文章目录
- week37 GGNN
- 摘要
- Abstract
- 一、文献阅读
- 1. 题目
- 2. abstract
- 3. 网络架构
- 3.1 数据处理部分
- 3.2 门控图神经网络
- 3.3 掩码操作
- 4. 文献解读
- 4.1 Introduction
- 4.2 创新点
- 4.3 实验过程
- 4.3.1 传感器设置策略
- 4.3.2 数据集
- 4.3.3 实验设置
- 4.3.4 模型参数设置
- 4.3.5 实验结果
- 5. 结论
- 二、梯度、散度、旋度
- 三、实验内容
- 1. 数据集和问题定义
- 2. 数据集与数据结构展示
- 3. 网络框架定义
- 4. dataloader
- 5. training
- 6. analyzing
- 总结
- 参考文献
week37 GGNN
摘要
本周阅读了题为Real-time water quality prediction in water distribution networks using graph neural networks with sparse monitoring data的论文。该研究通过构建 GGNN 模型来捕获监测节点和非监测节点之间的空间拓扑关系,研究了使用机器学习进行 WDN 实时水质预测的泛化问题。为了提高预测精度,在模型训练期间实施了屏蔽操作,在每个训练批次中随机屏蔽指定百分比的传感器节点。尽管使用来自有限数量的传感器站点的水质数据进行训练,但该模型可以在整个网络中实现较高的预测精度。最后,本文以pytorch_gerometric实现了GCN网络,基于ESOL数据集实现了根据分子结构预测可溶性。
Abstract
This week read the paper titled Real-time water quality prediction in water distribution networks using graph neural networks with sparse monitoring data.This work studies the generalization problem of real-time water quality prediction of WDN using machine learning by constructing a GGNN model to capture the spatial topological relationship between monitoring nodes and non-monitoring nodes. This research implements a masking operation was implemented to improve the prediction accuracy, and a specified percentage of sensor nodes were randomly masked in each training batch. Although trained using water quality data from a limited number of sensor sites, the model can achieve high prediction accuracy across the network. At Last, this article implements he GCN network by pytorch_gerometric, and the solubility is predicted according to the molecular structure based on the ESOL dataset.
一、文献阅读
1. 题目
标题:Real-time water quality prediction in water distribution networks using graph neural networks with sparse monitoring data
作者:Zilin Li, etc.
期刊名:Water Research(一区12.8)
链接:https://doi.org/10.1016/j.watres.2023.121018
2. abstract
该研究提出了一种新颖的门控图神经网络 (GGNN) 模型,用于 WDN (水管网)中的实时水质预测。 GGNN模型集成了水力流向和水质数据来表示拓扑和系统动力学,并采用掩蔽操作进行训练以提高预测精度。真实WDN的评估结果表明,GGNN模型能够实现整个WDN的准确水质预测。尽管使用来自有限数量的传感器站点的水质数据进行训练,但该模型可以在整个网络(包括那些未监测的站点)中实现较高的预测精度(平均绝对误差 = 0.07 mg L−1 和平均绝对百分比误差 = 10.0 %)。此外,基于水质的传感器放置显著提高了预测准确性,强调了仔细选择传感器位置的重要性。这项研究通过提供实用且有效的机器学习解决方案来解决与有限的传感器数据和网络复杂性相关的挑战,从而推进了 WDN 的水质预测。这项研究为开发机器学习模型以取代 WDN 建模中的水力模型迈出了第一步。
This study proposes a novel gated graph neural network (GGNN) model for real-time water quality prediction in WDNs. The GGNN model integrates hydraulic flow directions and water quality data to represent the topology and system dynamics, and employs a masking operation for training to enhance prediction accuracy. Evaluation results from a real-world WDN demonstrate that the GGNN model is capable to achieve accurate water quality prediction across the entire WDN. Despite being trained with water quality data from a limited number of sensor sites, the model can achieve high predictive accuracies (Mean Absolute Error = 0.07 mg L−1 and Mean Absolute Percentage Error = 10.0 %) across the entire network including those unmonitored sites. Furthermore, water quality-based sensor placement significantly improves predictive accuracy, emphasizing the importance of careful sensor location selection. This research advances water quality prediction in WDNs by offering a practical and effective machine learning solution to address challenges related to limited sensor data and network complexity. This study provides a first step towards developing machine learning models to replace hydraulic models in WDN modelling.
3. 网络架构
3.1 数据处理部分
GGNN模型需要两类数据:传感器监测站的WDN拓扑结构和历史水质监测数据。假设一个WDN由n个节点和m条管道组成,配备 N s N_s Ns个传感器站监测水质。网络拓扑由图 G = ( V , E ) G=(V,E) G=(V,E)表示,其中V表示由水库、储罐和连接点组成的节点集,E表示由管道、阀门和泵组成的边集。网络的流向信息和空间拓扑细节通常可以从EPANET等水力模型中获得。利用这些数据构建有向图的邻接矩阵 A ∈ R n × n A\in \mathbb R^{n\times n} A∈Rn×n,其中每个元素 A i j A_{ij} Aij表示水是否从节点i流向节点j ( A i j = 1 A_{ij}=1 Aij=1)或不流向 ( A i j = 0 A_{ij}=0 Aij=0)。论文仅在边的权重相等时考虑水流方向。更进一步还可以同时考虑流量的动态变化和加权边。
通过在WDN中实现的监控和数据采集(SCADA)系统,可以获得各监测站的历史水质数据。该数据采集过程包括在指定的时间窗口内采集水质测量数据,记为 T c T_c Tc,也表示采集历史数据的周期时间。然后将采集到的数据作为数据集中被监测节点的节点属性,对于未被监测节点,将空值替换为0,得到节点属性 X ∈ R n × N c X\in \mathbb R^{n\times N_c} X∈Rn×Nc。 N c N_c Nc表示数据采集周期 T c T_c Tc内获得的水质测量次数,对应于指定时间窗口内的时间步数。它是预测下一时刻水质所需数据大小的指标。
3.2 门控图神经网络
为了解决WDN的非欧氏图域带来的挑战,将GGNN架构用于水质预测。GGNN是一种图神经网络,用于处理复杂的图结构数据,如WDN拓扑。它扩展了通常定义在欧氏域上的传统神经网络,使其能够直接处理非欧氏图数据。GGNN模型根据相邻节点和边之间传递的消息为每个节点 v ∈ V v\in V v∈V计算状态向量 h v h_v hv。状态向量 h v h_v hv表示节点学习到的特征表示,编码了关于图的局部和全局信息。它可以被认为是节点的隐藏状态,从其邻域和整个图中捕获相关信息。最终,状态向量可用于水质预测。GGNN的整体工作流程如下图所示。
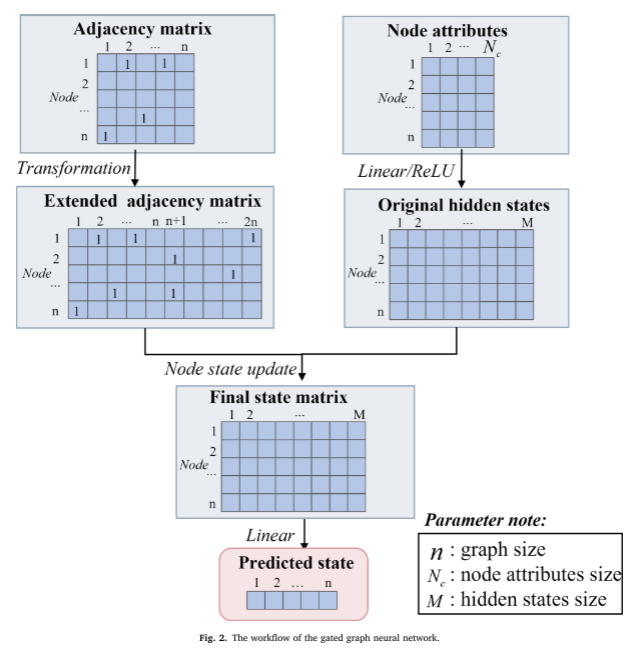

GGNN以扩展的邻接矩阵
A
^
=
[
A
,
A
T
]
\hat A=[A,A^T]
A^=[A,AT]和映射的节点属性
h
(
0
)
h^{(0)}
h(0)
为输入,在固定的k步上递归计算节点状态以产生最终的状态矩阵
h
(
K
)
∈
R
n
×
M
h(K)∈\mathbb R^{n×M}
h(K)∈Rn×M。在聚合阶段,利用扩展邻接矩阵
A
^
\hat A
A^计算聚合向量
a
v
a_v
av,
a
v
a_v
av表示节点v和相邻节点状态的聚合,聚合向量的计算公式如下:

其中,上标k表示时间步长, A ^ v ∈ R n × 2 \hat A_v\in \mathbb R^{n×2} A^v∈Rn×2是块 A ^ \hat A A^中对应节点v的两列,b是偏移向量。在聚合阶段之后,传播阶段采用门控循环单元(gated recurrent units, GRU)机制更新节点状态。GRU传播方程描述如下
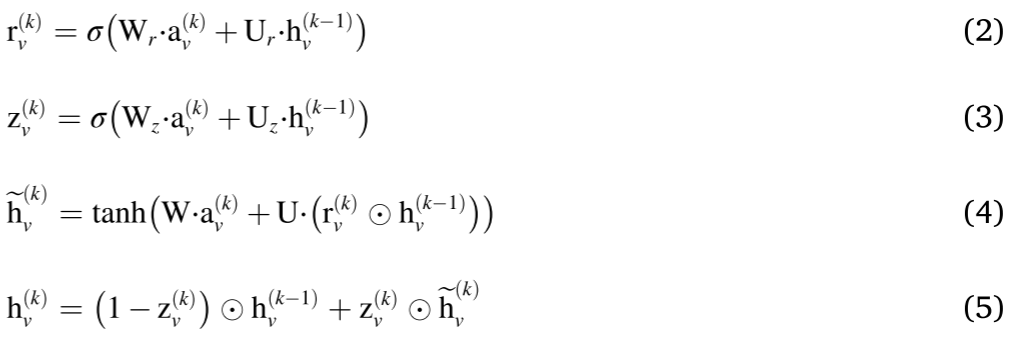
其中r和z是重置门和更新门; W r , W z , W W_r,W_z,W Wr,Wz,W和 U r , U z , U U_r,U_z,U Ur,Uz,U是每层的权重和偏差;σ(⋅)为sigmoid激活函数; ⊙ \odot ⊙是元素点积运算。
GGNN中的聚合和传播步骤允许模型迭代更新和细化节点状态,合并来自节点先前的特征及其邻近节点的特征信息。这个迭代过程捕获了图结构内的动态和交互规则,使GGNN能够学习和表示节点之间的复杂关系和依赖关系。传播步长K(也即GNN层数)决定了GGNN中信息传播的深度。当K=1时,每个节点只能从其近邻节点学习。随着K的增加,GGNN可以从距离K步的节点捕获信息,包括它们的间接连接。K的选择影响模型的学习能力和效率。较高的K值会导致训练较慢以及增加内存需求,而较低的K值会限制每个节点可以学习的依赖关系的数量。因此,K的选择应该在模型性能和计算效率之间取得平衡。
在使用GRU模块更新节点状态后,使用线性层将更新后的状态h(K)转换为表示每个节点预测状态的 Y ^ ∈ R n \hat Y\in \mathbb R^n Y^∈Rn。在本研究中,节点属性为历史水质浓度数据,其预测状态表示模型对每个节点下一时间步水质浓度的预测。这种转换允许模型根据其更新的表示和从邻近节点传播的信息在每个节点生成对水质的预测。
3.3 掩码操作
本文方法在训练阶段利用掩码操作来增强模型对未监测节点的预测能力。在训练过程中,结合掩码操作对解决两个重大挑战至关重要。
- 首先,现有研究通常假设传感器节点的输入,并根据模拟的网络中所有节点的值来计算损失,这在现实世界中是不切实际的,因为获取非传感器节点的测量数据很困难。论文使用模拟模型的合成数据,这样数据虽然完整,但作者并没有使用所有网络节点的所有数据进行训练。相反,只使用了一小部分节点数据。
- 其次,如果模型仅基于传感器节点的输入进行训练,并基于这些节点计算损失,可能会导致过拟合,阻碍模型预测未监测节点的水质的能力。
为了克服这些挑战,在训练过程中引入了掩码操作。随机选择指定比例(例如20%)的传感器节点,并通过在每个训练批次中将其输入替换为零进行掩盖。这个屏蔽操作有两个目的。
- 首先,在训练过程中模拟非传感器节点数据的不可用性,使模型能够在观测到的传感器数据之外进行泛化,并学习预测无监测节点的值;
- 其次,它作为正则化技术,防止模型仅依赖有限的传感器输入。
通过鼓励模型捕捉传感器节点和非监测节点之间的关系,提高模型的泛化能力,降低过拟合的可能性。需要研究掩码节点的比例,因为它可以平衡模型性能和过拟合。更高的比率会减少可用的信息,增加欠拟合的风险。较低的速率可以提供更多的信息,但可能会导致过拟合。因此,掩码率也是一个十分重要的超参数。
4. 文献解读
4.1 Introduction
研究机器学习在 WDN 内实时水质预测的潜力代表了一个及时的研究方向,对水务公司和参与水基础设施管理的决策者具有实际意义。但在该领域上机器学习也面对着许多挑战。首先,使用神经网络预测水质存在数据方面的限制,在面对差异化数据时较难获得同训练和预测所使用水域水平相近的结果。其次,传统神经网络在捕获网络节点的复杂动态方面存在局限性。而GNN能够应对WDN的复杂拓扑结构,揭示了解决上述多方面挑战的新途径。 GNN 的一个关键优势是能够从网络拓扑中提取基本信息并捕获 WDN 内复杂的空间依赖性。本研究提出了一种新颖的门控图神经网络 (GGNN) 方法,用于整个 WDN 所有节点的水质预测。 GGNN能够捕获网络的拓扑结构和流向,从而能够准确分析节点之间的空间相关性和依赖关系。GGNN 模型针对现实世界 WDN 中的氯预测进行了评估,结果验证了该模型的性能及其为 WDN 水质监测和管理实践进步做出贡献的潜力。
4.2 创新点
这项工作设计了一种模型,首先对)对供水网络信息进行数据处理,然后,使用基于GNN的神经网络(称为 GGNN)来预测WDN。主要贡献总结如下:
- GGNN 模型中掩蔽的结合显着增强了所有网络节点水质预测的泛化能力,凸显了 GGNN 模型作为 WDN 准确预测的有价值工具的潜力。
- 即使传感器数据有限,GGNN 模型也能利用网络拓扑和水力信息展现出强大的节点级预测能力。无论节点与传感器的距离如何,此功能都有助于提高整个 WDN 节点预测的整体准确性。
- 基于水质信息的传感器放置提高了模型的预测精度。重要的是,传感器放置的位置对预测精度的影响比部署的传感器的绝对数量更大。这凸显了仔细选择传感器位置以最大限度地提高水质监测工作有效性的重要性。
4.3 实验过程
4.3.1 传感器设置策略
研究中的传感器放置策略是通过两个过程生成的:基于 WDN 中安装的传感器数量 N 的网络聚类以及在每个聚类内选择适当的传感器节点。
采用Girvan-Newman聚类将WDN内的节点划分为 N s N_s Ns个簇
tip:Girvan-Newman聚类是一种基于边介数中心性的图聚类算法
具体来说,为要安装在 WDN 中的每个传感器创建一个集群。边介数中心性通过量化经过每条边的最短路径的数量来衡量网络中边的重要性。在GirvanNewman算法中,迭代地删除介数中心性最高的边,导致网络逐渐划分为多个相连的子图或簇。一旦网络形成集群,下一步就是在每个集群中选择合适的传感器节点。
该选择过程使用两种不同的方法:中间中心性方法和方差分析(ANOVA)方法。通过采用这两种不同的方法,传感器放置策略考虑了 WDN 的不同方面。介数中心性方法关注网络的拓扑意义,识别网络连通性方面有影响的节点。另一方面,方差分析方法结合了水质相关性,能够检测水质参数的变化。这两种方法的使用提供了一种综合的传感器放置方法,提高了网络内水质监测的有效性。
4.3.2 数据集
所提出的 GGNN 模型应用于中国的实际 WDN 案例研究:盐田网络。盐田管网由两个水源(S1和S2)、952个需求节点和1175条管道组成。网络中共有33个水质传感器站,其数据用于本研究。盐田网络为24小时需求模式,需求间隔为5分钟。
研究采用 EPANET 作为模拟工具来生成用于培训和测试目的的合成水质数据
模拟过程涉及应用在网络中的水源处测量的实际氯浓度。然后结合一阶衰变模型来模拟氯衰变。下图显示了水源(S1 和 S2)两个月内的氯浓度分布。
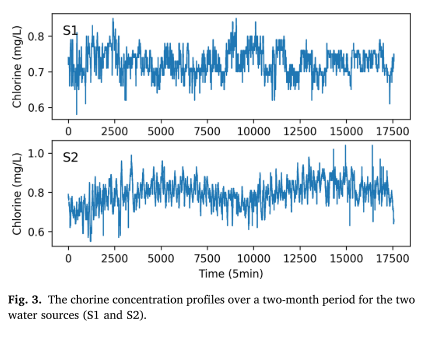
校准衰减模型的特点是 WDN 中所有管道的系数 k b = 0.25 ( d − 1 ) k_b = 0.25(d^{−1}) kb=0.25(d−1) 和 k w = 0.04 ( m d − 1 ) k_w = 0.04(m d^{−1}) kw=0.04(md−1) 值一致,分别代表整体和壁衰减的衰减率。该网络模拟了两个月(水力和水质),时间步长为 5 分钟。
4.3.3 实验设置
训练损失函数:使用MAE作为。
评估指标:MAE 和平均绝对百分比误差 (MAPE)
在应用阶段,不需要掩码操作,因为模型直接预测水质值。经过训练的 GGNN 模型用于预测整个 WDN 中所有节点的水质。具体来说,它利用 Tc 时间段内收集的历史水质数据来预测下一个时间步的水质。
训练集和测试集划分:由4.3.2产生的模拟氯数据涵盖两个月的时间,分为 80% 的训练集和 20% 的测试集。该划分允许评估 GGNN 模型的性能,因为它根据可用的传感器数据预测未监测节点的水质值。
4.3.4 模型参数设置
利用过去两小时的数据,间隔五分钟 ( N c = 24 N_c = 24 Nc=24),根据经验确定实验。测试了 1 到 5 小时内不同数量的过去数据,但 MAE 在 [0.070, 0.076] 范围内非常相似。所有实验和模型训练均在 Google Colab Pro 上进行。 GGNN 模型具有优化的超参数。隐藏状态大小设置为 128。为了从相邻节点捕获相关信息,该模型采用了 20 个传播步骤。在训练过程中,使用大小为 64 的小批量来确保高效计算。该模型训练了 30 个 epoch,采用 Adam 优化器有效优化模型参数。
4.3.5 实验结果
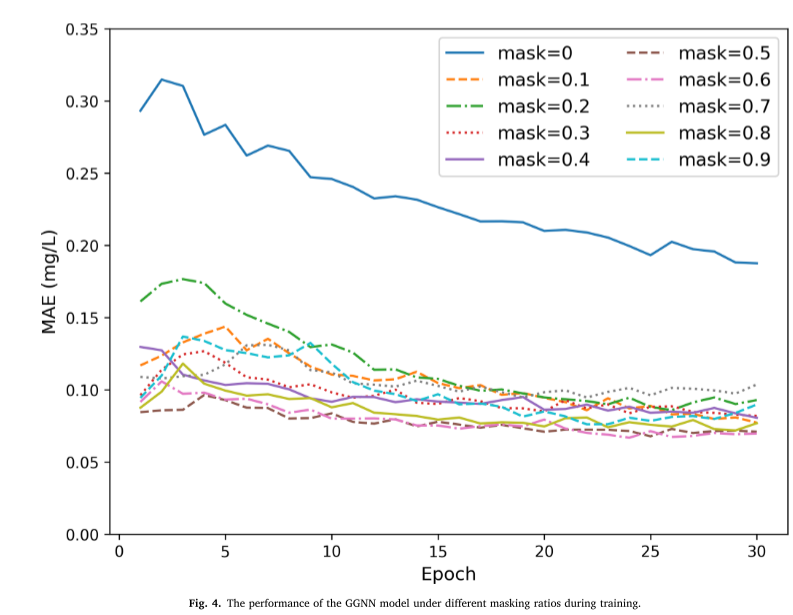
掩码操作对模型的影响:进行了 10 次实验,包括未掩蔽训练和掩蔽比率范围为 0.1 至 0.9 的训练。使用网络中所有 954 个节点(包括 2 个水源和 952 个需求节点)的 MAE 作为不同训练时期的评估指标。下图显示了模型在不同掩蔽条件和训练时期下的 MAE 结果。结果表明,所有掩蔽比率始终优于未掩蔽模型
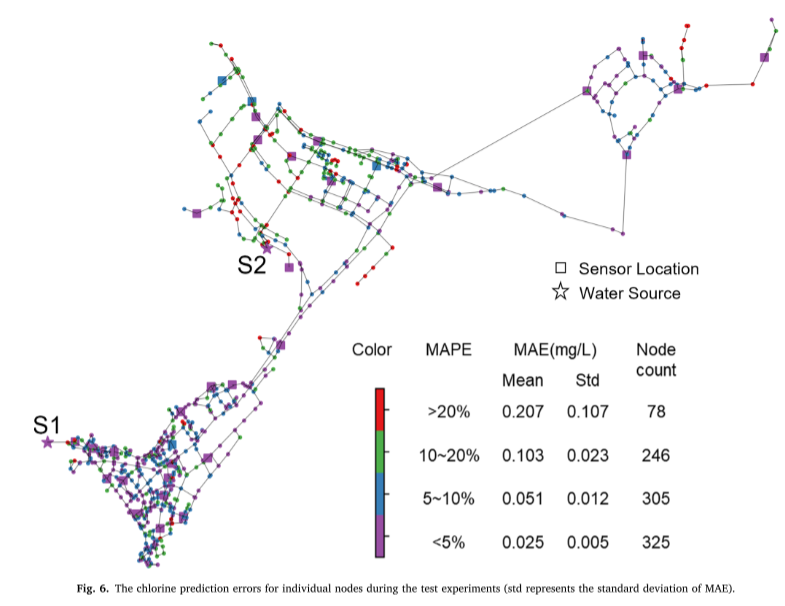
节点级预测精度:下图展示了 WDN 测试数据集中各个节点的预测精度分析(std 代表 MAE 的标准差)。节点根据其 MAPE 值分为四个级别。研究结果表明,节点之间的准确度水平各不相同,其中很大一部分节点的 MAPE 范围低于 5%。
5. 结论
该研究通过构建 GGNN 模型来捕获监测节点和非监测节点之间的空间拓扑关系,研究了使用机器学习进行 WDN 实时水质预测的泛化问题。为了提高预测精度,在模型训练期间实施了屏蔽操作,在每个训练批次中随机屏蔽指定百分比的传感器节点。此外,通过根据沿流动方向的边缘数量计算最短路径距离来检查传感器距离对预测精度的影响。此外,考虑到不同的传感器数量,使用介数中心性和方差分析方法评估了不同的传感器放置策略。
二、梯度、散度、旋度
- 偏微分方程
首先,偏微分方程的定义为:方程或式子中含有未知函数、导数或偏导数的方程即为偏微分方程。这样概括未免太过笼统,满足以下三个解释时,偏微分方程的定义能够被更好的说明:
①一个因素对另一个因素有所谓的变化率,且该变化率同其他的一些变量间有一定的比例关系。
②各个变量间有物理规律,用该类变量组成一个等式,且该式子中含有偏导数,或一个变量对另一个变量有导数的等式。
③变量本身不满足物理或者自然规律,但在微元的情况下,该变量满足物理概率或守恒律,可以使用微元分析法在微元中建立出一个积分方程,对该方程采用数学原理变成偏微分方程的形式。
-
算子
-
梯度算子
-
∇ = ( ∂ ∂ x , ∂ ∂ y , ∂ ∂ z ) = e ⃗ x ∂ ∂ x + e ⃗ y ∂ ∂ y + e ⃗ z ∂ ∂ z = ∑ i = 1 3 e ⃗ i ∂ ∂ i \nabla = (\frac{\partial}{\partial x},\frac{\partial}{\partial y},\frac{\partial}{\partial z})=\vec e_x\frac{\partial}{\partial x}+\vec e_y\frac{\partial}{\partial y}+\vec e_z\frac{\partial}{\partial z}=\sum^3_{i=1}\vec e_i\frac{\partial}{\partial i} ∇=(∂x∂,∂y∂,∂z∂)=ex∂x∂+ey∂y∂+ez∂z∂=i=1∑3ei∂i∂
-
该算子为向量,表示函数在某个点往哪个方向走,变化最快梯度为方向导数的最大值
-
标量函数与向量函数
- 标量函数:没有方向只标出数量的函数
- 向量函数:有大小,有方向, F ⃗ = ( f 1 , f 2 , . . , f N ) \vec F=(f_1,f_2,..,f_N) F=(f1,f2,..,fN)
-
-
散度算子
-
d i v ( F ) = ∇ ⋅ F = ∂ F x ∂ x + ∂ F y ∂ y + ∂ F z ∂ z div(F)=\nabla\cdot F=\frac{\partial F_x}{\partial x}+\frac{\partial F_y}{\partial y}+\frac{\partial F_z}{\partial z} div(F)=∇⋅F=∂x∂Fx+∂y∂Fy+∂z∂Fz
-
将 F ⃗ \vec F F的每个分量。对自变量的每个分量求偏导,然后求和,成为散度运算
-
即梯度算子对向量作内积
-
Δ = ∂ 2 ∂ x 1 2 + . . . + ∂ 2 ∂ x N 2 \Delta = \frac{\partial^2}{\partial x^2_1}+...+\frac{\partial^2}{\partial x^2_N} Δ=∂x12∂2+...+∂xN2∂2
上式为拉普拉斯算子,标量的梯度为矢量,故可对该矢量求散度,从而引入该算子
-
-
如果观察坐标系,可以发现对于梯度来说,其坐标系在外,观察点位于坐标系中任意一个点上。而散度,它的坐标系通常表示为它自身,即以观察点为中心,建立XYZ坐标系。
-
-
旋度算子
-
旋度由 ∇ \nabla ∇同矢量叉乘得到,运算结果为矢量,代表了矢量做旋转运动的方向和强度
-
r o t F ⃗ = ( ∂ R ∂ y − ∂ Q ∂ z , ∂ P ∂ z − ∂ R ∂ z ) rot\ \vec F=(\frac{\partial R}{\partial y}-\frac{\partial Q}{\partial z},\frac{\partial P}{\partial z}-\frac{\partial R}{\partial z}) rot F=(∂y∂R−∂z∂Q,∂z∂P−∂z∂R)
-
-
三、实验内容
1. 数据集和问题定义
本次实验的内容为基于分子结构预测物质可溶性,使用pytorch_gerometric进行开发,数据集为pytorch_geometric中的MoleclueNet的ESOL数据集
其中使用SMILES字符串编码表达分子结构,为了处理分子数据,需要安装rdkit。
2. 数据集与数据结构展示
from torch_geometric.datasets import MoleculeNet
data = MoleculeNet(root=".", name="ESOL")
print(data)
print("Dataset type: ", type(data))
print("Dataset features:", data.num_features)
print("Dataset target:", data.num_classes)
print("Dataset sample:", data[0])
print("Dataset Size:", len(data))
上述代码展示了数据集,其中包含1128个分子,每种分子有9个特征,存在734个分类

print(data[0].x)
print(data[0].edge_index.T)
print(data[0].y)
print("Dataset sample smiles:", data[0]["smiles"])
上述代码展示了第一种分子的参数,因输出较长故不作展示。edge_index描述边集
from rdkit import Chem
from rdkit.Chem import Draw
molecule = Chem.MolFromSmiles(data[0]["smiles"])
Draw.MolToFile(molecule, "mol.png")
print(f"Type of molecule: {type(molecule)}")
上述代码基于SMILES字符串,生成分子式,写入mol.png,即下图

3. 网络框架定义
embedding_size = 64
class GCN(nn.Module):
def __init__(self):
# Initialization
super().__init__()
torch.manual_seed(42)
# GCN Layers,第1层网络将特征转化为embedding
self.initial_conv = GCNConv(data.num_features, embedding_size)
self.conv1 = GCNConv(embedding_size, embedding_size)
self.conv2 = GCNConv(embedding_size, embedding_size)
self.conv3 = GCNConv(embedding_size, embedding_size)
# output layer,输出是一个线性层,将128维向量转成预测值,该值是个标量,维度和y相同,X2是因为下面要cat两个pooling
self.out = Linear(embedding_size*2, 1)
def forward(self, x , edge_index, batch_index):
# 1st Conv layer
hidden = self.initial_conv(x, edge_index)
hidden = torch.tanh(hidden)
# Other layers
hidden = self.conv1(hidden, edge_index)
hidden = torch.tanh(hidden)
hidden = self.conv2(hidden, edge_index)
hidden = torch.tanh(hidden)
hidden = self.conv3(hidden, edge_index)
hidden = torch.tanh(hidden)
# Global pooling
hidden = torch.cat((gmp(hidden, batch_index), gap(hidden, batch_index)), dim=1)
out = self.out(hidden)
return out, hidden
model = GCN()
print(model)
输入特征量为9,嵌入量为64。第一层将网络特征转换为embedding,后续接入三个gcn layer,每层后均有tanh激活。torch.cat将最大池化与平均池化两个向量连接在一起,维度变为128。输出层为线性层,将128维向量转换为标量。
4. dataloader
from torch_geometric.loader import DataLoader
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(),lr=0.0001)
data_size = len(data)
batch_size = 64
train_loader = DataLoader(data[:int(data_size*0.8)], batch_size=batch_size, shuffle=True)
test_loader = DataLoader(data[int(data_size*0.8):], batch_size=batch_size)
5. training
def train(data):
for batch in train_loader:
optimizer.zero_grad()
pred, embeding = model(batch.x.float(), batch.edge_index, batch.batch)
loss = torch.sqrt(loss_fn(pred, batch.y))
loss.backward()
optimizer.step()
return loss, embeding
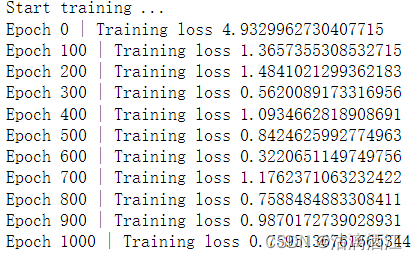
print("Start training ...")
losses = []
for epoch in range(1001):
loss, h = train(data)
losses.append(loss)
if epoch%100 == 0:
print(f"Epoch {epoch} | Training loss {loss}")
训练过程如下
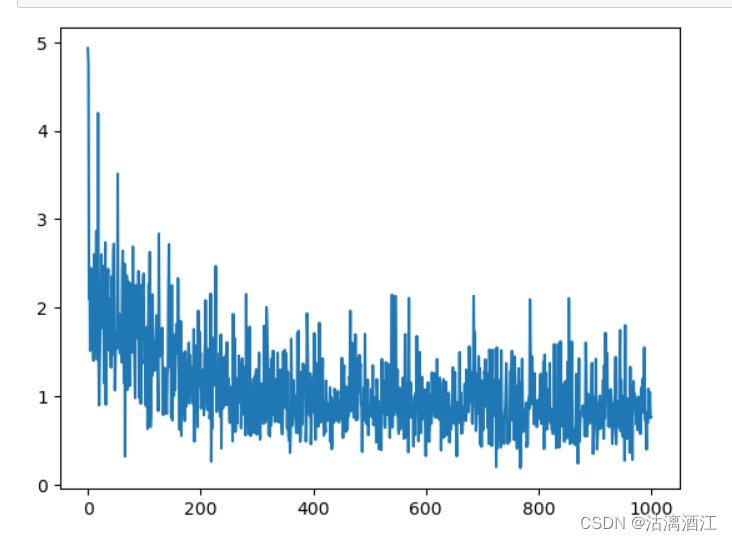
6. analyzing
import seaborn as sns
import matplotlib.pyplot as plt
losses_float = [float(loss) for loss in losses]
loss_indices = [i for i, l in enumerate(losses_float)]
sns.lineplot(losses_float)
plt.show()
这里使用了seaborn进行数据可视化,效果如下
总结
本周阅读的文献提出了GGNN,其将数据经过预处理后输入该网络,且该网络包含掩码操作,对于该模型的具体分析如下:
- GGNN 模型中掩蔽的结合显着增强了所有网络节点水质预测的泛化能力,凸显了 GGNN 模型作为 WDN 准确预测的有价值工具的潜力。
- 即使传感器数据有限,GGNN 模型也能利用网络拓扑和水力信息展现出强大的节点级预测能力。无论节点与传感器的距离如何,此功能都有助于提高整个 WDN 节点预测的整体准确性。
- 基于水质信息的传感器放置提高了模型的预测精度。重要的是,传感器放置的位置对预测精度的影响比部署的传感器的绝对数量更大。这凸显了仔细选择传感器位置以最大限度地提高水质监测工作有效性的重要性。
参考文献
[1] Zilin Li, etc., “Real-time water quality prediction in water distribution networks using graph neural networks with sparse monitoring data” [J], https://doi.org/10.1016/j.watres.2023.121018