一、实验目的
1.加深学生对贪心算法设计方法的基本思想、基本步骤、基本方法的理解与掌握;
2.提高学生利用课堂所学知识解决实际问题的能力;
3.提高学生综合应用所学知识解决实际问题的能力。
二、实验任务
用贪心算法实现:
1、TSP问题
TSP问题(Travelling Salesman Problem)即旅行商问题,又译为旅行推销员问题、货郎担问题,是数学领域中著名问题之一。假设有一个旅行商人要拜访n个城市,他必须选择所要走的路径,路径的限制是每个城市只能拜访一次,而且最后要回到原来出发的城市。路径的选择目标是要求得的路径路程为所有路径之中的最小值。
2、哈夫曼编码问题
a.写一个程序,为给定的英文文本构造一套哈夫曼编码,并对该文本编码。
b.写一个程序,对一段用哈夫曼编码的英文文本进行解码。
c.做一个实验,测试对包含1000个词左右的一段英文文本进行哈夫曼编码时,典型的压缩率位于什么样的区间。
3、设有n个顾客同时等待一项服务,顾客i 需要的服务时间为ti ,i=1,2,3,…,n 。从时刻0开始计时,若在时刻t开始对顾客i服务,那么i的等待时间为t,应该怎么安排n个顾客的服务次序使得总的等待时间(每个顾客等待时间的总和)最少?
假设服务时间分别为{1,3,2,15,10,6,12},用贪心算法给出这个问题的解。
4、最小生成树问题(Prim算法和Kruskal算法)
设G=(V,E)是一个无向连通网,生成树上各边的权值之和称为该生成树的代价,在G的所有生成树中,代价最小的生成树称为最小生成树(Minimal Spanning Trees)。
5、图着色问题
给定无向连通图G=(V, E),求图G的最小色数k,使得用k种颜色对G中的顶点着色,可使任意两个相邻顶点着色不同。
三、实验设备及编程开发工具
笔记本,Windows10操作系统,Dev-C++,Pycharm
四、实验过程设计(算法设计过程)
(一)TSP问题
1、TSP问题
在TSP问题上,假设城市集合为B,我们每次只选择距离当前城市最近的城市移动。同时集合s记录已经遍历过得城市,下次从集合(B-s)中选择。
# 贪心法
import pandas as pd
import numpy as np
import math
import time
dataframe = pd.read_csv("./data/TSP100cities.tsp", sep=" ", header=None)
v = dataframe.iloc[:, 1:3]
train_v = np.array(v)
train_d = train_v
dist = np.zeros((train_v.shape[0], train_d.shape[0]))
# 计算距离矩阵
for i in range(train_v.shape[0]):
for j in range(train_d.shape[0]):
dist[i, j] = math.sqrt(np.sum((train_v[i, :] - train_d[j, :]) ** 2))
"""
s:已经遍历过的城市
dist:城市间距离矩阵
sumpath:目前的最小路径总长度
Dtemp:当前最小距离
flag:访问标记
"""
i = 1
n = train_v.shape[0]
j = 0
sumpath = 0
s = []
s.append(0)
start = time.clock()
while True:
k = 1
Detemp = 10000000
while True:
l = 0
flag = 0
if k in s:
flag = 1
if (flag == 0) and (dist[k][s[i - 1]] < Detemp):
j = k;
Detemp = dist[k][s[i - 1]];
k += 1
if k >= n:
break;
s.append(j)
i += 1;
sumpath += Detemp
if i >= n:
break;
sumpath += dist[0][j]
end = time.clock()
print("结果:")
print(sumpath)
for m in range(n):
print("%s-> " % (s[m]), end='')
print()
print("程序的运行时间是:%s" % (end - start))
(二)哈夫曼编码问题
(1)问题分析:
哈夫曼提出构造最优前缀码的贪心算法,由此产生的编码方案称为哈夫曼编码。其构造步骤如下:
(1)哈夫曼算法以自底向上的方式构造表示最优前缀码的二叉树T。
(2)算法以|C|个叶结点开始,执行|C|-1次的“合并”运算后产生最终所要求的树T。
(3)假设编码字符集中每一字符c的频率是f©。以f为键值的优先队列Q用在贪心选择时有效地确定算法当前要合并的2棵具有最小频率的树。一旦2棵具有最小频率的树合并后,产生一棵新的树,其频率为合并的2棵树的频率之和,并将新树插入优先队列Q。经过n-1次的合并后,优先队列中只剩下一棵树,即所要求的树T。
(2)算法实现:
import requests
# 实现节点类
class Node:
def __init__(self, freq):
self.left = None
self.right = None
self.father = None
self.freq = freq
def is_left(self):
return self.father.left == self
# 为每一个节点赋权值
def create_nodes(frequencies):
return [Node(freq) for freq in frequencies]
# 创建哈夫曼树
def createHuffmanTree(nodes):
queue = nodes[:]
while len(queue) > 1:
queue.sort(key=lambda item: item.freq) # 将字符出现的频率视为权值,按权值排序。sort()默认升序排列
node_left = queue.pop(0) # 将弹出的第一个元素(最小)赋给左边节点
node_right = queue.pop(0)
node_father = Node(node_left.freq + node_right.freq) # 将左右子树的权值相加赋给父节点
# 构建节点之间的关系
node_father.left = node_left
node_father.right = node_right
node_left.father = node_father
node_right.father = node_father
queue.append(node_father) # 将父节点插入到队列中
queue[0].father = None # 第一个节点没有父节点
# print(type(queue[0])) queue[0] 中保存的是什么数据
return queue[0]
# 遍历叶节点
def huffman_encoding(nodes, root):
codes = [''] * len(nodes)
for i in range(len(nodes)):
node_tmp = nodes[i]
while node_tmp != root:
if node_tmp.is_left():
codes[i] = '0' + codes[i]
else:
codes[i] = '1' + codes[i]
node_tmp = node_tmp.father
return codes
# 获取字符出现的频数
def count_frequency(input_string):
# 用于存放字符
char_store = []
# 用于存放频数
freq_store = []
# 解析字符串
for index in range(len(input_string)):
if char_store.count(input_string[index]) > 0:
temp = int(freq_store[char_store.index(input_string[index])])
temp = temp + 1
freq_store[char_store.index(input_string[index])] = temp
else:
char_store.append(input_string[index])
freq_store.append(1)
# 返回字符列表和频数列表
return char_store, freq_store
# 获取字符、频数的列表
def get_char_frequency(char_store=[], freq_store=[]):
# 用于存放char_frequency
char_frequency = []
for item in zip(char_store, freq_store):
temp = (item[0], item[1])
char_frequency.append(temp)
return char_frequency
# 解压缩huffman文件
def decode_huffman(input_string, char_store, freq_store):
encode = ''
decode = ''
for index in range(len(input_string)):
encode = encode + input_string[index]
for item in zip(char_store, freq_store):
if encode == item[1]:
decode = decode + item[0]
encode = ''
return decode
input_string = input()
a, b = count_frequency(input_string)
char_freqs = get_char_frequency(a, b)
nodes = create_nodes([item[1] for item in char_freqs])
root = createHuffmanTree(nodes)
codes = huffman_encoding(nodes, root)
for item in zip(char_freqs, codes):
print('Character:%s freq:%-2d encoding: %s' % (item[0][0], item[0][1], item[1]))
(三)顾客等待问题
(1) 问题分析:
服务时间最小的顾客先服务,第一位顾客服务时,每一位顾客都等待A[0]个时间;第二个时,有n-1位顾客等待;以此类推,第i个顾客服务时,有n- i个顾客在等待中,由此得出公式 总的等待时间 time += (n - i) * A [ i ] ,最小平均等待时间为 time / n。
(2) 算法实现:
#include <stdio.h>
#include <string.h>
#define SIZE 10
int A[SIZE];
void sort(int A[],int n);
double greedy(int A[],int n);
void swap(int * a,int * b);
int main()
{
int n,i;// n个顾客
printf("请输入顾客数:\n");
scanf("%d",&n);
printf("请输入每个顾客的服务时间:\n");
for(i = 1;i<=n;i++)
{
printf("No.%d\n",i);
scanf("%d",&A[i-1]);
}
sort(A,n);
printf("最小平均等待时间:%.2f",greedy(A,n));
return 0;
}
double greedy(int A[],int n)
{
int i,time = 0;
double t = 0;//最小平均等待时间
for(i = 0;i < n;i++)
{
time = time +(n-i)*A[i];
}
t = time/n;
return t;
}
void sort(int A[],int n)
{
int i,j;
for(i = 0;i < n;i++)
{
for(j = i+1;j < n;j++)
{
if(A[i] > A[j])
swap(&A[i],&A[j]);
}
}
}
void swap(int *a,int *b)
{
int temp;
temp = *a;
*a = *b;
*b = temp;
}
(四)最小生成树问题
(1) Prim算法
任选一个顶点,并以此建立起生成树,每一步的贪心选择是简单地把不在生成树中的最近顶点添加到生成树中。设最小生成树T=(U,TE),初始化时U={u0}(u0为任意顶点),TE={ }。Prim算法的关键是如何找到连接 U 和 V-U 的最短边来扩充生成树T。
对于每一个不在当前生成树中的顶点v∈ V-U,必须知道它连接生成树中每一个顶点u∈U的边信息,从中选择最短边。
所以,对当前不在生成树中的顶点v∈ V-U,需要保存两个信息:lowcost[v]表示顶点v到生成树中所有顶点的最短边;adjvex[v]表示该最短边在生成树中的顶点。
(2) Kruskal算法
设G=(V,E)是一个无向连通网,令T=(U,TE)是G的最小生成树。最短边策略从TE={ }开始,每一次贪心选择都是在边集E中选择最短边(u,v),如果边(u,v)加入集合TE中不产生回路,则将边(u,v)加入边集TE中,并将它在集合E中删去。
class Graph(object):
def __init__(self, maps):
self.maps = maps
self.nodenum = self.get_nodenum()
self.edgenum = self.get_edgenum()
def get_nodenum(self):
return len(self.maps)
def get_edgenum(self):
count = 0
for i in range(self.nodenum):
for j in range(i):
if self.maps[i][j] > 0 and self.maps[i][j] < 9999:
count += 1
return count
def kruskal(self):
res = []
if self.nodenum <= 0 or self.edgenum < self.nodenum - 1:
return res
edge_list = []
for i in range(self.nodenum):
for j in range(i, self.nodenum):
if self.maps[i][j] < 9999:
edge_list.append([i, j, self.maps[i][j]]) # 按[begin, end, weight]形式加入
edge_list.sort(key=lambda a: a[2]) # 已经排好序的边集合
group = [[i] for i in range(self.nodenum)]
for edge in edge_list:
for i in range(len(group)):
if edge[0] in group[i]:
m = i
if edge[1] in group[i]:
n = i
if m != n:
res.append(edge)
group[m] = group[m] + group[n]
group[n] = []
return res
def prim(self):
res = []
if self.nodenum <= 0 or self.edgenum < self.nodenum - 1:
return res
res = []
seleted_node = [0]
candidate_node = [i for i in range(1, self.nodenum)]
while len(candidate_node) > 0:
begin, end, minweight = 0, 0, 9999
for i in seleted_node:
for j in candidate_node:
if self.maps[i][j] < minweight:
minweight = self.maps[i][j]
begin = i
end = j
res.append([begin, end, minweight])
seleted_node.append(end)
candidate_node.remove(end)
return res
max_value = 9999
row0 = [0, 7, max_value, max_value, max_value, 5]
row1 = [7, 0, 9, max_value, 3, max_value]
row2 = [max_value, 9, 0, 6, max_value, max_value]
row3 = [max_value, max_value, 6, 0, 8, 10]
row4 = [max_value, 3, max_value, 8, 0, 4]
row5 = [5, max_value, max_value, 10, 4, 0]
maps = [row0, row1, row2, row3, row4, row5]
graph = Graph(maps)
print('邻接矩阵为\n%s' % graph.maps)
print('节点数据为%d,边数为%d\n' % (graph.nodenum, graph.edgenum))
print('------最小生成树kruskal算法------')
print(graph.kruskal())
print('------最小生成树prim算法')
print(graph.prim())
(五)图着色问题
(1) 问题分析:
图的m色优化问题:给定无向连通图G,为图G的各顶点着色, 使图中任2邻接点着不同颜色,问最少需要几种颜色。所需的最少颜色的数目m称为该图的色数。
若图G是可平面图,则它的色数不超过4色(4色定理).
4色定理的应用:在一个平面或球面上的任何地图能够只用4种
颜色来着色使得相邻的国家在地图上着有不同颜色。
(2) 算法实现:
#include<stdio.h>
int color[100];
//int c[100][100];
bool ok(int k ,int c[][100])//判断顶点k的着色是否发生冲突
{
int i,j;
for(i=1;i<k;i++)
if(c[k][i]==1&&color[i]==color[k])
return false;
return true;
}
void graphcolor(int n,int m,int c[][100])
{
int i,k;
for(i=1;i<=n;i++)
color[i]=0;//初始化
k=1;
while(k>=1)
{
color[k]=color[k]+1;
while(color[k]<=m)
if (ok(k,c)) break;
else color[k]=color[k]+1;//搜索下一个颜色
if(color[k]<=m&&k==n)//求解完毕,输出解
{
for(i=1;i<=n;i++)
printf("%d ",color[i]);
printf("\n");
//return;//return表示之求解其中一种解
}
else if(color[k]<=m&&k<n)
k=k+1; //处理下一个顶点
else
{
color[k]=0;
k=k-1;//回溯
}
}
}
void main()
{
int i,j,n,m;
int c[100][100];//存储n个顶点的无向图的数组
printf("输入顶点数n和着色数m:\n");
scanf("%d %d",&n,&m);
printf("输入无向图的邻接矩阵:\n");
for(i=1;i<=n;i++)
for(j=1;j<=n;j++)
scanf("%d",&c[i][j]);
printf("着色所有可能的解:\n");
graphcolor(n,m,c);
}
五、实验结果及算法复杂度分析
(一)TSP问题
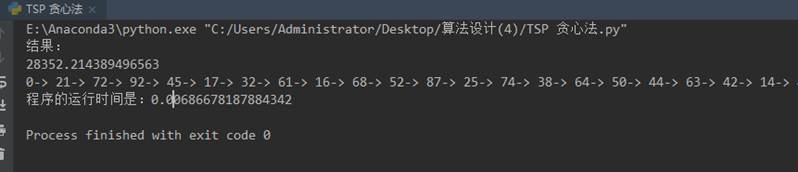
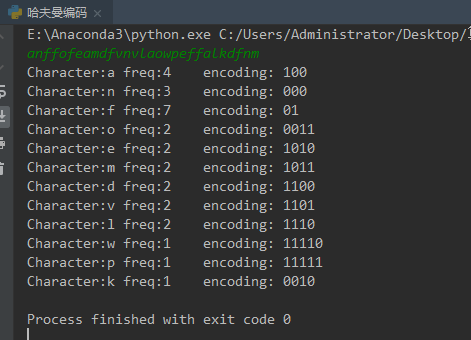
(二)哈夫曼编码问题
(三)动态服务问题

(四)最小生成树问题

(1)Prim算法
设连通网中有 n 个顶点,则第一个进行初始化的循环语句需要执行 n-1 次,第二个循环共执行 n-1 次,内嵌两个循环,其一是在长度为 n 的数组中求最小值,需要执行 n-1 次,其二是调整辅助数组,需要执行 n-1 次,所以,Prim 算法的时间复杂度为O(n2)。
(2) Kruskal算法
为了提高每次贪心选择时查找最短边的效率,可以先将图G中的边按代价从小到达排序,则这个操作的时间复杂度为O(elog2e),其中e为无向连通网中边的个数。对于两个顶点是否属于同一个连通分量,可以用并查集的操作将其时间性能提高到O(n),所以Kruskal算法的时间性能是O(elog2e)。
(五)图着色问题

实验小结(包括问题和解决方法、心得体会等)
通过本次实验,利用C/python语言编程实现解决了TSP问题,哈夫曼编码问题,顾客等待问题,最小生成树问题。对贪心算法有了更进一步的认识,对算法设计这门课程有了更多的认识。
本次实验增加了动手编码能力,对算法设计有了更进一步的认识,但是技术上的缺陷,编码能力上存在的短板,在今后的实验中还需要加大练习力度。