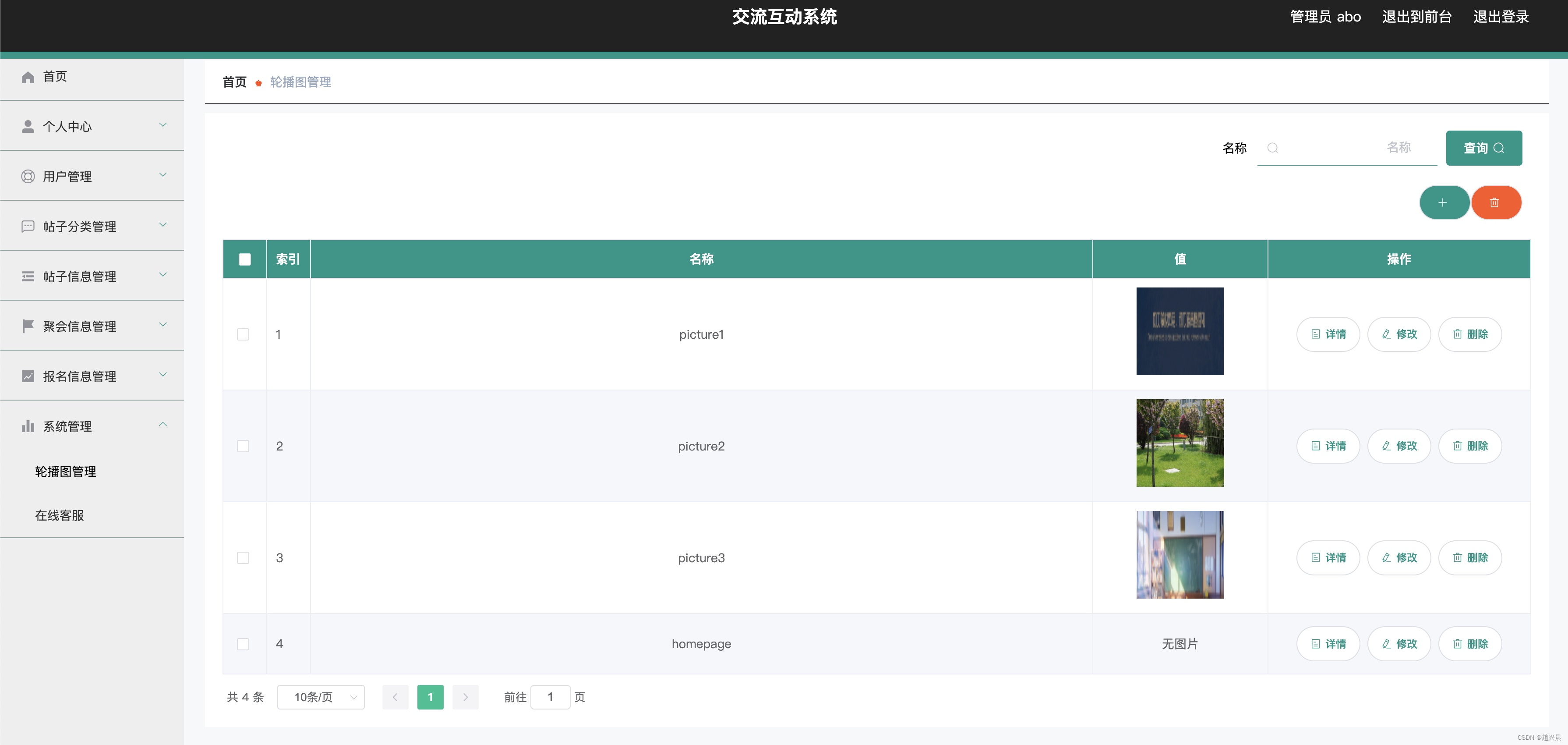
首先,我们得有个环境——通常是个缓冲池,这个池子里可以塞很多缓冲区,它们是用来存放数据的。生产者就是那个不停造东西的家伙,而消费者则是等着用这些东西的人。
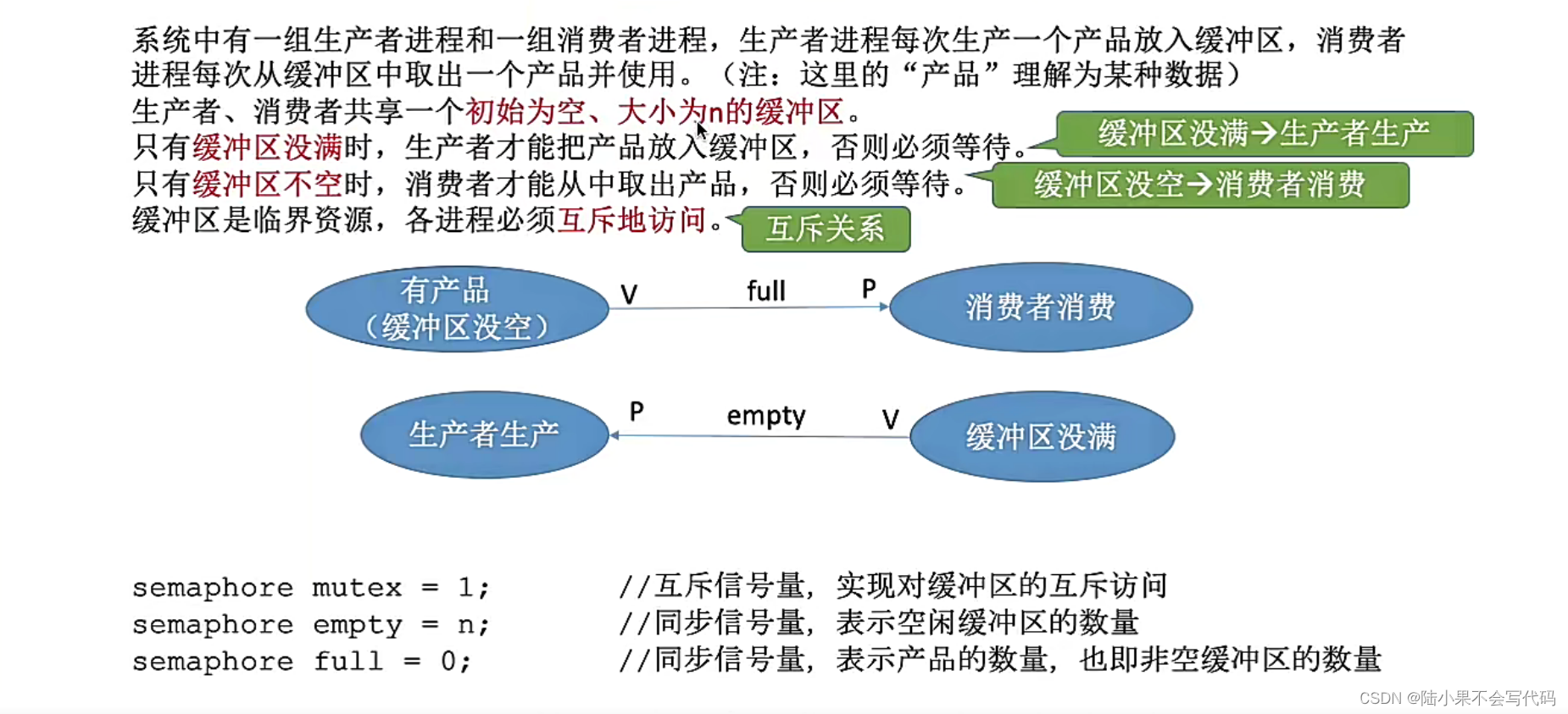
1. 空闲缓冲区(empty): 这玩意儿其实是个计数信号量,它的值表示当前有多少个空的缓冲区可以被生产者使用。这个数是动态变化的,每当生产者往一个缓冲区内放置了数据后,这个“empty”信号量就会减一(因为空的缓冲区少了一个)(一般初始值为n)。而每当消费者从缓冲区中取出数据,这个信号量就会增加,因为又空出来了一个缓冲区。这个信号量的初始值通常是缓冲区的总数。
2. 非空缓冲区(full): 相对的,这个也是个计数信号量,但它告诉我们有多少个缓冲区是满的,即里面有数据,等待消费者来取用。这个“full”信号量在生产者放入数据时增加(表示现在又多了一个满的缓冲区),而在消费者取用数据后减少(因为缓冲区被清空了)。如果你有5个缓冲区,开始时这个信号量是0,因为还没有生产者放东西进去。
在这个模型中,生产者和消费者通过这两个信号量来同步他们的活动。如果“empty”信号量是0,意味着没有空的缓冲区,生产者就需要等待,不能继续生产。相似地,如果“full”信号量是0,说明没有满的缓冲区,消费者也需要等待,不能消费数据。
这种机制不仅保证了数据的安全生产和消费,而且还避免了资源的冲突和浪费,是不是挺精妙的?这种玩法确保大家都不会踩到对方的脚,同时又能保持生产和消费的高效率。就这样,操场上的游戏规则清清楚楚,谁也不会撞车了。