⚠️ 不处理边界的问题
以前有同学写过这样的代码,思考注释中两个问题,以 bio 为例,其实 nio 道理是一样的
public class Server {
public static void main(String[] args) throws IOException {
ServerSocket ss=new ServerSocket(9000);
while (true) {
Socket s = ss.accept();
InputStream in = s.getInputStream();
// 这里这么写,有没有问题
byte[] arr = new byte[4];
while(true) {
int read = in.read(arr);
// 这里这么写,有没有问题
if(read == -1) {
break;
}
System.out.println(new String(arr, 0, read));
}
}
}
}客户端
public class Client {
public static void main(String[] args) throws IOException {
Socket max = new Socket("localhost", 9000);
OutputStream out = max.getOutputStream();
out.write("hello".getBytes());
out.write("world".getBytes());
out.write("你好".getBytes());
max.close();
}
}输出
hell owor ld� �好
为什么?
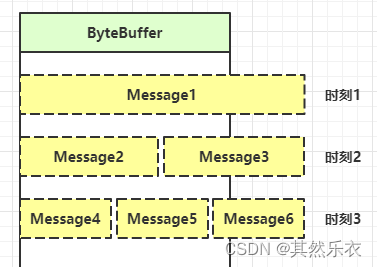
处理消息的边界 & 附件与扩容
-
一种思路是固定消息长度,数据包大小一样,服务器按预定长度读取,缺点是浪费带宽
-
另一种思路是按分隔符拆分,缺点是效率低
-
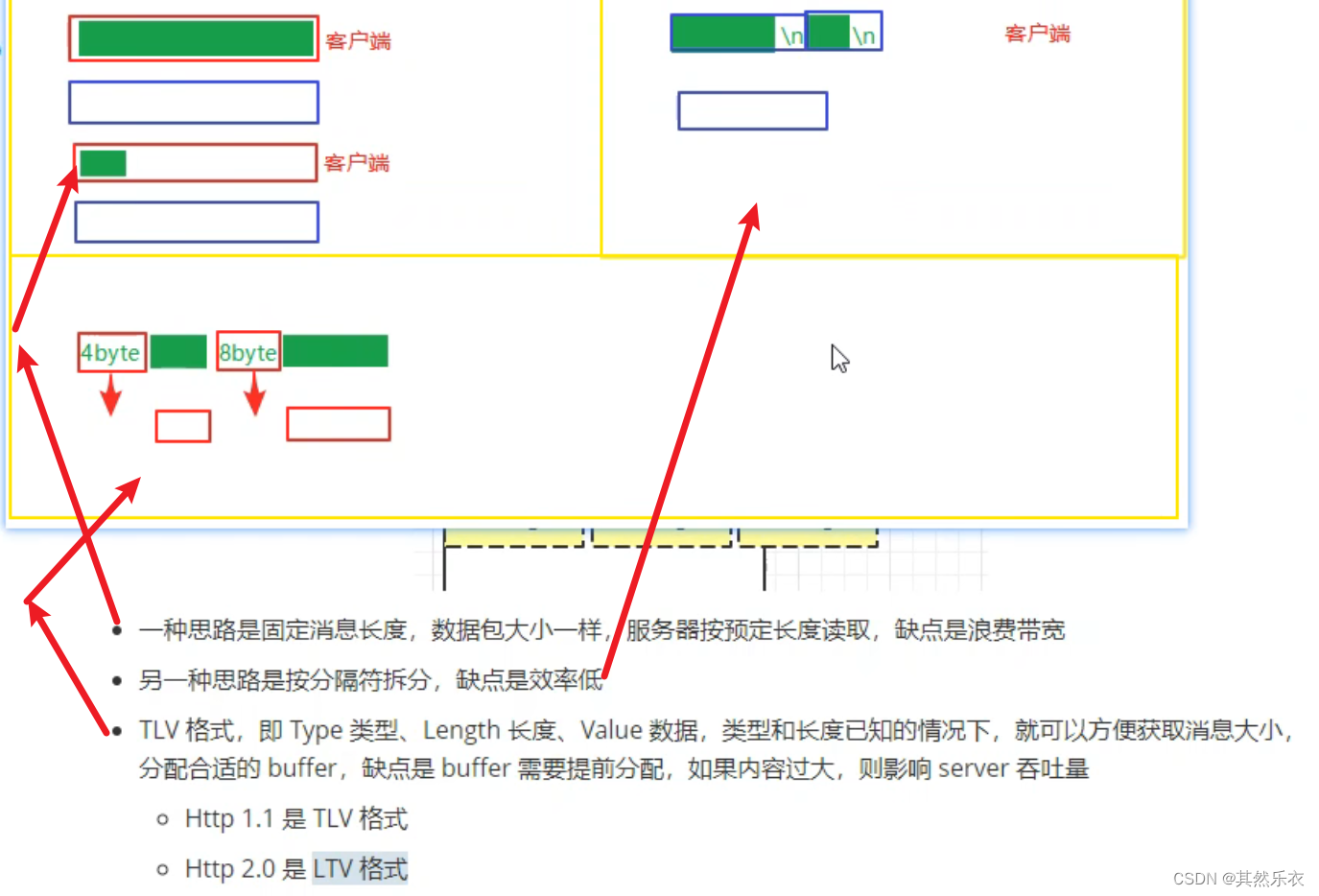
TLV 格式,即 Type 类型、Length 长度、Value 数据,类型和长度已知的情况下,就可以方便获取消息大小,分配合适的 buffer,缺点是 buffer 需要提前分配,如果内容过大,则影响 server 吞吐量
-
Http 1.1 是 TLV 格式
-
Http 2.0 是 LTV 格式
-
服务器端
private static void split(ByteBuffer source) {
source.flip();
for (int i = 0; i < source.limit(); i++) {
// 找到一条完整消息
if (source.get(i) == '\n') {
int length = i + 1 - source.position();
// 把这条完整消息存入新的 ByteBuffer
ByteBuffer target = ByteBuffer.allocate(length);
// 从 source 读,向 target 写
for (int j = 0; j < length; j++) {
target.put(source.get());
}
debugAll(target);
}
}
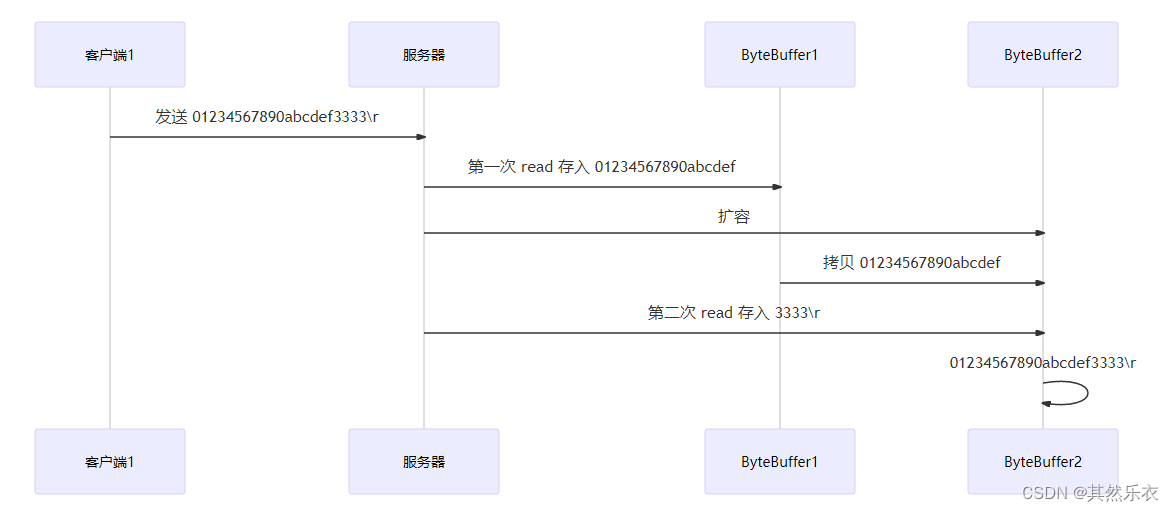
source.compact(); // 0123456789abcdef position 16 limit 16
}
public static void main(String[] args) throws IOException {
// 1. 创建 selector, 管理多个 channel
Selector selector = Selector.open();
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.configureBlocking(false);
// 2. 建立 selector 和 channel 的联系(注册)
// SelectionKey 就是将来事件发生后,通过它可以知道事件和哪个channel的事件
SelectionKey sscKey = ssc.register(selector, 0, null);
// key 只关注 accept 事件
sscKey.interestOps(SelectionKey.OP_ACCEPT);
log.debug("sscKey:{}", sscKey);
ssc.bind(new InetSocketAddress(8080));
while (true) {
// 3. select 方法, 没有事件发生,线程阻塞,有事件,线程才会恢复运行
// select 在事件未处理时,它不会阻塞, 事件发生后要么处理,要么取消,不能置之不理
selector.select();
// 4. 处理事件, selectedKeys 内部包含了所有发生的事件
Iterator<SelectionKey> iter = selector.selectedKeys().iterator(); // accept, read
while (iter.hasNext()) {
SelectionKey key = iter.next();
// 处理key 时,要从 selectedKeys 集合中删除,否则下次处理就会有问题
iter.remove();
log.debug("key: {}", key);
// 5. 区分事件类型
if (key.isAcceptable()) { // 如果是 accept
ServerSocketChannel channel = (ServerSocketChannel) key.channel();
SocketChannel sc = channel.accept();
sc.configureBlocking(false);
ByteBuffer buffer = ByteBuffer.allocate(16); // attachment附件
// 将一个 byteBuffer 作为附件关联到 selectionKey 上,让每一个selectionKey具有自己的ByteBuffer
SelectionKey scKey = sc.register(selector, 0, buffer);
scKey.interestOps(SelectionKey.OP_READ);
log.debug("{}", sc);
log.debug("scKey:{}", scKey);
} else if (key.isReadable()) { // 如果是 read
try {
SocketChannel channel = (SocketChannel) key.channel(); // 拿到触发事件的channel
// 获取 selectionKey 上关联的附件
ByteBuffer buffer = (ByteBuffer) key.attachment();
int read = channel.read(buffer); // 如果是正常断开,read 的方法的返回值是 -1
if(read == -1) {
key.cancel();
} else {
split(buffer);
// 需要扩容
if (buffer.position() == buffer.limit()) {
ByteBuffer newBuffer = ByteBuffer.allocate(buffer.capacity() * 2);
buffer.flip();
newBuffer.put(buffer); // 0123456789abcdef3333\n
key.attach(newBuffer); // 将扩容的ByteBuffer作为新的绑定的附件,覆盖旧的附件
}
}
} catch (IOException e) {
e.printStackTrace();
key.cancel(); // 因为客户端断开了,因此需要将 key 取消(从 selector 的 keys 集合中真正删除 key)
}
}
}
}
}客户端
SocketChannel sc = SocketChannel.open();
sc.connect(new InetSocketAddress("localhost", 8080));
SocketAddress address = sc.getLocalAddress();
// sc.write(Charset.defaultCharset().encode("hello\nworld\n"));
sc.write(Charset.defaultCharset().encode("0123\n456789abcdef"));
sc.write(Charset.defaultCharset().encode("0123456789abcdef3333\n"));
System.in.read();测试结果图:
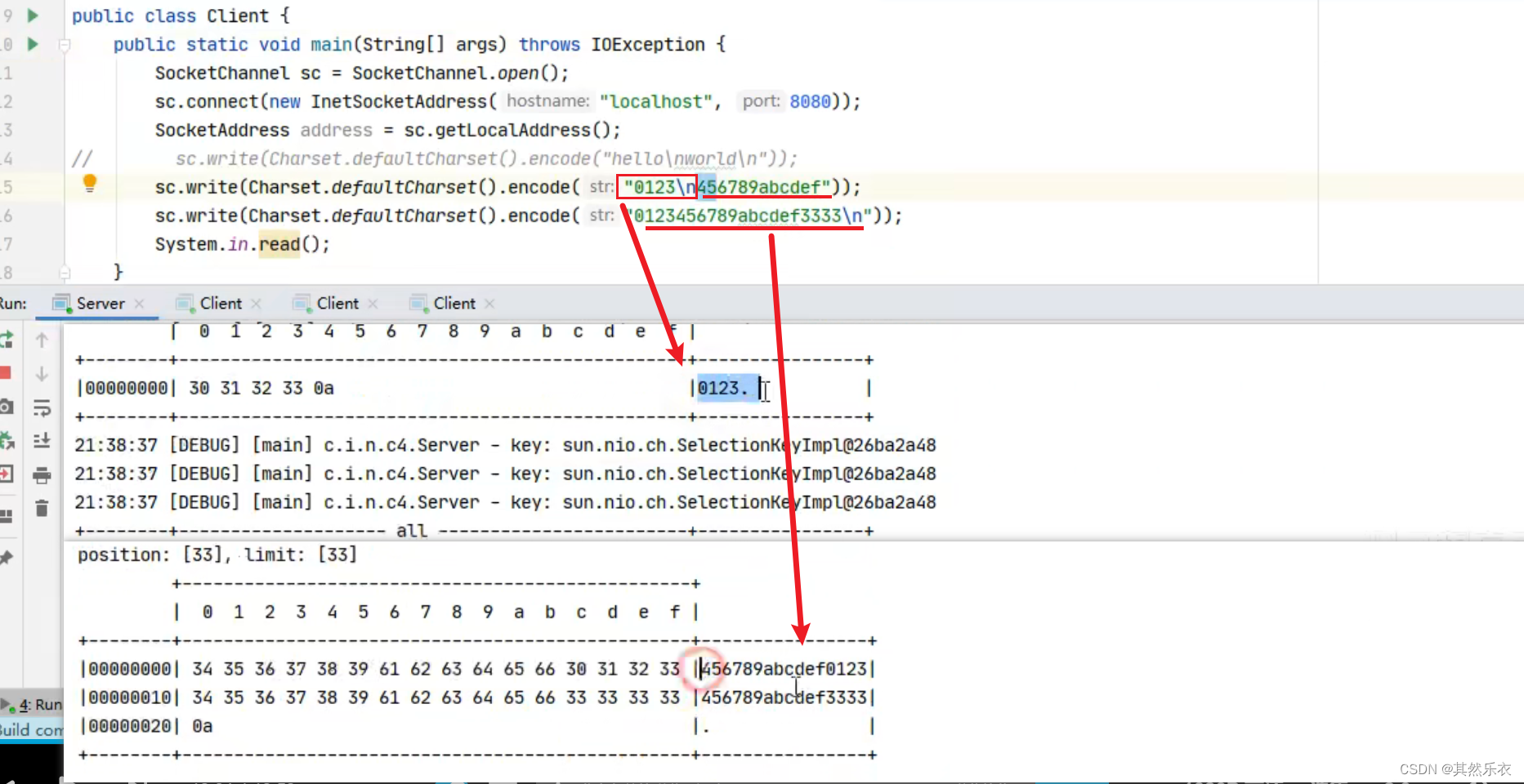
ByteBuffer 大小分配
-
每个 channel 都需要记录可能被切分的消息,因为 ByteBuffer 不能被多个 channel 共同使用,因此需要为每个 channel 维护一个独立的 ByteBuffer
-
ByteBuffer 不能太大,比如一个 ByteBuffer 1Mb 的话,要支持百万连接就要 1Tb 内存,因此需要设计大小可变的 ByteBuffer
-
一种思路是首先分配一个较小的 buffer,例如 4k,如果发现数据不够,再分配 8k 的 buffer,将 4k buffer 内容拷贝至 8k buffer,优点是消息连续容易处理,缺点是数据拷贝耗费性能,参考实现 Java Resizable Array
-
另一种思路是用多个数组组成 buffer,一个数组不够,把多出来的内容写入新的数组,与前面的区别是消息存储不连续解析复杂,优点是避免了拷贝引起的性能损耗
-
对应的教学视频:第1章_34_nio-selector-处理消息边界-附件与扩容_哔哩哔哩_bilibili

![[激光原理与应用-63]:激光器-光学-探测光、泵浦光和种子光三种光的区别](https://img-blog.csdnimg.cn/img_convert/c4dfd2c7cbbee4df88d949be656ed4d3.png)