文章涉及具体代码gitee: 登录 - Gitee.com
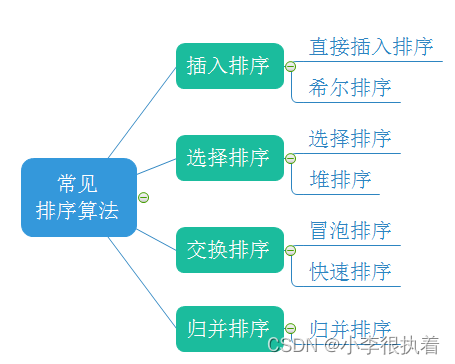
目录
1.插入排序
1.直接插入排序
总结
2.希尔排序
总结
2.选择排序
1.选择排序
编辑
总结
2.堆排序
总结
3.交换排序
1.冒泡排序
总结
2.快速排序
总结
4.归并排序
总结
5.总的分析总结
1.插入排序
具体分析过程见我的博客插入排序:http://t.csdnimg.cn/FauY7
1.直接插入排序
void InsertSort(int* a, int n)
{
// [0, end] end+1
for (int i = 0; i < n - 1; ++i)
{
int end = i;
int tmp = a[end + 1];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + 1] = a[end];
--end;
}
else
{
break;
}
}
a[end + 1] = tmp;
}
}

总结
直接插入排序是一种简单观的排序算法,它基本思想是将待排序的元逐个插入到已经排好序的序列中,直到所有元素都插入完成为止下面是对直接插入排序的析总结:
时间复杂度:
- 最好情况下待排序序列已经是有序的此时只需要比较n-1次,时间复杂度为O(n)。
- 最坏情况下,待排序序列是逆序的,此时需要比较和移动元素的次数最多,时间复杂度为O(n^2)。
- 平均情况下,假设待排序序列中的每个元素都等概率地出现在任何位置,那么平时间复杂度为O(n^2)。
空间复杂度: 直接插入排序是一种原地排序算法,不需要额外的空间存储数据,所以空间复杂度为O(1)。
稳定性: 直接插入排序是一种稳定的排序算法,相等元素的相对位置在排序前后不会发生改变。
适用性:
- 对于小规模的数据或者基本有序的数据,直接插入排序是一种简单高效的排序算法。
- 但对于大规模乱序的数据,直接插入排序的性能较差,不如快速排序、归并排序等高效。
2.希尔排序
void ShellSort(int* a, int n)
{
int gap = n;
// gap > 1时是预排序,目的让他接近有序
// gap == 1是直接插入排序,目的是让他有序
while (gap > 1)
{
//gap = gap / 2;
gap = gap / 3 + 1;
for (int i = 0; i < n - gap; ++i)
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}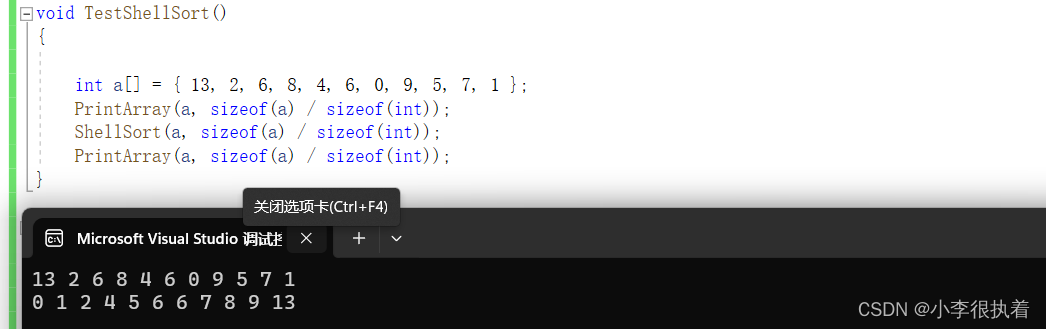
总结
希尔排序是一种基于插入排序的排序算法,它通过将待排序的元素按照一定的间隔分组,对每个分组进行插入排序,然后逐渐缩小间隔,直到间隔为1,最后进行一次完整的插入排序。希尔排序的主要思想是通过较大的步长先将数组局部有序,然后逐渐减小步长,最终使得整个数组有序。
希尔排序的分析总结如下:
- 时间复杂度:希尔排序的时间复杂度与步长序列的选择有关。最好情况下,当步长序列为1时,希尔排序的时间复杂度为O(nlogn);最坏情况下,当步长序列为2^k-1时,希尔排序的时间复杂度为O(n^2);平均情况下,希尔排序的时间复杂度为O(nlogn)。
- 空间复杂度:希尔排序的空间复杂度为O(1),即不需要额外的空间存储数据。
- 稳定性:希尔排序是不稳定的排序算法,即相同元素的相对位置可能会发生改变。
- 对于大规模数据和中等规模数据,希尔排序相对于其他简单的排序算法(如插入排序、冒泡排序)具有较好的性能。
2.选择排序
1.选择排序
// 时间复杂度:O(N^2)
// 最好的情况下:O(N^2)
void SelectSort(int* a, int n)
{
int begin = 0, end = n - 1;
while (begin < end)
{
int mini = begin, maxi = begin;
for (int i = begin + 1; i <= end; ++i)
{
if (a[i] < a[mini])
{
mini = i;
}
if (a[i] > a[maxi])
{
maxi = i;
}
}
Swap(&a[begin], &a[mini]);
if (maxi == begin)
{
maxi = mini;
}
Swap(&a[end], &a[maxi]);
++begin;
--end;
}
}
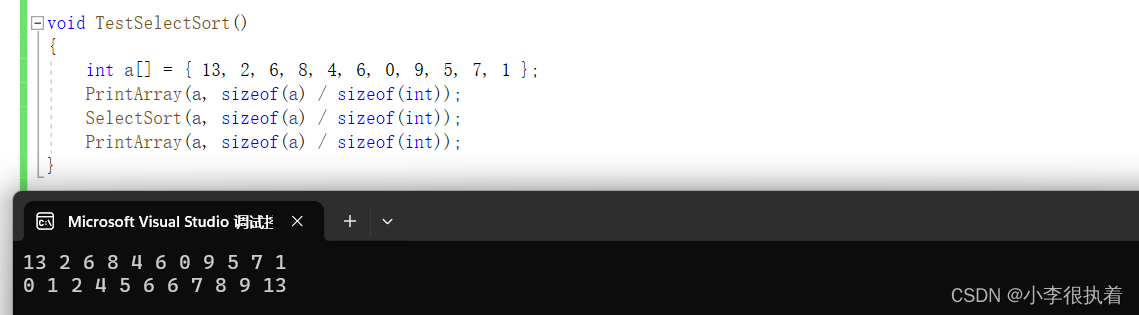
总结
选择排序是一种简单直观的排序算法,其基本想是每次从待排序的元素中选择最小(或最大)的元素,放到已排序序列的末尾。选择排序的分析总结如下:
时间复杂度:选择排序的时间复杂度为O(n^2),其中n是待排序序列的长度。因为每次都需要在剩余的未排序元素中找到最小(或最大)的元素,需要进行n-1次比较和交换操作。
空间复杂度:选择排序的空间复杂度为O(1),即不需要额外的空间来存储数据。
稳定性:选择排序是一种不稳定的排序算法。在每次选择最小(或最大)元素时,可能会改变相同元素之间的相对顺序。
适用性:选择排序适用于小规模数据的排序,但对于大规模数据效率较低。由于其简单直观的思想,选择排序在教学和理解排序算法的过程中具有一定的价值。
2.堆排序
void AdjustDown(int* a, int size, int parent)
{
int child = parent * 2 + 1;
while (child < size)
{
// 假设左孩子小,如果解设错了,更新一下
if (child + 1 < size && a[child + 1] > a[child])
{
++child;
}
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
// 升序
void HeapSort(int* a, int n)
{
// O(N)
// 建大堆
for (int i = (n - 1 - 1) / 2; i >= 0; --i)
{
AdjustDown(a, n, i);
}
// O(N*logN)
int end = n - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
--end;
}
}
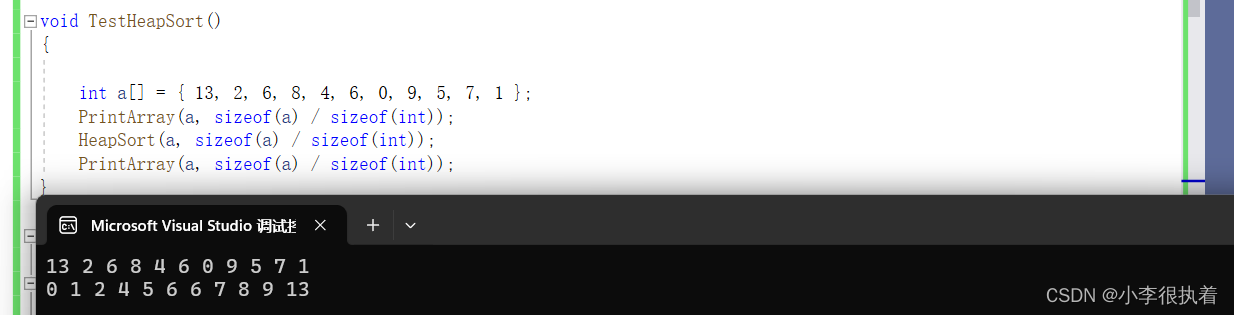
总结
堆排序是一种高效的排序算法,它利用了堆这种数据结构的特性来进行排序。下面是对堆排序的分析总结:
堆的构建:首先需要将待排序的数组构建成一个堆。堆是一个完全二叉树,可以使用数组来表示。通过从最后一个非叶子节点开始,依次向上调整每个节点,使得每个节点都满足堆的性质。
堆的调整:构建好堆之后,将堆顶元素(最大值或最小值)与最后一个元素交换位置,并将堆的大小减一。然后再对堆顶元素进行调整,使得剩余元素重新满足堆的性质。重复这个过程,直到堆的大小为1,即完成了排序。
时间复杂度:堆排序的时间复杂度为O(nlogn),其中n是待排序数组的长度。堆的构建需要O(n)的时间复杂度,而每次调整堆的操作需要O(logn)的时间复杂度,总共需要进行n-1次调整。
空间复杂度:堆排序的空间复杂度为O(1),只需要常数级别的额外空间来存储中间变量。
稳定性:堆排序是一种不稳定的排序算法,因为在调整堆的过程中,可能会改变相同元素的相对顺序。
3.交换排序
1.冒泡排序
// 时间复杂度:O(N^2)
// 最好情况是多少:O(N)
void BubbleSort(int* a, int n)
{
for (int j = 0; j < n; j++)
{
bool exchange = false;
for (int i = 1; i < n - j; i++)
{
if (a[i - 1] > a[i])
{
Swap(&a[i - 1], &a[i]);
exchange = true;
}
}
if (exchange == false)
break;
}
}
总结
冒泡排序是一种简单的排序算法,它通过多次比较和交换相邻元素的方式将最大(或最小)的元素逐渐“冒泡”到数组的末尾。下面是对冒泡排序的分析总结:
基本思想:冒泡排序的基本思想是通过相邻元素的比较和交换来实现排序。每一轮比较都会将当前未排序部分的最大(或最小)元素“冒泡”到末尾。
时间复杂度:冒泡排序的时间复杂度为O(n^2),其中n是待排序数组的长度。这是因为冒泡排序需要进行n-1轮比较,每轮比较需要遍历未排序部分的元素。
空间复杂度:冒泡排序的空间复杂度为O(1),即不需要额外的空间来存储数据。
稳定性:冒泡排序是一种稳定的排序算法,即相等元素的相对顺序在排序后不会改变。
最佳情况和最差情况:无论是最佳情况还是最差情况,冒泡排序的时间复杂度都是O(n^2)。最佳情况是待排序数组已经有序,此时只需要进行n-1轮比较即可。最差情况是待排序数组逆序,需要进行n-1轮比较,并且每轮比较都需要交换元素。
2.快速排序
// 挖坑法
int PartSort2(int* a, int begin, int end)
{
int midi = GetMidi(a, begin, end);
Swap(&a[midi], &a[begin]);
int key = a[begin];
int hole = begin;
while (begin < end)
{
// 右边找小,填到左边的坑
while (begin < end && a[end] >= key)
{
--end;
}
a[hole] = a[end];
hole = end;
// 左边找大,填到右边的坑
while (begin < end && a[begin] <= key)
{
++begin;
}
a[hole] = a[begin];
hole = begin;
}
a[hole] = key;
return hole;
}
void QuickSort(int* a, int begin, int end)
{
if (begin >= end)
return;
int keyi = PartSort2(a, begin, end);
QuickSort(a, begin, keyi - 1);
QuickSort(a, keyi + 1, end);
}
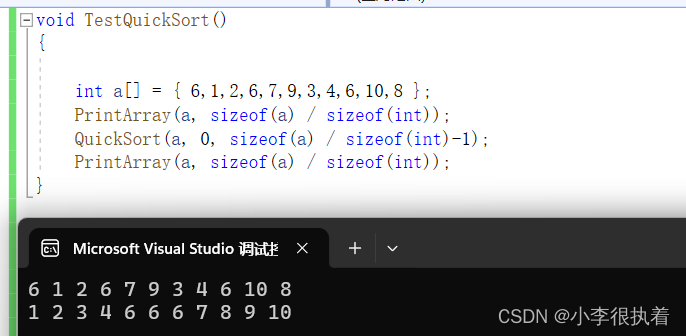
总结
快速排序是一种常用的排序算法,它的基本思想是通过一趟排序将待排序的数据分割成独立的两部分,其中一部分的所有数据都比另一部分的所有数据小,然后再按此方法对这两部分数据分别进行快速排序,整个过程递归进行,以达到整个数据变成有序序列的目的。
快速排序的分析总结如下:
- 时间复杂度:平均情况下,快速排序的时间复杂度为O(nlogn),最坏情况下为O(n^2)。最坏情况发生在待排序序列已经有序或基本有序的情况下,此时每次划分只能减少一个元素,需要进行n-1次划分,因此时间复杂度较高。但是通过优化措施(如随机选择基准元素),可以避免最坏情况的发生。
- 空间复杂度:快速排序的空间复杂度为O(logn),主要是由于递归调用造成的栈空间使用。
- 稳定性:快速排序是一种不稳定的排序算法,因为在交换元素的过程中可能改变相同元素的相对顺序。
- 应用场景:快速排序在实际应用中广泛使用,特别适用于大规模数据的排序。它的性能优于其他常见的排序算法,如冒泡排序和插入排序。
4.归并排序
void _MergeSort(int* a, int begin, int end, int* tmp)
{
if (begin >= end)
return;
int mid = (begin + end) / 2;
// [begin, mid][mid+1, end]
_MergeSort(a, begin, mid, tmp);
_MergeSort(a, mid + 1, end, tmp);
// [begin, mid][mid+1, end]归并
int begin1 = begin, end1 = mid;
int begin2 = mid + 1, end2 = end;
int i = begin;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[i++] = a[begin1++];
}
else
{
tmp[i++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = a[begin2++];
}
memcpy(a + begin, tmp + begin, sizeof(int) * (end - begin + 1));
}
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail");
return;
}
_MergeSort(a, 0, n - 1, tmp);
free(tmp);
}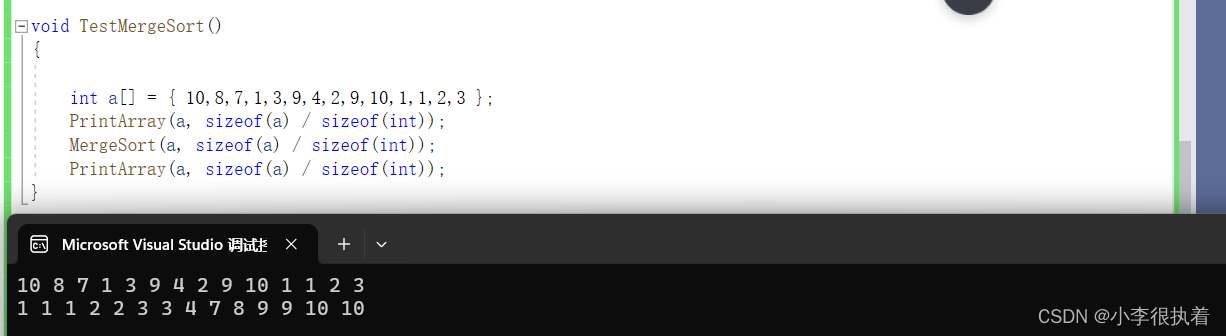
总结
归并排序是一种经典的排序算法,它采用分治的思想来实现排序。下面是对归并排序的分析总结:
算法思想:归并排序将待排序的序列不断地分割成两个子序列,直到每个子序列只有一个元素,然后将这些子序列两两合并,直到最终得到有序的序列。
时间复杂度:归并排序的时间复杂度为O(nlogn),其中n是待排序序列的长度。这是因为每次合并操作都需要O(n)的时间,而分割操作需要O(logn)次。
空间复杂度:归并排序需要额外的O(n)空间来存储临时数组,用于合并操作。
稳定性:归并排序是一种稳定的排序算法,即相等元素的相对顺序在排序后保持不变。
优点:归并排序具有稳定性和适应性好的特点,适用于各种数据类型和数据规模。
缺点:归并排序需要额外的空间来存储临时数组,对于大规模数据排序时可能会占用较多的内存。
5.总的分析总结
插入排序是一种简单直观的排序算法,它的基本思想是将待排序的元素逐个插入到已排序序列中的适当位置,直到全部元都插入完毕。插入排序包直接插入排序和希尔排序。
-
直接插入排序:
- 算法思想:将待排序序列分为已排序和未排序两部分,初始时已排序部分只有一个元素。然后从未排序部分依次取出元素,与已排序部分的元素进行比较并插入到合适的位置。
- 时间复杂度:最好情况下为O(n),最坏情况下为O(n^2),平均情况下为O(n^2)。
- 空间复杂度:O(1)。
- 稳定性:稳定。
-
希尔排序:
- 算法思想:希尔排序是直接插入排序的改进版,通过设置一个增量序列,将待排序序列分割成若干个子序列,对每个子序列进行直接插入排序。然后逐步缩小增量,最终完成整个序列的排序。
- 时间复杂度:平均情况下为O(nlogn),最坏情况下为O(n^2)。
- 空间复杂度:O(1)。
- 稳定性:不稳定。
选择排序是一种简单直观的排序算法,它的基本思想是每次从待排序序列中选择最小(或最大)的元素放到已排序序列的末尾。选择排序包括选择排序和堆排序。
-
选择排序:
- 算法思想:将待排序序列分为已排序和未排序两部分,初始时已排序部分为空。每次从未排序部分选择最小(或最大)的元素,放到已排序部分的末尾。
- 时间复杂度:最好情况下为O(n^2),最坏情况下为O(n^2),平均情况下为O(n^2)。
- 空间复杂度:O(1)。
- 稳定性:不稳定。
-
堆排序:
- 算法思想:堆排序利用堆这种数据结构进行排序。首先将待排序序列构建成一个大顶堆(或小顶堆),然后依次将堆顶元素与末尾元素交换,并重新调整堆,直到整个序列有序。
- 时间复杂度:平均情况下为O(nlogn),最坏情况下为O(nlogn)。
- 空间复杂度:O(1)。
- 稳定性:不稳定。
交换排序是一种通过元素之间的交换来进行排序的算法,包括冒泡排序和快速排序。
-
冒泡排序:
- 算法思想:冒泡排序通过依次比较相邻的元素,并交换它们的位置,使得每一轮循环都能将最大(或最小)的元素移动到末尾。重复这个过程,直到整个序列有序。
- 时间复杂度:最好情况下为O(n),最坏情况下为O(n^2),平均情况下为O(n^2)。
- 空间复杂度:O(1)。
- 稳定性:稳定。
-
快速排序:
- 算法思想:快速排序通过选择一个基准元素,将待排序序列分成两部分,一部分小于基准元素,一部分大于基准元素。然后对这两部分分别进行快速排序,直到整个序列有序。
- 时间复杂度:平均情况下为O(nlogn),最坏情况下为O(n^2)。
- 空间复杂度:平均情况下为O(logn),最坏情况下为O(n)。
- 稳定性:不稳定。
归并排序是一种基于分治思想的排序算法。
- 归并排序:
- 算法思想:归并排序将待排序序列递归地分成两个子序列,对每个子序列进行归并排序,然后将两个有序子序列合并成一个有序序列。重复这个过程,直到整个序列有序。
- 时间复杂度:平均情况下为O(nlogn),最坏情况下为O(nlogn)。
- 空间复杂度:O(n)。
- 稳定性:稳定。
优缺点和注意实现分析总结:
- 直接插入排序和冒泡排序简单易懂,但对于大规模数据排序效率较低。
- 希尔排序通过设置增量序列,可以在一定程度上提高排序效率。
- 选择排序和堆排序的时间复杂度较高,但堆排序在大规模数据排序时相对较快。
- 快速排序是一种高效的排序算法,但在最坏情况下可能会退化为O(n^2)的时间复杂度。
- 归并排序具有稳定性和较高的时间复杂度,适用于大规模数据排序。
![[Java EE] 多线程(七): 锁策略](https://img-blog.csdnimg.cn/direct/bcc96511d96a4b8e808cecb34bc31156.png)