目录
概念
通用文件模型
VFS所处理的系统调用
VFS的数据结构
超级块对象
索引节点对象(inode)
文件对象
目录项对象
目录项高速缓存
与进程相关的文件
文件系统类型
特殊文件系统
文件系统类型注册
文件系统处理
命名空间
概念
虚拟文件系统(Virtual Filesystem)也可以称之为虚拟文件系统转换(Virtual Filesystem Switch),是一个内核软件层,用来处理与Unix标准文件系统相关的所有系统调用。其健壮性表现在能为各种文件系统提供一个通用的接口。可以认为它屏蔽了不同文件系统之间的实现细节转而依赖它们的接口。

VFS支持的文件系统可以划分为三种主要类型:
-
磁盘文件系统 这些文件系统管理在本地磁盘分区中可用的存储空间或者其他可以起到磁盘作用的设备(比如说一个USB闪存)。VFS支持的基于磁盘的某些著名文件系统有:Disk-based 文件系统:Ext2, ext3, ReiserFS,Sysv, UFS, MINIX, VxFS,VFAT, NTFS,ISO9660 CD-ROM, UDF DVD,HPFS, HFS, AFFS, ADFS等等
-
网络文件系统 这些文件系统允许轻易地访问属于其他网络计算机的文件系统所包含的文件。虚拟文件系统所支持的一些著名的网络文件系统有:NFS、Coda、AFS(Andrew文件系统)、CIFS(用于Microsoft Windows的通用网络文件系统)以及NCP(Novell 公司的NetWare Core Protocol)。
-
特殊文件系统 这些文件系统不管理本地或者远程磁盘空间。/proc文件系统是特殊文件系统的一个典型范例(参见稍后“特殊文件系统“一节)。
根目录包含在根文件系统(root filesystem)中,在Linux中这个根文件系统通常就是Ext2或Ext3类型。其他所有的文件系统都可以被“安装“在根文件系统的子目录中基于磁盘的文件系统通常存放在硬件块设备中,如硬盘、软盘或者CD-ROM。Linux VFS 的一个有用特点是能够处理如/dev/loop0这样的虚拟块设备,这种设备可以用来安装普通文件所在的文件系统。作为一种可能的应用,用户可以保护自己的私有文件系统,这可以通过把自己文件系统的加密版本存放在一个普通文件中来实现。
通用文件模型
VFS所隐含的主要思想在于引入了一个通用的文件模型(common file model),这个模型能够表示所有支持的文件系统。该模型严格反映传统Unix文件系统提供的文件模型。
例如,在通用文件模型中,每个目录被看作一个文件,可以包含若干文件和其他的子目录。但是,存在几个非Unix的基于磁盘的文件系统,它们利用文件分配表(File Allocation Table,FAT)存放每个文件在目录树中的位置,在这些文件系统中,存放的是目录而不是文件。为了符合VFS的通用文件模型,对上述基于FAT的文件系统的实现,Linux必须在必要时能够快速建立对应于目录的文件。这样的文件只作为内核内存的对象而存在。
从本质上说,Linux内核不能对一个特定的函数进行硬编码来执行诸如read()或ioctl()这样的操作,而是对每个操作都必须使用一个指针,指向要访问的具体文件系统的适当函数为了进一步说明这一概念,参见图12-1,其中显示了内核如何把read()转换为专对MS-DOS文件系统的一个调用。应用程序对read()的调用引起内核调用相应的sys_read()服务例程,这与其他系统调用完全类似。
文件在内核内存中是由一个file数据结构来表示的。这种数据结构中包含一个称为f_op的字段,该字段中包含一个指向专对MS-DOS文件的函数指针,当然还包括读文件的函数。sys_read()查找到指向该函数的指针,并调用它。这样一来,应用程序的read()就被转化为相对间接的调用:file->f_op->read(…);与之类似,write()操作也会引发一个与输出文件相关的Ext2写函数的执行。简而言之,内核负责把一组合适的指针分配给与每个打开文件相关的file变量,然后负责调用针对每个具体文件系统的函数(由f_op字段指向)。(人话,调用具体的函数指针,想想虚函数表)
通用文件模型有下列对象组成:
-
超级块对象存放在已安装文件系统的有关信息,对基于磁盘的文件系统,,它们通常对应于存放在磁盘上的文件控制块
-
索引节点对象:也就是Iinode存放关于具体文件的一般信息
-
文件对象:存放打开文件与进程之间进行交互的有关信息,这类信息仅当进程访问文件期间存在于内核内存中!
-
目录项对象:存放目录项与对应文件进行链接的有关信息
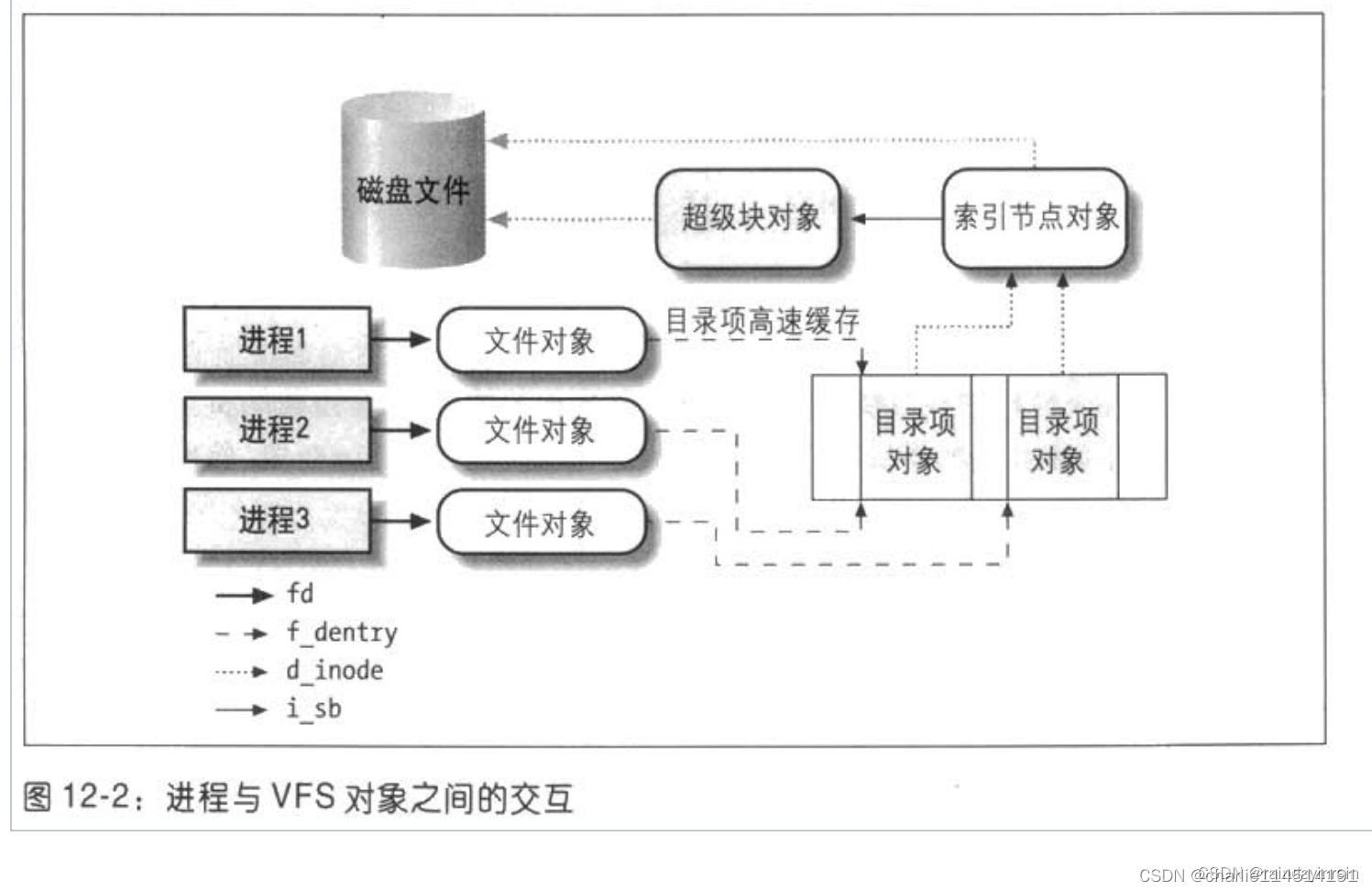
如图12-2所示是一个简单的示例,说明进程怎样与文件进行交互。三个不同进程已经打开同一个文件,其中两个进程使用同一个硬链接。在这种情况下,其中的每个进程都使用自己的文件对象,但只需要两个目录项对象,每个硬链接对应一个目录项对象。这两个目录项对象指向同一个索引节点对象,该索引节点对象标识超级块对象,以及随后的普通磁盘文件。

VFS除了能为所有文件系统的实现提供一个通用接口外,还具有另一个与系统性能相关的重要作用。最近最常使用的目录项对象被放在所谓目录项高速缓存(dentrycache)的磁盘高速缓存中,以加速从文件路径名到最后一个路径分量的索引节点的转换过程。
一般说来,磁盘高速缓存(diskcache)属于软件机制,它允许内核将原本存在磁盘上的某些信息保存在RAM中,以便对这些数据的进一步访问能快速进行,而不必慢速访问磁盘本身。
注意,磁盘高速缓存不同于硬件高速缓存(硬件高速缓存)或内存高速缓存(动态内存分配器),后两者都与磁盘或其他设备无关。硬件高速缓存是一个快速静态RAM,它加快了直接对慢速动态RAM的请求。内存高速缓存是一种软件机制,引入它是为了绕过内核内存分配器。除了目录项高速缓存和索引结点高速缓存之外,Linux还使用其他磁盘高速缓存。其中最重要的一种就是所谓的页高速缓存。
VFS所处理的系统调用
表12-1列出了VFS的系统调用,这些系统调用涉及文件系统、普通文件、目录文件以及符号链接文件。另外还有少数几个由VFS处理的其他系统调用,诸如ioperm()、ioctl()、pipe()和mknod(),涉及设备文件和管道文件,这些将在后续章节中讨论。最后一组由VFS处理的系统调用,诸如socket()、connect()和bind()属于套接字系统调用,并用于实现网络功能。与表12-1列出的系统调用对应的一些内核服务例程,我们会在本章或第十八章中陆续进行讨论。
-
文件系统相关:mount, umount, umount2, sysfs, statfs, fstatfs, fstatfs64, ustat
-
目录相关:chroot,pivot_root,chdir,fchdir,getcwd,mkdir,rmdir,getdents,getdents64,readdir,link,unlink,rename,lookup_dcookie
-
链接相关:readlink,symlink
-
文件相关:chown, fchown,lchown,chown16,fchown16,lchown16,hmod,fchmod,utime,stat,fstat,lstat,acess,oldstat,oldfstat,oldlstat,stat64,lstat64,lstat64,open,close,creat,umask,dup,dup2,fcntl, fcntl64,select,poll,truncate,ftruncate,truncate64,ftruncate64,lseek,llseek,read,write,readv,writev,sendfile,sendfile64,readahead
前面我们已经提到,VFS是应用程序和具体文件系统之间的一层。不过,在某些情况下,一个文件操作可能由VFS本身去执行,无需调用低层函数。例如,当某个进程关闭一个打开的文件时,并不需要涉及磁盘上的相应文件,因此VFS只需释放对应的文件对象。类似地,当系统调用lseek()修改一个文件指针,而这个文件指针是打开文件与进程交互所涉及的一个属性时,VFS就只需修改对应的文件对象,而不必访问磁盘上的文件,因此,无需调用具体文件系统的函数。从某种意义上说,可以把VFS看成“通用“文件系统,它在必要时依赖某种具体文件系统。
VFS的数据结构
每个VFS对象都存放在一个适当的数据结构中,其中包括对象的属性和指向对象方法表的指针。内核可以动态地修改对象的方法,因此可以为对象建立专用的行为。下面几节详细介绍VFS的对象及其内在关系。
超级块对象
超级块对象由super_block结构组成,表12-2列举了其中的字段。
| 字段 | 说明 |
|---|---|
| s_list | 指向超级块链表的指针,这个struct list_head是很熟悉的结构了,里面其实就是用于连接关系的prev和next字段。内核中的结构处理都是有讲究的(内核协议栈中也说过),内核单独使用一个简单的结构体将所有的super_block都链接起来,但是这个结构不是super_block本身,因为本身数据结构太大,效率不高,所有仅仅使用 `struct{list_head prev;list_head next;}这样的结构来将super_block中的s_list链接起来,那么遍历到s_list之后,直接读取super_block这么长的一个内存块,就可以将这个这个块读取进来 |
| s_dev | 包含该具体文件系统的块设备标识符。例如,对于 /dev/hda1,其设备标识符为 0x301 |
| s_blocksize | 文件系统中数据块大小,以字节单位 |
| s_blocksize_bits | 上面的size大小占用位数,例如512字节就是9 bits |
| s_dirt | 脏位,标识是否超级块被修改 |
| s_maxbytes | 允许的最大的文件大小(字节数) |
| struct file_system_type *s_type | 文件系统类型(也就是当前这个文件系统属于哪个类型?ext2还是fat32)要区分“文件系统”和“文件系统类型”不一样!一个文件系统类型下可以包括很多文件系统即很多的super_block,后面会说! |
| struct super_operations *s_op | 指向某个特定的具体文件系统的用于超级块操作的函数集合 |
| struct dquot_operations *dq_op | 指向某个特定的具体文件系统用于限额操作的函数集合 |
| struct quotactl_ops *s_qcop | 用于配置磁盘限额的的方法,处理来自用户空间的请求 |
| s_magic | 区别于其他文件系统的标识 |
| s_root | 指向该具体文件系统安装目录的目录项 |
| s_flags | 安装标识 |
| s_umount: | 对超级块读写时进行同步 |
| s_lock: | 锁标志位,若置该位,则其它进程不能对该超级块操作 |
| s_count: | 对超级块的使用计数 |
| s_active: | 引用计数 |
| s_dirty: | 已修改的索引节点inode形成的链表,一个文件系统中有很多的inode,有些inode节点的内容会被修改,那么会先被记录,然后写回磁盘。 |
| s_locked_inodes: | 要进行同步的索引节点形成的链表 |
| s_files: | 所有的已经打开文件的链表,这个file和实实在在的进程相关的 |
| s_bdev: | 指向文件系统被安装的块设备 |
| u: | u 联合体域包括属于具体文件系统的超级块信息 |
| s_instances: | 具体的意义后来会说的!(同一类型的文件系统通过这个子墩将所有的super_block连接起来) |
| s_dquot: | 磁盘限额相关选项 |
所有超级块对象都以双向循环链表的形式链接在一起。链表中第一个元素用super_blocks变量来表示,而超级块对象的s_list字段存放指向链表相邻元素的指针。sb_lock自旋锁保护链表免受多处理器系统上的同时访问。
s_fs_info字段指向属于具体文件系统的超级块信息;例如,假如超级块对象指的是Ext2文件系统,该字段就指向ext2_sb_info数据结构,该结构包括磁盘分配位掩码和其他与VFS的通用文件模型无关的数据。通常,为了效率起见,由s_fs_info字段所指向的数据被复制到内存。任何基于磁盘的文件系统都需要访问和更改自己的磁盘分配位图,以便分配或释放磁盘块。VFS允许这些文件系统直接对内存超级块的s_fs_info字段进行操作,而无需访问磁盘。但是,这种方法带来一个新问题:有可能VFS超级块最终不再与磁盘上相应的超级块同步。
因此,有必要引入一个s_dirt标志来表示该超级块是否是脏的——那磁盘上的数据是否必须要更新。缺乏同步还会导致产生我们熟悉的一个问题:当一台机器的电源突然断开而用户来不及正常关闭系统时,就会出现文件系统崩溃。Linux是通过周期性地将所有“脏“的超级块写回磁盘来减少该问题带来的危害。
与超级块关联的方法就是所谓的超级块操作。这些操作是由数据结构super_operations 来描述的,该结构的起始地址存放在超级块的s_op字段中。每个具体的文件系统都可以定义自己的超级块操作。当VFS需要调用其中一个操作时,比如说read_inode(),它执行下列操作:sb->s_op->read_inode(inode);这里sb存放所涉及超级块对象的地址。super_operations表的read_inode字段存放这一函数的地址,因此,这一函数被直接调用。让我们简要描述一下超级块操作,其中实现了一些高级操作,比如删除文件或安装磁盘。下面这些操作按照它们在super_operation表中出现的顺序来排列:
| 操作 | 操作 |
|---|---|
| alloc_inode | 被inode_alloc()函数调用用于分配inode内存并进行inode结构初始化。如果函数未定义,则简单的分配一个'struct inode'。通常alloc_inode用于底层文件系统分配一个包含inode结构体的更大的结构体(特定的inode结构,如:fuse_inode)。 |
| destroy_inode: | 被destroy_inode()函数调用用于释放inode相关申请的资源。只有alloc_inode定义了才需要定义destroy_inode,并且释放的也是alloc_inode里申请的相关资源。 |
| dirty_inode: | 由VFS调用标记inode dirty(元数据信息被修改过并且没有同步到磁盘或服务器)。 |
| write_inode: | 由VFS调用用于将inode同步到磁盘。第二个参数用于标识是否同步写盘 |
| drop_inode: | VFS在当inode的引用计数减为0时,调用该函数。调用者已经持有了inode->i_lock。该函数返回0,则inode将可能被丢到LRU链表里,返回1则会由调用者继续调用evict_inode和destroy_inode。如果文件系统不需要缓存inode,则该函数可以设置为NULL或者generic_delete_inode(函数里直接return 1) |
| delete_inode: | VFS删除inode时直接调用该函数。由于查看的Linux文档版本是2.6.39,所以有该函数指针,在3.10版本已经没有了detele_inode。 |
| put_super: | VFS想要释放sb时调用(如umount操作)。调用者已经持有sb的lock。 |
| sync_fs: | VFS想要把该文件系统所有的脏数据刷盘时调用。 |
| freeze_fs: | 目前只有LVM使用。用于冻结文件系统,不能进行写入操作 |
| unfreeze_fs: | 解冻文件系统,使其可以写入。 |
| statfs: | 用于获取文件系统的统计信息。 |
| remount_fs: | 用于重新挂载文件系统,调用者持有kernel lock。 |
| clear_inode: | 同样在3.10版本没有了。 |
| umount_begin: | 用于umount文件系统。 |
| show_options: | 用于/proc/mounts里显示文件系统的mount选项。 |
| quota_read和quota_write: | 用于读写文件系统的quota文件。 |
| nr_cached_objects和free_cache_objects | 用于返回可以释放的cache对象个数,以及进行实际的释放对象操作。 |
前述的方法对所有可能的文件系统类型均是可用的。但是,只有其中的一个子集应用到每个具体的文件系统;未实现的方法对应的字段置为NULL。注意,系统没有定义get_super方法来读超级块,那么,内核如何能够调用一个对象的方法而从磁盘读出该对象?我们将在描述文件系统类型的另一个对象中找到等价的get_sb方法。
索引节点对象(inode)
文件系统处理文件所需要的所有信息都放在一个名为索引节点的数据结构中。文件名可以随时更改,但是索引节点对文件是唯一的,并且随文件的存在而存在。内存中的索引节点对象由一个inode数据结构组成,其字段如表12-3所示。
struct inode {
umode_t i_mode; /* 访问权限 */
unsigned short i_opflags;
kuid_t i_uid; /* 使用者id */
kgid_t i_gid; /* 使用组id */
unsigned int i_flags; /* 文件系统标志 */
#ifdef CONFIG_FS_POSIX_ACL
struct posix_acl *i_acl; /* 访问控制列表相关 */
struct posix_acl *i_default_acl;
#endif
const struct inode_operations *i_op; /* 索引节点操作函数 */
struct super_block *i_sb; /* 所属的超级块 */
struct address_space *i_mapping; /* 地址映射 */
#ifdef CONFIG_SECURITY
void *i_security; /* 安全模块 */
#endif
/* Stat data, not accessed from path walking */
unsigned long i_ino; /* 节点号 */
/*
* Filesystems may only read i_nlink directly. They shall use the
* following functions for modification:
*
* (set|clear|inc|drop)_nlink
* inode_(inc|dec)_link_count
*/
union {
const unsigned int i_nlink;
unsigned int __i_nlink; /*硬链接数,对于目录来说,是子目录数目*/
};
dev_t i_rdev; /* 实际设备标识符 */
loff_t i_size; /* 以字节为单位的文件大小 */
struct timespec i_atime; /* 最后访问时间 */
struct timespec i_mtime; /* 最后修改时间 */
struct timespec i_ctime; /* 最后改变时间 */
spinlock_t i_lock; /* i_blocks, i_bytes, maybe i_size */
unsigned short i_bytes;
unsigned int i_blkbits;
blkcnt_t i_blocks;
#ifdef __NEED_I_SIZE_ORDERED
seqcount_t i_size_seqcount; /* 对i_size进行串行计数 */
#endif
/* Misc */
unsigned long i_state; /* 状态标志 */
struct rw_semaphore i_rwsem;
unsigned long dirtied_when; /* jiffies of first dirtying */
unsigned long dirtied_time_when;
struct hlist_node i_hash; /*散列表,用于快速查找inode */
struct list_head i_io_list; /* backing dev IO list */
#ifdef CONFIG_CGROUP_WRITEBACK
struct bdi_writeback *i_wb; /* the associated cgroup wb */
/* foreign inode detection, see wbc_detach_inode() */
int i_wb_frn_winner;
u16 i_wb_frn_avg_time;
u16 i_wb_frn_history;
#endif
struct list_head i_lru; /* inode LRU list */
struct list_head i_sb_list; /* 超级块链表 */
struct list_head i_wb_list; /* backing dev writeback list */
union {
struct hlist_head i_dentry; /* 目录项链表 */
struct rcu_head i_rcu;
};
u64 i_version;
atomic_t i_count; /* 引用计数 */
atomic_t i_dio_count;
atomic_t i_writecount; /* 写者计数 */
#ifdef CONFIG_IMA
atomic_t i_readcount; /* struct files open RO */
#endif
const struct file_operations *i_fop; /* 缺省的索引节点操作 former ->i_op->default_file_ops */
struct file_lock_context *i_flctx;
struct address_space i_data; /* 设备地址映射 */
struct list_head i_devices; /* 块设备链表 */
union {
struct pipe_inode_info *i_pipe; /* 管道信息 */
struct block_device *i_bdev; /* 块设备信息 */
struct cdev *i_cdev; /* 字符设备信息 */
char *i_link;
unsigned i_dir_seq;
};
__u32 i_generation;
#ifdef CONFIG_FSNOTIFY
__u32 i_fsnotify_mask; /* all events this inode cares about */
struct hlist_head i_fsnotify_marks;
#endif
#if IS_ENABLED(CONFIG_FS_ENCRYPTION)
struct fscrypt_info *i_crypt_info;
#endif
void *i_private; /* fs or device private pointer */
};
| 字段 | 说明 |
|---|---|
| i_hash: | 指向hash链表指针,用于inode的hash表 |
| i_list: | 指向索引节点链表指针,用于inode之间的连接 |
| i_dentry: | 指向目录项链表指针,注意一个inodes可以对应多个dentry,因为一个实际的文件可能被链接到其他的文件,那么就会有另一个dentry,这个链表就是将所有的与本inode有关的dentry都连在一起。 |
| i_dirty_buffers和i_dirty_data_buffers: | 脏数据缓冲区 |
| i_ino: | 索引节点号,每个inode都是唯一的 |
| i_count: | 引用计数 |
| i_dev: | 如果inode代表设备,那么就是设备号 |
| i_mode: | 文件的类型和访问权限 |
| i_nlink: | 与该节点建立链接的文件数(硬链接数) |
| i_uid: | 文件拥有者标号 |
| i_gid: | 文件所在组标号 |
| i_rdev: | 实际的设备标识(注意i_dev和i_rdev之间区别:如果是普通的文件,例如磁盘文件,存储在某块磁盘上,那么i_dev代表的就是保存这个文件的磁盘号,但是如果此处是特殊文件例如就是磁盘本身(因为所有的设备也看做文件处理),那么i_rdev就代表这个磁盘实际的磁盘号。) |
| i_size: | inode所代表的的文件的大小,以字节为单位 |
| i_atime: | 文件最后一次访问时间 |
| i_mtime: | 文件最后一次修改时间 |
| i_ctime: | inode最后一次修改时间 |
| i_blkbits: | 单位块大小,字节 |
| i_blksize: | 块大小,bit单位 |
| i_blocks: | 文件所占块数 |
| i_version: | 版本号 |
| i_bytes: | 文件中最后一个块的字节数 |
| i_sem: | 指向用于同步操作的信号量结构 |
| i_alloc_sem: | 保护inode上的IO操作不被另一个打断 |
| i_zombie: | 僵尸inode信号量 |
| i_op: | 索引节点操作 |
| i_fop: | 文件操作 |
| i_sb: | inode所属文件系统的超级块指针 |
| i_wait: | 指向索引节点等待队列指针 |
| i_flock: | 文件锁链表(注意:address_space不是代表某个地址空间,而是用于描述页高速缓存中的页面的。一个文件对应一个address_space,一个address_space和一个偏移量可以确定一个页高速缓存中的页面。) |
| i_mapping: | 表示向谁请求页面 |
| i_data: | 表示被inode读写的页面 |
| i_dquot: | inode的磁盘限额(关于磁盘限额:在多任务环境下,对于每个用户的磁盘使用限制是必须的,起到一个公平性作用。磁盘限额分为两种:block限额和inode限额,而且对于一个特文件系统来说,使用的限额机制都是一样的,所以限额的操作函数放在super_block中就OK!) |
| i_devices: | 设备链表。共用同一个驱动程序的设备形成的链表 |
| i_pipe: | 指向管道文件(如果文件是管道文件时使用) |
| i_bdev: | 指向块设备文件指针(如果文件是块设备文件时使用) |
| i_cdev: | 指向字符设备文件指针(如果文件是字符设备时使用) |
| i_dnotify_mask: | 目录通知事件掩码 |
| i_dnotify: | 用于目录通知 |
| i_state: | 索引节点的状态标识:I_NEW,I_LOCK,I_FREEING |
| i_flags: | 索引节点的安装标识 |
| i_sock: | 如果是套接字文件则为True |
| i_write_count: | 记录多少进程以刻写模式打开此文件 |
| i_attr_flags: | 文件创建标识 |
| i_generation: | 保留 |
| u: | 具体的inode信息 |
每个索引节点对象都会复制磁盘索引节点包含的一些数据,比如分配给文件的磁盘块数。如果i_state字段的值等于I_DIRTY_SYNC、I_DIRTY_DATASYNC或I_DIRTY_PAGES,该索引节点就是“脏“的,也就是说,对应的磁盘索引节点必须被更新。I_DIRTY宏可以用来立即检查这三个标志的值。i_state字段的其他值有I_LOCK(涉及的索引节点对象处于I/O传送中)、I_FREEING(索引节点对象正在被释放)、I_CLEAR(索引节点对象的内容不再有意义)以及I_NEW(索引节点对象已经分配但还没有用从磁盘索引节点读取来的数据填充)。
每个索引节点对象总是出现在下列双向循环链表的某个链表中(所有情况下,指向相邻元素的指针存放在i_list字段中):
-
有效未使用的索引节点链表,典型的如那些镜像有效的磁盘索引节点,且当前未被任何进程使用。这些索引节点不为脏,且它们的i_count字段置为0。链表中的首元素和尾元素是由变量inode_unused的next字段和prev字段分别指向的。这个链表用作磁盘高速缓存。
-
正在使用的索引节点链表,也就是那些镜像有效的磁盘索引节点,且当前被某些进程使用。这些索引节点不为脏,但它们的i_count字段为正数。链表中的首元素和尾元素是由变量inode_in_use引用的。
-
脏索引节点的链表。链表中的首元素和尾元素是由相应超级块对象的s_dirty字段引用的。这些链表都是通过适当的索引节点对象的i_list字段链接在一起的。
此外,每个索引节点对象也包含在每文件系统(per-filesystem)的双向循环链表中,链表的头存放在超级块对象的s_inodes字段中;索引节点对象的i_sb_list字段存放了指向链表相邻元素的指针。
最后,索引节点对象也存放在一个称为inode_hashtable的散列表中。散列表加快了对索引节点对象的搜索,前提是系统内核要知道索引节点号及文件所在文件系统对应的超级块对象的地址。由于散列技术可能引发冲突,所以索引节点对象包含一个i_hash字段,该字段中包含向前和向后的两个指针,分别指向散列到同一地址的前一个索引节点和后一个索引节点;该字段因此创建了由这些索引节点组成的一个双向链表。
与索引节点对象关联的方法也叫索引节点操作。它们由inode_operations结构来描述,该结构的地址存放在i_op字段中。以下是索引节点的操作,以它们在inode_operations表中出现的次序来排列:
| 操作 | 说明 |
|---|---|
| create(dir, dentry, mode, nameidata) | 在某一目录下,为与目录项对象相关的普通文件创建一个新的磁盘索引节点。 |
| lookup(dir, dentry, nameidata) | 为包含在一个目录项对象中的文件名对应的索引节点查找目录。 |
| link(old_dentry, dir, new_dentry) | 创建一个新的名为new_dentry的硬链接,它指向dir目录下名为old_dentry的文件。 |
| unlink(dir, dentry) | 从一个目录中删除目录项对象所指定文件的硬链接。 |
| symlink(dir, dentry, symname) | 在某个目录下,为与目录项对象相关的符号链接创建一个新的索引节点。 |
| mkdir(dir, dentry, mode) | 在某个目录下,为与目录项对象相关的目录创建一个新的索引节点。 |
| rmdir(dir, dentry) | 从一个目录删除子目录,子目录的名称包含在目录项对象中。 |
| mknod(dir, dentry, mode, rdev) | 在某个目录中位于目录项对象相关的特定文件创建一个新的磁盘索引节点!其中参数mode和rdev分别表示文件的类型和设备的 |
| rename(old_dir, old_dentry, new_dir, new_dentry) | 将old_dir目录下由old_entry标识的文件移到new_dir目录下。新文件名包含在new_dentry指向的目录项对象中。 |
| readlink(dentry, buffer, buflen) | 将目录项所指定的符号链接中对应的文件路径名拷贝到buffer所指定的用户态内存区。 |
| follow_link(inode, nameidata) | 解析索引节点对象所指定的符号链接;如果该符号链接是一个相对路径名,则从第二个参数所指定的目录开始进行查找。 |
| put_link(dentry, nameidata) | 释放由 follow_link方法分配的用于解析符号链接的所有临时数据结构。 |
| truncate(inode) | 修改与索引节点相关的文件长度。在调用该方法之前,必须将inode对象的i_size字段设置为需要的新长度值。 |
| permission(inode, mask, nameidata) | 检查是否允许对与索引节点所指的文件进行指定模式的访问。 |
| setattr(dentry, iattr) | 在触及索引节点属性后通知一个“修改事件“。 |
| getattr(mnt, dentry, kstat) | 由一些文件系统用于读取索引节点属性。 |
| setxattr(dentry, name, value, size, flags) | 为索引节点设置“扩展属性“(扩展属性存放在任何索引节点之外的磁盘块中)。 |
| getxattr(dentry, name, buffer, size) | 获取索引节点的扩展属性。 |
| listxattr(dentry, buffer, size) | 获取扩展属性名称的整个链表。 |
| removexattr(dentry, name) | 删除索引节点的扩展属性。上述列举的方法对所有可能的索引节点和文件系统类型都是可用的。不过,只有其中的一个子集应用到某一特定的索引节点和文件系统;未实现的方法对应的字段被置为NULL。 |
文件对象
文件对象描述进程怎样与一个打开的文件进行交互。文件对象是在文件被打开时创建的,由一个file结构组成,其中包含的字段如表12-4所示。注意,文件对象在磁盘上没有对应的映像,因此file结构中没有设置“脏“字段来表示文件对象是否已被修改。
| 字段 | 说明 |
|---|---|
| f_list | 用于通用文件对象链表的指针 |
| f_dentry | 与文件相关的目录项对象 |
| f_vfsmnt | 含有该文件的已安装文件系统 |
| f_op | 指向文件操作表的指针 |
| f_count | 文件对象的引用计数器 |
| f_flags | 当打开文件时所指定的标志 |
| f_mode | 进程的访问模式 |
| f_error | 网络写操作的错误码 |
| f_pos | 当前的文件位移量(文件指针) |
| f_version | 版本号,每次使用后自动递增 |
| f_security | 指向文件对象的安全结构的指针 |
| private_data | 指向特定文件系统或设备驱动程序所需的数据 的指针 |
| f_ep_links | 文件的事件轮询等待者链表的头 |
| f_ep_lock | 保护f_ep_links链表的自旋锁 |
| f_mapping | 指向文件地址空间对象的指针 |
存放在文件对象中的主要信息是文件指针,即文件中当前的位置,下一个操作将在该位置发生。由于几个进程可能同时访问同一文件,因此文件指针必须存放在文件对象而不是索引节点对象中。
文件对象通过一个名为filp的slab高速缓存分配,filp描述符地址存放在filp_cachep 变量中。由于分配的文件对象数目是有限的,因此files_stat变量在其max_files字段中指定了可分配文件对象的最大数目,也就是系统可同时访问的最大文件数(注4)。
在使用“文件对象包含在由具体文件系统的超级块所确立的几个链表中。每个超级块对象把文件对象链表的头存放在s_files字段中;因此,属于不同文件系统的文件对象就包含在不同的链表中。链表中分别指向前一个元素和后一个元素的指针都存放在文件对象的f_list字段中。files_lock自旋锁保护超级块的s_files链表免受多处理器系统上的同时访问。
文件对象的f_count字段是一个引用计数器:它记录使用文件对象的进程数(记住,以CLONE_FILES标志创建的轻量级进程共享打开文件表,因此它们可以使用相同的文件对象)。当内核本身使用该文件对象时也要增加计数器的值——例如,把对象插入链表中或发出dup()系统调用时。
当VFS代表进程必须打开一个文件时,它调用get_empty_filp()函数来分配一个新的文件对象。该函数调用kmem_cache_alloc()从filp高速缓存中获得一个空闲的文件对象,然后初始化这个对象的字段,如下所示:
// 重置 memset(f, 0, sizeof(*f)); // 初始化 INIT_LIST_HEAD(&f->f_ep_links); spin_lock_init(&f->f_ep_lock); atomic_set(&f->f_count, 1); f->f_uid = current->fsuid; f->f_gid = current->fsgid; f->f_owmer.lock = RW_LOCK_UNLOCKED; INIT_LIST_HEAD(&f->f_list〉; f->f_maxcount = INT_MAX;
正如在“通用文件模型“一节中讨论过的那样,每个文件系统都有其自己的文件操作集合,执行诸如读写文件这样的操作。当内核将一个索引节点从磁盘装入内存时,就会把指向这些文件操作的指针存放在file_operations结构中,而该结构的地址存放在该索引节点对象的i_fop字段中。
当进程打开这个文件时,VFS就用存放在索引节点中的这个地址初始化新文件对象的f_op字段,使得对文件操作的后续调用能够使用这些函数。如果需要,VFS随后也可以通过在f_op字段存放一个新值而修改文件操作的集合。下面的列表描述了文件的操作,以它们在file_operations表中出现的次序来排列:
-
loff_t (*llseek) (struct file * filp , loff_t p, int orig); (指针参数filp为进行读取信息的目标文件结构体指针;参数 p 为文件定位的目标偏移量;参数orig为对文件定位的起始地址,这个值可以为文件开头(SEEK_SET,0,当前位置(SEEK_CUR,1),文件末尾(SEEK_END,2))
llseek 方法用作改变文件中的当前读/写位置, 并且新位置作为(正的)返回值.
loff_t 参数是一个"long offset", 并且就算在 32位平台上也至少 64 位宽. 错误由一个负返回值指示;如果这个函数指针是 NULL, seek 调用会以潜在地无法预知的方式修改 file 结构中的位置计数器( 在"file 结构" 一节中描述).
-
ssize_t (*read) (struct file * filp, char __user * buffer, size_t size , loff_t * p); (指针参数 filp 为进行读取信息的目标文件,指针参数buffer 为对应放置信息的缓冲区(即用户空间内存地址),参数size为要读取的信息长度,参数 p 为读的位置相对于文件开头的偏移,在读取信息后,这个指针一般都会移动,移动的值为要读取信息的长度值)
这个函数用来从设备中获取数据。在这个位置的一个空指针导致 read 系统调用以 -EINVAL("Invalid argument") 失败。一个非负返回值代表了成功读取的字节数( 返回值是一个 "signed size" 类型, 常常是目标平台本地的整数类型).
-
ssize_t (*aio_read)(struct kiocb * , char __user * buffer, size_t size , loff_t p); 可以看出,这个函数的第一、三个参数和本结构体中的read()函数的第一、三个参数是不同 的,异步读写的第三个参数直接传递值,而同步读写的第三个参数传递的是指针,因为AIO从来不需要改变文件的位置。异步读写的第一个参数为指向kiocb结构体的指针,而同步读写的第一参数为指向file结构体的指针,每一个I/O请求都对应一个kiocb结构体);初始化一个异步读 -- 可能在函数返回前不结束的读操作.如果这个方法是 NULL, 所有的操作会由 read 代替进行(同步地
-
ssize_t (*write) (struct file * filp, const char __user * buffer, size_t count, loff_t * ppos); (参数filp为目标文件结构体指针,buffer为要写入文件的信息缓冲区,count为要写入信息的长度,ppos为当前的偏移位置,这个值通常是用来判断写文件是否越界)
发送数据给设备.。如果 NULL, -EINVAL 返回给调用 write 系统调用的程序. 如果非负, 返回值代表成功写的字节数。 (注:这个操作和上面的对文件进行读的操作均为阻塞操作)
-
ssize_t (*aio_write)(struct kiocb *, const char __user * buffer, size_t count, loff_t * ppos); 初始化设备上的一个异步写.参数类型同aio_read()函数;
-
int (*readdir) (struct file * filp, void *, filldir_t); 对于设备文件这个成员应当为 NULL; 它用来读取目录, 并且仅对文件系统有用.
-
unsigned int (*poll) (struct file *, struct poll_table_struct *); (这是一个设备驱动中的轮询函数,第一个参数为file结构指针,第二个为轮询表指针)
这个函数返回设备资源的可获取状态,即POLLIN,POLLOUT,POLLPRI,POLLERR,POLLNVAL等宏的位“或”结果。每个宏都表明设备的一种状态,如:POLLIN(定义为0x0001)意味着设备可以无阻塞的读,POLLOUT(定义为0x0004)意味着设备可以无阻塞的写。
(poll 方法是 3 个系统调用的后端: poll, epoll, 和 select, 都用作查询对一个或多个文件描述符的读或写是否会阻塞.poll 方法应当返回一个位掩码指示是否非阻塞的读或写是可能的, 并且, 可能地, 提供给内核信息用来使调用进程睡眠直到 I/O 变为可能. 如果一个驱动的 poll 方法为 NULL, 设备假定为不阻塞地可读可写.
(这里通常将设备看作一个文件进行相关的操作,而轮询操作的取值直接关系到设备的响应情况,可以是阻塞操作结果,同时也可以是非阻塞操作结果)
-
int (*ioctl) (struct inode *inode, struct file *filp, unsigned int cmd, unsigned long arg); (inode 和 filp 指针是对应应用程序传递的文件描述符 fd 的值, 和传递给 open 方法的相同参数.cmd 参数从用户那里不改变地传下来, 并且可选的参数 arg 参数以一个 unsigned long 的形式传递, 不管它是否由用户给定为一个整数或一个指针.如果调用程序不传递第 3 个参数, 被驱动操作收到的 arg 值是无定义的.因为类型检查在这个额外参数上被关闭, 编译器不能警告你如果一个无效的参数被传递给 ioctl, 并且任何关联的错误将难以查找.)
ioctl 系统调用提供了发出设备特定命令的方法(例如格式化软盘的一个磁道, 这不是读也不是写). 另外, 几个 ioctl 命令被内核识别而不必引用 fops 表.如果设备不提供 ioctl 方法, 对于任何未事先定义的请求(-ENOTTY, "设备无这样的 ioctl"), 系统调用返回一个错误.
-
int (*mmap) (struct file *, struct vm_area_struct *); mmap 用来请求将设备内存映射到进程的地址空间。 如果这个方法是 NULL, mmap 系统调用返回 -ENODEV.
-
int (*open) (struct inode * inode , struct file * filp ) ;
(inode 为文件节点,这个节点只有一个,无论用户打开多少个文件,都只是对应着一个inode结构;但是filp就不同,只要打开一个文件,就对应着一个file结构体,file结构体通常用来追踪文件在运行时的状态信息)
尽管这常常是对设备文件进行的第一个操作, 不要求驱动声明一个对应的方法. 如果这个项是 NULL, 设备打开一直成功, 但是你的驱动不会得到通知.与open()函数对应的是release()函数。
-
int (*flush) (struct file *);
flush 操作在进程关闭它的设备文件描述符的拷贝时调用
它应当执行(并且等待)设备的任何未完成的操作.这个必须不要和用户查询请求的 fsync 操作混淆了. 当前, flush 在很少驱动中使用;SCSI 磁带驱动使用它, 例如, 为确保所有写的数据在设备关闭前写到磁带上. 如果 flush 为 NULL, 内核简单地忽略用户应用程序的请求.
-
int (*release) (struct inode *, struct file *);
release ()函数当最后一个打开设备的用户进程执行close()系统调用的时候,内核将调用驱动程序release()函数:
-
void release(struct inode inode,struct file *file)
release函数的主要任务是清理未结束的输入输出操作,释放资源,用户自定义排他标志的复位等。在文件结构被释放时引用这个操作. 如同 open, release 可以为 NULL.
-
int(*synch)(struct file *,struct dentry *,int datasync); 刷新待处理的数据,允许进程把所有的脏缓冲区刷新到磁盘。
-
int (*aio_fsync)(struct kiocb *, int); 这是 fsync 方法的异步版本.所谓的fsync方法是一个系统调用函数。系统调用fsync把文件所指定的文件的所有脏缓冲区写到磁盘中(如果需要,还包括存有索引节点的缓冲区)。相应的服务例程获得文件对象的地址,并随后调用fsync方法。通常这个方法以调用函数__writeback_single_inode()结束,这个函数把与被选中的索引节点相关的脏页和索引节点本身都写回磁盘
-
int (*fasync) (int, struct file *, int); 这个函数是系统支持异步通知的设备驱动,
-
int (*lock) (struct file *, int, struct file_lock *); lock 方法用来实现文件加锁; 加锁对常规文件是必不可少的特性, 但是设备驱动几乎从不实现它.
-
ssize_t (*readv) (struct file *, const struct iovec *, unsigned long, loff_t \*); ssize_t (*writev) (struct file *, const struct iovec *, unsigned long, loff_t *);
这些方法实现发散/汇聚读和写操作. 应用程序偶尔需要做一个包含多个内存区的单个读或写操作;这些系统调用允许它们这样做而不必对数据进行额外拷贝. 如果这些函数指针为 NULL, read 和 write 方法被调用( 可能多于一次 ).
-
ssize_t (*sendfile)(struct file *, loff_t *, size_t, read_actor_t, void *); 这个方法实现 sendfile 系统调用的读, 使用最少的拷贝从一个文件描述符搬移数据到另一个.例如, 它被一个需要发送文件内容到一个网络连接的 web 服务器使用. 设备驱动常常使 sendfile 为 NULL.
-
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int); sendpage 是 sendfile 的另一半; 它由内核调用来发送数据, 一次一页, 到对应的文件. 设备驱动实际上不实现 sendpage.
-
unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long); 这个方法的目的是在进程的地址空间找一个合适的位置来映射在底层设备上的内存段中。这个任务通常由内存管理代码进行; 这个方法存在为了使驱动能强制特殊设备可能有的任何的对齐请求. 大部分驱动可以置这个方法为 NULL.[10]
-
int (*check_flags)(int) 这个方法允许模块检查传递给 fnctl(F_SETFL...) 调用的标志.
-
int (*dir_notify)(struct file *, unsigned long); 这个方法在应用程序使用 fcntl 来请求目录改变通知时调用. 只对文件系统有用; 驱动不需要实现 dir_notify.
以上描述的方法对所有可能的文件类型都是可用的。不过,对于一个具体的文件类型,只使用其中的一个子集;那些未实现的方法对应的字段被置为NULL。
Linux字符设备驱动file_operations - GreenHand# - 博客园 (cnblogs.com)
目录项对象
在“通用文件模型“一节中我们曾提到,VFS把每个目录看作由若干子目录和文件组成的一个普通文件。然而,一旦目录项被读入内存,VFS就把它转换成基于dentry结构的一个目录项对象,该结构的字段如表12-5所示。对于进程查找的路径名中的每个分量,内核都为其创建一个目录项对象;目录项对象将每个分量与其对应的索引节点相联系。例如,在查找路径名/tmp/test时,内核为根目录“/“创建一个目录项对象,为根目录下的tmp项创建一个第二级目录项对象,为/tmp目录下的test项创建一个第三级目录项对象。
请注意,目录项对象在磁盘上并没有对应的映像,因此在dentry结构中不包含指出该对象已被修改的字段。目录项对象存放在名为dentry_cache的slab分配器高速缓存中。因此,目录项对象的创建和删除是通过调用kmem_cache_alloc()和kmem_cache_free()实现的。
| 字段 | 说明 |
|---|---|
| d_revalidate: | VFS用于检查在dcache里找到的dentry是否有效。通常设置为NULL,则只要在dcache找到即认为是有效的。但对网络文件系统如NFS来说,dentry可能在一段时间之后就会失效,因此需要实现该函数用于检查是否有效。如果有效,函数需要返回一个正数。 |
| d_weak_revalidate: | 用于检查'jumped'的dentry,即那些不是通过lookup获取的dentry,如'', '.'或者'..'。这种场景只需要检查dentry对应inode是否OK即可。该函数不会在rcu-walk模式下调用,所以可以放心的使用inode。 |
| d_hash: | 用于VFS将dentry放入HASH列表。并不清楚HASH表用来做啥,通常不需要设置它,使用VFS默认的即可。 |
| d_compare: | 用于比较dentry name和指定的name。该函数必须是可重入的,即每次的返回结果一样。 |
| d_revalidate | 可能在rcu-walk模式(flags & LOOKUP_RCU)下被调用。此时该函数里不能阻塞也不能写入数据到dentry,并且d_parent和d_inode不能使用,因为他们可能瞬间就可能被修改。如果在rcu-walk模式遇到困难,则返回-ECHILD,将在ref-walk模式下重新调用。 |
| d_release: | 用于释放dentry资源。 |
| d_delete: | 用于引用计数递减为0时调用,返回1则dcache立即删除dentry,返回0则继续缓存该dentry。默认为NULL,则总是将dentry进行缓存。该函数必须是可重入的,即每次的返回结果一样。 |
| d_iput: | 用于释放dentry对应inode引用计数。该函数在释放dentry之前调用。如果为NULL,则VFS默认调用iput()。 |
| d_dname: | 用于生成dentry的pathname,主要是一些伪文件系统(sockfs, pipefs等)用于延迟生成pathname。一般文件系统不实现该函数,因为其dentry存在于dcache的hash表里(通过pathname做hash),所以并不希望pathname变化。 |
| d_automount: | 可选函数,用于穿越到一个自动挂载的dentry。它会创建一个新的vfsmount记录,并将其返回,成功后调用者将根据vfsmount去尝试mount它到挂载点。 |
| d_manage: | 可选函数,用于管理从dentry进行transition。 |
每个目录项对象可以处于以下四种状态之一:
-
空闲状态(free) 处于该状态的目录项对象不包括有效的信息,且还没有被VFS使用。对应的内存区由slab分配器进行处理。
-
未使用状态(unused) 处于该状态的目录项对象当前还没有被内核使用。该对象的引用计数器d_count的值为0,但其d_inode字段仍然指向关联的索引节点。该目录项对象包含有效的信息,但为了在必要时回收内存,它的内容可能被丢弃。
-
正在使用状态(in use) 处于该状态的目录项对象当前正在被内核使用。该对象的引用计数器d_count的值为正数,其d_inode字段指向关联的索引节点对象。该目录项对象包含有效的信息,并且不能被丢弃。
-
负状态(negative) 与目录项关联的索引节点不复存在,那是因为相应的磁盘索引节点已被删除,或者因为目录项对象是通过解析一个不存在文件的路径名创建的。目录项对象的d_inode字段被置为NULL,但该对象仍然被保存在目录项高速缓存中,以便后续对同一文件目录名的查找操作能够快速完成。术语“负状态“容易使人误解,因为根本不涉及任何负值。
与目录项对象关联的方法称为目录项操作。这些方法由dentry_operations结构加以描述,该结构的地址存放在目录项对象的d_op字段中。尽管一些文件系统定义了它们自己的目录项方法,但是这些字段通常为NULL,而VFS使用缺省函数代替这些方法。以下按照其在dentry_operations表中出现的顺序来列举一些方法。
| 操作 | 说明 |
|---|---|
| d_revalidate(dentry,nameidata) | 在把目录项对象转换为一个文件路径名之前,判定该目录项对象是否仍然有效。缺 省的VFS函数什么也不做,而网络文件系统可以指定自已的函数。 |
| d_hash(dentry, name) | 生成一个散列值,这是用于目录项散列表的、特定于具体文件系统的散列函数。参 数dentry标识包含路径分量的自录。参数name指向一个结构,该结构包含要查找 的路径名分量以及由散列函数生成的散列值。 |
| d_compare(dir,namel,name2) | 比较两个文件名。name1应该属于dir所指的目录。缺省的VFS函数是常用的字 符串匹配函数。不过,每个文件系统可用自已的方式实现这一方法。例如,MS-DOS 文件系统不区分大写和小写字母。 |
| d_delete(dentry) | 当对自录项对象的最后一个引用被删除(dcount变为“0“)时,调用该方法。缺省的VFS函数什么也不做。 |
| d_release(dentry) | 当要释放一个目录项对象时(放人slab分配器),调用该方法。缺省的VFS函数什 么也不做。 |
| d_iput(dentry,ino) | 当一个自录项对象变为“负“状态(即丢弃它的索引节点)时,调用该方法。缺省 的VFS函数调用iput()释放索引节点对象。 |
目录项高速缓存
由于从磁盘读入一个目录项并构造相应的目录项对象需要花费大量的时间,所以,在完成对目录项对象的操作后,可能后面还要使用它,因此仍在内存中保留它有重要的意义。例如,我们经常需要编辑文件,随后编译它,或者编辑并打印它,或者复制它并编辑这个拷贝,在诸如此类的情况中,同一个文件需要被反复访问。为了最大限度地提高处理这些目录项对象的效率,Linux使用目录项高速缓存,它由两种类型的数据结构组成:
一个处于正在使用未使用或负状态的目录项对象的集合
一个散列表,其中能够快速获取与给定的文件和目录名对应的目录项对象!同样如果访问的对象不在目录项高速缓存中,该散列函数会返回一个空值
目录项高速缓存的作用还相当于索引节点高速缓存(inode cache)的控制器。在内核内存中,并不丢弃与未用目录项相关的索引节点,这是由于目录项高速缓存仍在使用它们。因此,这些索引节点对象保存在RAM中,并能够借助相应的目录项快速引用它们。
所有“未使用“目录项对象都存放在一个“最近最少使用(Least Recently used,LRU)“的双向链表中,该链表按照插入的时间排序。换句话说,最后释放的目录项对象放在链表的首部,所以最近最少使用的目录项对象总是靠近链表的尾部。一旦目录项高速缓存的空间开始变小,内核就从链表的尾部删除元素,使得最近最常使用的对象得以保留。
LRU链表的首元素和尾元素的地址存放在list_head类型的dentry_unused变量的next字段和prev字段中。目录项对象的d_1ru字段包含指向链表中相邻目录项的指针。
每个“正在使用“的目录项对象都被插入一个双向链表中,该链表由相应索引节点对象的i_dentry字段所指向(由于每个索引节点可能与若干硬链接关联,所以需要一个链表)。目录项对象的d_alias字段存放链表中相邻元素的地址。这两个字段的类型都是struct list_head。
当指向相应文件的最后一个硬链接被删除后,一个“正在使用“的目录项对象可能变成“负“状态。在这种情况下,该目录项对象被移到“未使用“目录项对象组成的LRU链表中。每当内核缩减目录项高速缓存时,“负“状态目录项对象就朝着LRU链表的尾部移动,这样一来,这些对象就逐渐被释放。
散列表是由dentry_hashtable数组实现的。数组中的每个元素是一个指向链表的指针,这种链表就是把具有相同散列表值的目录项进行散列而形成的。该数组的长度取决于系统已安装RAM的数量;缺省值是每兆字节RAM包含256个元素。目录项对象的d_hash 字段包含指向具有相同散列值的链表中的相邻元素。散列函数产生的值是由目录的目录项对象及文件名计算出来的。
dcache_lock自旋锁保护目录项高速缓存数据结构免受多处理器系统上的同时访问。d_lookup()函数在散列表中查找给定的父目录项对象和文件名;为了避免发生竞争,使用顺序锁(seqlock)。__d_lookup()函数与之类似,不过它假定不会发生竞争,因此不使用顺序锁。
与进程相关的文件
每个进程都有它自己当前的工作目录和它自己的根目录。这仅仅是内核用来表示进程与文件系统相互作用所必须维护的数据中的两个例子。类型为fs_struc的整个数据结构就用于此目的(参见表12-6),且每个进程描述符的fs字段就指向进程的fs_struc结构。
| 字段 | 说明 |
|---|---|
| count: | 共享这个表的进程个数 |
| lock: | 用于表中字段的读/写自旋锁 |
| umask: | 当打开文件设置文件权限时所使用的位掩码 |
| root: | 根目录的目录项 |
| pwd: | 当前工作目录的目录项 |
| altroot: | 模拟根目录的目录项(在80x86结构上始终为NULL) |
| rootmnt: | 根目录所安装的文件系统对象 |
| pwdmnt: | 当前工作目录所安装的文件系统对象 |
| altrootmnt: | 模拟根目录所安装的文件系统对象(在80x86结构上始终为NULL) |
第二个表表示进程当前打开的文件表的地址存放于进程描述符的files字段。该表的类型为files_struct结构,它的各个字段如表12-7所示。
| 字段 | 说明 |
|---|---|
| count | 共享该表的进程数目 |
| file_lock | 于表中字段的读/写自旋锁 |
| max_fds | 用文件对象的当前最大数目 |
| max_fdset | 文件描述符的当前最大数目 |
| next_fd | 所分配的最大文件描述符加1 |
| close_on_exec | 指向执行exec()时需要关闭的文件描述符的 指针 |
| fd | 指向文件对象指针数组的指针 |
| open_fds | 指向打开文件描述符的指针 |
| close_on_exec_init | 执行exec()时需要关闭的文件描述符的初始集合 |
| open_fds_init | 文件描述符的初始集合 |
| fd_array | 文件对象指针的初始化数组 |
fd字段指向文件对象的指针数组。该数组的长度存放在max_fds字段中。通常,fd字段指向files_struct结构的fd_array字段,该字段包括32个文件对象指针。如果进程打开的文件数目多于32,内核就分配一个新的、更大的文件指针数组,并将其地址存放在fd字段中,内核同时也更新max_fds字段的值。
对于在fd数组中有元素的每个文件来说,数组的索引就是文件描述符(file descriptor)。通常,数组的第一个元素(索引0)是进程的标准输入文件,数组的第二个元素(索引1)是进程的标准输出文件,数组的第三个元素(索引2)是进程的标准错误文件。
Unix进程将文件描述符作为主文件标识符。请注意,借助于dup()、dup2()和fcntl()系统调用,两个文件描述符可以指向同一个打开的文件,也就是说,数组的两个元素可能指向同一个文件对象。当用户使用shell结构(如2>&1)将标准错误文件重定向到标准输出文件上时,用户总能看到这一点。
进程不能使用多于NR_OPEN(通常为1048576)个文件描述符。内核也在进程描述符的signal->rlim[RLIMIT_NOFILE]结构上强制限制文件描述符的最大数;这个值通常为1024,但是如果进程具有超级用户特权,就可以增大这个值。
open_fds字段最初包含open_fds_init字段的地址,open_fds_init字段表示当前已打开文件的文件描述符的位图。max_fdset字段存放位图中的位数。由于fd_set数据结构有1024位,所以通常不需要扩大位图的大小。但,如果确有必要的话,内核仍能动态增加位图的大小,这非常类似于文件对象的数组的情形。
当内核开始使用一个文件对象时,内核提供fget()函数以供调用。函数接收fd作为参数,返回在current->files->fd[fd]中的地址,即对应文件对象的地址,如果没有任何文件与fd对应,则返回NULL。在第一种情况下,fget()使文件对象引用计数器f_count的值增1。
当内核控制路径完成对文件对象的使用时,调用内核提供的fput()函数。该函数将文件对象的地址作为参数,并减少文件对象引用计数器f_count的值。另外,如果这个字段变为0,该函数就调用文件操作的release方法(如果已定义):
-
减少索引节点对象的i_write count字段的值(如果该文件是可写的)。
-
将文件对象从超级块链表中移走。
-
释放文件对象给slab分配器。
-
最后减少相关的文件系统描述符的目录项对象的引用计数器的值。
fget_light()和fget_light()函数是fget()和fput()的快速版本:内核要使用它们,前提是能够安全地假设当前进程已经拥有文件对象,即进程先前已经增加了文件对象引用计数器的值。例如,它们由接收一个文件描述符作为参数的系统调用服务例程使用,这是由于先前的open()系统调用已经增加了文件对象引用计数器的值。
文件系统类型
Linux内核支持很多不同的文件系统类型。在下面的内容中,我们介绍一些特殊的文件系统类型,它们在Linux内核的内部设计中具有非常重要的作用。接下来,我们将讨论文件系统注册——也就是通常在系统初始化期间并且在使用文件系统类型之前必须执行的基本操作。一旦文件系统被注册,其特定的函数对内核就是可用的,因此文件系统类型可以安装在系统的目录树上。
特殊文件系统
当网络和磁盘文件系统能够使用户处理存放在内核之外的信息时,特殊文件系统可以为系统程序员和管理员提供一种容易的方式来操作内核的数据结构并实现操作系统的特殊特征。表12-8列出了Linux中所用的最常用的特殊文件系统;对于其中的每个文件系统,表中给出了它的安装点和简短描述。注意,有几个文件系统没有固定的安装点(表中的关键词“任意”)。这些文件系统可以由用户自由地安装和使用。一些特殊文件系统根本没有安装点(表中的“无”),它们不是用于与用户交互,但是内核可以用它们来很容易地重新使用VFS层的某些代码.
特殊文件系统不限于物理块设备,然而,内核给每个安装的特殊文件系统分配一个虚拟的块设备,让其主设备号为0而次设备号具有任意值(每个特殊文件系统有不同的值)。set_anon_super()函数用于初始化特殊文件系统的超级块;函数获得一个未使用的次设备号dev,然后用主设备号0和次设备号dev设置新超级块的s_dev字段。
而另一个kill_anon_super()函数移走特殊文件系统的超级块。unnamed_dev_idr变量包含指向一个辅助结构(记录当前在用的次设备号)的指针。尽管有些内核设计者不喜欢虚拟块设备标识符,但是这些标识符有助于内核以统一的方式处理特殊文件系统和普通文件系统。
文件系统类型注册
通常,用户在为自己的系统编译内核时可以把Linux配置为能够识别所有需要的文件系统。但是,文件系统的源代码实际上要么包含在内核映像中,要么作为一个模块被动态装入。VFS必须对代码目前已在内核中的所有文件系统的类型进行跟踪。这就是通过进行文件系统类型注册来实现的。每个注册的文件系统都用一个类型为file_system_type的对象来表示,该对象的所有字段在表12-9中列出。
struct file_system_type {
115 const char *name;
116 int fs_flags;
117 struct dentry *(*mount) (struct file_system_type *, int,
118 const char *, void *);
119 void (*kill_sb) (struct super_block *);
120 struct module *owner;
121 struct file_system_type * next;
122 struct list_head fs_supers;
123 struct lock_class_key s_lock_key;
124 struct lock_class_key s_umount_key;
125 };
其中,name是文件系统名称,如ext4, xfs等等。fs_flags为各种标识,如FS_REQUIRES_DEV, FS_NO_DCACHE等。mount()函数指针用于挂载一个新的文件系统实例。kill_sb()函数指针用于关闭文件系统实例。owner是VFS内部使用,通常设置为THIS_MODULE。next也是VFS内部使用,初始化时设置为NULL即可。s_lock_key和s_umount_key是lockdep相关的结构。
mount()函数有几个参数:fs_type为对应的file_sytem_type结构指针。flags为挂载的标识。dev_name为挂载的设备名,对于网络文件系统通常是一个网络路径。data为挂载的选项,通常为一组ASCII字符串。
mount()必须返回文件系统目录树的root dentry。文件系统的super block增加一个引用计数并处于locked状态。mount失败时返回ERR_PTR(err)。mount()函数可以选择返回一个已经存在的文件系统的一个子树,而不是创建一个新的文件系统实例,这种情况返回的是子树的root dentry。
底层文件系统实现mount,可以直接调用通用的mount实现:mount_bdev(在块设备上挂载文件系统)、mount_nodev(挂载没有设备的文件系统)和mount_single(挂载在不同的mounts间共享实例的文件系统),并提供一个fill_super()的回调函数用于创建root dentry和inode。比如FUSE就通过调用mount_nodev来实现mount操作。 其中file_super()回调函数的参数包括:struct super_block sb(文件系统sb,需要在fill_super()里进行初始化)、void data(文件系统挂载的选项字符串)、int silent(是否忽略error)。
当然也可以参考通用的mount实现自己的mount操作,比如Ceph就直接调用了sget()函数创建sb并通过set()回调函数初始化sb。所有文件系统类型的对象都插入到一个单向链表中。由变量file_systems指向链表的第一个元素,而结构中的next字段指向链表的下一个元素。file_systems_lock读/写自旋锁保护整个链表免受同时访问。
fs_supers字段表示给定类型的已安装文件系统所对应的超级块链表的头(第一个伪元素)。链表元素的向后和向前链接存放在超级块对象的s_instances字段中。get_sb字段指向依赖于文件系统类型的函数,该函数分配一个新的超级块对象并初始化它(如果需要,可读磁盘)。而kill_sb字段指向删除超级块的函数。fs_flags字段存放几个标志,如表12-10所示。
| 名称 | 说明 |
|---|---|
| FS_REQUIRES_DEV | 这种类型的任何文件系统必须位于物理磁盘设备上 |
| FS_BINARY_MOUNTDATA | 文件系统使用的二进制安装数据 |
| FS_REVAL_DOT | 始终在目录项高速缓存中时.和..路径重新生效 |
| FS_ODD_RENAME | 重命名操作就是移动操作 |
在系统初始化期间,调用register_filesystem()函数来注册编译时指定的每个文件系统;该函数把相应的file_system_type对象插入到文件系统类型的链表中。当实现了文件系统的模块被装入时,也要调用register_filesystem()函数。在这种情况下,当该模块被卸载时,对应的文件系统也可以被注销(调用unregister_filesystem()函数)。
get_fs_type()函数(参数为文件系统名)扫描已注册的文件系统链表以查找文件系统类型的name字段,并返回指向相应的file_system_type对象(如果存在)的指针。
文件系统处理
就像每个传统的Unix系统一样,Linux也使用系统的根文件系统(system’s rootfilesystem):它由内核在引导阶段直接安装,并拥有系统初始化脚本以及最基本的系统程序。其他文件系统要么由初始化脚本安装,要么由用户直接安装在已安装文件系统的目录上。
作为一个目录树,每个文件系统都拥有自己的根目录(root directory)。安装文件系统的这个目录称之为安装点(mount point)。已安装文件系统属于安装点目录的一个子文件系统。例如,/proc虚拟文件系统是系统的根文件系统的孩子(且系统的根文件系统是/proc的父亲)。已安装文件系统的根目录隐藏了父文件系统的安装点目录原来的内容,而且父文件系统的整个子树位于安装点之下。
文件系统的根目录有可能不同于进程的根目录:进程的根目录是与“/“路径对应的目录。缺省情况下,进程的根目录与系统的根文件系统的根目录一致(更准确地说是与进程的命名空间中的根文件系统的根目录一致,这一点将在下一节描述),但是可以通过调用chroot()系统调用改变进程的根目录。
命名空间
在传统的Unix系统中,只有一个已安装文件系统树:从系统的根文件系统开始,每个进程通过指定合适的路径名可以访问已安装文件系统中的任何文件。从这个方面考虑,Linux 2.6更加的精确:每个进程可拥有自己的已安装文件系统树——叫做进程的命名空间(namespace)。
通常大多数进程共享同一个命名空间,即位于系统的根文件系统且被init进程使用的已安装文件系统树。不过,如果clone()系统调用以CLONE_NEWNS标志创建一个新进程,那么进程将获取一个新的命名空间。这个新的命名空间随后由子进程继承(如果父进程没有以CLONE_NEWNS标志创建这些子进程)。当进程安装或卸载一个文件系统时,仅修改它的命名空间。因此,所做的修改对共享同一命名空间的所有进程都是可见的,并且也只对它们可见。
进程甚至可通过使用Linux 特有的pivot_root()系统调用来改变它的命名空间的根文件系统。进程的命名空间由进程描述符的namespace字段指向的namespace结构描述。该结构的字段如表12-11所示。
| 名称 | 说明 |
|---|---|
| count | 引用计数器(共享命名空间的进程数) |
| root | 命名空间根目录的已安装文件系统描述符 |
| list | 所有已安装文件系统描述符链表的头 |
| sem | 保护这个结构的读/写信号量 |
list字段是双向循环链表的头,该表聚集了属于命名空间的所有已安装文件系统。root 字段表示已安装文件系统,它是这个命名空间的已安装文件系统树的根。