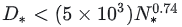1. 算法效率
- 如何衡量一个算法的好坏?
- 一般是从时间和空间的维度来讨论复杂度,但是现在由于计算机行业发展迅速,所以现在并不怎么在乎空间复杂度了
- 下面例子中,斐波那契看上去很简洁,但是复杂度未必如此
long long Fib(int N)
{
if(N < 3)
return 1;
return Fib(N-1) + Fib(N-2);
}- 摩尔定律,每两年硬件性能就会翻两倍,但是现在这个结论有些失效了,主要是因为计算机行业现在快处于瓶颈期了,很难再有突破
- 学习复杂度有什么用呢?
- 主要是在面试中和校招中考察。
- 其实再写一个算法的时候可以进行大概的估算
2. 时间复杂度
- 算法的时间复杂度是一个数学函数,定量描述了该算法的运行时间
- 每个机器的运行速度都不一样,不同的机器跑一样的代码,时间上会有差异
- 所以这个时候有了时间复杂度,时间复杂度计算的是程序执行的次数(大概的次数)
- 下面举个最简单的例子,下面代码的复杂度是多少?看时间复杂度,循环嵌套循环的复杂度就是 N^2
- 这个得出N^2,是因为在程序执行的时候,假设每执行100次,100次里的第一个循环就要执行100次,外层循环每次执行一次,里面的for循环就要执行100次。
int main()
{
int n = 100000,count = 0;
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
count++;
}
}
printf("%d", count);
return 0;
}2.1. 大0的渐进表示法
- 看下面图来说,当 N 值越来越大的时候,2 * N + 10的部分影响就很小了

- 因为计算机运行的速度很快,比如我这个电脑运行速度是3.10GHz,也就意味着,在一段时间周期内可以处理3.1亿次指令,对于电脑来说多处理十几万的次数可谓相当轻松。

- 大O渐进法,就是对影响结果最大的值进行估算,只要保留最高项就行
- 再举个例子 1.N^2 + 2n; 2.N + 100; 3. N^3 。当N在10和100像这种比较小的数的时候,此时他们时间复杂度是差不多的。

2.2. clock 函数 <time.h>
- 返回程序消耗的处理器时间 ,单位 毫秒(ms)。
- 我的电脑,处理10亿次指令,用2075ms,2秒多。大家有兴趣,也可以用这个函数去试试

2.3. 例题
- 0 ms表示,运行时间小于1 ms
- 那么下面的时间复杂度是多少呢?时间复杂度计算的是大概的执行次数。是 F(N) = 2 * N + M; 用大O渐进法就是 O(N);
- 得出O(N),因为我们要省略对结果影响不大的值
void Func2(int N)
{
int count = 0;
for (int k = 0; k < 2 * N; ++k)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
printf("%d\n", count);
}2.3.1. 第二题
- 最好的情况就是一方远大于另一方

void Func3(int N, int M)
{
int count = 0;
for (int k = 0; k < M; ++ k)
{
++count;
}
for (int k = 0; k < N ; ++ k)
{
++count;
}
printf("%d\n", count);
}2.3.2. 第三题
- 那么这里是多少?,这个O(1), 这里意思不是执行1次,也不是执行时间低于1ms,而是这里的 1,表示常数次(常数就是1,2,3,4,5,...)
void Func4(int N)
{
int count = 0;
for (int k = 0; k < 100; ++ k)
{
++count;
}
printf("%d\n", count);
}2.4. 大O符号(Big O notation):是用于描述函数渐进行为(大概)的数学符号
- 推导大O阶方法:
- 用常数1代替运行时的所有加法常数
- 去掉其他影响不大的项,只要保留最高阶项
- 如果最高阶项存在且不是1,则去除与这个项目相乘的常数。得到的结果就是大O阶。
- 本质:计算算法复杂度(次数) 属于哪个量级(level)
- 假如有两个富豪,一个有2000亿,另一个有3000亿,都去买咖啡喝,不管是便宜的200左右的,还是5000的,就算是50w的。富豪都买的起,意思想表达的就是富豪们都是属于一个级别的你买起,那么他也买的起,这点钱就无足轻重了
常见算法复杂度如下:

2.5. 复杂度的最好、平均和最坏
- 最坏情况:任意输入规模的最大运行次数(上限)
- 平均情况:输入任意数,期望的运行次数
- 最好情况:输入任意数,最小的运行次数(下限)
例如:在长度N的数组中查找一个数据
- 最好的情况 O(1),最坏的情况O(N),平均情况 N/2.
2.6. 例题,消失的数字
- 此题共提供两种思路
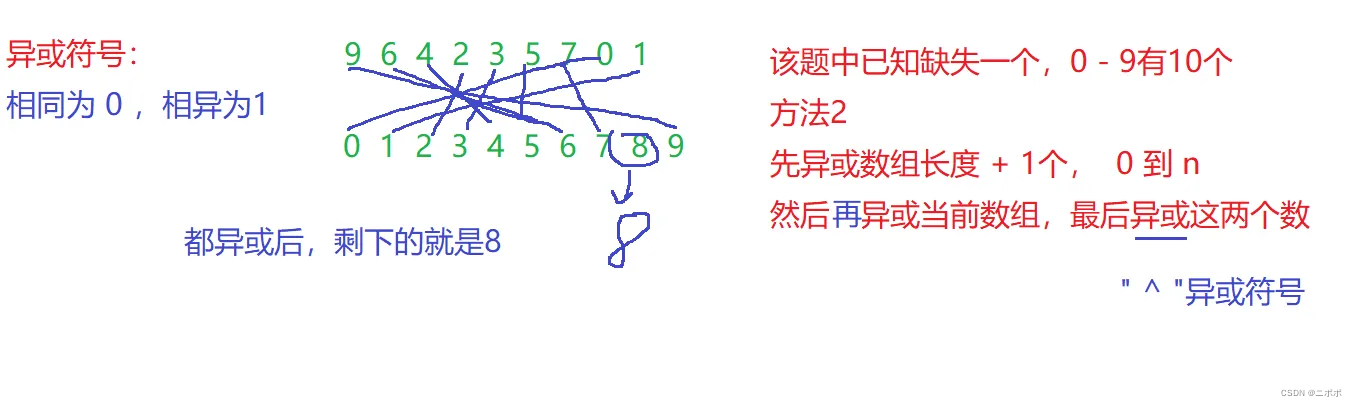
- 第1种:用按位或,先按位或上
- 第2种:所有项数相加,然后依次减去数组里的值,减去剩下来的值就是,单生狗

//方法1
int missingNumber(int* nums, int numsSize){
int one = 0,second = 0;
for(int i = 0;i <= numsSize;++i)//numsSize <= 多一个
{
one ^= i;
}
for(int j = 0;j < numsSize;j++)
{
second ^= nums[j];
}
return one ^ second;
}
//方法2
int missingNumber(int* nums, int numsSize){
int N = numsSize;//等差数列项数 result
int ret = (0 + N) * (N + 1) / 2; // N + 1 是因为确实的那个项
for(int i = 0;i < numsSize; i++)
{
ret -= nums[i];//ret 项数的总和,依次减去数组内的数
}
return ret;
}- 图中是挨个异或,这里代码中直接先将0 - n,全部异或。然后再异或原数组,最有将两个异或,就得到了这个数
2.7. 轮转数组
- 循环条件是 left < right; //不用写 left <= right,当时单数的时候,交不交换都一样。,因为两边向中间靠拢交换
- 要画图,画清楚图代码都是水到渠成了
- 一定要注意,数组下标绝对不能是负数

void reverse(int* nums,int left, int right)
{
while(left < right)//比较的下标值
{
int tmp = nums[left];
nums[left] = nums[right];
nums[right] = tmp;
left++;
right--;
}
}
void rotate(int* nums, int numsSize, int k) {
k %= numsSize;// k % numsSize 6 % 7 = 6
reverse(nums,0,numsSize - k - 1);
reverse(nums,numsSize - k,numsSize - 1);
reverse(nums,0,numsSize - 1);
}2.7.1. 还有一种方法,额外开辟空间
- 就是你们常说的用空间换时间,这个的空间复杂度是O(N),为什么是N,因为malloc开辟的空间是未知的
- 只要根据上面画的图,稍微推断一下就知道了
- 如果还不知道memcpy怎么使用的可以去看看 ,这篇博客C语言的内存函数
void rotate(int* nums, int numsSize, int k) {
k %= numsSize;
int* numsby = (int*)malloc(sizeof(int) * numsSize);
//拷贝到新空间的前三个
memcpy(numsby,nums + (numsSize - k),sizeof(int) * k);
//把剩下的拷贝
memcpy(numsby + k,nums,sizeof(int) * (numsSize - k));
//把新空间的拷贝会nums
memcpy(nums,numsby,sizeof(int) * numsSize);
free(numsby);
numsby = NULL;
}2.8. logN复杂度

int main()
{
int n = 8;
int count = 0, i = 1;
for (i = 1; i < n; i *= 2)
{
count++;
}
printf("%d\n", count);
return 0;
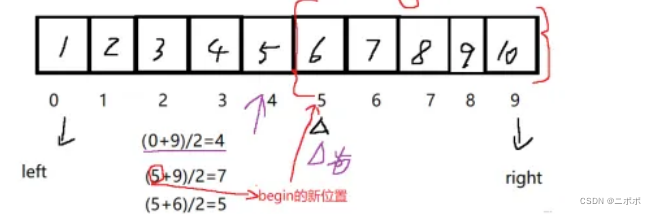
}- 二分查找的每次区间变化是 N / 2,每次查找都是N /2 /2 /2...
int main()
{
int arr[] = { 1,2,3,4,5,6,7,8,9 };
int sz = sizeof(arr) / sizeof(arr[0]);
int left = 0, right = sz - 1;
int k = 7;
while (left <= right)//为啥有等于因为,为单数时还有一个数需要查找
{
int mid = left + (right - left) / 2;
if (arr[mid] < k)//左半没有我需要的值
left = mid + 1;
else if (arr[mid] > k)//被查找的值小于中间值,此时说明右半区间没有需要的值
right = mid - 1;
else
{
printf("%d", mid);
break;
}
left++;
right--;
}
return 0;
}
2.9. 乘阶的复杂度
- 乘阶的复杂的是 N + 1,算的是函数的调用次数总和 ,所以就是O(N)。
// 计算阶乘递归Fac的时间复杂度?
long long Fac(size_t N)
{
if(0 == N)
return 1;
return Fac(N-1)*N;
}- 如果乘阶里面还有计算呢?
long long Fac(size_t N)
{
if(0 == N)
return 1;
for(int i; i < N;i++)
{
;
}
return Fac(N-1)*N;
}- 这个时候每调用一次,for循环就会打印 N次,这个消耗也要算进去,而且这个是递归调用,每次调用自身都会打印 n - 1次的数据,直到满足结束条件。
- 所以在这个递归调用里,复杂度是 O(N^2);。所有递归次数累加
2.10. 斐波那契的复杂度


int Fib(int n)
{
if (n < 3)
return 1;
return Fib(n - 1) + Fib(n - 2);
}
int main()
{
//斐波那契
int ret = Fib(40);
printf("%d ", ret);
return 0;
}- 对此上面的方法只有理论意义,并不具有实际意义
- 所以我们要用迭代的方法O(N),来解决,这个方法更好
int main()
{
//斐波那契
//迭代的方法,因为斐波那契前两项都是1
unsigned long long x1 = 1;
unsigned long long x2 = 1;
unsigned long long x3 = 0;
int n = 1150;
for (int i = 3; i <= n; i++)
{
x3 = x1 + x2;
x1 = x2;
x2 = x3;
}
printf("%lld", x3);
return 0;
}- 这种迭代的方法还是不够好,算较小的数还行,数字大了还是不行,会到类型上限
- 可以用字符串存储,只要空间够大,多大的数都能存储。不过还没学到,下次一定!!

3. 空间复杂度
- 一个算法重点关注时间复杂度,不太关注空间复杂度,除非是嵌入式那些有大小限制的设备上。
- 空间复杂度算的是变量的个数,因为每个变量的差异不大,为什么没有什么差异?,举个例子
- 1GB = 1024MB;1MB = 1024KB 1 KB = 1024 Byte ;1Byte = 8bit;
- 一个MB的空间都有这么大了,还在乎这么点空间吗?
- 空间复杂度使用的也是大O渐进法。
- 可以来看看实例 ,函数的形参部分的变量不算个数,算的是函数内额外的变量个数
- 在此题目中冒泡排序里面,发现只开辟了三个变量,空间复杂度是O(1)
void bbu(int a[], int len)
{
for (int i = 0; i < len - 1; i++)
{
for (int j = 0; j < len - i - 1; j++)
{
if (a[j] < a[j + 1])
{
int tmp = a[j];
a[j] = a[j + 1];
a[j + 1] = tmp;
}
}
}
}3.1. 空间复杂度 O(N)
- 实际上空间复杂度比时间复杂度更加容易计算
- 常见的空间复杂度只有三个,O(1) O(N) O(N^2);但是也有其他的
- 举个空间复杂为O(N)的例子
- 每次函数的调用都会创建一个栈帧,创建了多少个栈帧就是多大的空间,会调用N次,O(N)了
// 计算阶乘递归Fac的空间复杂度?
long long Fac(size_t N)
{
if(N == 0)
return 1;
return Fac(N-1)*N;
}总结:个人觉得可能会不太详细,但是重点部分都没拉下