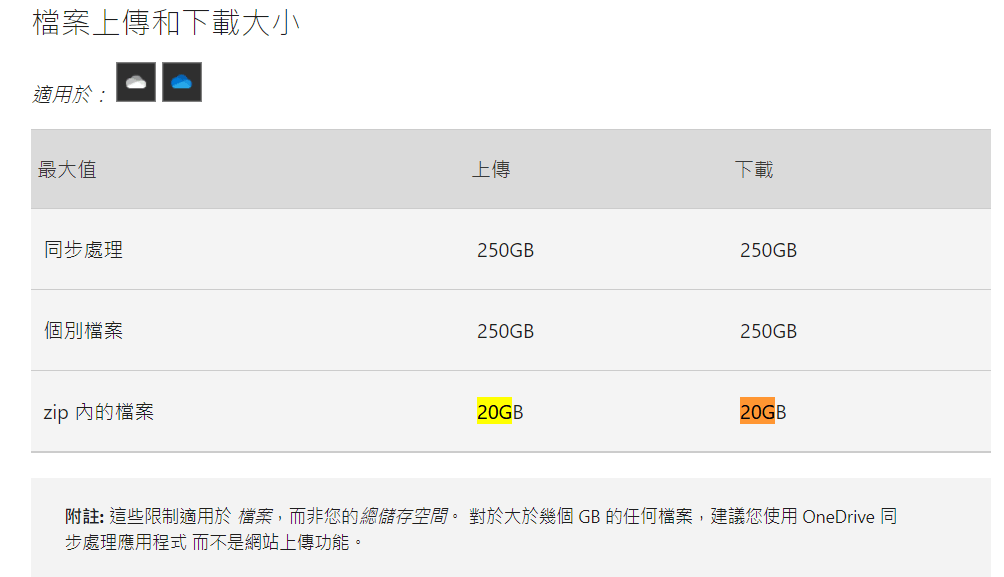
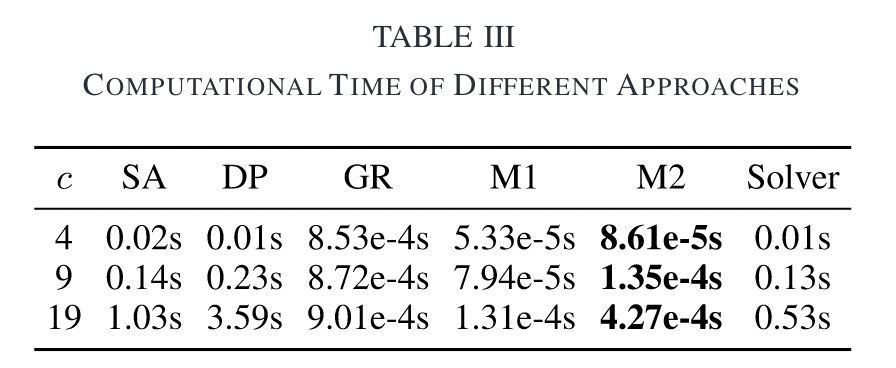
导入必要的库
norman Python 语句:import
<span style="color:#000000"><span style="background-color:#fbedbb"><span style="color:#0000ff">import</span> pandas <span style="color:#0000ff">as</span> pd
<span style="color:#0000ff">import</span> numpy <span style="color:#0000ff">as</span> np
<span style="color:#0000ff">from</span> sklearn.feature_extraction.text <span style="color:#0000ff">import</span> TfidfVectorizer
<span style="color:#0000ff">from</span> sklearn.linear_model.logistic <span style="color:#0000ff">import</span> LogisticRegression
<span style="color:#0000ff">from</span> sklearn.ensemble <span style="color:#0000ff">import</span> RandomForestClassifier
<span style="color:#0000ff">from</span> sklearn.svm <span style="color:#0000ff">import</span> LinearSVC
<span style="color:#0000ff">from</span> sklearn.tree <span style="color:#0000ff">import</span> DecisionTreeClassifier
<span style="color:#0000ff">from</span> sklearn.naive_bayes <span style="color:#0000ff">import</span> MultinomialNB
<span style="color:#0000ff">from</span> sklearn.model_selection <span style="color:#0000ff">import</span> train_test_split, cross_val_score
<span style="color:#0000ff">from</span> sklearn.utils <span style="color:#0000ff">import</span> shuffle
<span style="color:#0000ff">from</span> sklearn.metrics <span style="color:#0000ff">import</span> precision_score, classification_report, accuracy_score
<span style="color:#0000ff">from</span> sklearn.pipeline <span style="color:#0000ff">import</span> FeatureUnion
<span style="color:#0000ff">from</span> sklearn.preprocessing <span style="color:#0000ff">import</span> LabelEncoder
<span style="color:#0000ff">import</span> re
<span style="color:#0000ff">import</span> time</span></span>检索和解析数据
我在这个挑战中的大部分时间都花在了弄清楚如何有效地解析数据以从文本中提取语言名称,然后从文本中删除该信息,这样它就不会污染我们的训练和测试数据集。
下面是两个文本字符串/段(跨越多行并包含回车符)的示例:
<span style="color:#000000"><span style="background-color:#fbedbb"><pre lang=<span style="color:#800080">"</span><span style="color:#800080">Swift"</span>>
@objc func handleTap(sender: UITapGestureRecognizer) {
<span style="color:#0000ff">if</span> <span style="color:#0000ff">let</span> tappedSceneView = sender.view as? ARSCNView {
<span style="color:#0000ff">let</span> tapLocationInView = sender.<span style="color:#339999">location</span>(<span style="color:#0000ff">in</span>: tappedSceneView)
<span style="color:#0000ff">let</span> planeHitTest = tappedSceneView.hitTest(tapLocationInView,
types: .existingPlaneUsingExtent)
<span style="color:#0000ff">if</span> !planeHitTest.isEmpty {
addFurniture(hitTest: planeHitTest)
}
}
}<span style="color:#0000ff"></</span><span style="color:#800000">pre</span><span style="color:#0000ff">></span>
<pre lang=<span style="color:#800080">"</span><span style="color:#800080">JavaScript"</span>>
<span style="color:#0000ff">var</span> my_dataset = [
{
id: <span style="color:#800080">"</span><span style="color:#800080">1"</span>,
text: <span style="color:#800080">"</span><span style="color:#800080">Chairman & CEO"</span>,
title: <span style="color:#800080">"</span><span style="color:#800080">Henry Bennett"</span>
},
{
id: <span style="color:#800080">"</span><span style="color:#800080">2"</span>,
text: <span style="color:#800080">"</span><span style="color:#800080">Manager"</span>,
title: <span style="color:#800080">"</span><span style="color:#800080">Mildred Kim"</span>
},
{
id: <span style="color:#800080">"</span><span style="color:#800080">3"</span>,
text: <span style="color:#800080">"</span><span style="color:#800080">Technical Director"</span>,
title: <span style="color:#800080">"</span><span style="color:#800080">Jerry Wagner"</span>
},
{ id: <span style="color:#800080">"</span><span style="color:#800080">1-2"</span>, <span style="color:#0000ff">from</span>: <span style="color:#800080">"</span><span style="color:#800080">1"</span>, to: <span style="color:#800080">"</span><span style="color:#800080">2"</span>, type: <span style="color:#800080">"</span><span style="color:#800080">line"</span> },
{ id: <span style="color:#800080">"</span><span style="color:#800080">1-3"</span>, <span style="color:#0000ff">from</span>: <span style="color:#800080">"</span><span style="color:#800080">1"</span>, to: <span style="color:#800080">"</span><span style="color:#800080">3"</span>, type: <span style="color:#800080">"</span><span style="color:#800080">line"</span> }
];<span style="color:#0000ff"></</span><span style="color:#800000">pre</span><span style="color:#0000ff">></span></span></span>棘手的部分是让正则表达式返回 “” 标签中的数据,然后创建另一个正则表达式来只返回 “” 标签的 “” 部分。<pre lang...><pre>langpre
它并不漂亮,我相信它可以优化,但它有效:
<span style="color:#000000"><span style="background-color:#fbedbb"><span style="color:#0000ff">def</span> get_data():
file_name = <span style="color:#800080">'</span><span style="color:#800080">./LanguageSamples.txt'</span>
rawdata = <span style="color:#339999">open</span>(file_name, <span style="color:#800080">'</span><span style="color:#800080">r'</span>)
lines = rawdata.readlines()
<span style="color:#0000ff">return</span> lines
<span style="color:#0000ff">def</span> clean_data(input_lines):
<span style="color:#008000"><em>#</em></span><span style="color:#008000"><em>find matches for all data within the pre tags</em></span>
all_found = re.findall(r<span style="color:#800080">'</span><span style="color:#800080"><pre[\s\S]*?<\/pre>'</span>, input_lines, re.MULTILINE)
<span style="color:#008000"><em>#</em></span><span style="color:#008000"><em>clean the string of various tags</em></span>
clean_string = <span style="color:#0000ff">lambda</span> x: x.replace(<span style="color:#800080">'</span><span style="color:#800080"><'</span>, <span style="color:#800080">'</span><span style="color:#800080"><'</span>).replace(<span style="color:#800080">'</span><span style="color:#800080">>'</span>, <span style="color:#800080">'</span><span style="color:#800080">>'</span>).replace
(<span style="color:#800080">'</span><span style="color:#800080"></pre>'</span>, <span style="color:#800080">'</span><span style="color:#800080">'</span>).replace(<span style="color:#800080">'</span><span style="color:#800080">\n'</span>, <span style="color:#800080">'</span><span style="color:#800080">'</span>)
all_found = [clean_string(item) <span style="color:#0000ff">for</span> item <span style="color:#0000ff">in</span> all_found]
<span style="color:#008000"><em>#</em></span><span style="color:#008000"><em>get the language for all of the pre tags</em></span>
get_language = <span style="color:#0000ff">lambda</span> x: re.findall(r<span style="color:#800080">'</span><span style="color:#800080"><pre lang="(.*?)">'</span>, x, re.MULTILINE)[<span style="color:#000080">0</span>]
lang_items = [get_language(item) <span style="color:#0000ff">for</span> item <span style="color:#0000ff">in</span> all_found]
<span style="color:#008000"><em>#</em></span><span style="color:#008000"><em>remove all of the pre tags that contain the language</em></span>
remove_lang = <span style="color:#0000ff">lambda</span> x: re.sub(r<span style="color:#800080">'</span><span style="color:#800080"><pre lang="(.*?)">'</span>, <span style="color:#800080">"</span><span style="color:#800080">"</span>, x)
all_found = [remove_lang(item) <span style="color:#0000ff">for</span> item <span style="color:#0000ff">in</span> all_found]
<span style="color:#008000"><em>#</em></span><span style="color:#008000"><em>return let text between the pre tags and their corresponding language</em></span>
<span style="color:#0000ff">return</span> (all_found, lang_items) </span></span>创建 Pandas DataFrame
在这里,我们获取数据,创建一个并用数据填充它。DataFrame
<span style="color:#000000"><span style="background-color:#fbedbb">all_samples = <span style="color:#800080">'</span><span style="color:#800080">'</span>.join(get_data())
cleaned_data, languages = clean_data(all_samples)
df = pd.DataFrame()
df[<span style="color:#800080">'</span><span style="color:#800080">lang_text'</span>] = languages
df[<span style="color:#800080">'</span><span style="color:#800080">data'</span>] = cleaned_data</span></span>这是我们的样子:DataFrame
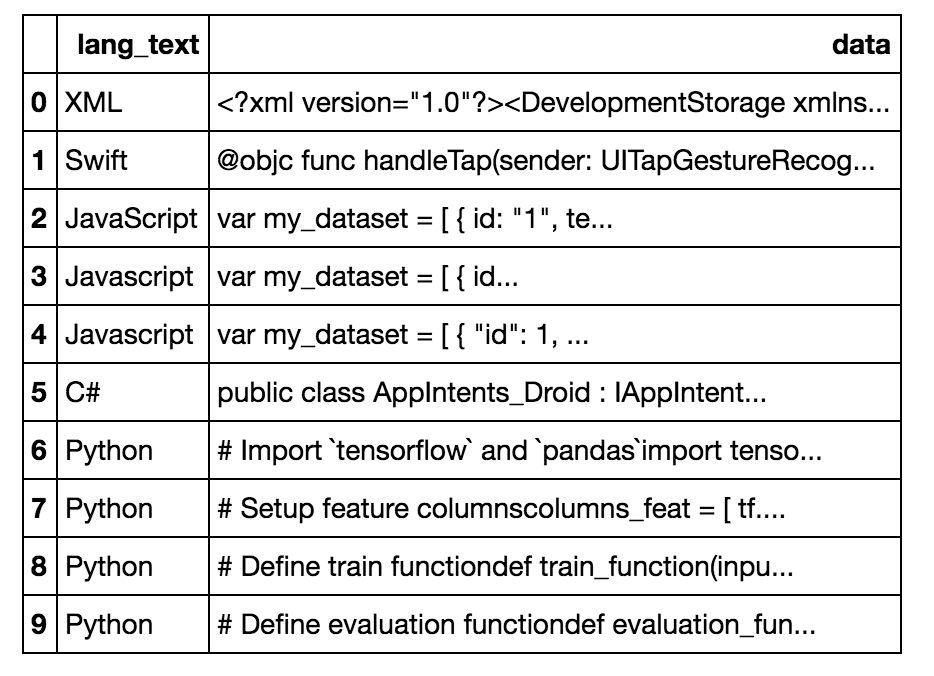
创建分类列
接下来我们需要做的是将我们的 “” 列变成一个数字列,因为这是许多机器学习模型对它试图确定的 “” 或输出的期望。为此,我们将使用 LabelEncoder 并使用它来将我们的 “” 列转换为分类列。lang_textYlang_text
<span style="color:#000000"><span style="background-color:#fbedbb">lb_enc = LabelEncoder()
df[<span style="color:#800080">'</span><span style="color:#800080">language'</span>] = lb_enc.fit_transform(df[<span style="color:#800080">'</span><span style="color:#800080">lang_text'</span>]) </span></span>现在我们看起来像这样:DataFrame
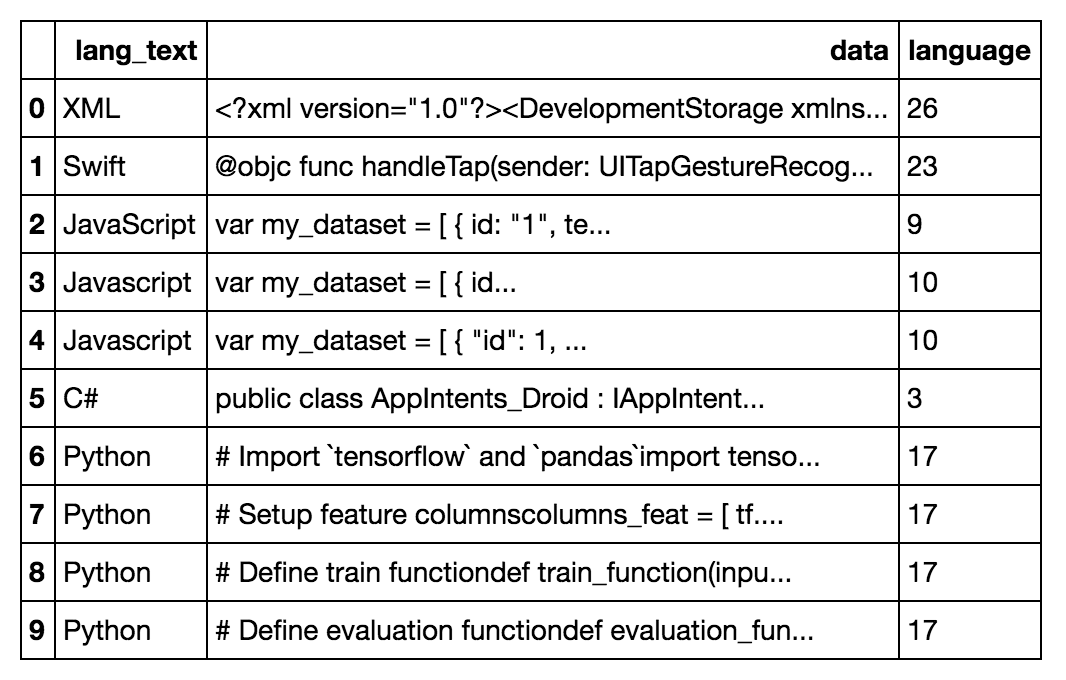
我们可以通过运行以下命令来查看该列是如何编码的:
<span style="color:#000000"><span style="background-color:#fbedbb">lb_enc.classes_</span></span>显示此内容(数组中的位置与新的“语言”分类列中的整数值匹配):
<span style="color:#000000"><span style="background-color:#fbedbb">array([<span style="color:#800080">'</span><span style="color:#800080">ASM'</span>, <span style="color:#800080">'</span><span style="color:#800080">ASP.NET'</span>, <span style="color:#800080">'</span><span style="color:#800080">Angular'</span>, <span style="color:#800080">'</span><span style="color:#800080">C#'</span>, <span style="color:#800080">'</span><span style="color:#800080">C++'</span>, <span style="color:#800080">'</span><span style="color:#800080">CSS'</span>, <span style="color:#800080">'</span><span style="color:#800080">Delphi'</span>, <span style="color:#800080">'</span><span style="color:#800080">HTML'</span>,
<span style="color:#800080">'</span><span style="color:#800080">Java'</span>, <span style="color:#800080">'</span><span style="color:#800080">JavaScript'</span>, <span style="color:#800080">'</span><span style="color:#800080">Javascript'</span>, <span style="color:#800080">'</span><span style="color:#800080">ObjectiveC'</span>, <span style="color:#800080">'</span><span style="color:#800080">PERL'</span>, <span style="color:#800080">'</span><span style="color:#800080">PHP'</span>,
<span style="color:#800080">'</span><span style="color:#800080">Pascal'</span>, <span style="color:#800080">'</span><span style="color:#800080">PowerShell'</span>, <span style="color:#800080">'</span><span style="color:#800080">Powershell'</span>, <span style="color:#800080">'</span><span style="color:#800080">Python'</span>, <span style="color:#800080">'</span><span style="color:#800080">Razor'</span>, <span style="color:#800080">'</span><span style="color:#800080">React'</span>,
<span style="color:#800080">'</span><span style="color:#800080">Ruby'</span>, <span style="color:#800080">'</span><span style="color:#800080">SQL'</span>, <span style="color:#800080">'</span><span style="color:#800080">Scala'</span>, <span style="color:#800080">'</span><span style="color:#800080">Swift'</span>, <span style="color:#800080">'</span><span style="color:#800080">TypeScript'</span>, <span style="color:#800080">'</span><span style="color:#800080">VB.NET'</span>, <span style="color:#800080">'</span><span style="color:#800080">XML'</span>], dtype=object)</span></span>样板代码
以下是后续步骤:
- 声明用于输出训练结果的函数
- 声明用于训练和测试模型的函数
- 声明用于创建要测试的模型的函数
- 随机播放数据
- 拆分训练和测试数据
- 将数据和模型传递到训练和测试函数中,并查看结果:
<span style="color:#000000"><span style="background-color:#fbedbb"><span style="color:#0000ff">def</span> output_accuracy(actual_y, predicted_y, model_name, train_time, predict_time):
<span style="color:#0000ff">print</span>(<span style="color:#800080">'</span><span style="color:#800080">Model Name: '</span> + model_name)
<span style="color:#0000ff">print</span>(<span style="color:#800080">'</span><span style="color:#800080">Train time: '</span>, <span style="color:#339999">round</span>(train_time, <span style="color:#000080">2</span>))
<span style="color:#0000ff">print</span>(<span style="color:#800080">'</span><span style="color:#800080">Predict time: '</span>, <span style="color:#339999">round</span>(predict_time, <span style="color:#000080">2</span>))
<span style="color:#0000ff">print</span>(<span style="color:#800080">'</span><span style="color:#800080">Model Accuracy: {:.4f}'</span>.<span style="color:#339999">format</span>(accuracy_score(actual_y, predicted_y)))
<span style="color:#0000ff">print</span>(<span style="color:#800080">'</span><span style="color:#800080">'</span>)
<span style="color:#0000ff">print</span>(classification_report(actual_y, predicted_y, digits=4))
<span style="color:#0000ff">print</span>(<span style="color:#800080">"</span><span style="color:#800080">======================================================="</span>)
<span style="color:#0000ff">def</span> test_models(X_train_input_raw, y_train_input, X_test_input_raw, y_test_input, models_dict):
return_trained_models = {}
return_vectorizer = FeatureUnion([(<span style="color:#800080">'</span><span style="color:#800080">tfidf_vect'</span>, TfidfVectorizer())])
X_train = return_vectorizer.fit_transform(X_train_input_raw)
X_test = return_vectorizer.transform(X_test_input_raw)
<span style="color:#0000ff">for</span> key <span style="color:#0000ff">in</span> models_dict:
model_name = key
model = models_dict[key]
t1 = time.time()
model.fit(X_train, y_train_input)
t2 = time.time()
predicted_y = model.predict(X_test)
t3 = time.time()
output_accuracy(y_test_input, predicted_y, model_name, t2 - t1, t3 - t2)
return_trained_models[model_name] = model
<span style="color:#0000ff">return</span> (return_trained_models, return_vectorizer)
<span style="color:#0000ff">def</span> create_models():
models = {}
models[<span style="color:#800080">'</span><span style="color:#800080">LinearSVC'</span>] = LinearSVC()
models[<span style="color:#800080">'</span><span style="color:#800080">LogisticRegression'</span>] = LogisticRegression()
models[<span style="color:#800080">'</span><span style="color:#800080">RandomForestClassifier'</span>] = RandomForestClassifier()
models[<span style="color:#800080">'</span><span style="color:#800080">DecisionTreeClassifier'</span>] = DecisionTreeClassifier()
models[<span style="color:#800080">'</span><span style="color:#800080">MultinomialNB'</span>] = MultinomialNB()
<span style="color:#0000ff">return</span> models
X_input, y_input = shuffle(df[<span style="color:#800080">'</span><span style="color:#800080">data'</span>], df[<span style="color:#800080">'</span><span style="color:#800080">language'</span>], random_state=7)
X_train_raw, X_test_raw, y_train, y_test = train_test_split(X_input, y_input, test_size=0.<span style="color:#000080">7</span>)
models = create_models()
trained_models, fitted_vectorizer = test_models(X_train_raw, y_train, X_test_raw, y_test, models) </span></span>结果是这样的:
<span style="color:#000000"><span style="background-color:#fbedbb">Model Name: LinearSVC
Train time: 0.99
Predict time: 0.0
Model Accuracy: 0.9262
precision recall f1-score support
0 1.0000 1.0000 1.0000 6
1 1.0000 1.0000 1.0000 2
2 1.0000 1.0000 1.0000 1
3 0.8968 1.0000 0.9456 339
4 0.9695 0.8527 0.9074 224
5 0.9032 1.0000 0.9492 28
6 0.7000 1.0000 0.8235 7
7 0.9032 0.7568 0.8235 74
8 0.7778 0.5833 0.6667 36
9 0.9613 0.9255 0.9430 161
10 1.0000 0.5000 0.6667 6
11 1.0000 1.0000 1.0000 14
12 1.0000 1.0000 1.0000 5
13 1.0000 1.0000 1.0000 2
14 1.0000 0.4545 0.6250 11
15 1.0000 1.0000 1.0000 6
16 1.0000 0.4000 0.5714 5
17 0.9589 0.9589 0.9589 73
18 1.0000 1.0000 1.0000 8
19 0.7600 0.9268 0.8352 41
20 0.1818 1.0000 0.3077 2
21 1.0000 1.0000 1.0000 137
22 1.0000 0.8750 0.9333 24
23 1.0000 1.0000 1.0000 7
24 1.0000 1.0000 1.0000 25
25 0.9571 0.9571 0.9571 70
26 0.9211 0.9722 0.9459 108
avg / total 0.9339 0.9262 0.9255 1422
=========================================================================
Model Name: DecisionTreeClassifier
Train time: 0.13
Predict time: 0.0
Model Accuracy: 0.9388
precision recall f1-score support
0 1.0000 1.0000 1.0000 6
1 1.0000 1.0000 1.0000 2
2 1.0000 1.0000 1.0000 1
3 0.9123 0.9204 0.9163 339
4 0.8408 0.9196 0.8785 224
5 1.0000 0.8929 0.9434 28
6 1.0000 1.0000 1.0000 7
7 1.0000 0.9595 0.9793 74
8 0.9091 0.8333 0.8696 36
9 0.9817 1.0000 0.9908 161
10 1.0000 0.5000 0.6667 6
11 1.0000 1.0000 1.0000 14
12 1.0000 1.0000 1.0000 5
13 1.0000 1.0000 1.0000 2
14 1.0000 0.4545 0.6250 11
15 1.0000 0.5000 0.6667 6
16 1.0000 0.4000 0.5714 5
17 1.0000 1.0000 1.0000 73
18 1.0000 1.0000 1.0000 8
19 0.9268 0.9268 0.9268 41
20 1.0000 1.0000 1.0000 2
21 1.0000 1.0000 1.0000 137
22 1.0000 0.7500 0.8571 24
23 1.0000 1.0000 1.0000 7
24 0.6786 0.7600 0.7170 25
25 1.0000 1.0000 1.0000 70
26 1.0000 1.0000 1.0000 108
avg / total 0.9419 0.9388 0.9376 1422
=========================================================================
Model Name: LogisticRegression
Train time: 0.71
Predict time: 0.01
Model Accuracy: 0.9304
precision recall f1-score support
0 1.0000 1.0000 1.0000 6
1 1.0000 1.0000 1.0000 2
2 1.0000 1.0000 1.0000 1
3 0.9040 1.0000 0.9496 339
4 0.9569 0.8929 0.9238 224
5 0.9032 1.0000 0.9492 28
6 0.7000 1.0000 0.8235 7
7 0.8929 0.6757 0.7692 74
8 0.8750 0.5833 0.7000 36
9 0.9281 0.9627 0.9451 161
10 1.0000 0.5000 0.6667 6
11 1.0000 1.0000 1.0000 14
12 1.0000 1.0000 1.0000 5
13 1.0000 1.0000 1.0000 2
14 1.0000 0.4545 0.6250 11
15 1.0000 1.0000 1.0000 6
16 1.0000 0.4000 0.5714 5
17 0.9589 0.9589 0.9589 73
18 1.0000 1.0000 1.0000 8
19 0.7600 0.9268 0.8352 41
20 1.0000 1.0000 1.0000 2
21 1.0000 0.9781 0.9889 137
22 1.0000 0.8750 0.9333 24
23 1.0000 1.0000 1.0000 7
24 1.0000 1.0000 1.0000 25
25 0.9571 0.9571 0.9571 70
26 0.9211 0.9722 0.9459 108
avg / total 0.9329 0.9304 0.9272 1422
=========================================================================
Model Name: RandomForestClassifier
Train time: 0.04
Predict time: 0.01
Model Accuracy: 0.9374
precision recall f1-score support
0 1.0000 1.0000 1.0000 6
1 1.0000 1.0000 1.0000 2
2 1.0000 1.0000 1.0000 1
3 0.8760 1.0000 0.9339 339
4 0.9452 0.9241 0.9345 224
5 0.9032 1.0000 0.9492 28
6 0.7000 1.0000 0.8235 7
7 1.0000 0.8378 0.9118 74
8 1.0000 0.5278 0.6909 36
9 0.9527 1.0000 0.9758 161
10 1.0000 0.1667 0.2857 6
11 1.0000 1.0000 1.0000 14
12 1.0000 1.0000 1.0000 5
13 1.0000 1.0000 1.0000 2
14 1.0000 0.4545 0.6250 11
15 1.0000 0.5000 0.6667 6
16 1.0000 0.4000 0.5714 5
17 1.0000 1.0000 1.0000 73
18 1.0000 0.6250 0.7692 8
19 0.9268 0.9268 0.9268 41
20 0.0000 0.0000 0.0000 2
21 1.0000 1.0000 1.0000 137
22 1.0000 1.0000 1.0000 24
23 1.0000 0.5714 0.7273 7
24 1.0000 1.0000 1.0000 25
25 1.0000 0.9571 0.9781 70
26 0.8889 0.8889 0.8889 108
avg / total 0.9411 0.9374 0.9324 1422
=========================================================================
Model Name: MultinomialNB
Train time: 0.01
Predict time: 0.0
Model Accuracy: 0.8776
precision recall f1-score support
0 1.0000 1.0000 1.0000 6
1 0.0000 0.0000 0.0000 2
2 0.0000 0.0000 0.0000 1
3 0.8380 0.9764 0.9019 339
4 1.0000 0.8750 0.9333 224
5 1.0000 1.0000 1.0000 28
6 1.0000 1.0000 1.0000 7
7 0.6628 0.7703 0.7125 74
8 1.0000 0.5833 0.7368 36
9 0.8952 0.6894 0.7789 161
10 1.0000 0.3333 0.5000 6
11 1.0000 1.0000 1.0000 14
12 1.0000 1.0000 1.0000 5
13 0.0000 0.0000 0.0000 2
14 1.0000 0.7273 0.8421 11
15 1.0000 1.0000 1.0000 6
16 1.0000 0.4000 0.5714 5
17 1.0000 0.9178 0.9571 73
18 0.8000 1.0000 0.8889 8
19 0.4607 1.0000 0.6308 41
20 0.0000 0.0000 0.0000 2
21 1.0000 1.0000 1.0000 137
22 1.0000 1.0000 1.0000 24
23 1.0000 1.0000 1.0000 7
24 0.8462 0.8800 0.8627 25
25 0.8642 1.0000 0.9272 70
26 0.9630 0.7222 0.8254 108
avg / total 0.8982 0.8776 0.8770 1422
=========================================================================</span></span>