- 参数
(1)如果 n 小于当前的原字符串大小,那么则保留原字符串的前 n 个元素,去除超过的部分
void TestString()
{
string s1("hello world");
s1.resize(5);
cout << s1 << endl;
}
(2)如果 n 大于当前的原字符串大小,则通过在原字符串结尾插入适合数量的元素使得整个字符串的大小达到 n
void TestString()
{
string s1("hello world");
s1.resize(15, 'x');
cout << s1 << endl;
}
字符串的缩容:shrink_to_fit
C++11提出了 shrink_to_fit 函数目的是缩容:让容量 capacity 大小跟 size 大小保持一致
void TestString()
{
string s1;
s1.reserve(100);
cout << "capacity:" << s1.capacity() << endl;
s1.resize(20);
cout << "capacity:" << s1.capacity() << endl;
s1.shrink_to_fit();
cout << "capacity:" << s1.capacity() << endl;
} 说到这里,我们来讲一下缩容的原理:
说到这里,我们来讲一下缩容的原理:
错误示范(在没讲之前是不是有很多老铁是这种缩容观念)
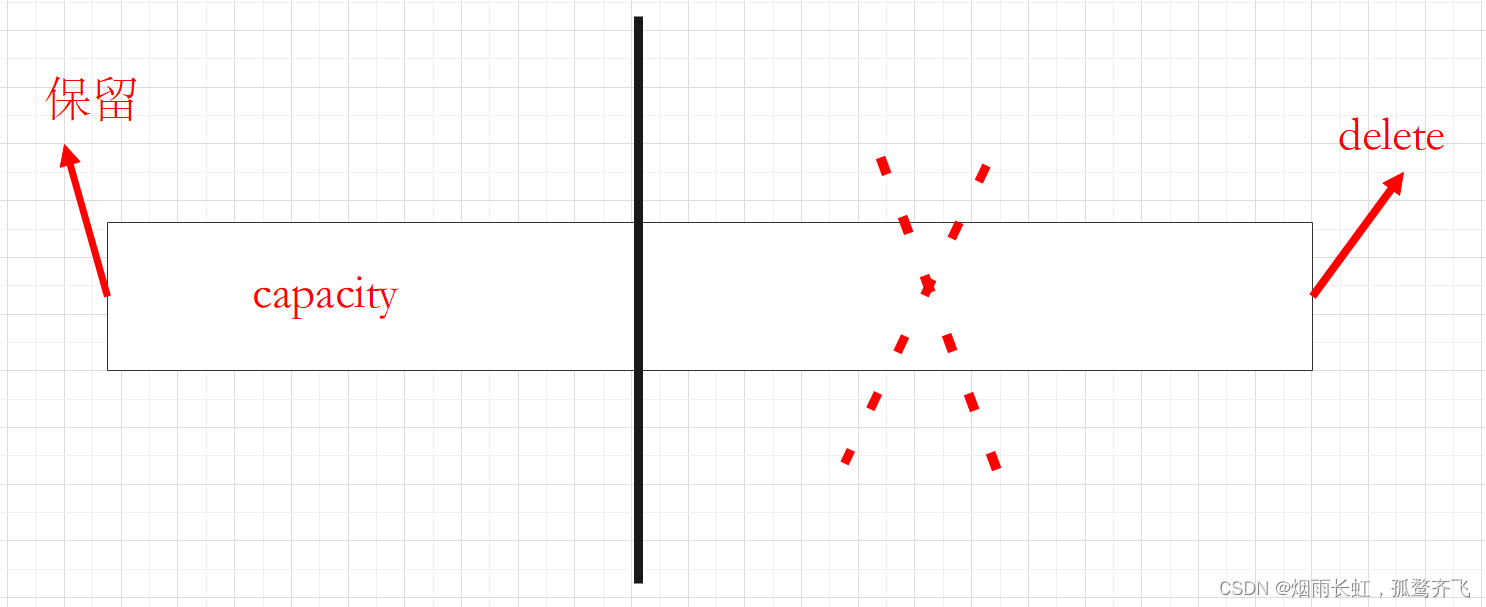
将一整条空间中的一部分释放再保留一部分
其实这是错误的 ~ 因为我们释放空间是必须从数组的首地址开始释放:
正确的缩容方式为:找一块更小的空间再将数据拷贝进去,并释放原来的空间
这样就导致他的效率很低 ~ 老铁使用的时候要注意

此身天地一虚舟
何处江山不自由
先介绍到这里啦~
有不对的地方请指出💞




![[答疑]系统需求并不会修改领域事实(警惕伪创新)](https://img-blog.csdnimg.cn/img_convert/d54b51fed70e80def2ae27dd8d3acb9c.png)