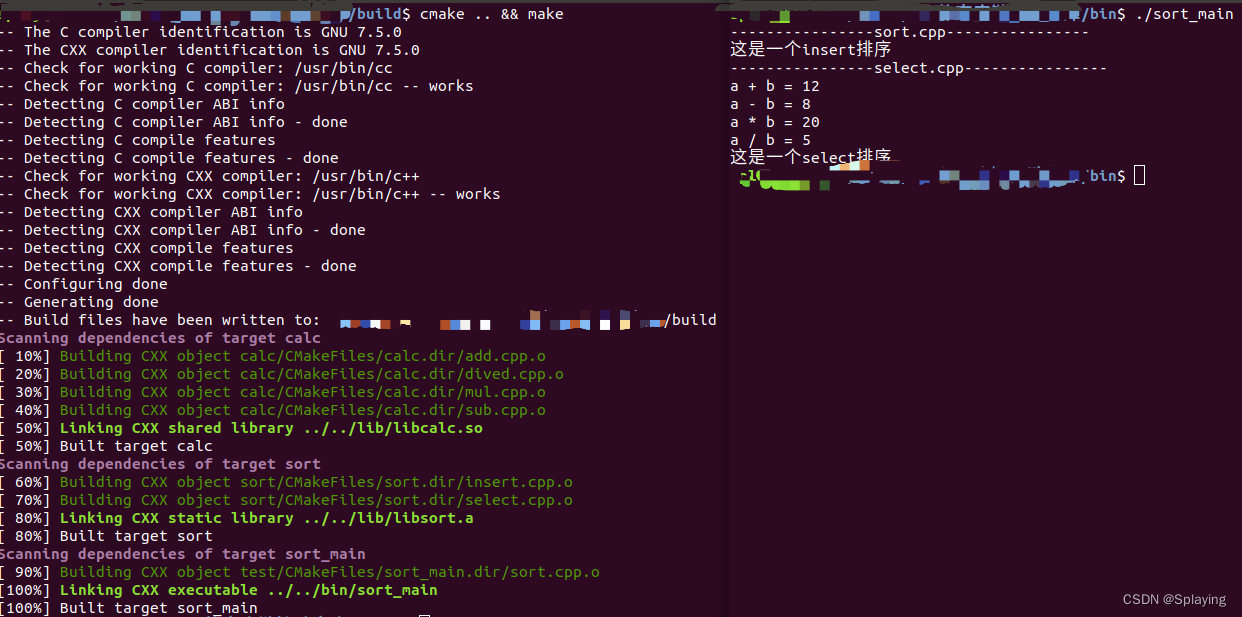
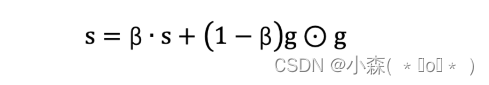最近做一个攻防演习,使用了一些工具收集域名,子域名,但是在将这些域名解析成 IP 这个过程遇到了一些小问题,默认工具给出的 cdn 标志根本不准,所以被迫写了这么一个小工具:get_real_ip.py
PS:下面有详细代码,文章最后有下载链接
使用方法
-
安装依赖包
pip3 install -r requirements.txt -
将要检测的域名放入到文件中,假设文件为
domains.txt -
假设设置线程为 20 (默认为 50)
-
执行
python3 get_real_ip.py -f domains.txt
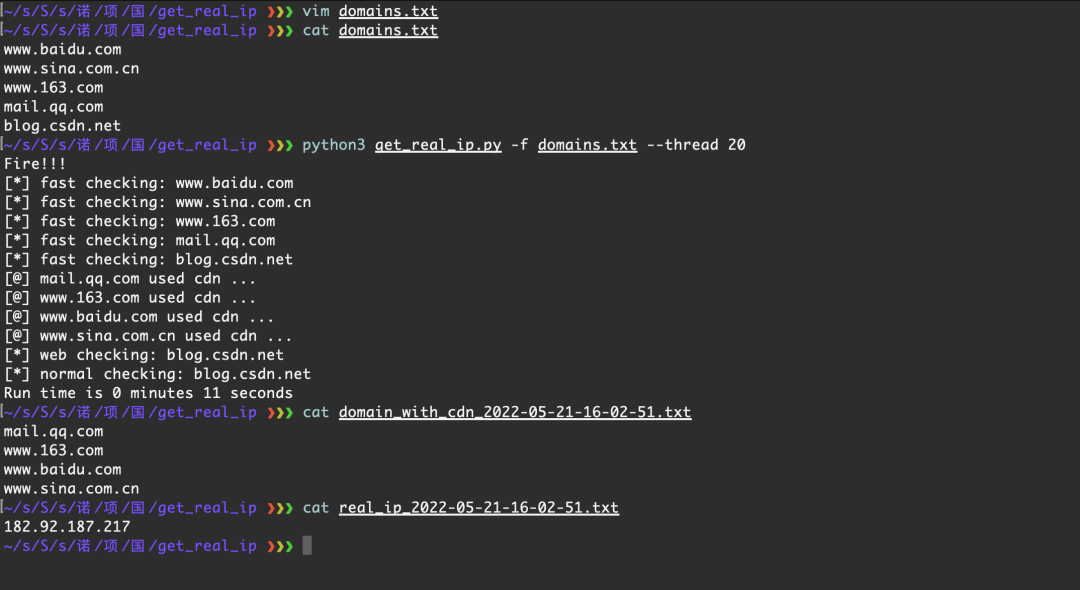
使用了 cdn 的域名放到了文件 domain_with_cdn_xxxx 中,未使用 cdn 的域名解析的 IP 放到了real_ip_xxxx 中
注意事项
-
执行后,如果目标没有使用cdn,你是会向目标发起至少两次无害的 web 请求的,如果不想暴漏IP,就做好准备
-
建议选择可以解析目标域名的 DNS 服务器来测试,脚本自带的都是效果比较好的,自己选择的话下文有说
-
移动的 DNS 服务器是不支持其他运营商网络使用的,如果你不是移动的网络,而且要追求那一丢丢可能出现的遗漏,可以考虑在移动网络下再执行一次
脚本中的一些技术点
判定方法
判定方法很简单,使用了全球各地的 DNS 服务器对域名的 A 记录进行解析,之后根据结果 IP 数量来进行判断,这里选择的阈值是 3,这也对应着三大运营商,解析得到不同的 ip 数量大于 3 个就认为使用了 cdn
为了加速判定,这里先选择了具有代表性的四个 DNS 服务器,对某个域名的 A 记录进行解析,如果得到的结果 IP数量大于 3 个,那么就认为其使用了 cdn。如果小于 4 个,对其进行 web 网页标题检查,将直接 IP 访问网页标题一致的保存下来,如果存在不一致的,那么就进行常规检查
常规检查就是通过精心选择的大量 DNS 服务器对该域名进行 A 记录解析,再根据 IP 数量进行判定,阈值依旧是 3
DNS 服务器的选择
一开始我们选择了非常多的 DNS 服务器,遍布全球,但后来经过不断测试发现,很多 DNS 服务器对国内域名的解析并不友好,最后保留了近 50 个 DNS 服务器
选择 DNS 服务器至少包括:
-
国内外常用的公共 DNS 服务器
-
中国大陆南方DNS服务器、中国大陆北方DNS服务器
-
香港、台湾、澳门地区的 DNS 服务器
-
美国、日本、俄罗斯、澳大利亚、德国、加拿大、法国、泰国的DNS服务器
-
国内三大运营商的 DNS 服务器
运营商 DNS 困境
假如这次测试的目标是百度,那么就使用这些DNS服务器先解析一下 www.baidu.com 试一下
寻找其他 DNS 服务器的时候,问题其实不是很大,使用这些 DNS 服务器解析一下的 www.baidu.com 就行了,如果有结果,没有报错,又符合条件,那就可以加入进来,但是到了运营商这里,问题就来了
运营商的 DNS 非常多,每个省都有,但是这些 DNS 中绝大多数都有地域限制,比如说你是山西的联通网络,那么你就只能使用山西的联通 DNS,而不能使用其他地区的联通 DNS,也不能使用其他运营商的 DNS
我们耗费了很长时间,终于找到了允许任意运营商、任意地区的网络使用的联通和电信的 DNS 服务器,移动的并没有找到,DNS服务器这么多,如果一个一个测试,那实在是太折磨人了,于是有了下面的部分
自定义 DNS 服务器列表
因为 DNS 数量太多了,不知道具体哪些 DNS 服务器能够成功解析当前目标的比较有代表性的域名,所以我们拿出了祖传技能,写了一个 Nmap 的 NSE 脚本 find-useful-dnsserver.nse 来帮助我们批量测试
local dns = require "dns"
local nmap = require "nmap"
local stdnse = require "stdnse"
description = [[ Attempts to test if these dns servers are available. ]]
-- 2022-05-20
---
-- @usage
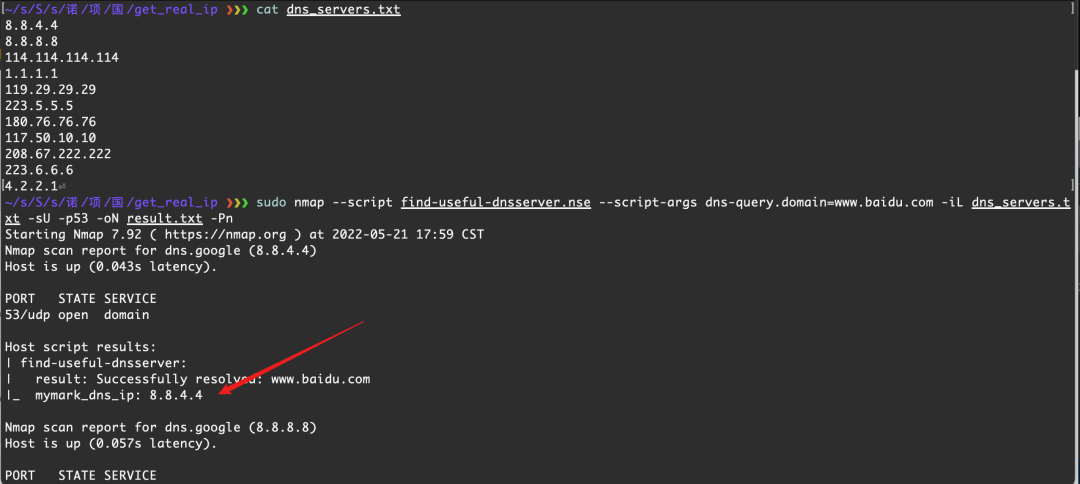
-- sudo nmap --script find-useful-dnsserver.nse --script-args dns-query.domain=www.baidu.com -sU -p 53 -iL dns_servers.txt -Pn
-- @args dns-brute.domain The domain to test dns servers. Defaults to "www.baidu.com"
--
-- @output
-- PORT STATE SERVICE
-- 53/udp open domain
-- Host script results:
-- | find-useful-dnsserver:
-- | result: Successfully resolved: www.baidu.com
-- |_ mymark_dns_ip: 8.8.8.8
--
author = "test94"
license = "Same as Nmap--See https://nmap.org/book/man-legal.html"
categories = {"intrusive", "discovery"}
prerule = function()
if not stdnse.get_script_args("dns-query.domain") then
stdnse.debug1("please input the domain to test.")
return false
end
end
hostrule = function()
return true
end
action = function(host)
local domainname = stdnse.get_script_args('dns-query.domain')
-- 如果没有指定域名,那就用 www.baidu.com 来进行测试
if not domainname then
domainname = "www.baidu.com"
end
local status, result = dns.query(domainname, {dtype="A",retAll=true,host=host.ip})
local output = stdnse.output_table()
if status then
output.result = "Successfully resolved: " .. domainname
output.mymark_dns_ip = host.ip
else
output.result = "Failed to resolve: " .. domainname
end
return output
end
具体使用方法如下:
-
将要测试的 DNS 服务器地址写入到文件中,这里以
dns_servers.txt为例 -
将当前路径切换到脚本所在的路径下
-
假设目标为
www.baidu.com -
执行
sudo nmap --script find-useful-dnsserver.nse --script-args dns-query.domain=www.baidu.com -iL dns_servers.txt -sU -p53 -oN result.txt -Pn -
如果脚本发现了可用的 DNS 服务器,
result.txt中会有mark标记,筛选就可以了 -
筛选
cat result.txt | grep mark | cut -d " " -f 4
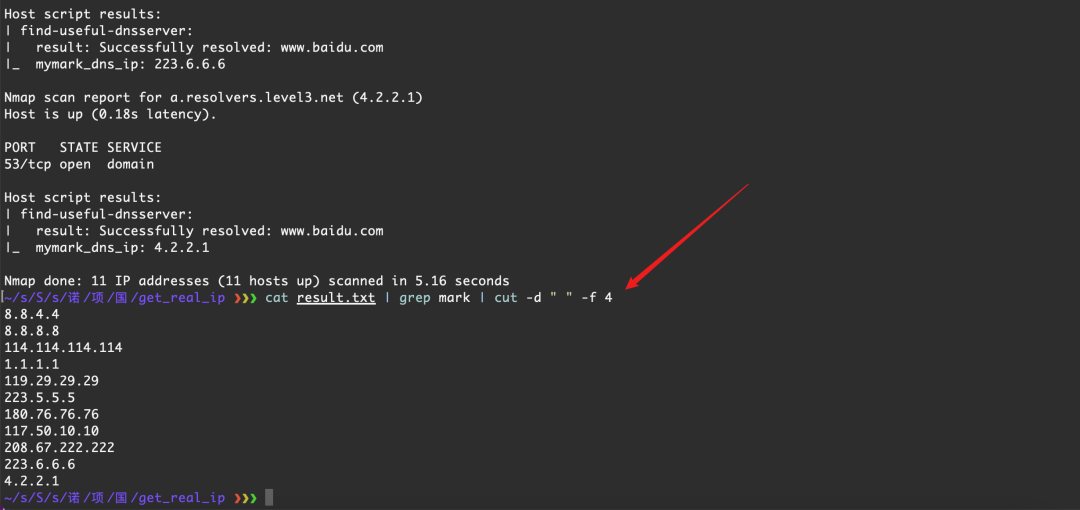
这些 DNS 地址就是有效 DNS 服务器地址了,用它们来测试准没错
【已更新,从下面的百度云链接下载】最后附上 get_real_ip.py 的代码:
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# Author: 意大利的猫
'''
这个程序用来将使用了 cdn 和没有使用 cdn 的域名分开,获取没有使用 cdn 的域名的真实 ip
'''
import datetime
import argparse
import requests
from bs4 import BeautifulSoup
import time
import threading
import queue
import dns.resolver
import sys
import re
import tldextract
# pip3 freeze > requirements.txt 生成 requirements.txt
# 函数时间装饰器
def functime(func):
def wap(*args, **kw):
local_time = datetime.datetime.now()
func(*args, **kw)
times = (datetime.datetime.now() - local_time).seconds
print('Run time is {} minutes {} seconds'.format(
times // 60, times % 60))
return wap
# 类方法时间装饰器
# def get_class_func_time(func):
# def wrapper(self, *args, **kwargs):
# local_time = datetime.datetime.now()
# func(self, *args, **kwargs)
# times = (datetime.datetime.now() - local_time).seconds
# funcname = func.__name__
# print('Run {} time is {} minutes {} seconds'.format(
# funcname, times // 60, times % 60))
# return wrapper
class GetRealIP:
"""
=================================================
功能: 这个类用来获取域名的真实IP
args:
domain_file, 域名列表文件
threads, 线程数
=================================================
"""
# 构造函数
def __init__(self, domain_file, threads):
self.domain_file = domain_file
self.threads = threads
self.thread_list = []
self.ip_list = []
self.cdn_domains_list = []
self.myResolver = dns.resolver.Resolver()
self.myResolver.retry_servfail = True
self.myResolver.timeout = 3
self.lock = threading.Lock()
self.DOMAIN_QUEUE = queue.Queue()
nowTime = datetime.datetime.now().strftime('%Y-%m-%d-%H-%M-%S')
self.save_ip_file = "real_ip_" + str(nowTime) + ".txt"
self.save_cdn_domain_file = "domain_with_cdn_" + str(nowTime) + ".txt"
self.fast_nameservers = ["114.114.114.114", "8.8.8.8", "223.5.5.5", "80.80.80.80"]
self.nameservers = ['8.8.4.4',
'8.8.8.8',
'114.114.114.114',
'1.1.1.1',
'119.29.29.29',
'223.5.5.5',
'180.76.76.76',
'117.50.10.10',
'208.67.222.222',
'223.6.6.6',
'4.2.2.1',
'168.95.1.1',
'202.14.67.4',
'202.14.67.14',
'168.95.192.1',
'168.95.1.1',
'202.86.191.50',
'202.175.45.2',
'202.248.20.133',
'211.129.155.175',
'101.110.50.105',
'212.66.129.108',
'104.152.211.99',
'9.9.9.9',
'82.127.173.122',
'61.19.42.5',
'210.23.129.34',
'210.80.58.3',
'62.122.101.59',
'80.66.158.118',
'101.226.4.6',
'218.30.118.6',
'123.125.81.6',
'140.207.198.6',
'80.80.80.80',
'61.132.163.68',
'202.102.213.68',
'202.98.192.67',
'202.98.198.167',
'210.22.70.3',
'123.123.123.123',
'210.22.84.3',
'221.7.1.20',
'221.7.1.21',
'202.116.128.1',
'202.192.18.1',
'211.136.112.50',
'211.138.30.66']
"""
=================================================
功能:批量做 dns 解析的函数
参数:
domain 待解析的域名
nameservers_list 用来解析域名的 dns 服务器地址
返回值:
result_list 解析这个域名得到的 IP 列表
==================================================
"""
def dns_resolve(self, domain, nameservers_list):
local_Resolver = dns.resolver.Resolver()
local_Resolver.retry_servfail = True
local_Resolver.timeout = 3
result_list = []
for name_server in nameservers_list:
# time.sleep(1)
local_Resolver.nameservers = [name_server]
if len(result_list) > 4:
return result_list
try:
myAnswers = local_Resolver.resolve(domain, "A", lifetime=1)
for rdata in myAnswers:
if rdata.address not in result_list and ":" not in rdata.address:# and len(result_list) < 5:
result_list.append(rdata.address)
except Exception as error:
continue
return result_list
'''
=================================================
功能: 获取网页编码,循环获取,非常变态
参数:
soup bs4 的 返回值
返回值:
encoding 返回页面编码
=================================================
'''
def get_encoding(self, soup):
encoding = None
if soup:
for meta_tag in soup.find_all("meta"):
encoding = meta_tag.get('charset')
if encoding: break
else:
encoding = meta_tag.get('content-type')
if encoding: break
else:
content = meta_tag.get('content')
if content:
match = re.search('charset=(.*)', content)
if match:
encoding = match.group(1)
break
if encoding:
return str(encoding).lower()
return encoding
'''
=================================================
功能: 这个函数用来解析网页 title
参数:
resp requests 的返回值
返回值:
title.string 网页 title 字符串
=================================================
'''
def parse_title(self, resp):
soup_for_charset = BeautifulSoup(resp.text, 'lxml')
resp.encoding = self.get_encoding(soup_for_charset) or "utf-8"
soup = BeautifulSoup(resp.text, 'html.parser')
title = soup.find('title')
return title.string
'''
========================================================================================
功能: 获取使用http 或者 https 协议访问网页,获取网页的 title
参数:
host domain 或者 ip,通用
返回值:
http_title http 访问得到的 title
https_title https 访问得到的 title
status_flag 如果 http和https 都无法访问,status_flag = False ,表示 web 访问失败
========================================================================================
'''
def get_page_title(self, host):
http_url = "http://" + host + "/"
https_url = "https://" + host + "/"
http_title = None
https_title = None
status_flag = True
# 请求头
Headers = {
"Upgrade-Insecure-Requests": '1',
"User-Agent":
"Mozilla/5.0 (Windows NT 6.3; WOW64; rv:47.0) Gecko/20100101 Firefox/47.0",
"Connection": "close"
}
requests.packages.urllib3.disable_warnings()
try:
http_resp = requests.get(http_url, verify=False, headers=Headers, timeout=15, max_retries=3, dely_between_retries=1)
if http_resp.status_code < 400 or http_resp.status_code == 412:
http_title = self.parse_title(http_resp)
except Exception as e:
pass
try:
https_resp = requests.get(https_url, verify=False, headers=Headers, timeout=15, max_retries=3, dely_between_retries=1)
if https_resp.status_code < 400 or https_resp.status_code == 412:
https_title = self.parse_title(https_resp)
except Exception as e:
pass
if http_title == None and https_title == None:
status_flag = False
return http_title, https_title, status_flag
'''
========================================================================================
功能:用来保存结果
参数:
ip=None 如果是 IP, 那就将其作为真实 IP 进行存储
cdn_domain=None 如果是域名,那就将其作为使用了cdn 的域名进行存储
返回值:无返回值
========================================================================================
'''
def save_results(self, ip=None, cdn_domain=None):
self.lock.acquire()
if ip and ip not in self.ip_list:
self.ip_list.append(ip)
with open(self.save_ip_file, "a+") as f:
f.write(ip + "\n")
elif cdn_domain and cdn_domain not in self.cdn_domains_list:
print(f"[@] {cdn_domain} used cdn ...")
self.cdn_domains_list.append(cdn_domain)
with open(self.save_cdn_domain_file, "a+") as f:
f.write(cdn_domain + "\n")
self.lock.release()
'''
========================================================================================
功能:这个函数做常规检查,具体也就是通过几十个 dns 服务器对域名进行解析,根据得到的 ip 数量来判断
参数:
domain 待解析的域名
返回值:无返回值
========================================================================================
'''
def normal_check(self, domain):
print(f"[*] normal checking: {domain}")
normal_list = self.dns_resolve(domain, self.nameservers)
if 0 < len(normal_list) < 4:
for ip in normal_list:
self.save_results(ip=ip)
elif len(normal_list) != 0:
self.save_results(cdn_domain=domain)
'''
========================================================================================
功能:这个函数做web检查,先用 8.8.8.8 来进行解析,之后使用这个IP直接去访问,
如果得到的结果和直接用http或者https访问有任何的相同都认为是真实ip
参数:
domain 待测试的域名
返回值:无返回值
========================================================================================
'''
def web_check(self, domain):
print(f"[*] web checking: {domain}")
# 如果 8.8.8.8 解析失败了,那就走常规检查
ip_list = self.dns_resolve(domain, ["8.8.8.8"])
if len(ip_list) == 0:
self.normal_check(domain)
return
# 如果用域名访问都获取不到title,那就直接走常规检查
normal_http_title, normal_https_title, normal_status_flag = self.get_page_title(domain)
if not normal_status_flag:
self.normal_check(domain)
return
title_list = [normal_http_title, normal_https_title]
real_ip_flag = 1
for ip in ip_list:
ip_http_title, ip_https_title, ip_status_flag = self.get_page_title(ip)
if ip_status_flag:
if ip_http_title != None and ip_http_title in title_list:
self.save_results(ip=ip)
elif ip_https_title != None and ip_https_title in title_list:
self.save_results(ip=ip)
else:
real_ip_flag = 0
if not real_ip_flag:
self.normal_check(domain)
'''
========================================================================================
功能:这个方法用来快速解析域名,目的是快速去掉一些明显使用了 cdn 的域名
参数:无参数
返回值:无返回值
========================================================================================
'''
def fast_check(self):
# global DOMAIN_QUEUE
while True:
domain = None
self.lock.acquire()
if not self.DOMAIN_QUEUE.qsize():
self.lock.release()
break
domain = self.DOMAIN_QUEUE.get()
self.lock.release()
print(f"[*] fast checking: {domain}")
fast_list = self.dns_resolve(domain, self.fast_nameservers)
if 0 < len(fast_list) < 4:
self.web_check(domain)
elif len(fast_list) != 0:
self.save_results(cdn_domain=domain)
'''
=======================
功能:纯属个人爱好
参数:无参数
返回值:无返回值
=======================
'''
def fire(self):
print("Fire!!!")
time.sleep(1)
# 将域名放入到队列中
f = self.domain_file
for domain in f:
domain = domain.strip()
self.DOMAIN_QUEUE.put(domain)
# 创建线程
for i in range(self.threads):
t = threading.Thread(target=self.fast_check)
self.thread_list.append(t)
# 启动进程
for t in self.thread_list:
t.start()
# 设置子线程结束后才退出程序
for t in self.thread_list:
t.join()
'''
=======================
功能:主函数
参数:无参数
返回值:无返回值
=======================
'''
@functime
def main():
if args.file:
domains_file = args.file
gri = GetRealIP(domain_file=domains_file, threads=args.threads)
gri.fire()
else:
print("Usage: python3 dns_threads.py -f domains.txt --threads=50")
if __name__ == '__main__':
# 设置各种参数
parser = argparse.ArgumentParser(description=u'筛选出未使用cdn的域名,并获取真实IP', add_help=False)
parser.add_argument('-h', '--help', action='help', help=u'显示帮助信息')
group = parser.add_mutually_exclusive_group()
group.add_argument('-f', '--file', type=argparse.FileType('r'), help=u'选定要转换的域名文件(按行分割)')
parser.add_argument('-tn', '--threads', type=int, default=50, help=u'指定线程数,默认50')
args = parser.parse_args()
# 调用主函数
main()
文件下载地址:
https://pan.baidu.com/s/1r2QocjUfAHDSRPMPVEbxhQ 提取码: ah4l
「你即将失去如下所有学习变强机会」
学习效率低,学不到实战内容,花几千、上万报机构没有性价比
一顿自助钱,我承诺一定让用户满意,也希望用户能给予我一份信任
【详情下方图片了解】,【扫下方二维码加入】:只做高质量优质精品内容」
现在圈子已经有150+师傅相信并选择加入我们,人数满199人将涨价,老用户可永久享受初始加入价格,圈子内容持续更新中


免责声明
由于传播、利用本公众号所提供的信息而造成的任何直接或者间接的后果及损失,均由使用者本人负责,本公众号及作者不为此承担任何责任,一旦造成后果请自行承担!如有侵权烦请告知,我们会立即删除并致歉。谢谢!