为了更好地聚合和治理跨域数据,帮助企业用较低的成本快速聚合分析,快速决策,不断的让企业积累的数据产生价值,从全域海量数据抓取,高性能流批处理,元数据血缘治理等等方面都对数仓类产品提出了非常高的要求。OceanBase 以其天然的分布式架构,高效的存储引擎和强大的数据处理能力,可以很好的帮助企业快速构建低延迟,高性能,低成本的轻量级数据仓库。
目录
- 方案概要
- 方案优势
- 高效的 SQL 引擎
- 向量化执行技术
- 存储的向量化实现
- SQL 向量引擎的数据组织
- 并行执行技术
- 串行执行
- 并行执行
- 适用并行执行的场景
- 适用串行执行的场景
方案概要
- 通过 Flink CDC 组件作为流处理引擎,以 OceanBase 的 PL/SQL + Job Package 实现批处理任务,完成数据集成以及数据建模的流批一体处理。
- 同时通过向量引擎+多副本架构,实现数据与业务的协同以及时效性的保障。

方案优势
- 一体化极简架构:基于 OceanBase 的优化版 Lambda 架构,多系统,流批加工,多场景,分析于一体的一站式数据服务。
- 低成本海量存储:基于 LSM-Tree 以及高级压缩编码技术,存储成本相比传统方案降低 70% - 90%。
- CDC 低延迟高性能:CDC 持久化模式提升大事务传输能力,提供更高的数据处理加工性能以及即时分析决策能力。
- MPP 架构支撑高并发计算:OceanBase 的对等架构,天生支持多机并行计算,最大支持百 PB 容量,轻松为业务的全域数据提供稳定的存储底盘。
OceanBase 轻量级数仓的关键技术
高效的 SQL 引擎
向量化执行技术
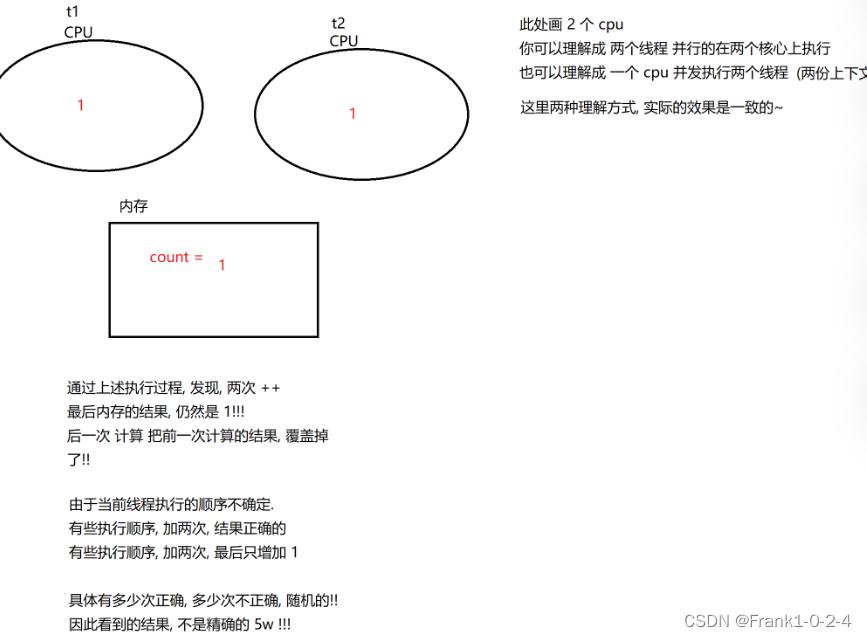
要让 HTAP 数据库具备 OLAP 的能力,尤其是大数据量 OLAP 的能力,除原生分布式架构、资源隔离,还需要给复杂查询和大数据量查询找到最优解。OceanBase 执行引擎的向量化执行,就是解决这个问题的核心技术之一。
为了更好地提高 CPU 利用率,减少 SQL 执行时的资源等待(Memory/Resource Stall) ,向量化引擎被提出并应用到现代数据库引擎设计中。 与数据库传统的火山模型迭代类似,向量化模型也是通过 PULL 模式从算子树的根节点层层拉取数据。区别于 next 调用一次传递一行数据,向量化引擎一次传递一批数据,并尽量保证该批数据在内存上紧凑排列。由于数据连续,CPU 可以通过预取指令快速把数据加载到 level 2 cache 中,减少 memory stall 现象,从而提升 CPU 的利用率。其次由于数据在内存上是紧密连续排列的,可以通过 SIMD 指令一次处理多个数据,充分发挥现代 CPU 的计算能力。
向量化引擎大幅减少了框架函数的调用次数。假设一张表有 1 亿行数据,按火山模型的处理方式需要执行 1 亿次迭代才能完成查询。使用向量化引擎返回一批数据 ,假设设置向量大小为 1024,则执行一次查询的函数调用次数降低为小于 10 万次( 1 亿/1024 = 97657 ),大大降低了函数调用次数。在算子函数内部,函数不再一次处理一行数据,而是通过循环遍历的方式处理一批数据。通过批量处理连续数据的方式提升 CPU DCache 和 ICache 的友好性,减少 Cache Miss。
由于数据库 SQL 引擎逻辑十分复杂,在火山模型下条件判断逻辑往往不可避免。但向量引擎可以在算子内部最大限度地避免条件判断,例如向量引擎可以通过默认覆盖写的操作,避免在 for 循环内部出现 if 判断,从而避免分支预测失败对 CPU 流水线的破坏,大幅提升 CPU 的处理能力。
存储的向量化实现
OceanBase 的存储系统的最小单元是微块,每个微块是一个默认 64KB(大小可调)的 IO 块。在每个微块内部,数据按照列存放。查询时,存储直接把微块上的数据按列批量投影到 SQL 引擎的内存上。由于数据紧密排列,有着较好的 cache 友好性,同时投影过程都可以使用 SIMD 指令进行加速。由于向量化引擎内部不再维护物理行的概念,和存储格式十分契合,数据处理也更加简单高效。整个存储的投影逻辑如下图:

SQL 向量引擎的数据组织
SQL 引擎的向量化先从的数据组织和内存编排说起。在 SQL 引擎内部,所有数据都被存放在表达式上,表达式的内存通过 Data Frame 管理。Data Frame 是一块连续内存(大小不超过 2MB), 负责存放参与 SQL 查询的所有表达式的数据。SQL 引擎从 Data Frame 上分配所需内存,内存编排如下图。

在非向量化引擎下,一个表达式一次只能处理一个数据(Cell)(上图左)。
向量化引擎下,每个表达式不再存储一个 Cell 数据,而是存放一组 Cell 数据,Cell 数据紧密排列(上图右)。这样表达式的计算都从单行计算变成了批量计算,对 CPU 的 cache 更友好,数据紧密排列也非常方便的使用 SIMD 指令进行计算加速。另外每个表达式分配 Cell 的个数即向量大小, 根据 CPU Level2 Cache 大小和 SQL 中表达式的多少动态调整。调整的原则是尽量保证参与计算的 Cell 都能存在 CPU 的level2 cache 上,减少 memory stalling 对性能的影响。
并行执行技术
SQL 的执行引擎需要处理很多情况,为什么要对这些情况进行细分呢?是因为 OceanBase 希望在每种情况下都能自适应地做到最优。从最大的层面上来说,每一条 SQL 的执行都有两种模式:串行执行或并行执行,可以通过在 SQL 中增加 hint /*+ parallel(N) */ 来决定是否走并行执行以及并行度时多少。

串行执行
如果这张表或者这个分区是位于本机的,这条路线和单机 SQL 的处理是没有任何区别的。如果所访问的是另外一台节点上的数据,有两种做法:一种是当数据量比较小时,会把数据从远程拉取到本机来,OceanBase 中叫做远程数据获取服务;当数据量比较大时,会自适应地选择远程执行,把这条 SQL 发送到数据所在节点上,将整条 SQL 代理给这个远程节点,执行结束之后再从远程节点返回结果。如果单条 SQL 要访问的数据位于很多个节点上,会把计算压到每个节点上,并且为了能够达到串行执行(在单机情况下开销最小)的效果,还会提供分布式执行能力,即把计算压给每个节点,让它在本机做处理,最后做汇总,并行度只有 1,不会因为分布式执行而增加资源额外的消耗。
对于串行的执行,一般开销最小。这种执行计划,在单机做串行的扫描,既没有上下文切换,也没有远程数据的访问,是非常高效的。
并行执行
并行执行同时支持 DML 写入操作的并行执行和查询的并行执行,对并行查询分还会再去自适应地选择是本机并行执行还是分布式并行执行。
对于当前很多小规模业务来说,串行执行的处理方式足够。但如果需要访问大量数据时,可以在 OceanBase 单机内引入并行能力,目前,这个能力很多开源的单机数据库还不支持,但只要有足够多的 CPU,是可以通过并行的方式使得单条 SQL 处理能力线性地缩短时间,只要有一个高性能多核服务器增加并行就可以了。
针对同样形式的分布式执行计划,可以让它在多机上分布式去做并行,这样可以支撑更大的规模,突破单机 CPU 的数目,去做更大规模的并行,比如从几百核到几千核的能力。

OceanBase 的并行执行框架可以自适应地处理单机内并行和分布式并行。这里所有并行处理的 Worker 既可以是本机上多个线程,也可以是位于很多个节点上的线程。我们在分布式执行框架里有一层自适应数据的传输层,对于单机内的并行,传输层会自动把线程之间的数据交互转换成内存拷贝。这样把不同的两种场景完全由数据传输层抽象掉了,实际上并行执行引擎对于单机内的并行和分布式并行,在调度层的实现上是没有区别的。

适用并行执行的场景
并行执行通过充分利用多个 CPU 和 IO 资源,达到降低 SQL 执行时间的目的。当满足下列条件时,使用并行执行会优于串行执行:
- 访问的数据量大
- SQL 并发低
- 要求低延迟
- 有充足的硬件资源
并行执行用多个处理器协同并发处理同一任务,在这样的系统中会有收益:
- 多处理器系统(SMPs)、集群
- IO 带宽足够
- 内存富余(可用于处理内存密集型操作,如排序、建 hash 表等)
- 系统负载不高,或有峰谷特征(如系统负载一般在30%以下)
并行执行不仅适用于离线数据仓库、实时报表、在线大数据分析等 AP 分析型系统,而且在 OLTP 领域也能发挥作用,可用于加速 DDL 操作、以及数据跑批工作等。但是,对于 OLTP 系统中的普通 SELECT 和 DML 语句,并行执行并不适用。
适用串行执行的场景
串行执行使用单个线程来执行数据库操作,在下面这些场景下使用串行执行会优于并行执行:
- Query 访问的数据量很小
- 高并发
- Query 执行时间小于 100 毫秒
并行执行一般不适用于如下场景:
- 系统中的典型 SQL 执行时间都在毫秒级。并行查询本身有毫秒级的调度开销,对于短查询来说,并行执行带来的收益完全会被调度开销所抵消。
- 系统负载本就很高。并行执行的设计目标就是去充分利用系统的空余资源,如果系统本身已经没有空余资源,那么并行执行并不能带来额外收益,相反还会影响系统整体性能。
[ 参考来源 ] : OceanBase官网