目录
交叉卡方检验
配对卡方检验
趋势卡方检验
交叉卡方检验
交叉卡方表用于比较组间“率”的差异。适用于分类型变量,被检验的分类变量应该是无序分类变量,分组变量可以是有序分组也可以是无序分组。比如比较两种药物治疗某个疾病的效率,分类变量就是两种药物,因为这是无序分类变量,分组变量可能是有50mg组,75mg组这样的分组,因为这是有序分类变量。
交叉表卡方检验使用的是gmodel包中的CrossTable函数。
在R语言中,CrossTable 函数是用来生成交叉表(列联表)的,并且可以进行卡方检验等统计测试,以分析不同分类变量之间的关系。以下是CrossTable函数的一些常用参数及其含义:
- x和 y:这两个参数指定了要进行交叉表分析的两个分类变量。也可以提前使用table(x,y)得到一张交叉表,这个表也可以作为CrossTable函数的参数,实际上我们推荐先用table函数生成一个交叉表作为CrossTable函数的参数。
- digits:设置输出中数值显示的小数位数。digits=2表示保留两位小数,这个参数也可以不写,后续使用round(数值,2)来保留两位小数
- max.width:设置交叉表的最大宽度。我还没有用过,这个参数不是很重要
- expected:逻辑值,指定是否计算并显示期望频数。通常会先把这个参数设置成T,看看交叉表的expect值是不是大于5,如果都大于5,且样本数大于40,则选择非连续校正,如果至少有一个小于5,且样本量大于40,则选择连续校正,如果样本量小于40则选择fisher精准检验
- prop.r、prop.c 和 prop.t:这些参数是逻辑值,分别指定是否显示行比例、列比例或表比例。
- prop.chisq:逻辑值,指定是否计算比例的卡方检验。
- chisq:逻辑值,指定是否执行卡方检验。
- fisher:逻辑值,指定是否执行Fisher精确检验。
- mcnemar:逻辑值,指定是否执行McNemar检验,这通常用于配对分类数据。
- resid、sresid、asresid:这些参数涉及残差的相关计算,用于更深入的分析,暂时没用过
- missing.include:逻辑值,指定是否在交叉表中包含缺失值。
- format:设置输出格式,可以是"SAS"或"SPSS"。
- dnn:可以指定一个自定义的列联表标题,这个参数一般没用,因为CrossTable函数的结果是一个列表,我们通常会把这个列表通过一系列的方式转换成数据框,每一列的名字在转成数据框的时候再修改即可。
举个例子,数据框mydata如图所示

这个数据框使我们通过spss.get函数读取进来的,spss.get函数来自于R包Hmisc。交叉卡方检验的对象应该是一张交叉表,也就是通过table函数得到的一张表,运行代码tab1

现在我们就要使用CrossTable函数对这个表进行交叉卡方检验,运行代码
CrossTable(tab1),注意大小写,运行结果如图
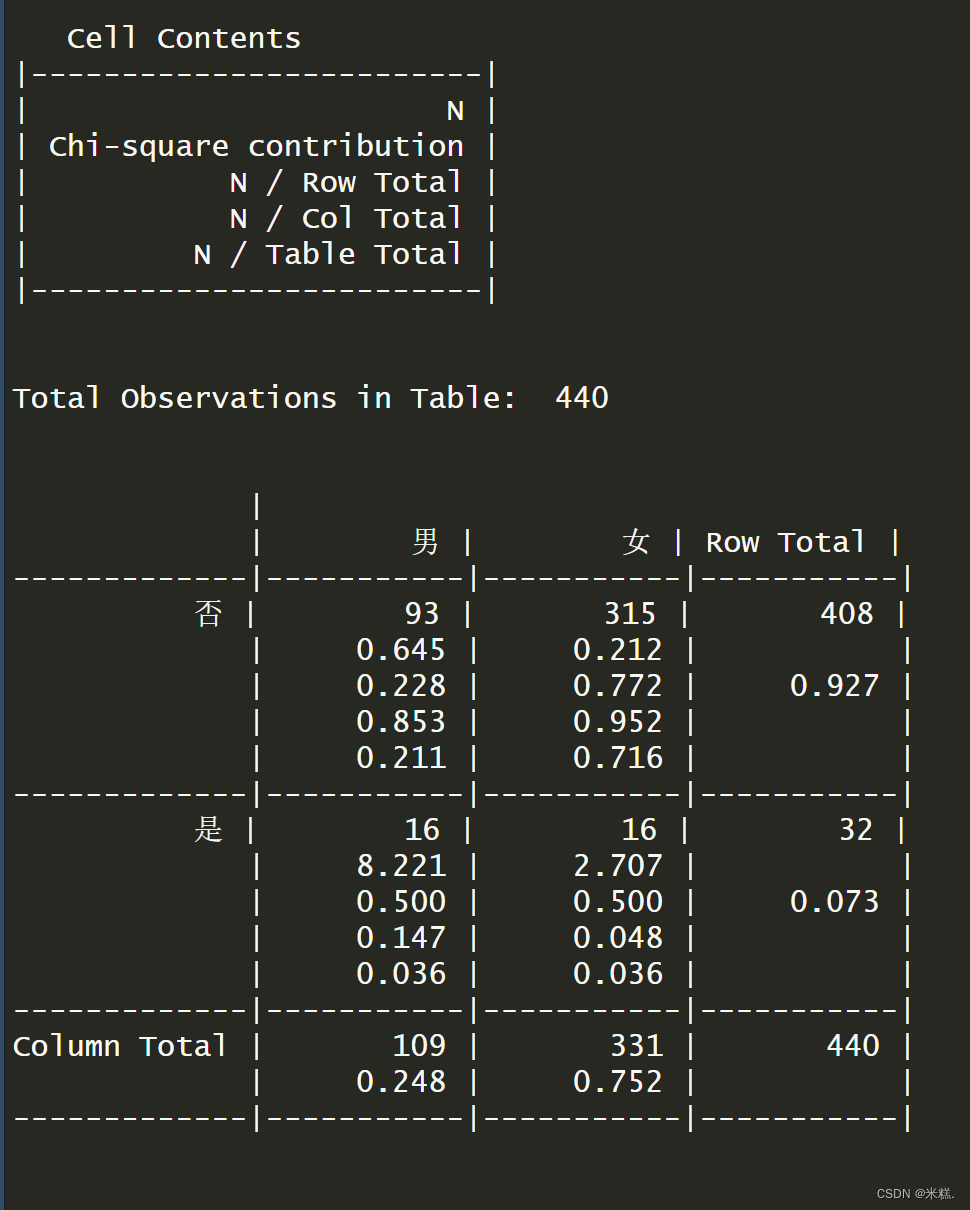
可以看到结果由两部分组成,第一部分是一个说明,第一行是交叉贡献,第二行是横向的一个比例,第三行是纵向的一个比例,最后是总的比例。
CrossTable函数默认是不输出卡方检验的结果的,如果想要让他输出,可以引入参数chisq=TRUE,这样结果就会在刚才的表格中多了这样一段

可以看到卡方检验的结果有非连续矫正(上面那个)和连续校正(下面那个),至于看哪一个的结果,规则如下,其中T叫做卡方值,n是样本数量,结果中有P值,卡方值越大,组间差异越大,P值越小,差异越大。也就是说我们希望T很大,P很小。

但是T是什么呢?这可以通过在CrossTable函数中引入参数expected=TRUE,这样运行结果会告诉我们T是多少,结果如图
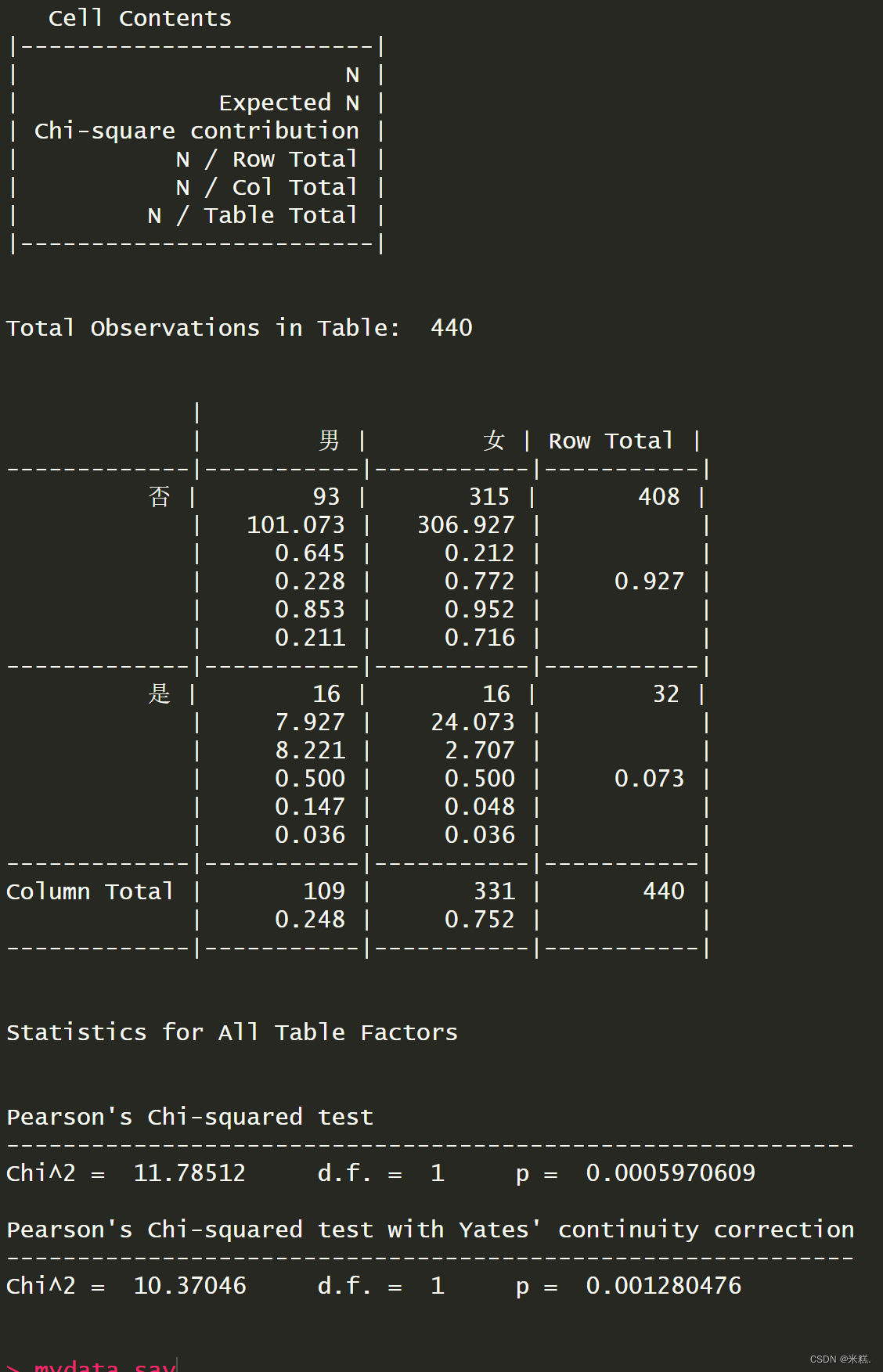
根据结果最开始的说明可以知道第二行就是T,我们发现所有的T都是大于等于5且n=440也是远大于40,所以我们选择非连续校正。把这个结果用a1存起来,通过class(a1)的结果可以发现a1是一个列表。长这样
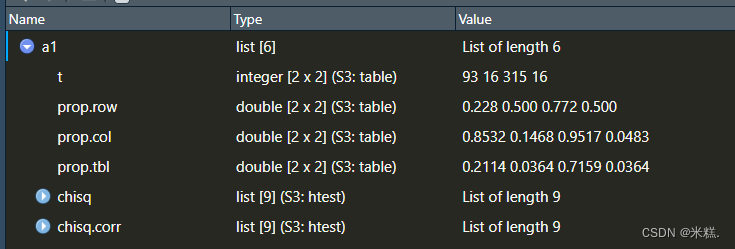
其中t是不同性别患病与不患病的人数,prop.row是横向的比例等等。查看列表中元素的方法是使用$符号,

其中a1$prop.col就是查看纵向的比例,也就是患病男性除所有男性,不患病男性除所有男性这样的,a1$prop.row是查看横向的比例,也就是患病的男性占总患病人数的比例,不患病的男性占总健康人数的比例这样的。
现在我想要把这个结果保存为下面这样的表格

以糖尿病病史这一块为例,要求列出是否患病,并在后面跟上对应的人数以及纵向的比例。代码如下

首先需要的是93,315,16,16这是a1$t,后面还跟了一个括号,括号里面是纵向比例,且是以百分号的形式给出的,保留两位小数。因此代码里面首先是拿到a1$t,然后连接了一个(,然后拿到了纵向比例,并使用round函数保留两位小数,然后又连接了)%,第一句代码执行结束之后这些内容就被paste0函数连接起来了,结果如图

这是一个字符串,我们想要把这个字符串转成上面的表格形式,就要先把他转换成一个两行两列的矩阵,然后把这个矩阵再转换成数据框并修改行名和列名,(转成数据框是为了后续好编辑,比如增加行或者列)因此上面整段代码执行的结果如下,得到了这样的一个数据框,看起来初具雏形。

接下来我们还应该加上糖尿病病史,卡方值,P值这几列,首先卡方值和P值都来自于卡方检验的结果,也就是chisq,他是a1列表里面的一个元素,我们点开看看发现长这样,chisq也是一个列表,他的第一个元素就是卡方值,第三个元素就是P值,现在问题在于chisq并不是一个表格形式(矩阵或者数据框)

把列表转换成表格形式的方法已经写过多次,使用的是do.call函数与rbind函数,运行代码list1
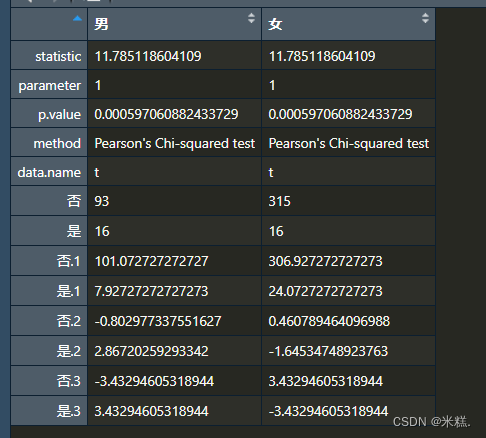
提取第一行第一列,和第一行第三列即可得到卡方值和P值。

其中部分列只有一个值,为了凑数加了一行NA进去,这个NA加的是字符串,不是那个缺失值NA。
运行结果如图

最后调整顺序,运行代码res1

配对卡方检验
同一批样本在两种情况下构成率的一致性检验就是配对卡方检验。
比如有一群运动员,用A方法和B方法检验这群人是否达标,两个方法得到的最后达标的结果不一样,现在要检验这两种方法得到的达标与不达标的差异,就用配对卡方检验。如果配对卡方检验得到的结果是两种方法是要一致的,那么通常还需要进行KAPPA检验,以检验两种方法的一致性。如果配对卡方检验得到的结果是两种方法具有差异性,那么就无需进行KAPPA检验,因为KAPPA检验是用来检验两种方法的一致性的。
配对卡方检验的函数仍然是CrossTable,但是需要将参数 mcnemar设置成TRUE,默认这个参数是FALSE。
假如有这样一个矩阵

现在以这个矩阵作为实参进行配对卡方检验。运行代码
CrossTable(tmp,mcnemar = T,expected = T)先看看预期值是不是大于5以决定用什么样校正,如果大于5就用非连续校正,如果小于5就用连续型校正。
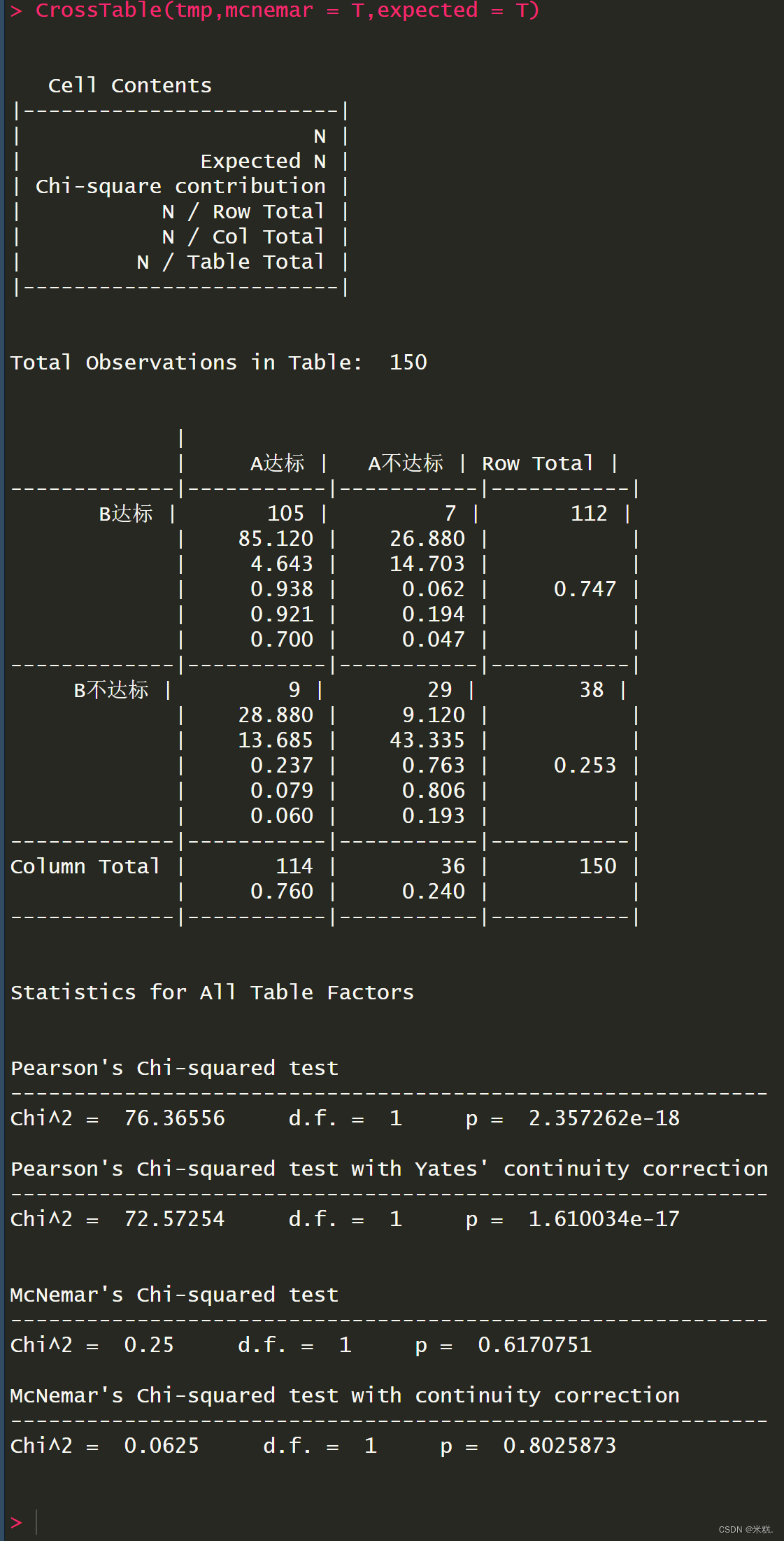
CrossTable函数的结果显示预期值均大于5,因此我们使用非连续校正。也就是这个

并且我们可以看到P大于0.05,因此两种方法不存在显著差异,此时我们需要进行KAPPA一致性检验,考查A与B方法的一致性程度,KAPPA一致性检验需要用到fmsb程序包中的kappa.test函数,运行代码Kappa.test(tmp)即可得到两种方法的一致性程度,如图

实际上我们只需要看这个sample estimates即可,这里显示两者的一致性程度为0.713056
趋势卡方检验
如果分组变量是有序分类变量,我们要探寻发生率是否会随着分组的变化而存在趋势,这时候就要选择趋势卡方检验,比如随着用药剂量的增加,治愈率是否会有一个趋势?
有这样一个名为b的矩阵

先运行代码CrossTable(b,chisq = TRUE, expected = TRUE)做一个交叉卡方验证,结果显示

对于这种多余两行的表CrossTable函数是不会给出连续型校正的,不过我们看到期望值都是大于5的,直接使用非连续性的校正即可,如果有Expect小于5的那么我们直接引入参数fisher=T表示进行Fisher精确检验即可。同时我们观察到P是0.25多显然大于0.05,因此不同剂量组之间的治愈率并没有显著差异,但是没有显著差异并不意味着不存在显著趋势。趋势卡方检验需要使用DescTools程序包中的CochraneArmitageTest()函数,现在我们有b这样的一个矩阵,直接把这个矩阵扔给CochranArmitageTest()函数即可判断不同剂量组与治愈是否存在趋势关系了,运行代码CochranArmitageTest(b)结果如图

p小于0.05说明有显著趋势。接下来整理一下信息的格式

res是一个列表,res$t是一个矩阵,长这样子

paste0里面放一个矩阵,并不是直接把这个矩阵和后面的东西连接起来,而是把矩阵里面的一个个元素和后面的东西连接起来,如果后面有再有矩阵,向量,这样的数据类型也是类似的,每次连接这些数据容器中的一个元素。因此第一句代码的意思就是连接矩阵中的元素,并且从结果来看R默认是按列的顺序进行元素的连接的。这是连接的结果

这个连接后的结果是一个character"类型,我们希望他变成一个数据框类型,就要先把这个字符转换成矩阵,因为矩阵的创建可以方便的给出行和列,直接data.frame把字符串转换成数据框不太行,因为不能很好的决定几行几列,所以我们代码中是先把字符串转换成矩阵并指定这个矩阵是六行两列,然后再把这个矩阵使用data.frame转换成数据框,最后用变量n把这个数据框存起来。最后对这个数据框的列名进行修改最终得到的数据框如图
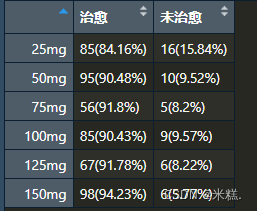
这样的数据框就可以直接写出成csv格式了,后续可以用excel打开这个文件方便的复制到word文档中。

![【Hadoop】--基于hadoop和hive实现聊天数据统计分析,构建聊天数据分析报表[17]](https://img-blog.csdnimg.cn/direct/3b3289d08e5b4760b22221992b76b577.png)