目录
一、opencv-ml模块
1.1 ml简介
1.2 StatModel基类及通用函数
1.3 ml模块各算法基本应用
二、ml模块的实现原理
2.1 cv::ml::StatModel的train函数实现原理
2.2 cv::ml::StatModel的predict函数实现原理
2.3 cv::ml::StatModel的save函数和load函数
一、opencv-ml模块
1.1 ml简介
通过前面几篇博文对应支持向量机(SVM)、决策树(DTrees)、随机森林(RTrees)、K近邻(KNN)等算法了解可以看出他们在示例应用上高度相似,这是因为他们都派生于cv::ml::StatModel类,尤其提供了通用函数。
在OpenCV的C++接口中,ML(Machine Learning)模块的源码路径如下:

进入include\opencv2目录,可以看到ml模块的引用头文件,几乎所有有关ml算法的类都在该头文件定义:
namespace ml
{
class CV_EXPORTS_W ParamGrid{...};
class CV_EXPORTS_W TrainData{...};
class CV_EXPORTS_W StatModel : public Algorithm{...};
class CV_EXPORTS_W NormalBayesClassifier : public StatModel{...};
class CV_EXPORTS_W KNearest : public StatModel{...};
class CV_EXPORTS_W SVM : public StatModel{...};
class CV_EXPORTS_W EM : public StatModel{...};
class CV_EXPORTS_W DTrees : public StatModel{...};
class CV_EXPORTS_W RTrees : public DTrees{...};
class CV_EXPORTS_W Boost : public DTrees{...};
class CV_EXPORTS_W ANN_MLP : public StatModel{...};
class CV_EXPORTS_W LogisticRegression : public StatModel{...};
class CV_EXPORTS_W SVMSGD : public cv::ml::StatModel{...};
...
};以下是一些常用的类和接口在ML模块中的概述:
1. 基本接口
cv::ml::StatModel:所有统计模型的基类。它提供了训练和预测的基本接口。
2. 分类算法
cv::ml::SVM:支持向量机(Support Vector Machines)。它可用于分类和回归问题。cv::ml::KNearest:K最近邻(K-Nearest Neighbors)。基于实例的学习,根据特征空间中的k个最近邻居进行分类或回归。cv::ml::DTrees:决策树分类器。cv::ml::RTrees:随机森林分类器。它是基于决策树的集成方法。cv::ml::Boost:提升算法(Boosting)。它结合了多个弱分类器来创建一个强分类器。cv::ml::LogisticRegression:逻辑回归分类器。
3. 数据表示
cv::ml::TrainData:训练数据的容器。它包含了特征向量(样本)、响应变量(标签)、样本权重和样本/变量类别等信息。
4. 参数优化
cv::ml::ParamGrid:参数网格,用于设置算法参数的搜索范围,通常与交叉验证一起使用以找到最佳参数。
5. 交叉验证
cv::ml::CvRTParams(对于随机森林)和cv::ml::CvSVMParams(对于SVM)等类的参数结构体中,通常有与交叉验证相关的字段,如termCrit(终止准则)和crossValidation标志。
6. 模型评估
- 评估分类器性能通常涉及计算准确率、召回率、精度、F1分数等指标。
- OpenCV没有直接提供这些指标的计算函数,但你可以使用预测结果和真实标签来计算它们。
1.2 StatModel基类及通用函数
在OpenCV的C++接口中,cv::ml::StatModel 是一个重要的基类,其继承Algorithm类,它代表了一个统计模型或学习器。这个类为所有OpenCV机器学习算法提供了一个通用的接口,包括训练(train)、预测(predict)、保存(save,来自Algorithm类)和加载(load,来自Algorithm类)模型等功能。
class CV_EXPORTS_W StatModel : public Algorithm
{
public:
CV_WRAP virtual int getVarCount() const = 0;
CV_WRAP virtual bool empty() const CV_OVERRIDE;
CV_WRAP virtual bool isTrained() const = 0;
CV_WRAP virtual bool isClassifier() const = 0;
CV_WRAP virtual bool train( const Ptr<TrainData>& trainData, int flags=0 );
CV_WRAP virtual bool train( InputArray samples, int layout, InputArray responses );
CV_WRAP virtual float predict( InputArray samples, OutputArray results=noArray(), int flags=0 ) const = 0;
CV_WRAP virtual float calcError( const Ptr<TrainData>& data, bool test, OutputArray resp ) const;
...
};主要成员函数
-
train(const Ptr<TrainData>& trainData, int flags=0)
使用提供的训练数据对模型进行训练。 -
train(InputArray samples, int layout, InputArray responses)
另一个版本的训练函数,允许你直接提供样本和响应。 -
predict(InputArray samples, OutputArray results=noArray(), int flags=0)
对输入样本进行预测,并返回预测结果。 -
calcError(const Ptr<TrainData>& data, bool testSampleWeights=false, OutputArray respType=noArray()) 计算模型在给定测试数据集上的误差。
-
save(const String& filename, const String& name="")
将模型保存到文件。 -
load(const String& filename, const String& name="")
从文件加载模型。 -
empty()
检查模型是否为空(即,是否已经被训练)。 -
getVarCount()
返回模型中的变量(特征)数量。 -
isClassifier()
检查模型是否是一个分类器。 -
isTrained()
检查模型是否已经被训练。
1.3 ml模块各算法基本应用
虽然cv::ml::StatModel本身不执行任何机器学习算法,但可以使用它的子类(如cv::ml::SVM、cv::ml::KNearest等)来创建和训练模型。以cv::ml::SVM类(它是cv::ml::StatModel的一个子类)使用为例,使用主要分为以下几步:
1)创建cv::ml::SVM实例,设置实例参数,使用训练数据集进行训练。
#include <opencv2/opencv.hpp>
#include <opencv2/ml.hpp>
//create SVM model
cv::Ptr<cv::ml::SVM> svm = cv::ml::SVM::create();
//set svm args,type and KernelTypes
svm->setType(cv::ml::SVM::C_SVC);
svm->setKernel(cv::ml::SVM::POLY);
//KernelTypes POLY is need set gamma and degree
svm->setGamma(3.0);
svm->setDegree(2.0);
//Set iteration termination conditions, maxCount is importance
svm->setTermCriteria(cv::TermCriteria(cv::TermCriteria::EPS | cv::TermCriteria::COUNT, 1000, 1e-8));
// svm model train
svm->train(trainingData, cv::ml::ROW_SAMPLE, labelsMat); 2)在模型训练完成后,调用predict函数进行预测,将预测结果和原对应标记标签集做比较评估预测准确度。
// svm model test
cv::Mat testData = read_mnist_image(testImgFile);
//images data normalization
testData = testData/255.0;
//预测
cv::Mat testResp;
float response = svm->predict(testData,testResp);
//read test label, data type CV_32SC1,读取原来验证标签集做比较
cv::Mat testlabel = read_mnist_label(testLabeFile);
testResp.convertTo(testResp,CV_32SC1);
int map_num = 0;
for (int i = 0; i <testResp.rows&&testResp.rows==testlabel.rows; i++)
{
if (testResp.at<int>(i, 0) == testlabel.at<int>(i, 0))
{
map_num++;
}
}
float proportion = float(map_num) / float(testResp.rows);3)保存模型,输出格式为.xml
//save svm model
svm->save("mnist_svm.xml");4)实时使用训练好的算法模型
//load svm model
cv::Ptr<cv::ml::SVM> svm = cv::ml::StatModel::load<cv::ml::SVM>("mnist_svm.xml");
//read img 28*28 size
cv::Mat image = cv::imread(fileName, cv::IMREAD_GRAYSCALE);
//uchar->float32
image.convertTo(image, CV_32F);
//image data normalization
image = image / 255.0;
//28*28 -> 1*784
image = image.reshape(1, 1);
//预测图片
float ret = svm ->predict(image);
std::cout << "predict val = "<< ret << std::endl;针对上述描述更详细的过程,见本专栏的博文C/C++开发,opencv-ml库学习,支持向量机(SVM)应用-CSDN博客。
二、ml模块的实现原理
cv::ml::StatModel 类最重要的函数无疑是train和predict函数。
2.1 cv::ml::StatModel的train函数实现原理
cv::ml::StatModel 类的 train 函数本身是一个抽象函数,它在 cv::ml::StatModel 类中并没有具体的实现。这是因为 cv::ml::StatModel 是一个抽象基类,它定义了一个通用的机器学习模型接口,而具体的训练算法和实现则是由其子类来提供的。

当子类(如 cv::ml::SVM、cv::ml::KNearest、cv::ml::DTrees 等)继承自 cv::ml::StatModel 并实现其接口时,它们需要为 train 函数提供具体的实现。

一般来说,子类中的 train 函数实现原理会依赖于该机器学习算法的具体要求。以下是一个大致的 train 函数实现原理的概述:
-
参数验证:
在训练开始前,函数会验证输入的训练数据是否有效,包括数据的维度、标签的数量和类型等。如果数据无效,函数可能会抛出一个异常或返回一个错误代码。 -
初始化模型参数:
根据机器学习算法的要求,函数会初始化模型的一些内部参数。这些参数可能包括学习率、迭代次数、正则化参数等。 -
数据预处理:
根据算法的需求,函数可能会对训练数据进行一些预处理操作,如特征缩放、归一化、编码分类标签等。 -
训练算法实现:
这是train函数的核心部分,它实现了具体的机器学习算法。对于不同的算法,这一步的实现方式会有很大的差异。例如,对于 SVM 算法,这一步可能包括求解支持向量、计算决策超平面等;对于决策树算法,这一步可能包括构建树结构、计算分裂节点等。
//SVMl类
bool train( const Ptr<TrainData>& data, int ) CV_OVERRIDE
{
CV_Assert(!data.empty());
clear();
checkParams();
int svmType = params.svmType;
Mat samples = data->getTrainSamples();
Mat responses;
if( svmType == C_SVC || svmType == NU_SVC )
{
responses = data->getTrainNormCatResponses();
if( responses.empty() )
CV_Error(CV_StsBadArg, "in the case of classification problem the responses must be categorical; "
"either specify varType when creating TrainData, or pass integer responses");
class_labels = data->getClassLabels();
}
else
responses = data->getTrainResponses();
if( !do_train( samples, responses ))
{
clear();
return false;
}
return true;
}需要注意的是,具体的实现方式会依赖于子类所实现的机器学习算法和 OpenCV 的版本。在使用 OpenCV 的 ML 模块时,查阅相关的文档和源代码可以了解特定算法的实现细节。
2.2 cv::ml::StatModel的predict函数实现原理
cv::ml::StatModel 的 predict 函数也是一个抽象函数,它在 cv::ml::StatModel 类中没有具体的实现。具体的实现细节由继承自 cv::ml::StatModel 的子类来提供,这些子类会根据它们所代表的机器学习算法来实现 predict 函数。
一般来说,predict 函数的实现原理可以概述如下:
-
输入验证:
首先,predict函数会验证输入数据的有效性。这包括检查数据的维度是否与模型训练时使用的数据维度一致,以及检查输入数据是否符合模型的要求(例如,对于分类器,输入数据应该是特征向量)。 -
数据预处理(如果需要):
如果模型在训练时进行了数据预处理(如特征缩放、归一化等),predict函数可能需要在预测前对输入数据进行相同的预处理操作,以确保输入数据与模型训练时使用的数据格式一致。 -
应用模型:
这是predict函数的核心部分。子类会根据它们所代表的机器学习算法来实现具体的预测逻辑。对于分类器,这通常涉及计算输入数据在每个类别上的得分(或概率),并选择得分最高的类别作为预测结果。对于回归器,这通常涉及计算输入数据对应的输出值。具体的实现方式取决于机器学习算法的类型。例如,对于基于决策树的模型,
predict函数可能会按照树的结构逐步遍历,根据输入数据的特征值选择路径,直到到达叶节点,并将叶节点的值作为预测结果。对于基于距离度量的模型(如 KNN),predict函数可能会计算输入数据与训练数据集中每个样本的距离,并选择距离最小的 K 个样本的类别(或输出值的平均值)作为预测结果。 -
后处理(如果需要):
在某些情况下,predict函数可能还需要对预测结果进行后处理。例如,对于多类分类问题,如果使用了 one-vs-all 策略训练了多个二分类器,predict函数可能需要将这些二分类器的预测结果组合起来,以确定最终的类别。 -
返回预测结果:
最后,predict函数会返回预测结果。对于分类器,这通常是一个表示类别的整数或字符串。对于回归器,这通常是一个实数或浮点数。
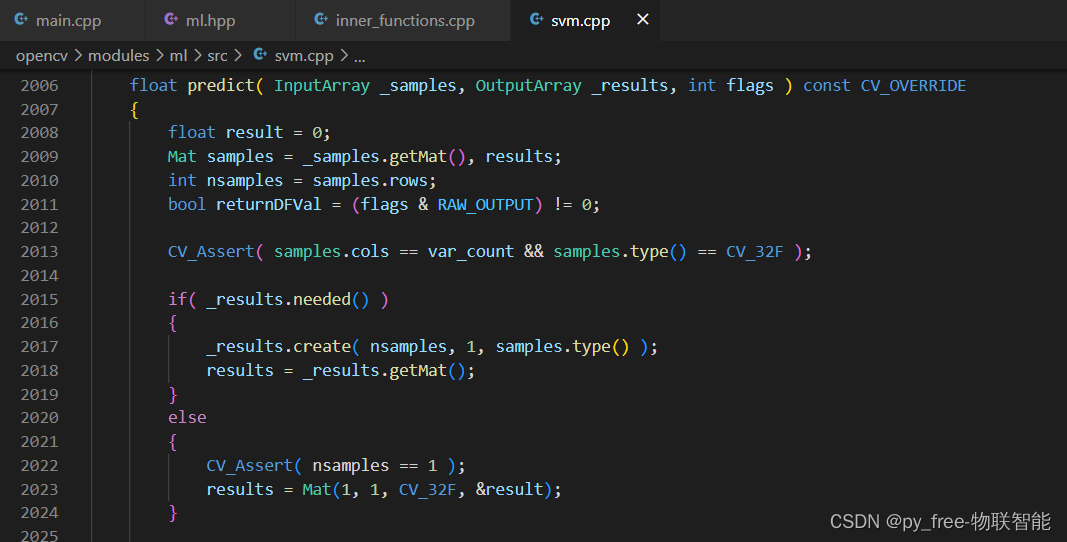
//SVM类的具体实现
float predict( InputArray _samples, OutputArray _results, int flags ) const CV_OVERRIDE
{
float result = 0;
Mat samples = _samples.getMat(), results;
int nsamples = samples.rows;
bool returnDFVal = (flags & RAW_OUTPUT) != 0;
CV_Assert( samples.cols == var_count && samples.type() == CV_32F );
if( _results.needed() )
{
_results.create( nsamples, 1, samples.type() );
results = _results.getMat();
}
else
{
CV_Assert( nsamples == 1 );
results = Mat(1, 1, CV_32F, &result);
}
PredictBody invoker(this, samples, results, returnDFVal);
if( nsamples < 10 )
invoker(Range(0, nsamples));
else
parallel_for_(Range(0, nsamples), invoker);
return result;
}需要注意的是,具体的实现方式会依赖于子类所实现的机器学习算法和 OpenCV 的版本。在使用 OpenCV 的 ML 模块时,查阅相关的文档和源代码了解特定算法的实现细节。
2.3 cv::ml::StatModel的save函数和load函数
在OpenCV的ML模块中,cv::ml::StatModel的save和load函数是其继承class CV_EXPORTS_W Algorithm类而获得,用于序列化和反序列化机器学习模型的接口。这两个函数会紧密依赖于write、read等函数。
class CV_EXPORTS_W Algorithm
{
public:
Algorithm();
virtual ~Algorithm();
CV_WRAP virtual void clear() {}
virtual void write(FileStorage& fs) const { CV_UNUSED(fs); }
CV_WRAP void write(const Ptr<FileStorage>& fs, const String& name = String()) const;
CV_WRAP virtual void read(const FileNode& fn) { CV_UNUSED(fn); }
CV_WRAP virtual bool empty() const { return false; }
template<typename _Tp> static Ptr<_Tp> read(const FileNode& fn)
{
Ptr<_Tp> obj = _Tp::create();
obj->read(fn);
return !obj->empty() ? obj : Ptr<_Tp>();
}
template<typename _Tp> static Ptr<_Tp> load(const String& filename, const String& objname=String())
{
FileStorage fs(filename, FileStorage::READ);
CV_Assert(fs.isOpened());
FileNode fn = objname.empty() ? fs.getFirstTopLevelNode() : fs[objname];
if (fn.empty()) return Ptr<_Tp>();
Ptr<_Tp> obj = _Tp::create();
obj->read(fn);
return !obj->empty() ? obj : Ptr<_Tp>();
}
template<typename _Tp> static Ptr<_Tp> loadFromString(const String& strModel, const String& objname=String())
{
FileStorage fs(strModel, FileStorage::READ + FileStorage::MEMORY);
FileNode fn = objname.empty() ? fs.getFirstTopLevelNode() : fs[objname];
Ptr<_Tp> obj = _Tp::create();
obj->read(fn);
return !obj->empty() ? obj : Ptr<_Tp>();
}
CV_WRAP virtual void save(const String& filename) const;
CV_WRAP virtual String getDefaultName() const;
protected:
void writeFormat(FileStorage& fs) const;
}; 由于cv::ml::StatModel是一个抽象基类,它本身并不直接实现这些函数,而是由继承自它的子类来提供具体的实现,甚至包括write、read等函数在子类中实现。
save函数实现原理
save函数的实现原理通常涉及以下几个步骤:
-
参数验证:
首先,函数会验证传入的文件路径是否有效,以及模型是否已经被训练(因为未训练的模型通常没有保存的价值)。 -
序列化模型参数:
接着,函数会遍历模型的各个部分(如决策树的结构、SVM的权重和偏置等),并将这些参数转换为可以写入文件的格式(如二进制、XML、YAML等)。这个过程通常被称为序列化。 -
写入文件:
然后,函数会将序列化后的数据写入到指定的文件中。这通常涉及到打开文件、写入数据、关闭文件等操作。 -
错误处理:
如果在序列化或写入文件的过程中发生错误(如磁盘空间不足、文件权限问题等),函数会进行相应的错误处理,如返回错误码或抛出异常。
void Algorithm::save(const String& filename) const
{
CV_TRACE_FUNCTION();
FileStorage fs(filename, FileStorage::WRITE);
fs << getDefaultName() << "{";
write(fs);
fs << "}";
}load函数实现原理
load函数的实现原理与save函数相反,通常涉及以下几个步骤:
-
参数验证:
首先,函数会验证传入的文件路径是否有效,以及文件是否包含有效的机器学习模型数据。 -
读取文件:
接着,函数会打开文件并读取其中的数据。这通常涉及到文件读取、数据解析等操作。 -
反序列化模型参数:
然后,函数会将读取的数据转换回原始的模型参数格式。这个过程通常被称为反序列化。具体的实现方式取决于模型参数的存储格式和算法的要求。 -
构建模型:
最后,函数会使用反序列化后的参数来构建或恢复机器学习模型的状态。这通常涉及到创建模型对象、设置参数值等操作。 -
错误处理:
如果在读取文件、解析数据或构建模型的过程中发生错误(如文件格式不匹配、数据损坏等),函数会进行相应的错误处理,如返回错误码或抛出异常。
class CV_EXPORTS_W Algorithm
{
public:
//...
template<typename _Tp> static Ptr<_Tp> load(const String& filename, const String& objname=String())
{
FileStorage fs(filename, FileStorage::READ);
CV_Assert(fs.isOpened());
FileNode fn = objname.empty() ? fs.getFirstTopLevelNode() : fs[objname];
if (fn.empty()) return Ptr<_Tp>();
Ptr<_Tp> obj = _Tp::create();
obj->read(fn);
return !obj->empty() ? obj : Ptr<_Tp>();
}
};
Ptr<SVM> SVM::load(const String& filepath)
{
FileStorage fs;
fs.open(filepath, FileStorage::READ);
Ptr<SVM> svm = makePtr<SVMImpl>();
((SVMImpl*)svm.get())->read(fs.getFirstTopLevelNode());
return svm;
}需要注意的是,不同的机器学习算法可能有不同的参数和存储需求,因此子类需要根据自己的需求来实现这些函数。