文章链接
- 领域驱动设计(DDD)笔记(一)基本概念-CSDN博客
- 领域驱动设计(DDD)笔记(二)代码组织原则-CSDN博客
- 领域驱动设计(DDD)笔记(三)后端工程架构-CSDN博客
DDD基本概念
- DDD 是一种面向复杂需求的软件设计方法,将软件开发和核心业务概念深度联系起来,设计出不断发展的模型
- DDD 目标概述
- 将主要重点放到核心领域和领域逻辑上(core domain)
- 将复杂的业务逻辑的实现设计体现在领域模型上
- 在技术专家和领域专家直接发起创造性合作,不断晚上特定领域下的概念模式
- DDD 名称解释
- 领域是一系列业务知识和业务行为的集合
- 比如金融领域:商户、客户、用户等领域专家从事活动、积累经验、掌握知识的集合
- 比如医疗领域: 医生、护士等领域专家从事活动、积累经验、掌握知识的集合
- 领域专家:领域专家不是一个职位;他可以是精通业务的任何人,了解业务领域知识,他们可能是相关从业者、产品经理、开发者、QA、销售等等。
- Model:领域模型是关于某个特定业务领域人软件模型。通常领域模型通过对象模型实现,这样对象同时包含了数据和行为,表达了准确的业务含义。
- Ubiquitous language
- 通用语言指的是一种围绕域模型构建的语音,由所有团队成员在限界上下文中使用,将团队和活动软件联系起来。比如在财经领域: 直连、间连、收单、退款
- 只有团队中所有成员都使用了通用语言(所有的词语、概念都是明确的),才能保证我们各方的理解是正确的;团队内成员合作是紧密高效的;是能激发团队内成员的创造力的。
- Context :上下文指的是一个人为设定,确定了上下文环境后,我们才能确定词语或语句的含义。只有在一个明确的上下文中,模型才能被理解。
- Bounded context
- 限界上下文是一个程序之内的概念性边界。在这个边界之内的每种领域术语、词组或者句子,都有明确的上下文含义。在这个边界之外,这些术语可能表示不同的意思。比如:用户这个概念,在在线问诊上下文中,是在线问诊被服务方,与医生概念相对;而在头条账号上下文中,则是注册账号的自然人实体,不区分用户、医生。
- 另外,相同一个客观物体,在不同的限界上下文中,关心的概念和细节也是不同的。 如,一个产品在商品上下文中,被称为商品,关心的是商品的规格、价格等信息;在物流上下文中,被称为货物,关心的则是仓储地、发货地、目的地等信息。
- 领域是一系列业务知识和业务行为的集合
DDD的好处和限制
好处
- 使领域专家和开发者一起工作,软件可以准确的传达业务规则
- “准确传达业务规则”是指软件就像领域专家开发出来的一样
- 可以帮助业务开发自我提高 在DDD中每个人都在学习,都是知识的共享者
- 团队的沟通效率和协作效率变得更高,统一模型语言,团队成员之间不存在翻译,或者减少翻译
- 对技术研发而言DDD分为战略设计和战术设计,以代码为界线上下文作为服务领域边界,代码开发始终围绕着领域中的关键模型
- 更好的指导我们划分服务、领域、设计更清晰的架构
- 指导我们写出更清晰、容易维护、符合SOLID原则的代码
限制
- DDD只适用于领域复杂、业务逻辑复杂的情况,它不适用于领域相对简单,但技术复杂的应用程序
- DDD学习曲线陡峭,需要在团队内反复实践,并且大家的认识也不一定一致
- DDD设计非常耗时,并且需要强大的领域专业知识。它需要领域专家的参与,所以需要根据项目实际情况决定是否使用DDD
- DDD设计是发展的,不是一蹴而就。需要知行结合,长期不断投入精力迭代
业务理解工具
可以使用业务模型画布(bussiness model canvas)来描述业务模型,可以使用用户故事图(user story mapping)来了解业务。

用户故事图:
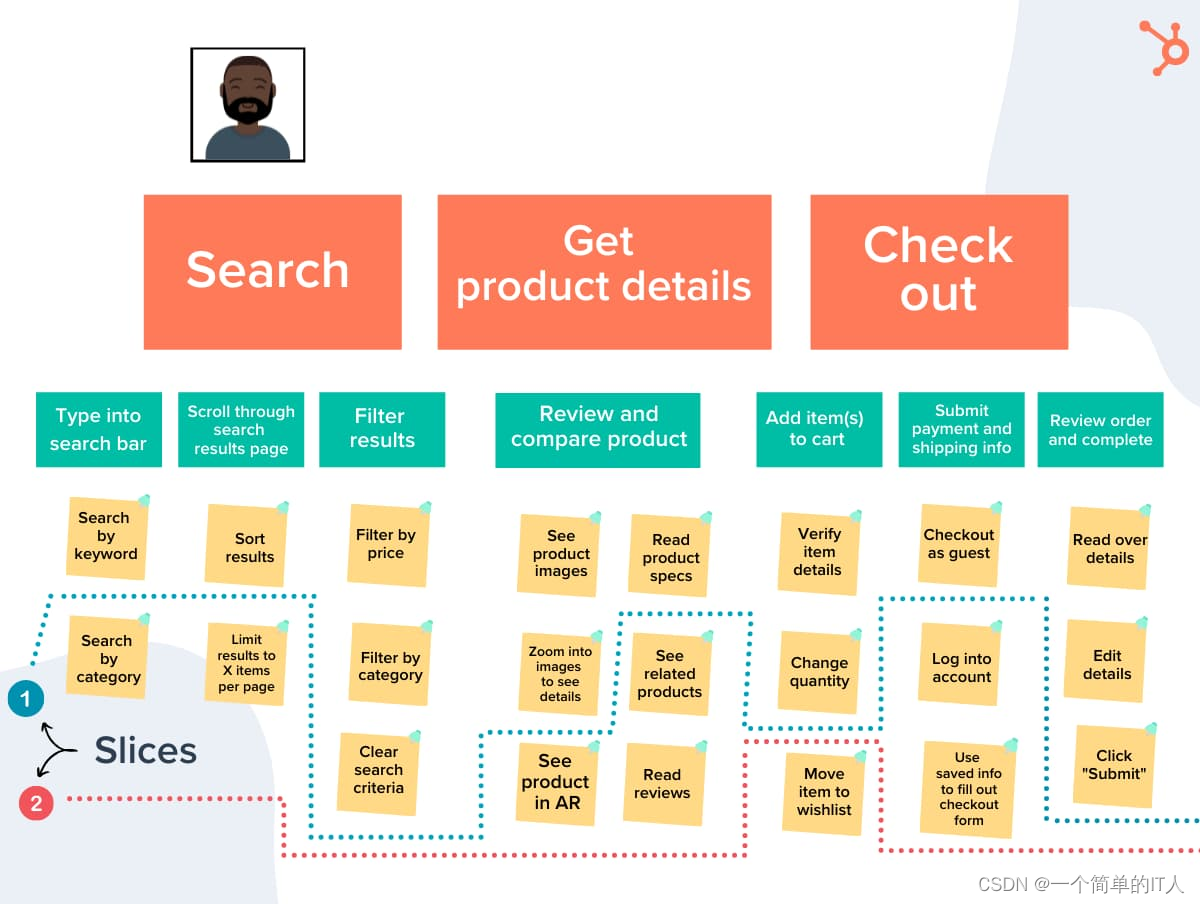
发现领域(四步法)
如何发现领域是DDD关键环节,如果整个团队没有很好的理解领域,软件决策有可能被误导,所谓发现领域,继需要我们各方协作,以可视化的方式发现业务模型中存在的领域。之后我们确保领域知识在整个团队中传播,使得所有成员能够为改进产品做出贡献。
需要说明的是发现领域的过程是持续不断的,我们总能在互相沟通中,不断细化对领域的理解,发现当前领域的不足
发现领域往往是最难的一步,这个阶段我们需要和领域专家进行深入、频繁的交流。最近方法是多次组织领域专家会议,并且尝试理解该领域中的知识。
在这个过程中,我们会收到很多学习;包括业务场景、角色、行为动作、产生影响等。我们可以使用事件风暴(event storming)方法,将这些离散数据串联为一个个业务场景,并归纳为领域
第一步,我们和领域专家一起分析业务,收集一下离散事件;参与人包括:设计、构建、测试软件的人、拥有领域知识的人、了解产品战略的人、了解客户需求的人 。
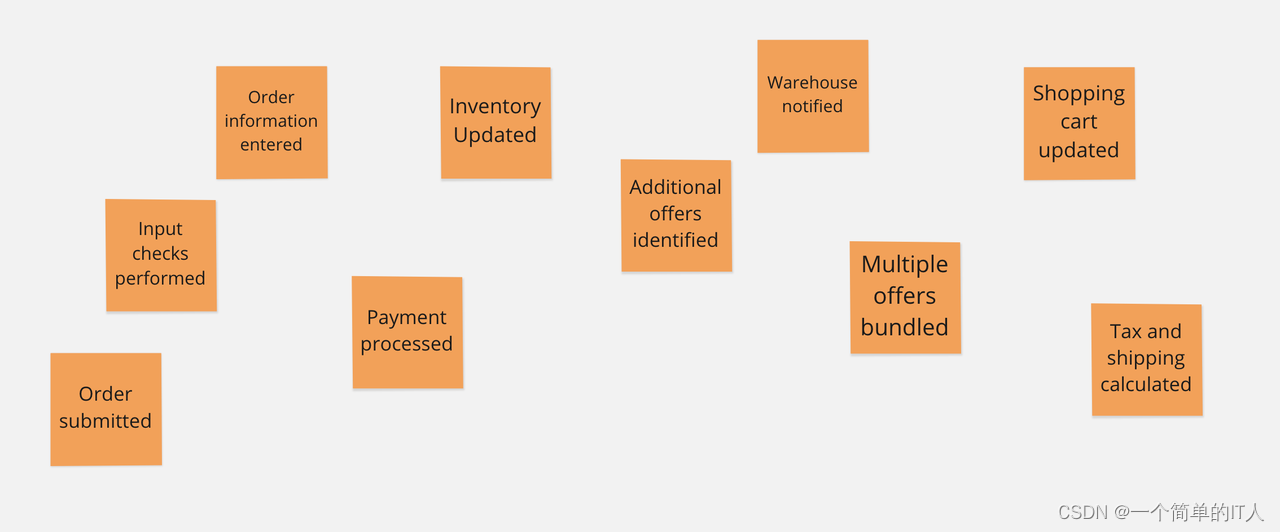
第二步,将收集到的事件按照时间排序,尝试找出中间缺失的环节
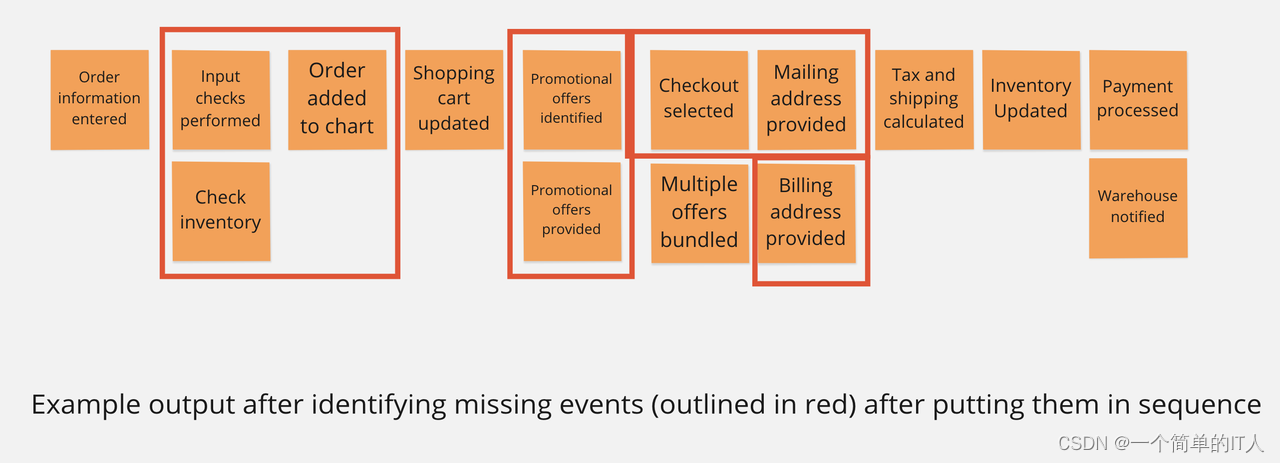
第三步,细化时间,为事件补充细节:

第四步,重新排序和总结,尝试对事件进行分类

各颜色代表的含义

识别核心领域
从工程角度而言,我们的时间和资源是有限的;从业务领域而言,我们总是感知到业务例最核心最重要的部分;因此了解领域的那些部分对业务产生最重要的影响至关重要,通过分析出核心领域是什么,我们更好的做出决策出构建系统的每个部需要多严谨、多稳定;哪些需要购买或者外部。
核心域:是让业务与众不同的地方,一个业务如果不在其核心领域表现出色,就不可能成功(甚至无法存在)。因此为核心域设计是如此重要;核心域设计是最高优先级、最大努力、最好的开发人员。对于较小的领域可能只有一个核心域,较大的可能有多个。(比如电商的支付场景的下单、结算中的订单模型和相关的接口就属于核心域)
支撑域:业务成功必须有的子域,但不属于核心域;它也不是通用的,因为他仍然需要相关程度的专业化或者特异化(比如订单的管理、订单的审核对应的操作页面和后台就属于支撑域)
通用域:它不包含组织特殊内容,但仍需要整个行业解决方案才能正常工作。通过尝试为通用子域找到现成的软件可以大量节省时间和工作。比如用户身份管理、单点登录。
举个例子,假设我们在搭建电商的管理系统,我们已经确定了以下子域:
- merchant_info: 用于提高电商的商户信息操作的基本接口
- merchant_admin: 用于进行电商商户的业务管理,比如入驻审核、体现管理、风险控制等
- settlement: 用于商户的清结算业务
- file archive:用于存储和管理商户的非结构化数据(营业执照照片、身份证照片等)
- sign:用于完成电商的签约和合同管理
现在我们开始进行分类:

确定领域模型的业务边界(限界上下文职责描述)
限界上下文既然作为一个显式边界,那么我们必须用更具体的语言去描述它,以便团队内所有成员对其的认识是一致的,以下举例一个膜拜,回答这些问题就是在描述领域模型的边界
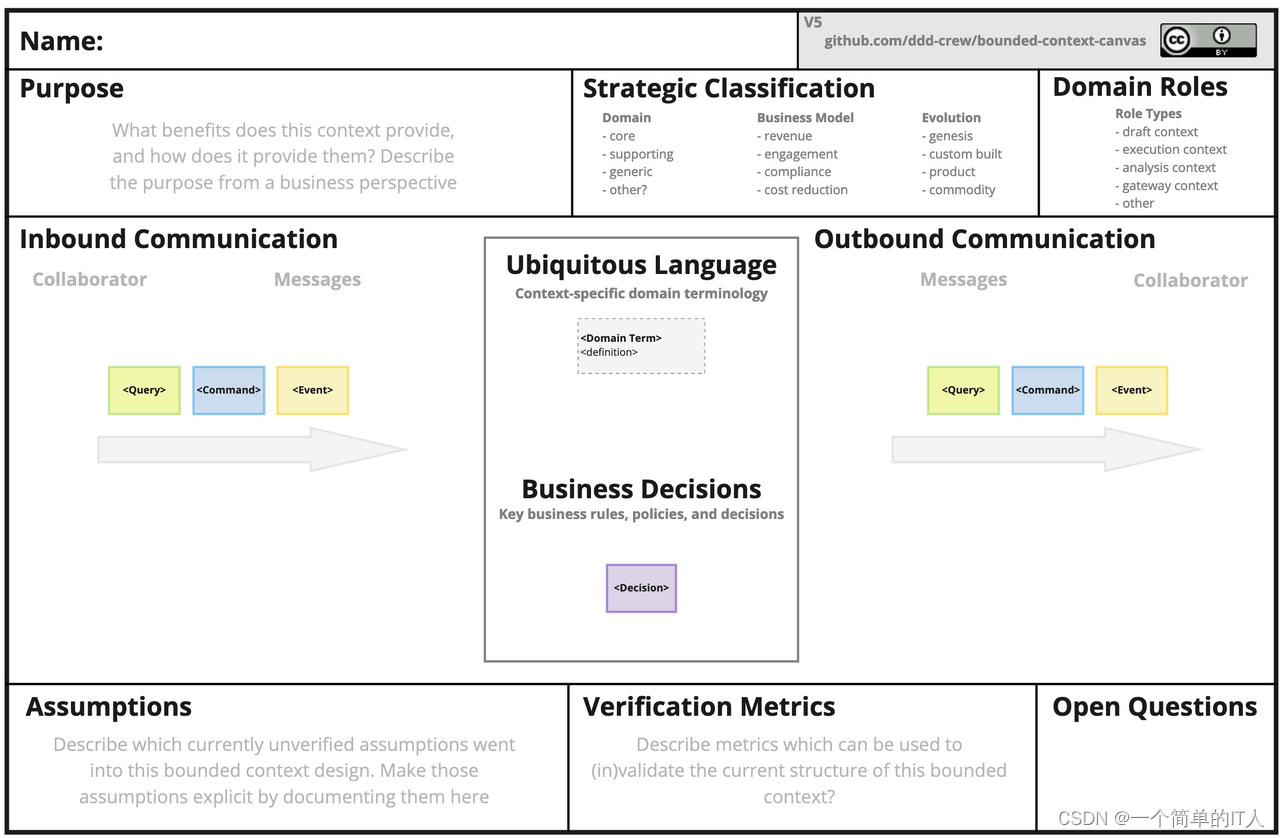
举个贷款评估的例子
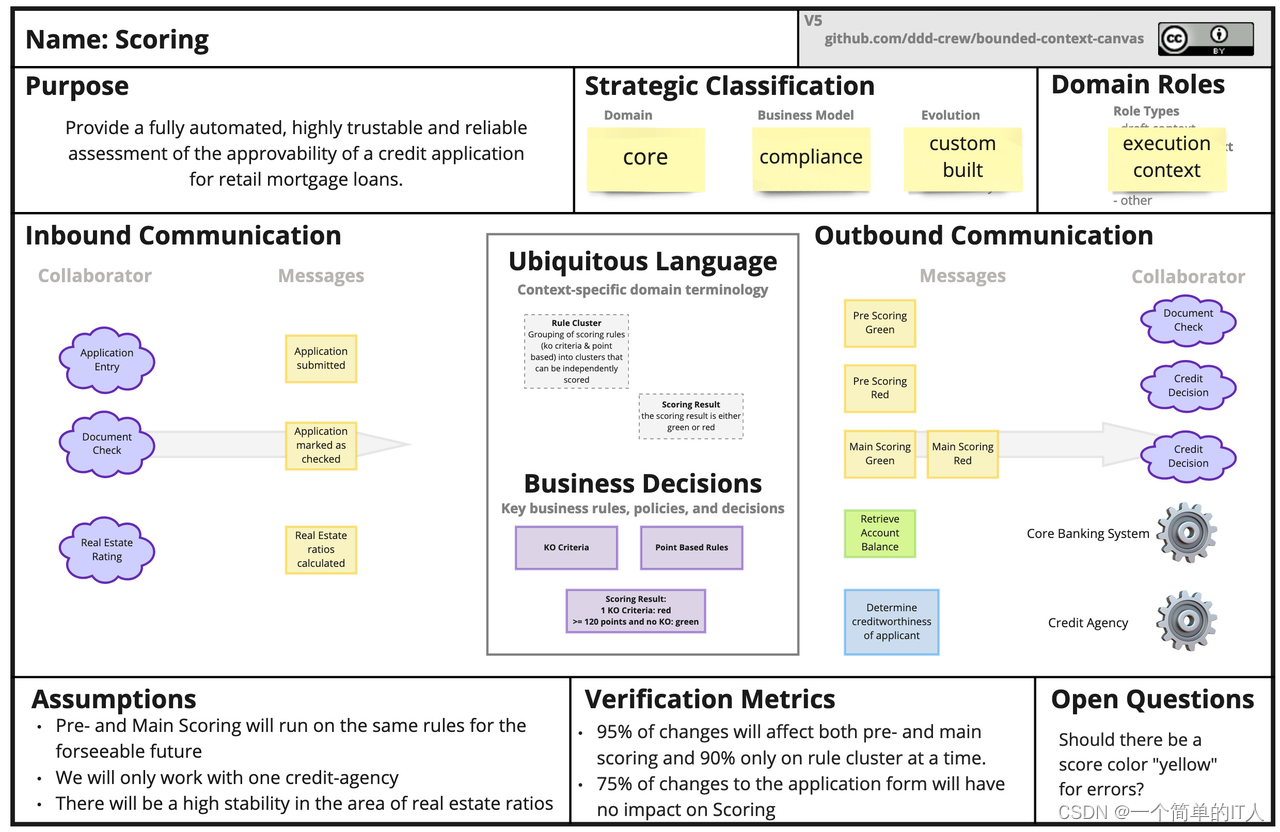
上下文映射(各个领域上下游之间的映射关系)
当我们定好所有上下文后,我们需要考虑各个上下文的直接的关系;我们引入上下文映射(context map);下面介绍几种常见的映射关系;方便我们日常选择。
- 合作关系(Partnership):准确来说这是在描述团队、上下文间的关系,而且是一种技术上的模式。它们建立了一种共同制定开发计划、共同管理的合作方式。
- 共享内核(Shared Kernel): 从领域模型中选出两个团队都同意共享的一个子集。除了模型的这个子集以外,可能还包括与该模型部分相关的代码子集.或数据库设计的子集。这部分明确共享的内容具有特殊的状态,而且一个团队在没与另一个团队商量的情况下不应擅自更改它,共享内核不能像其他设计部分那样可以自由更改。 在做决定时需要与另一个团队协商。当修改共享内核时,必须要通过两个团队的所有测试。例如,医学nlp上下文和视频审核上下文可以是共享内核关系。因为共享内核会导致两个上下文依赖很重,不推荐大家使用。
- 客户方-供应方开发(Customer-Supplier Development):在两个团队之间建立一种明确的客户/供应商关系。下游团队相当于上游团队的客户。根据下游团队的需求来协商需要执行的任务并为这些任务做预算,以便每个人都知道双方的约定和进度。两个团队一起开发自动验收测试,用来验证预期的接口。把这些测试添加到上游团队的测试case中,以便作为其持续集成的一部分来运行。这些测试使上游团队在做出修改时不必担心对下游团队产生副作用。 这也是我们最常见的合作模式之一。
- 遵奉者(Conformist):下游上下文只能盲目依赖上游上下文。例如,支付上下文和支付宝渠道通知上下文,就是遵奉者模式,支付上下文作为客户方只能遵循上游的协议和术语。
- 防腐层(Anticorruption Layer): 一个上下文通过一些适配和转换与另一个上下文交互。防腐层其实是设计思想“间接”的一种体现,引入一个中间层,有效隔离限界上下文之间耦合。防腐层往往属于下游限界上下文,用以隔绝上游限界上下文可能发生的变化,减少对上游不必要的依赖。
- 开放主机服务(Open Host Service): 定义一种协议来让其他上下文来对本上下文进行访问。开放这个协议,以便所有需要与你的子系统集成的人都可以使用它。当有新的集成需求时,就增强并扩展这个协议。例如,问诊IM提供的通用模板消息,可以认为是一种开放主机模式。
- 发布语言(Published Language): 通常与OHS一起使用,用于定义开放主机的协议。把一个文档化良好的、能够表达出所需领域信息的共享语言作为公共的通信媒介,必要时在其他信息与该语言之间进行转换。例如,redis通信协议可以被认为是一种PL,redis和字节内部的abase等都可以使用该协议通信;opentracing定义的事件协议,也可以是一种PL。
- 大泥球(Big Ball of Mud):混杂在一起的上下文关系,边界不清晰。当我们检查已有系统时,经常会发现系统中存在混杂在一起的模型,它们之间的边界是非常模糊的。此时,我们应该为这个混乱的系统划定一个边界,将其纳为大泥球的范畴。在这个边界之内,不要尝试使用复杂的建模手段来解决问题,并要时刻警惕不要让混乱的模型影响其他系统。
- 另谋他路(SeparateWay): 两个完全没有任何联系的上下文。让两个上下文扯上关系,总是有成本的。这种“无关系”仍然是一种关系额,而且是最好的一种关系。通过定义一个足够小、与其他上下文无关的上下文,让我们聚焦在这个小的领域,找到最简单、专用的解决方案。例如,全网作者库和抖音作者库集成到一个平台可能很麻烦,需要考虑很多问题。那么我们就让这两个上下文毫无关系,使用不同的方案去实现,比如都链接到已有平台。





![【Hadoop】--基于hadoop和hive实现聊天数据统计分析,构建聊天数据分析报表[17]](https://img-blog.csdnimg.cn/direct/3b3289d08e5b4760b22221992b76b577.png)