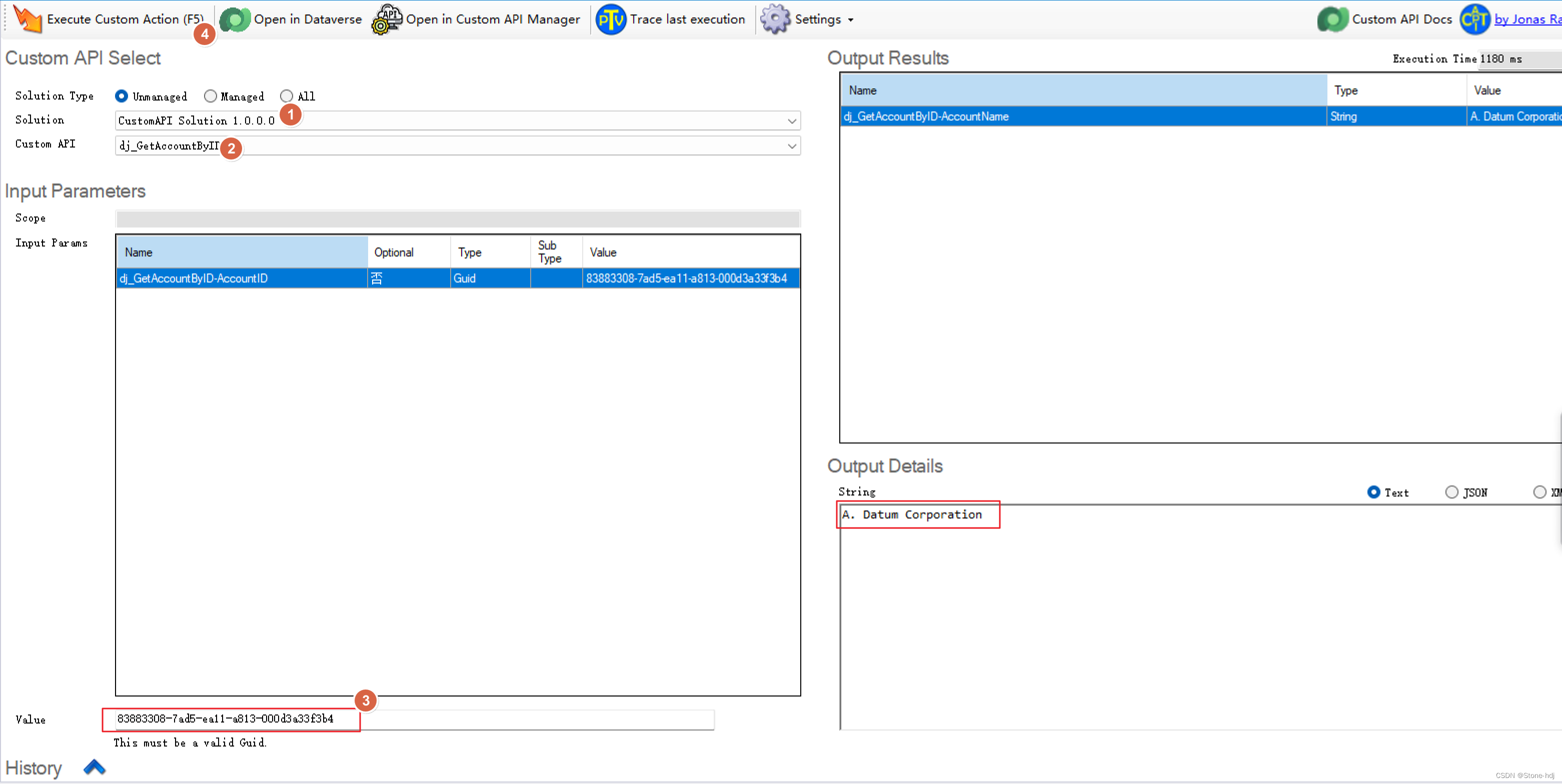
Instruction Selection 所处阶段
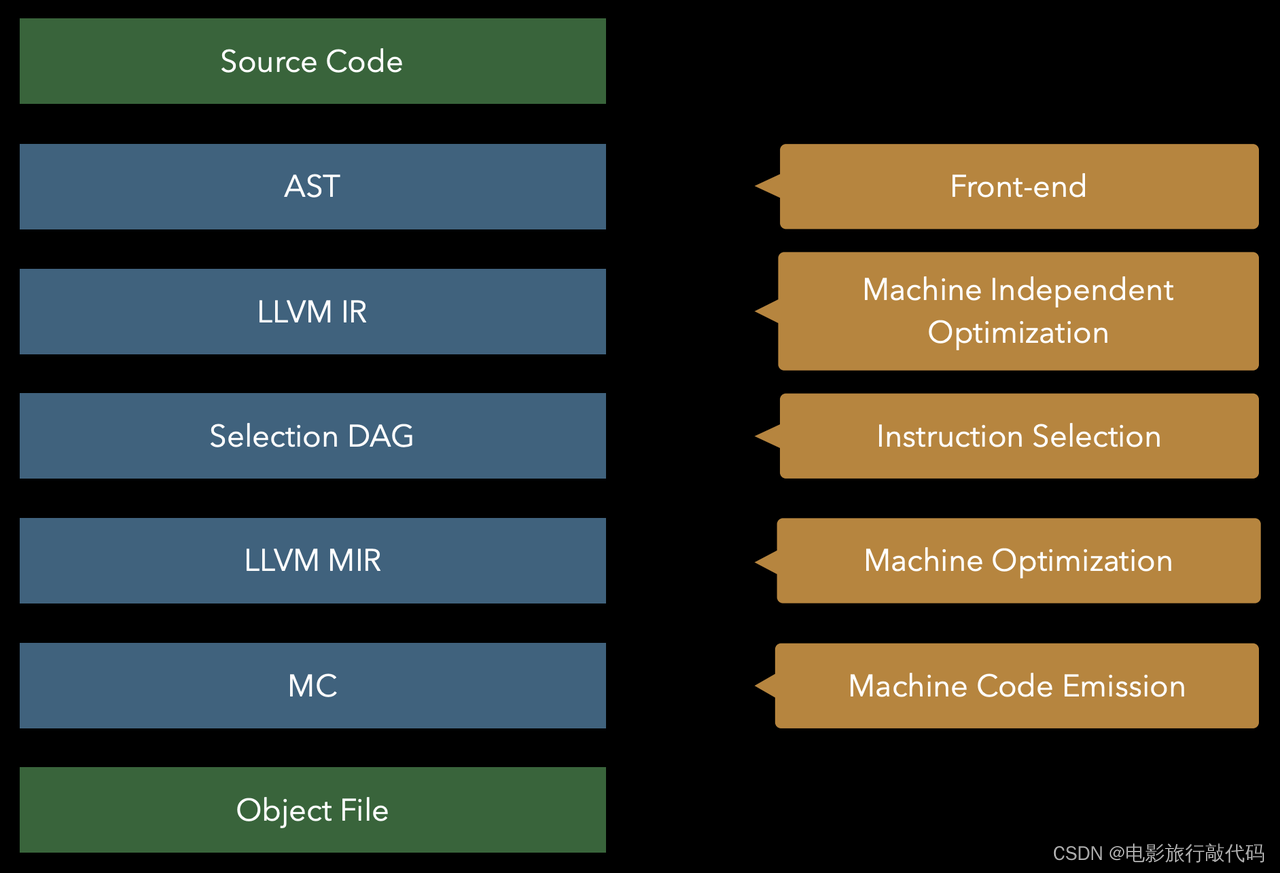
注:上图来源于 Welcome to the back-end: The LLVM machine representation
可以看到 SelectionDAG 架在 LLVM IR 和 LLVM MIR 之间,在此之前 machine independent optimization 已经完成。之后基本上就进入了 machine dependent 的阶段。
SelectionDAG
众所周知编译的过程就是将一种 “语言” 转换为另外一种 “语言”,其中要保持程序语义的性质不变,中间会做一些“变换”。常规认知中的编译是将 “高级语言” 变换为 “机器语言”,中间会经历一些列的 lowering 的阶段,每一个 lowering 的阶段几乎都会伴随一个中间的抽象形式来方便做性质分析和优化变换。对于常规的 C++ 语言来将,大致会经历如下几个阶段,

不同的 “抽象” 用于不同的目的,例如 LLVM IR SSA 用来更好的做优化,AST 用来做 syntax 和 semantic 检查,而 SelectionDAG 主要是用来做 Instruction Selection 以及一些的简单的变换(或者说 scheduling)。中间可能会穿插一些其它的辅助数据结构,例如 CFG, CallGraph 以及 Dom Tree等等。我们以下面的 C 代码为例,看下各个抽象分别长什么样子。
long imul(long a, long b) {
return a * b;
}| AST |
clang test.c -Xclang -ast-dump |
| LLVM IR SSA |
clang test.c -S -emit-llvm |
| LLVM IR CFG |
opt test.ll -passes='dot-cfg' |
| SelectionDAG |
llc test.ll --view-dag-combine1-dags=1 llc test.ll --view-isel-dags=1 llc test.ll --view-sched-dags=1 |
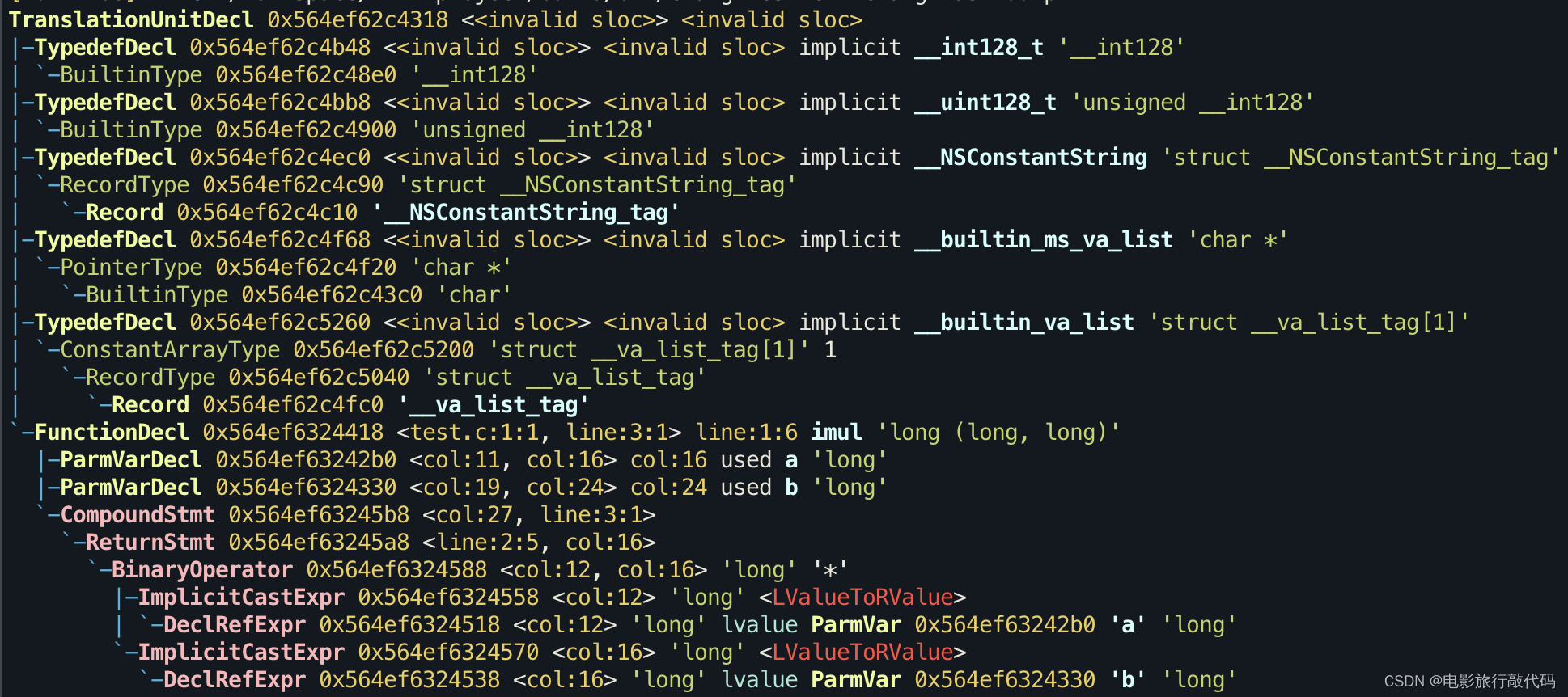
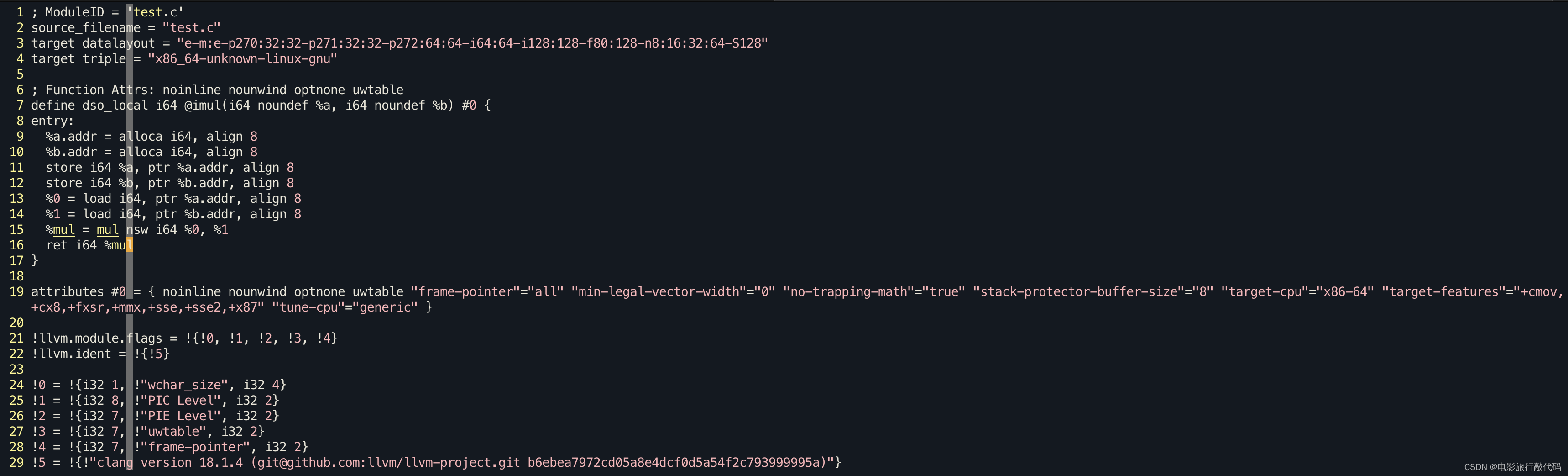

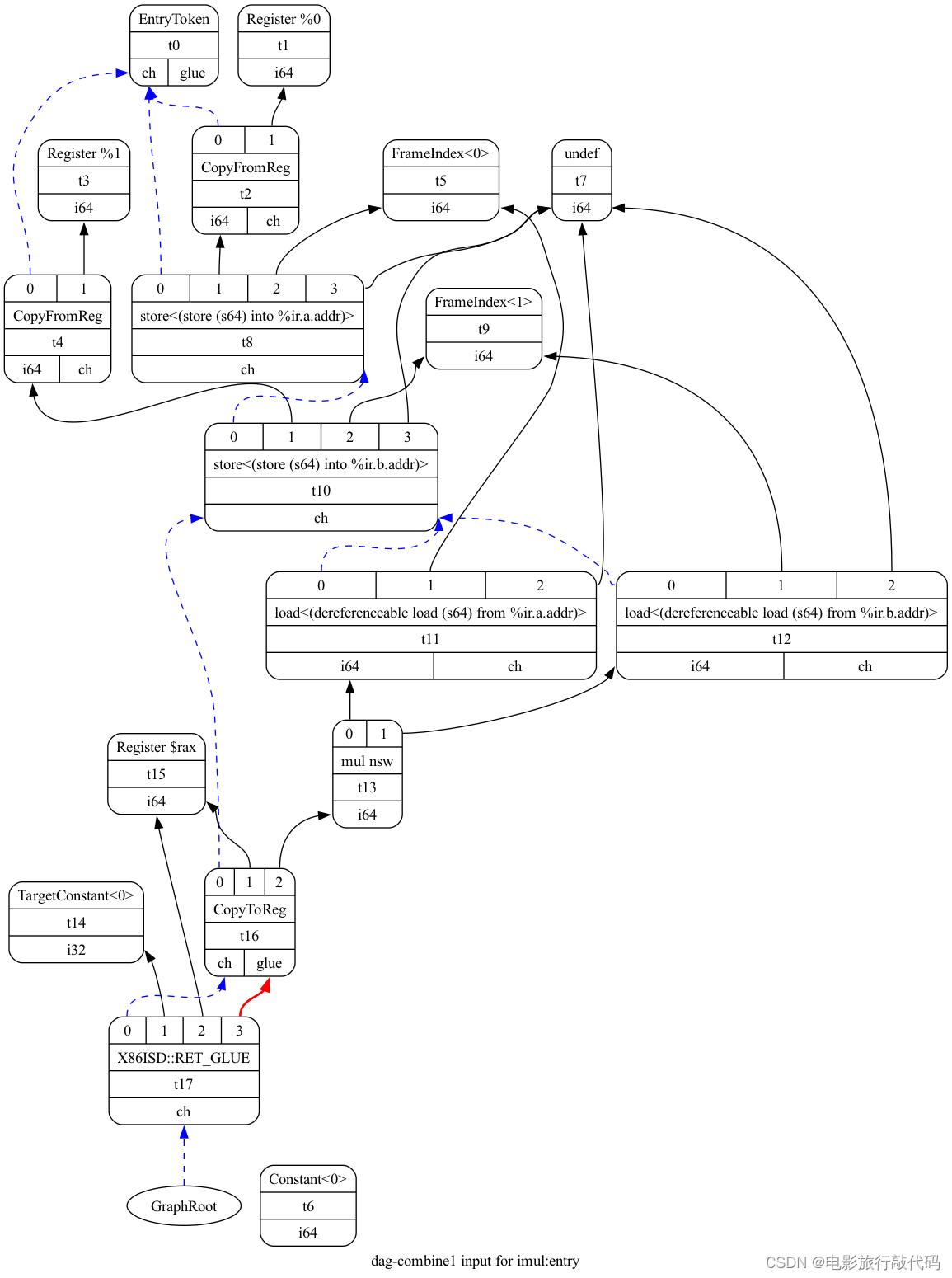
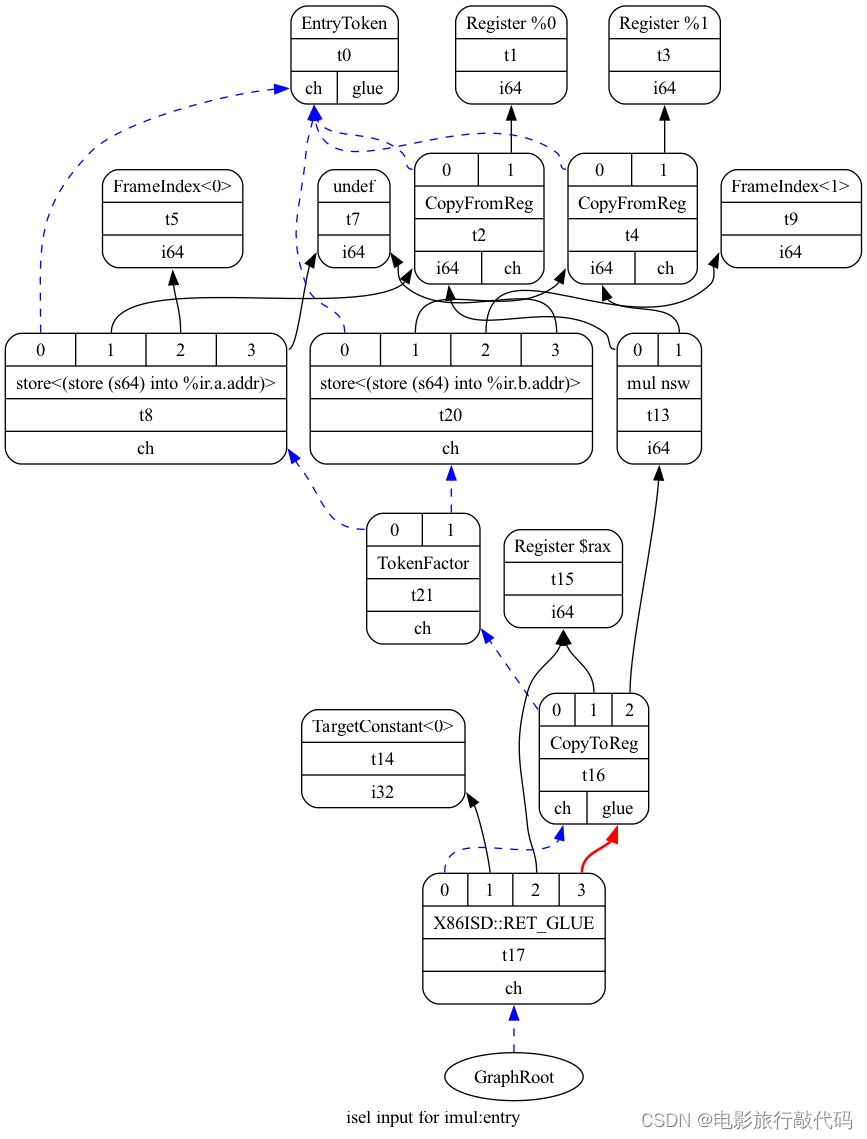
The SelectionDAG is a Directed-Acyclic-Graph whose nodes are instances of the
SDNodeclass. The primary payload of theSDNodeis its operation code (Opcode) that indicates what operation the node performs and the operands to the operation. The various operation node types are described at the top of theinclude/llvm/CodeGen/ISDOpcodes.hfile. The LLVM Target-Independent Code Generator — LLVM 19.0.0git documentation
SelectionDAG 是以 basic block 为单位的,也就是说后续的 instruction selection 所能看到的范围也是 basic block 内部。
| 源码 | |
| LLVM CFG |
opt test.cpp.ll -passes='dot-cfg' |
| Selection DAG |
llc test.cpp.ll --view-dag-combine1-dags=1 |

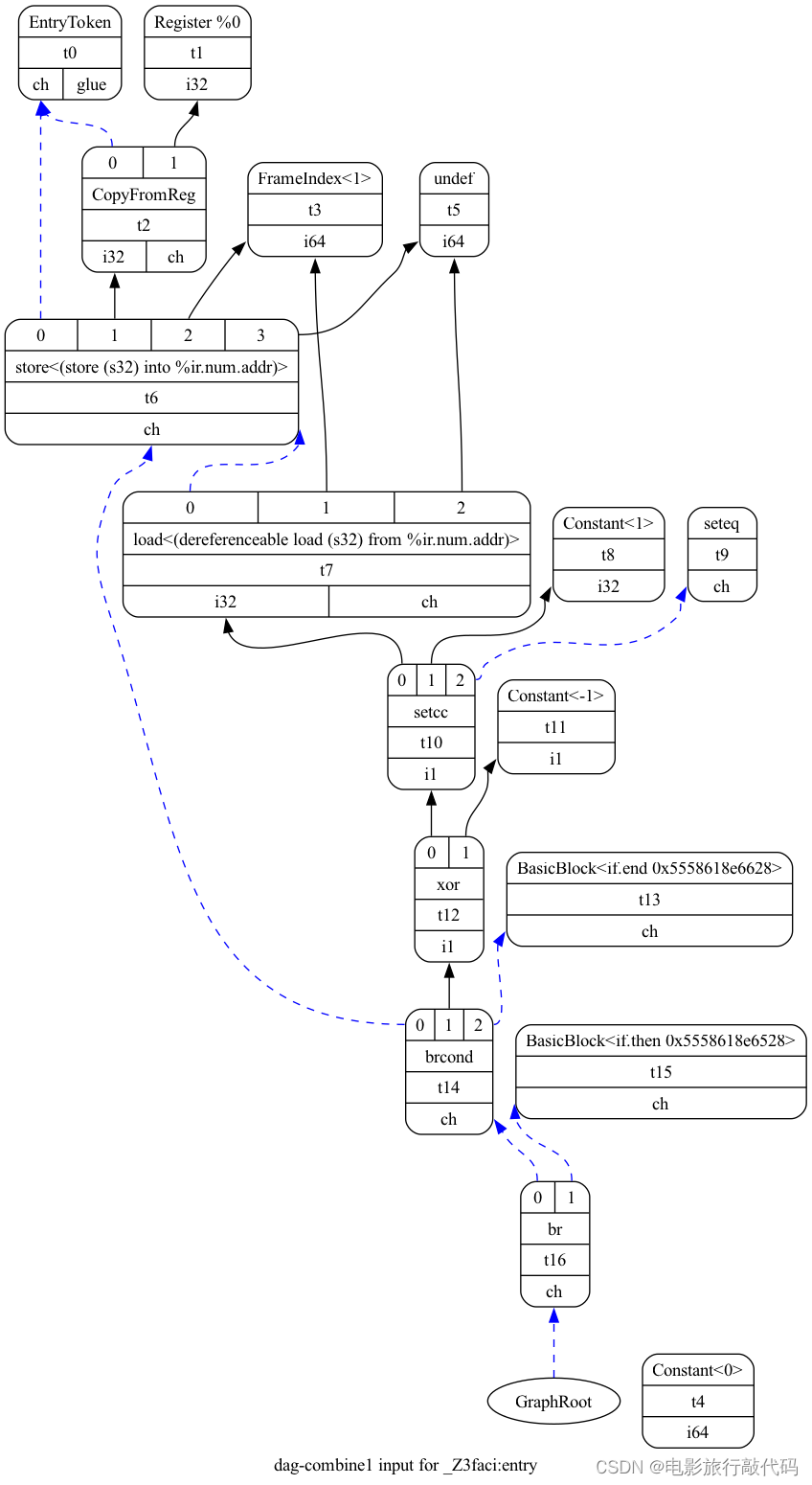


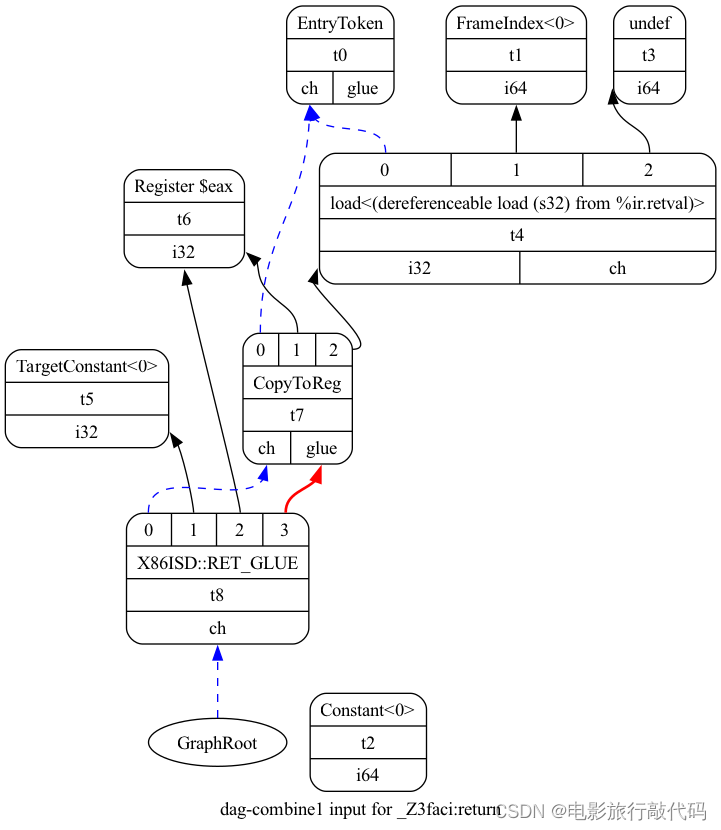
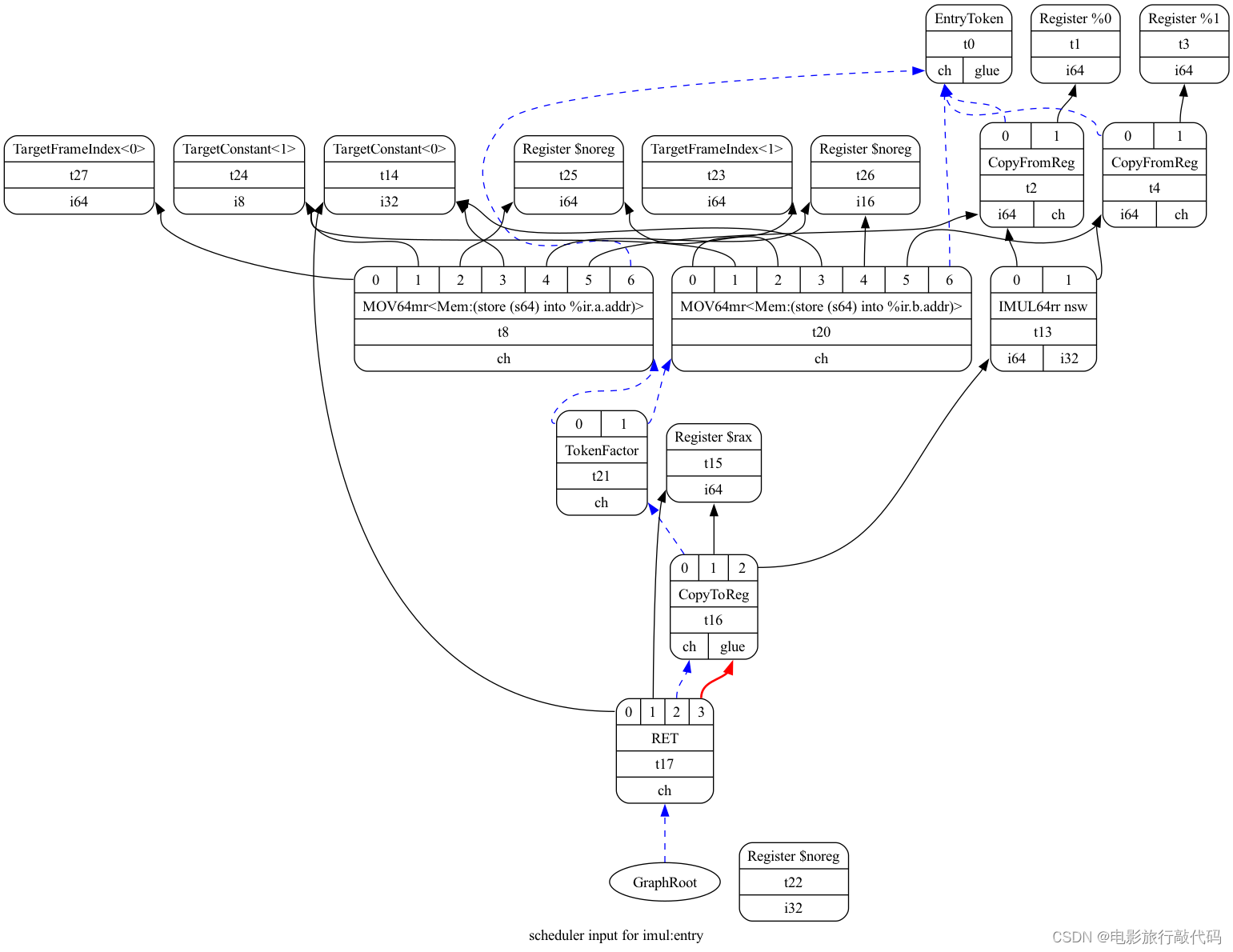
我们还是以下面的代码为例简单介绍其 SelectionDAG。
long imul(long a, long b) {
return a * b;
}
// LLVM IR
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i64 @imul(i64 noundef %a, i64 noundef %b) #0 {
entry:
%a.addr = alloca i64, align 8
%b.addr = alloca i64, align 8
store i64 %a, ptr %a.addr, align 8
store i64 %b, ptr %b.addr, align 8
%0 = load i64, ptr %a.addr, align 8
%1 = load i64, ptr %b.addr, align 8
%mul = mul nsw i64 %0, %1
ret i64 %mul
}Data flow dependencies: Simple edges with integer or floating point value type. Black Edges
Control flow dependencies: "chain" edges which are of type MVT::Other.
Chain edges provide an ordering between nodes that have side effects. Blue Edges
Glue Edges forbids breaking up instructions.
Convention:
Chain inputs are always operand #0
Chain results are always the last value produced by an operation
Entry & Root nodes
Entry node: A marker node with an Opcode of ISD::EntryToken.
Root node: Final side-effecting node in the token chain. The LLVM Target-Independent Code Generator — LLVM 19.0.0git documentation
下面的图有些复杂,这里分别介绍下
- 下图中每个节点都实例化自SDNode class,像是加减乘除等,详细的见 `include/llvm/CodeGen/ISDOpcodes.h`
- 每个 SDNode 有0个或者多个输入,边实例化自SDValue class
- SDNode 产生的 value 的类型为 Machine Value Type(MTV) 例如,i1 和 i8 分别表示 1bit 和 8bit 的整型
- 可能有副作用的节点会强行要求顺序,也就是会在输入和输出强行安插一个 chain dependence。
These edges provide an ordering between nodes that have side effects (such as loads, stores, calls, returns, etc). All nodes that have side effects should take a token chain as input and produce a new one as output. By convention, token chain inputs are always operand #0, and chain results are always the last value produced by an operation. The LLVM Target-Independent Code Generator — LLVM 19.0.0git documentation
我们可以看到 `t2` 和 `t4` 的 SDNode 的 OpCode 是 `CopyFromReg`。它表示 %a 和 %b 从外部来的值。
CopyFromReg - This node indicates that the input value is a virtual or physical register that is defined outside of the scope of this SelectionDAG.
FrameIndex<0> 和 FrameIndex<1> 用来表示栈上的一个对象,表示 %a.addr 和 %b.addr。
A serializaable representation of a reference to a stack object or fixed stack object.
实线表示有实际的值流动表示 flow dependencies。蓝色虚线表示 chain dependency,在指令调度时要保持顺序,例如下图中的两条 load 指令不能调度到最后一条 store 指令前面。因为它们可能会有隐含的“依赖关系”,例如可能会 access 同一块儿内存。所以编译器会额外添加一条 chain 依赖,使用 `ch` 表示。
//===- X86ISelDAGToDAG.cpp - A DAG pattern matching inst selector for X86 -===//
#define DEBUG_TYPE "x86-isel"
#define PASS_NAME "X86 DAG->DAG Instruction Selection"
//===--------------------------------------------------------------------===//
/// ISel - X86-specific code to select X86 machine instructions for
/// SelectionDAG operations.
///
class X86DAGToDAGISel final : public SelectionDAGISel {
bool runOnMachineFunction(MachineFunction &MF) override {
// Reset the subtarget each time through.
Subtarget = &MF.getSubtarget<X86Subtarget>();
IndirectTlsSegRefs = MF.getFunction().hasFnAttribute(
"indirect-tls-seg-refs");
// OptFor[Min]Size are used in pattern predicates that isel is matching.
OptForMinSize = MF.getFunction().hasMinSize();
assert((!OptForMinSize || MF.getFunction().hasOptSize()) &&
"OptForMinSize implies OptForSize");
SelectionDAGISel::runOnMachineFunction(MF);
return true;
}
}
bool SelectionDAGISel::runOnMachineFunction(MachineFunction &mf) {
SelectAllBasicBlocks(Fn);
}
void SelectionDAGISel::SelectAllBasicBlocks(const Function &Fn) {
ReversePostOrderTraversal<const Function*> RPOT(&Fn);
for (const BasicBlock *LLVMBB : RPOT) {
SelectBasicBlock(Begin, BI, HadTailCall);
}
}
void SelectionDAGISel::SelectBasicBlock(BasicBlock::const_iterator Begin,
BasicBlock::const_iterator End,
bool &HadTailCall) {
// Final step, emit the lowered DAG as machine code.
CodeGenAndEmitDAG();
}
void SelectionDAGISel::CodeGenAndEmitDAG() {
// Run the DAG combiner in pre-legalize mode.
{
NamedRegionTimer T("combine1", "DAG Combining 1", GroupName,
GroupDescription, TimePassesIsEnabled);
CurDAG->Combine(BeforeLegalizeTypes, AA, OptLevel);
}
// ...
// Third, instruction select all of the operations to machine code, adding the
// code to the MachineBasicBlock.
{
NamedRegionTimer T("isel", "Instruction Selection", GroupName,
GroupDescription, TimePassesIsEnabled);
DoInstructionSelection();
}
}
SelectionDAGBuilder 是构建 SelectionDAG 的入口,通过一组 `SelectionDAGBuilder::Visit*` 来进行 SelectionDAG 的构建,想要观察对于 store instruction 这种可能有副作用的指令是怎么创建 chain dependence 的话,可以通过 `SelectionDAGBuilder::visitStore()`。
The initial SelectionDAG is naïvely peephole expanded from the LLVM input by the
SelectionDAGBuilderclass. The intent of this pass is to expose as much low-level, target-specific details to the SelectionDAG as possible. This pass is mostly hard-coded (e.g. an LLVMaddturns into anSDNode addwhile agetelementptris expanded into the obvious arithmetic). This pass requires target-specific hooks to lower calls, returns, varargs, etc. For these features, the TargetLowering interface is used.
SelectionDAG ISel
在执行真正的 selection 之前,有很多的步骤,例如 dag combine, legalize 等等优化的过程。这里专注杂 instruction selection 的部分。

MatcherTable
MatcherTable 是 SelectionDAGISel 中比较基础的一个数据,这里先看一下这个 MatcherTable 长什么样子,有以下几点需要注意:
-
它是一个 unsigned char 超大数组(可能会有上百万个元素),基于什么由谁生成的?被谁用了?
-
有一堆
OPC_*开头的枚举类型,它们是做什么的?分别代表什么意思? -
里面有一些
TARGET_VAL(ISD::OR),TARGET_VAL是什么意思?ISD::OR又是什么意思? -
其中有很多注释,它们分别表示什么意思?
// build/lib/Target/X86/X86GenDAGISel.inc
/*===- TableGen'erated file -------------------------------------*- C++ -*-===*\
|* *|
|* DAG Instruction Selector for the X86 target *|
|* *|
|* Automatically generated file, do not edit! *|
|* *|
\*===----------------------------------------------------------------------===*/
#define TARGET_VAL(X) X & 255, unsigned(X) >> 8
static const unsigned char MatcherTable[] = {
/* 0*/ OPC_SwitchOpcode /*496 cases */, 74|128,121/*15562*/, TARGET_VAL(ISD::STORE),// ->15567
/* 5*/ OPC_RecordMemRef,
/* 6*/ OPC_RecordNode, // #0 = 'st' chained node
/* 7*/ OPC_Scope, 71|128,7/*967*/, /*->977*/ // 9 children in Scope
/* 10*/ OPC_RecordChild1, // #1 = $src
/* 11*/ OPC_Scope, 60, /*->73*/ // 24 children in Scope
/* 13*/ OPC_CheckChild1Type, MVT::v4f32,
/* 15*/ OPC_RecordChild2, // #2 = $dst
/* 16*/ OPC_CheckPredicate6, // Predicate_unindexedstore
/* 17*/ OPC_CheckPredicate7, // Predicate_store
/* 18*/ OPC_CheckPredicate, 42, // Predicate_nontemporalstore
/* 20*/ OPC_CheckPredicate, 49, // Predicate_alignednontemporalstore
/* 22*/ OPC_Scope, 15, /*->39*/ // 3 children in Scope
/* 24*/ OPC_CheckPatternPredicate7, // (Subtarget->hasAVX()) && (!Subtarget->hasVLX())
/* 25*/ OPC_CheckComplexPat0, /*#*/2, // selectAddr:$dst #3 #4 #5 #6 #7
/* 27*/ OPC_EmitMergeInputChains1_0,
/* 28*/ OPC_MorphNodeTo0, TARGET_VAL(X86::VMOVNTPSmr), 0|OPFL_Chain|OPFL_MemRefs,
6/*#Ops*/, 3, 4, 5, 6, 7, 1,
// Src: (st VR128:{ *:[v4f32] }:$src, addr:{ *:[iPTR] }:$dst)<<P:Predicate_unindexedstore>><<P:Predicate_store>><<P:Predicate_nontemporalstore>><<P:Predicate_alignednontemporalstore>> - Complexity = 422
// Dst: (VMOVNTPSmr addr:{ *:[iPTR] }:$dst, VR128:{ *:[v4f32] }:$src)
/* 39*/ /*Scope*/ 16, /*->56*/
/* 40*/ OPC_CheckPatternPredicate, 15, // (Subtarget->hasSSE1() && !Subtarget->hasAVX())
/* 42*/ OPC_CheckComplexPat0, /*#*/2, // selectAddr:$dst #3 #4 #5 #6 #7
/* 44*/ OPC_EmitMergeInputChains1_0,
// ...
}首先这个表格位于 X86GenDAGISel.inc,是基于 llvm/lib/Target/X86/X86.td 生成的,我们可以使用下面的命令来生成这个文件。
➜ llvm git:(release/18.x) ../build/bin/llvm-tblgen -gen-dag-isel ./lib/Target/X86/X86.td -I=include -I=lib/Target/X86 OPC_*定义在SelectionDAGISel的内部枚举类型BuiltinOpcodes中,下面划知识点,这个枚举类型会被 DAG state machine 用到。我们可以看到这些操作,有的是 Record Node,有的是 CaptureGlueInput,有的是 Move Child,有的是 Move Parent,有的是 Switch Type等等,应该是 state machine 状态转换的操作。行首注释与状态枚举之间的缩进长度指示了该状态的所属的层级。举例而言对于pattern (add a, (sub b, c)), 检查操作数b的范围与检查操作数c的范围两个状态是平级的,检查操作数字a的范围肯定优先于检查操作数 b 的范围(先匹配树的根节点,再叶子节点)。 利用缩进可以图形化阅读状态跳转表。
对于类似于 ISD::OR 的类型来说,它们的定义如下:
//===--------------------------------------------------------------------===//
/// ISD::NodeType enum - This enum defines the target-independent operators
/// for a SelectionDAG.
///
/// Targets may also define target-dependent operator codes for SDNodes. For
/// example, on x86, these are the enum values in the X86ISD namespace.
/// Targets should aim to use target-independent operators to model their
/// instruction sets as much as possible, and only use target-dependent
/// operators when they have special requirements.
///
/// Finally, during and after selection proper, SNodes may use special
/// operator codes that correspond directly with MachineInstr opcodes. These
/// are used to represent selected instructions. See the isMachineOpcode()
/// and getMachineOpcode() member functions of SDNode.
///
enum NodeType {
// ...
/// Bitwise operators - logical and, logical or, logical xor.
AND,
OR,
XOR,
// ...
}但是除此之外在 MatcherTable 中也有 X86::VMOVNTPSmr 这样的标识,这类表示就是 X86 自己的定义,它们全部定义在 build/lib/Target/X86/X86GenAsmMatcher.inc 中。
static const MatchEntry MatchTable0[] = {
{ 0 /* aaa */, X86::AAA, Convert_NoOperands, AMFBS_Not64BitMode, { }, },
{ 4 /* aad */, X86::AAD8i8, Convert__imm_95_10, AMFBS_Not64BitMode, { }, },
// ...
{ 14029 /* vmovntps */, X86::VMOVNTPSmr, Convert__Mem1285_1__Reg1_0, AMFBS_None, { MCK_FR16, MCK_Mem128 }, },
// ...
}类似于 X86::VMOVNTPSmr 这种标识基本上可以认为是 target-dependent operator code,与指令基本上有一一对应的关系。现在我们知道了 MatcherTable 中包含了一些和 state machine 相关的内容,这些内容涉及到 static machine 中的 state 和 转移的动作,同时包含一些 LLVM 指令选择时抽象出来的 MVT 和 ISD(target-independent operator code),以及 target 相关的 opcode(target-dependent)。那么 MatcherTable 中的一些注释代表什么意思呢?这些注释我们需要搭配着示例来解释。
void X86DAGToDAGISel::Select(SDNode *Node) {
switch (Opcode) {
default: break;
// ...
case Intrinsic::x86_tileloadd64:
case Intrinsic::x86_tileloaddt164:
case Intrinsic::x86_tilestored64: {
}
}
SelectCode(Node);
}整个过程的入口函数是 `llvm::X86DAGToDAGISel::Select` ,前半部分主要是 Intrinsic 的 select,最终会调用 `X86DAGToDAGISel::SelectCode`,而最终会调用 `llvm::SelectionDAGISel::SelectCodeCommon`,该函数是核心(它叫什么名字无所谓,关键是它的整个逻辑)。
先感受下核心函数大致分为几个部分,这里的核心是
-
首先会初始化此次为
SDNode选择指令所需要的数据结构,MatchScopes,RecoredNodes,InputChain,InputGlue 等(这些数据结构在注释中都写明了它的用途) -
一个 while 循环不停地根据 Opcode 来选择执行不同的动作,或更新当前状态,或跳转到下一状态
-
如果在匹配的过程中,发现匹配失败,如何进行回退,如何从所谓的栈上,也就是MatchScopes,回溯到前一个状态选择另外的状态进行匹配。
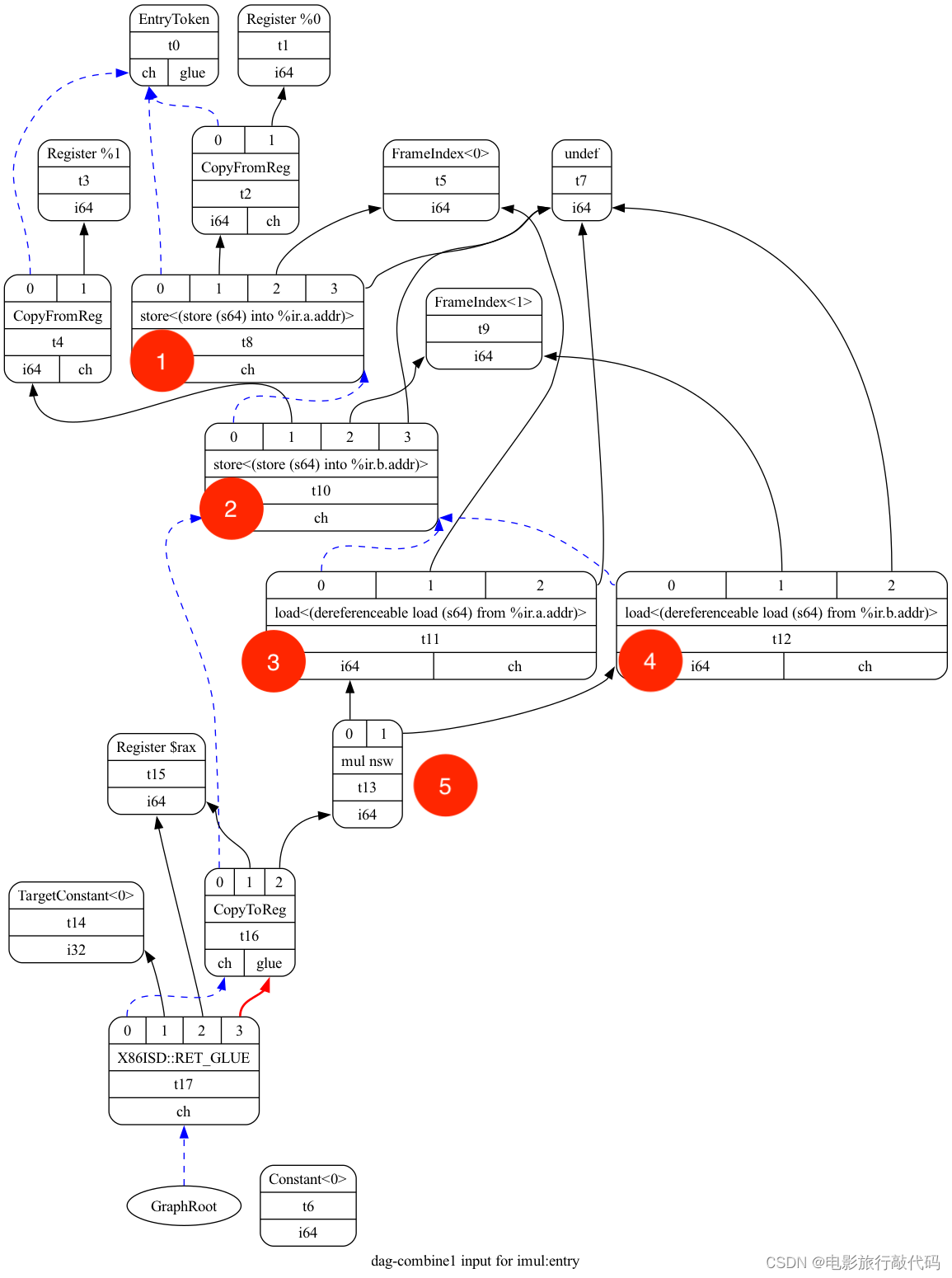
以代码中的 `mul` 指令为例,看看它是怎么选择的。在 state machine 转起来之前,先获取到 SDNode 的 `Opcode ISD::MUL`,它对应的 MatcherTable Index 是 57288(SelectCodeCommon会预先将各个 Opcode 在 MatcherTable 中对应的 Index 给缓存下来放到 OpcodeOffset),下面就让整个过程转起来。
%mul = mul nsw i64 %0, %1/* 96464*/ /*SwitchOpcode*/ 79|128,15/*1999*/, TARGET_VAL(ISD::MUL),// ->98467 /* 96468*/ OPC_Scope, 94, /*->96564*/ // 9 children in Scope /* 96470*/ OPC_MoveChild0, /* 96471*/ OPC_CheckOpcode, TARGET_VAL(ISD::LOAD), /* 96474*/ OPC_RecordMemRef, /* 96475*/ OPC_RecordNode, // #0 = 'ld' chained node /* 96476*/ OPC_CheckFoldableChainNode, /* 96477*/ OPC_RecordChild1, // #1 = $src1 /* 96478*/ OPC_CheckPredicate2, // Predicate_unindexedload /* 96479*/ OPC_Scope, 27, /*->96508*/ // 3 children in Scope /* 96481*/ OPC_CheckPredicate1, // Predicate_load /* 96482*/ OPC_MoveSibling1, /* 96483*/ OPC_CheckOpcode, TARGET_VAL(ISD::Constant), /* 96486*/ OPC_RecordNode, // #2 = $src2 /* 96487*/ OPC_CheckPredicate, 24, // Predicate_i64immSExt32 /* 96489*/ OPC_MoveParent, /* 96490*/ OPC_CheckTypeI64, /* 96491*/ OPC_CheckComplexPat0, /*#*/1, // selectAddr:$src1 #3 #4 #5 #6 #7 /* 96493*/ OPC_EmitMergeInputChains1_0, /* 96494*/ OPC_EmitConvertToTarget2, /* 96495*/ OPC_MorphNodeTo2, TARGET_VAL(X86::IMUL64rmi32), 0|OPFL_Chain|OPFL_MemRefs,MatcherTable
llc test.ll -debug-only=isel -O3 --debug
FastISel is disabled
=== imul
Optimized legalized selection DAG: %bb.0 'imul:entry'
SelectionDAG has 10 nodes:
t0: ch,glue = EntryToken
t4: i64,ch = CopyFromReg t0, Register:i64 %1
t2: i64,ch = CopyFromReg t0, Register:i64 %0
t5: i64 = mul nsw t4, t2
t8: ch,glue = CopyToReg t0, Register:i64 $rax, t5
t9: ch = X86ISD::RET_GLUE t8, TargetConstant:i32<0>, Register:i64 $rax, t8:1
===== Instruction selection begins: %bb.0 'entry'
ISEL: Starting selection on root node: t9: ch = X86ISD::RET_GLUE t8, TargetConstant:i32<0>, Register:i64 $rax, t8:1
ISEL: Starting pattern match
Morphed node: t9: ch = RET TargetConstant:i32<0>, Register:i64 $rax, t8, t8:1
ISEL: Match complete!
ISEL: Starting selection on root node: t8: ch,glue = CopyToReg t0, Register:i64 $rax, t5
ISEL: Starting selection on root node: t5: i64 = mul nsw t4, t2
ISEL: Starting pattern match
Initial Opcode index to 96468
Match failed at index 96471
Continuing at 96564
Match failed at index 96568
Continuing at 96739
Match failed at index 96742
Continuing at 96896
TypeSwitch[i64] from 96898 to 96935
Match failed at index 96935
Continuing at 96948
Match failed at index 96958
Continuing at 97003
Match failed at index 97004
Continuing at 97015
Match failed at index 97016
Continuing at 97042
Match failed at index 97043
Continuing at 97068
Morphed node: t5: i64,i32 = IMUL64rr nsw t4, t2
ISEL: Match complete!
===== Instruction selection ends:
Selected selection DAG: %bb.0 'imul:entry'
SelectionDAG has 11 nodes:
t0: ch,glue = EntryToken
t4: i64,ch = CopyFromReg t0, Register:i64 %1
t2: i64,ch = CopyFromReg t0, Register:i64 %0
t5: i64,i32 = IMUL64rr nsw t4, t2
t8: ch,glue = CopyToReg t0, Register:i64 $rax, t5
t10: i32 = Register $noreg
t9: ch = RET TargetConstant:i32<0>, Register:i64 $rax, t8, t8:1
Total amount of phi nodes to update: 0
*** MachineFunction at end of ISel ***
# Machine code for function imul: IsSSA, TracksLiveness
Function Live Ins: $rdi in %0, $rsi in %1
bb.0.entry:
liveins: $rdi, $rsi
%1:gr64 = COPY $rsi
%0:gr64 = COPY $rdi
%2:gr64 = nsw IMUL64rr %1:gr64(tied-def 0), %0:gr64, implicit-def dead $eflags
$rax = COPY %2:gr64
RET 0, $rax
# End machine code for function imul.整个过程类似于下图
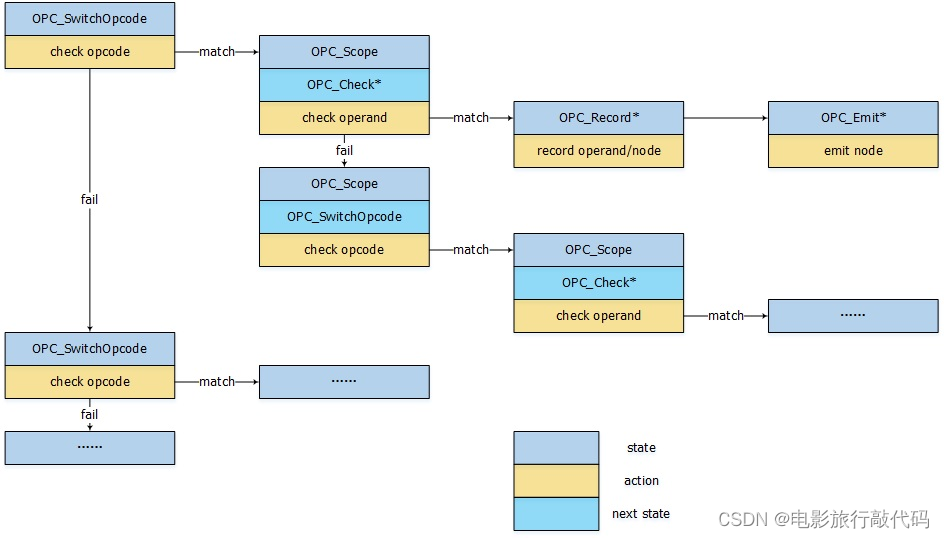
注:上图来源于 https://www.cnblogs.com/Five100Miles/p/12903057.html,介绍的非常深入
According to a blog entry by Bendersky [30] – which at the time of writing provided the only documentation except for the LLVM code itself – the instruction selector is basically a greedy DAG-to-DAG rewriter, where machine-independent DAG representations of basic blocks are rewritten into machine-dependent DAG representations.
The patterns, which are limited to trees, are expressed in a machine description format that allows common features to be factored out into abstract instructions.
Using a tool called TableGen, the machine description is then expanded into complete tree patterns which are processed by a matcher generator.
The matcher generator first performs a lexicographical sort on the patterns:
- first by decreasing complexity, which is the sum of the pattern size and a constant ( this can be tweaked to give higher priority for particular machine instructions);
- then by increasing cost;
- and lastly by increasing size of the output pattern.
Once sorted each pattern is converted into a recursive matcher which is essentially a small program that checks whether the pattern matches at a given node in the expression DAG. The table is arranged such that the patterns are checked in the order of the lexicographical sort. As a match is found the pattern is greedily selected and the matched subgraph is replaced with the output (usually a single node) of the matched pattern. Although powerful and in extensive use, LLVM’s instruction selector has several drawbacks. The main disadvantage is that any pattern that cannot be handled by TableGen has to be handled manually through custom C functions. Since patterns are restricted to tree shapes this includes all multiple-output patterns. In addition, the greedy scheme compromises code quality.
Survey on Instruction Selection
Global ISel
最原始的 proposal 来源于
- [LLVMdev] [global-isel] Proposal for a global instruction selector
- [GlobalISel] A Proposal for global instruction selection
按照下面的 motivation,SelectionDAG ISel 有一些问题,例如不是真正的 global instruction selector,慢,如 FastIsel 代码不共享,SelectionDAG 太 High Level 无法表示真正意义上的 Register 信息等等。
Motivation
Everybody loves to hate SelectionDAG, but it is still useful to make its shortcomings explicit. These are some of the goals for a new instruction selector architecture.
We want a global instruction selector.
SelectionDAG operates on a basic block at a time, and we have been forced to implement a number of hacks to work around that. For example, most of CodeGenPrepare is moving instructions around to make good local instruction selection more likely. Legalization of switches and selects must be done either before or after instruction selection because it requires creating new basic blocks.A number of passes running after instruction selection are also mostly about cleaning up after the single-basic-block selector. This includes MachineCSE, MachineLICM, and the peephole pass.
We want a faster instruction selector.
The SelectionDAG process is quite heavyweight because it uses continuous CSE, a whole new IR, and a mandatory scheduling phase to linearize the DAG. By selecting directly to MI, we can avoid one IR translation phase. By using a linearized IR, scheduling becomes optional.We want a shared code path for fast and good instruction selection.
Currently, the fast instruction selector used for -O0 builds is a completely separate code path. This is not healthy because it increases the likelihood of bugs in the fast path that were not present in the slow path. It would be better if the -O0 instruction selector were a trimmed down version of the full instruction selector.We want an IR that represents ISA concepts better.
The SelectionDAG IR is very good at representing LLVM IR directly, but as the code is lowered to model target machine concepts, weird hacks are often required. This is evident in the way too many SDNodes required to represent a function call, or the many custom ISD nodes that targets need to define.In many cases, custom target code knows exactly which instructions it wants to produce, and the IR should make it possible and easy to just emit the desired instructions directly. The MI intermediate representation isn't perfect either, and we should plan some MI improvements as well.
The SelectionDAG concept of legal types and their mapping to a single register class often causes problems. In some cases, it is necessary to lie about value types, just to get the instruction selector to do the right thing.
We want a more configurable instruction selector.
Weird targets have weird requirements, and it should be possible for targets to inject new passes into the instruction selection process. Sometimes, it may even be required to replace a standard pass.
SelectionDAG ISel 在 instruction selection 的同时完成 LLVM IR -> Machine IR 的转换。所以提出来了 Global ISel 的概念,中间也会涉及到一些转换。
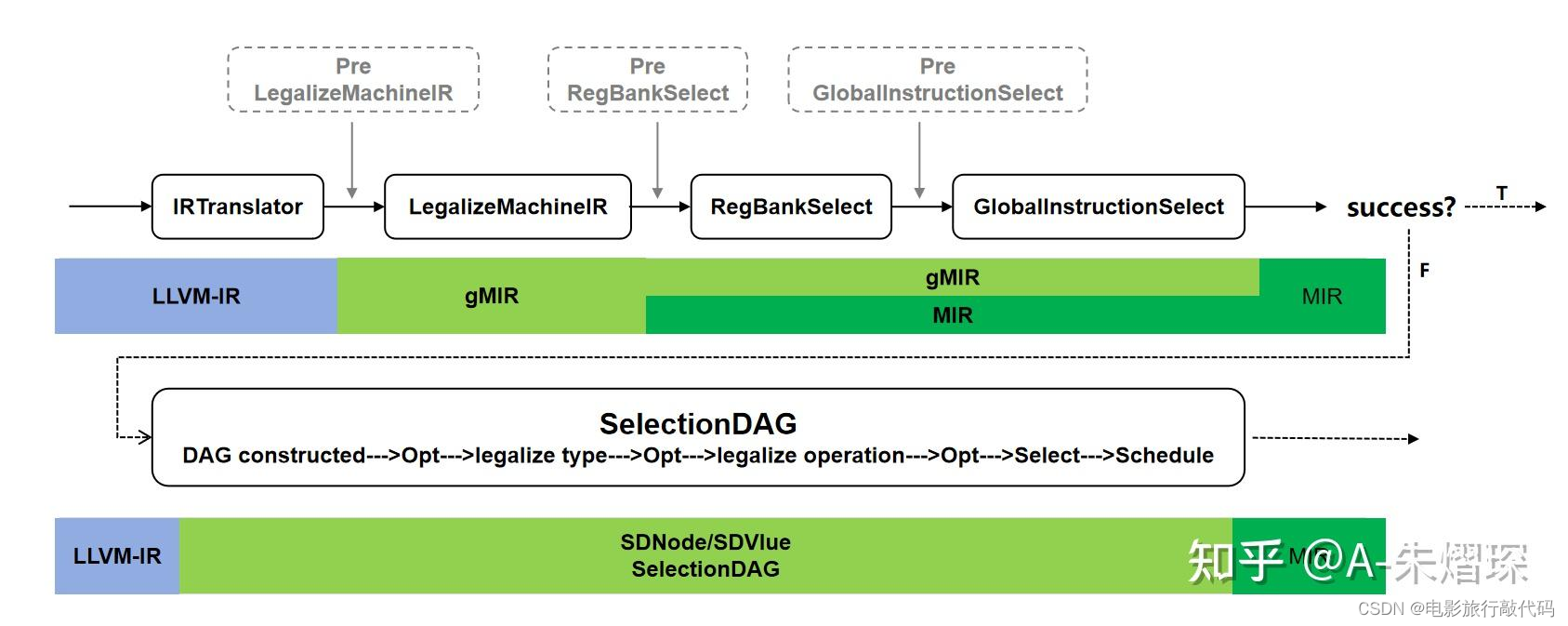
注:上图来源于 Global Instruction Selection(global-isel)

注:上图来源于 https://www.youtube.com/watch?v=S6SNs2ttdoA
但是按照目前的数据来看 Global ISel 比 SelectionDAG ISel 在编译耗时上有优势,性能上并没有 totally win。例如 https://www.youtube.com/watch?v=PEP0DfAT_N8 和 https://www.youtube.com/watch?v=S6SNs2ttdoA。本文不深入分析了
注:上图来源于 https://www.youtube.com/watch?v=F6GGbYtae3g
Reference
How to Write an LLVM Backend #4: Instruction Selection
LLVM笔记(10) - 指令选择(二) lowering https://sourcecodeartisan.com/2020/11/17/llvm-backend-4.html
https://www.youtube.com/watch?v=F6GGbYtae3g
https://www.youtube.com/watch?v=PEP0DfAT_N8
https://www.youtube.com/watch?v=S6SNs2ttdoA
https://llvm.org/devmtg/2017-10/slides/Bogner-Nandakumar-Sanders-Head%20First%20into%20GlobalISel.pdf