Enhanced Spatial-Temporal Salience for Cross-View Gait Recognition
Enhanced Spatial-Temporal Salience for Cross-View Gait Recognition | IEEE Journals & Magazine | IEEE Xplore
摘要:步态识别可以单独或与其他生物特征相结合,用于个人识别和再识别。虽然步态同时具有空间和时间属性,空间特征和时间特征解耦可以更好地在细粒度层面上利用步态特征,但是,在解耦过程中也丢失了视频信号的时空相关性,直接的3d卷积方法可以保持这种相关性,但它们也引入了不必要的干扰。本文提出了一种将解耦过程集成到三维卷积框架中的方法,用于跨视图步态识别。特别地,提出了一个由Parallel-insight卷积层和时空双注意(STDA)单元组成的新块作为全局时空信息提取的基本块。在STDA单元的引导下,该块可以很好地整合两个解耦模型提取的时空信息,同时保持时空相关性。此外,提出了一种多尺度显著特征提取器,通过对基于部件的特征进行上下文感知扩展并自适应聚合空间特征,进一步挖掘细粒度特征。在CASIA-B、OULP和OUMVLP三种常用的步态数据集上进行的大量实验表明,该方法优于目前最先进的方法。
I. I NTRODUCTION
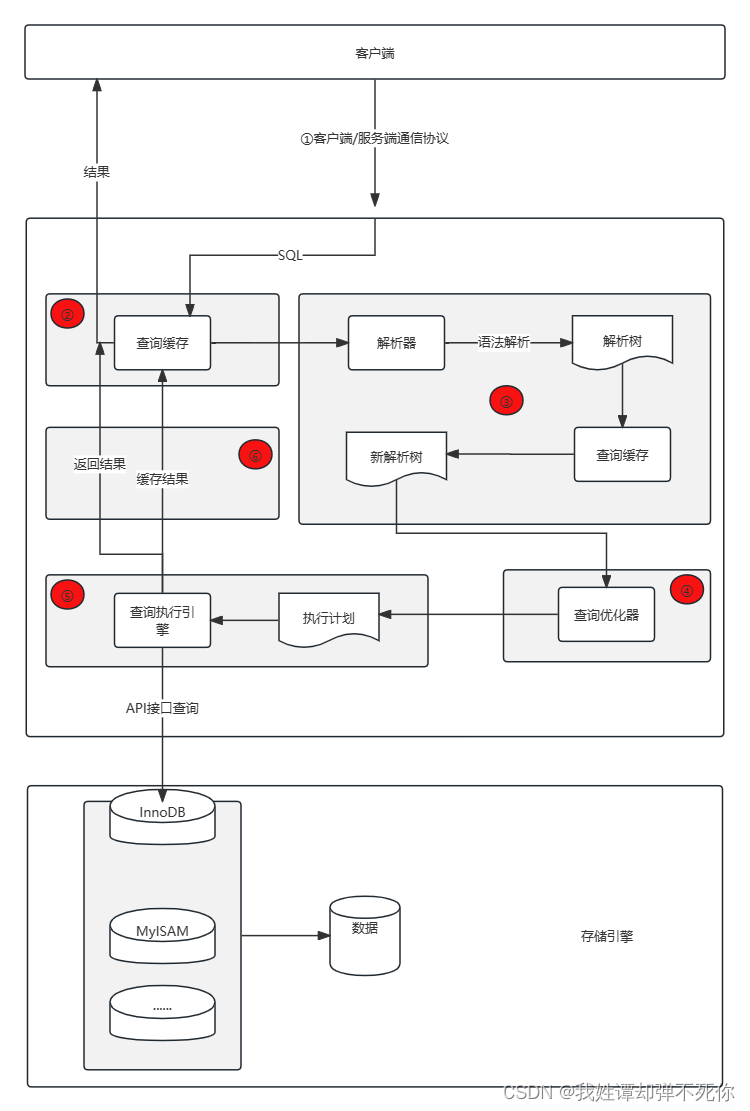
如图1所示,ESNet由初始层和两个精心设计的组件组成,即Dual-Attention Guided Feature Extractor (DAGFE)和Multi-ScaleSalient Feature Extractor (MSSFE)。具体来说,DAGFE 是一个 特殊的堆叠 CNN,它具有多个专门设计的 块,并以浅时空特征作为输入。DAGFE 中的每个块都可以并行提取联合时空和单个时空域的信息,然后将所有信息以直观但有效的方式组合。因此,我们可以提取更高质量的全局时空特征,而不会丢失两个域之间的相关性。随后,提出了从全局时空特征中挖掘细粒度特征MSSFE,可以进一步提高特征表示ESNet的能力。更具体地说,我们做出了以下三个主要贡献:1在DAGFE中,我们提出了一种新的时空提取层,称为并行洞察卷积(Pi-Conv)层,以实现直接3D卷积和解耦建模的协同作用。核心思想是 ,以实现并行卷积感知和提取 其核心思想是使并行卷积能够感知和提取不同域的信息。在DAGFE中,我们设计了一个简单而有效的注意力单元,即STDA单元。这是第一个专门为基于轮廓序列的步态识别设计的注意方法。采用注意方法,STDA 单元可以自适应调整Pi-Conv层的输出,实现直接三维卷积和解耦建模的更好集成。
MSSFE进一步获得突出和紧凑的细粒度特征。与直接对全局时空特征进行水平切片得到基于部件的特征不同,MSSFE扩展了每个部件的上下文感知范围来捕获相邻部件之间的关系,并自适应地聚合空间特征,从而更有效地促进了基于部件的鲁棒性特征学习。
2 整体实现流程:
XS = {x i |i = 1, 2, . . . , t }——输入进two initial layers (两个3DCNN)获取时空特征 输出f【B,10,32,64,44】——![]() reshape 操作——
reshape 操作——![]() MSSFE包含两个操作
MSSFE包含两个操作 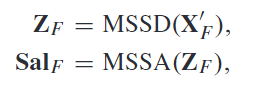 其中 MSSD 表示多尺度显着性描述符 ,可以提高每个 部分的空间上下文感知并有效地提取显着基于部分的特征。MSSA表示多尺度显着性聚合器,它使用 自适应地聚合 MSSD 获得的特征,获得紧凑的特征表示。最后,采用几个separate FC层将特征向量映射到metric空间,用于最终的个体识别。
其中 MSSD 表示多尺度显着性描述符 ,可以提高每个 部分的空间上下文感知并有效地提取显着基于部分的特征。MSSA表示多尺度显着性聚合器,它使用 自适应地聚合 MSSD 获得的特征,获得紧凑的特征表示。最后,采用几个separate FC层将特征向量映射到metric空间,用于最终的个体识别。


双注意引导特征提取器(Dual-Attention Guided Feature Extractor, DAGFE)
由三个串联块组成,旨在提取高质量的全局时空特征。如图2(a)所示,每个块由两个主要部分组成,一个是平行洞察卷积(Pi-Conv)层,另一个是空间- 时间双重注意(STDA)单元。在这一部分中,将首先详细描述Pi-Conv层和STDA单元,然后对每个模块进行总体说明。
1) Pi-Conv层:
a)定义:Pi-Conv层是一种基于三维卷积的新型时空特征提取层,包含三个不同核数的并行三维卷积。这三个并行的3D卷积分别在输入特征图上执行,它们的输出以元素方式添加。
b)动机:为了通过三维卷积将时空特征的解耦学习和关系保持组装起来,开发了Pi-Conv层。如图2(b)所示,可以通过设置Pi-Conv层的核大小来确定神经元的洞察域。核大小为k1 × k1 × k1的三维卷积(图2(b)左)是一种规则的三维卷积操作,可以同时提取时空信息。核大小为k2 × 1 × 1(图2(b)中)和1 × k3 × k3(图2(b)右)的3D 个卷积分别可以实现个独立的时域和空域特征提取,分别为个。这种并行洞察卷积设计保证了时空信息的协同,同时提取了高质量的时空特征,使两种基于序列的建模方法的优势得以充分发挥。

2) STDA单元:
a)定义:STDA单元是一个简单而有效的注意模块,专为基于轮廓序列的步态识别而设计。如图2(c)所示 STDA单元由两个简单的注意分支和几个元素算术运算组成
b)动机:将解耦的(时空)建模与直接的3D卷积有效整合,可以获得更鲁棒的时空特征。为此,设计了STDA单元并注入到每个块的封头中(将图2(c)注入到图2(a)中)。考虑到步态识别的二进制轮廓输入,我们抛弃了非局部注意机制,(将通道维度池化)因为他的输入是缺乏颜色和纹理,该机制计算每对像素位置的相似性或明确建模通道相互依赖(例如CBAM[43]或SENet [42])相反,STDA单元由两个简单的分支组成。时间注意分支(图2(c)中的左分支)探索时间特征之间的相关性,空间注意分支(图2(c)中的右分支)探索空间域中的语义鲁棒性特征。通过双注意分支的并行设计,可以激活输入中的关键空间和时间信息。通过将STDA单元嵌入Pi-Conv层的头部,期望STDA单元能够自适应调整Pi-Conv层提取的时空信息,从而更好地实现解耦时空特征提取与直接三维卷积的融合


该模块总体框架:



多尺度显著特征提取器多尺度显著特征提取器(MSSFE)
是为进一步的显著性和判别性零件特征提取而设计的。具体结构如图3所示。对于DAGFE的输出XF∈RN×C×T ×H×W,我们希望通过H轴上不同的个水平部分,挖掘出多样化、鲁棒性的细粒度特征。如第III-A节所述,首先进行重塑(RS)操作,使XF的432空间特征平坦化,以满足MSSFE的输入要求。MSSFE可以分解为一个多尺度显著描述符(MSSD)和一个多尺度显著聚合器(MSSA)。接下来,将分别对MSSD和MSSA进行详细介绍。
1) MSSD:
a)定义:MSSD是扩张卷积的一种新应用,它包含多个多尺度1D卷积,即多尺度Conv1d(如图3所示),,每个多尺度Conv1d由多个平行的不同扩张率的1D卷积组成。设n为预先定义的并行1D卷积的数字,d1, d2,…, dn分别表示这些平行一维卷积的膨胀率。其中,当n = 1.时,Multi-Scale Conv1d是等价于普通1D卷积层的-。
b)动机:人体的每个部位之间都有的依赖关系,尤其是相邻部位之间。为了增强基于零件的空间特征的细粒度学习,避免丢失相邻零件之间的关系,设计了MSSD。如图2所示,与XF的直接水平拼接相比,各部分的上下文感知范围随着膨胀率的逐渐增大而扩大,从而可以捕捉到相邻部分之间的关系。此外,具有多个不同膨胀率的并行1D卷积使每个部分能够感知多尺度上下文。通过这种方法,可以获得更加多样化和鲁棒的基于零件的特征表示。
c)操作:如图3所示,首先将重塑后的输入feature图X F∈RN×C×T X (H×W)沿T维切片,每个切片分别发送到Multi- Scale Conv1d。然后对每个切片执行常规卷积操作。请注意,每个切片的这些Multi-Scale Conv1ds是参数共享的。之后,沿着通道连接每个片的个输出。然后将所有这些切片的输出组合为整个输出特征图,并反向重塑以恢复形状,如XF。从而生成形状为N × nC × T × H × W的多尺度特征描述子。通常,在特征描述符上应用全局最大池化(GMP)操作来获得最终的多尺度特征ZF∈RN×nC×H×W
2) MSSA:475 a)定义:MSSA的行为就像一个多尺度显著性特征受体,可以感知哪些基于部分的多尺度特征是判别性的,需要保留。执行突出特征选择和各部分自适应空间特征聚合。
b)操作

与max和均值等常用统计函数相比,MSSA可以自适应地对各部分的空间特征进行整合,同时保持特征的显著性。
小结
这篇文章核心是利用3D 卷积 提取时空特征,保持步态识别的时空相关性,双注意引导特征提取器加入了注意力机制,同时将之前用的HPM水平金字塔映射 换成了基于扩张卷积的多尺度特征提取器,统计函数不再是max 操作,使用MSSA可以自适应地对各部分的空间特征进行整合,同时保持特征的显著性。