文章目录
- 通用网页数据
- 中文网页数据
- 书籍
- 维基百科
- 代码
- 混合型数据集
与早期的预训练语言模型相比,大语言模型需要更多的训练数据,这些数据需要涵盖广泛的内容范围。多领域、多源化的训练数据可以帮助大模型更加全面地学习真实世界的语言与知识,从而提高其通用性和准确性。根据其内容类型进行分类,这些语料库可以划分为:网页、书籍、维基百科、代码以及混合型数据集。
通用网页数据
网页是大语言模型训练语料中最主要的数据来源,包含了丰富多样的文本内容,例如新闻报道、博客文章、论坛讨论等,这些广泛且多元的数据为大语言模型深入理解人类语言提供了重要资源。下面介绍重要的网页数据资源。
通用网页数据,首先介绍面向各种语言(主要以英文为主)的通用网页数据集合。
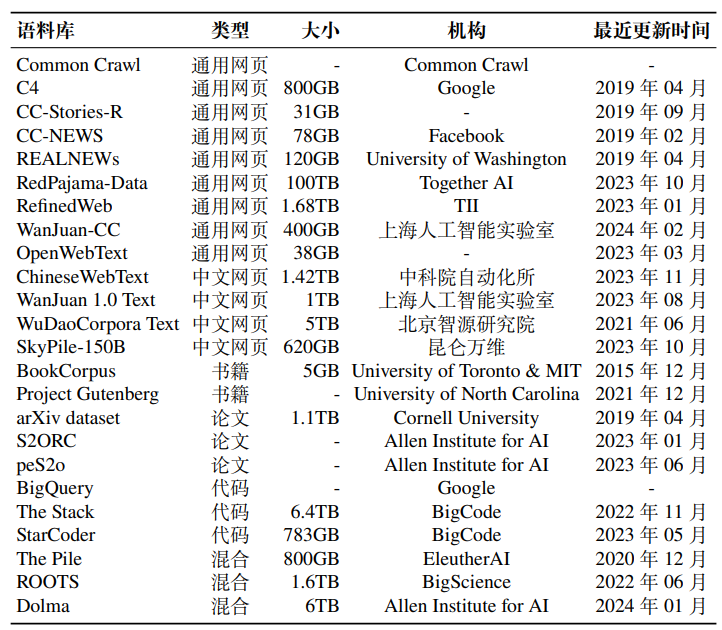
Common Crawl,该数据集是一个规模庞大的、非结构化的、多语言的网页数据集,其时间跨度很长,从 2008 年至今一直在定期更新,包含原始网页数据、元数据和提取的文本数据等,总数据量达到 PB 级别。由于这个数据集规模过于庞大,现有的研究工作主要提取其特定时间段或者符合特殊要求的子集进行使用,后文也将介绍多个基于 Common Crawl 的网页数据集。值得注意的是,该数据集内部充斥着大量的噪声和低质量数据,在使用前必须进行有效的数据清洗,以确保数据质量和准确性,常用的自动清洗工具有 CCNet 等。
C4(Colossal Clean Crawled Corpus),该数据集是一个大型网页数据集,源自超过 365M 个互联网域,包含超过 156B 词元,数据量约 800GB。该数据集基于 2019 年 4 月的 Common Crawl 语料构建,已经被公开发布,使用该数据集的典型模型有 UL2 和 LLaMA。此外,该数据集针对不同需求,发布了多个子版本:en(英文数据,806G),en.noclean(未清洗的原始数据,6T),realnewslike(仅包含 Real News 涉及的领域的内容,36G),webtextlike(仅包含来自 Open WebText 中URLs 的内容,17G)和 multilingual (多语言数据,38T)。
CC-Stories,该数据集是一个专为常识推理和语言建模构建的故事风格数据集,数据来源是 Common Crawl 中与常识推理任务问题有高度重叠的文档,总共包含约 5.3B 个词元,数据量约 31GB。CC-Stories 的原始来源现在无法访问,只有复现版本 CC-Stories-R 可供使用。使用该数据集训练的代表性模型包括 Megatron Turing NLG 等。
CC-News,该数据集是一个新闻文章数据集,数据量约 76GB,包含了 从 2016 年 9 月到 2019 年 2 月期间抓取的 63M 篇英文新闻文章,并以网页存档(WARC)文件形式提供,在 Hugging Face 上可以进行下载。
REALNEWs,该数据集是一个从 Common Crawl 中抓取的大型新闻语料 库,覆盖了谷歌新闻索引的 5,000 个新闻领域,数据量约为 120GB,可从 Open-DataLab 上进行下载。该数据集按照时间顺序进行了训练集和测试集的划分,其中2016 年 12 月至 2019 年 3 月的新闻划分为训练数据,2019 年 4 月的新闻划分为测试数据。
RedPajama-Data,该数据集是一个公开的综合网页数据集,包含了来自 Common Crawl 的 100B 份文档,其使用了 CCNet 工具进行清洗,在经过过滤和去重得到约 30T 词元,在 Hugging Face 上提供了公开下载。该数据集是一个多语言数据集,包含 5 种语言:英语、法语、西班牙语、德语和意大利语。此外,还提供了 40 余种预先标注好的数据注释,使下游模型开发者能够根据自己的标准对数据集进行筛选或重新加权。该数据集仍在不断更新维护,所有的数据处理脚本均在GitHub 开源,方便用户使用。
RefinedWeb,该数据集是一个在 Common Crawl 数据的基础上通过严格筛选和去重得到的网络数据集,使用的源数据是从 2008 年到 2023 年 6 月的所有Common Crawl 网页记录,共约 5T 词元。其中,开源部分有 600B 词元,数据量约500GB,解压后需要 2.8TB 的本地存储空间,可从 Hugging Face 上下载。该数据集是开源大语言模型 Falcon 的主要训练数据集。
WanJuan-CC(万卷 CC),该数据集是一个从 Common Crawl 数据中抽取并清洗的高质量英文数据集。首批开源的语料覆盖了过去十年内互联网上的公开内容,包含 100B 词元,构成约 400GB 的高质量数据。在数据清洗过程中,发布人员搭建了高性能分布式数据处理系统,通过启发式规则过滤、多层级数据去重、内容安全过滤、数据质量过滤等四个步骤,最终从约 130B 份原始数据文档中萃取出约 1.38% 的高质量内容。上海人工智能实验室发布的 InternLM2就是以 WanJuan-CC 作为关键数据进行训练。
WebText,该数据集是由 OpenAI 构建的一个专注于文档质量的网络文本语料库,它通过抓取 Reddit 上获得至少 3 个赞的外链得到。该语料库旨在捕捉用户认为有趣、有教育价值或幽默的内容,使用的数据是 2017 年 12 月之前的数据,包括了来自 45M 个链接的文本内容,共计超过 8M 份文档,文本总量达到 40GB。OpenAI 在一系列模型的训练过程中,都是使用了该数据集,包括 GPT-2、GPT-3和 InstructGPT 等。遗憾的是,WebText 并未开源。
中文网页数据
在上述网页数据集中,中文网页占比通常非常低。为了训练具有较好中文语言能力的大语言模型,通常需要专门收集与构建中文网页数据集合。
ChineseWebText,该数据集是从 Common Crawl 庞大的网页数据中精心筛选的中文数据集。该数据集汇集了 2021 年至 2023 年间的网页快照,总计 1.42TB数据量。同时,ChineseWebText 的每篇文本都附有一个定量的质量评分,为研究人员提供了可用于筛选与使用的参考标准。此外,为满足不同研究场景的需求,ChineseWebText 还特别发布了一个 600GB 大小的中文数据子集,并配套推出了一款名为 EvalWeb 的数据清洗工具,方便研究人员根据需求清洗数据。
WanJuan 1.0 Text,该数据集是上海人工智能实验室发布的万卷 1.0 多模态语料库的一部分(除文本数据集外,还有图文数据集和视频数据集)。该文本数据集由多种不同来源的数据组成,包括网页、书籍等,数据总量约 500M 个文档,数据大小超过 1 TB。在数据处理过程中,该语料将多种格式的数据进行了统一,并进行了细粒度的清洗、去重,提升了语料的纯净度。该数据集被用于 Intern Multimodal 和 Intern Puyu 的训练,完整数据集可在 Opendatalab 上进行下载。
WuDaoCorpora Text,该数据集是北京智源研究院构建的“悟道”项目数据集的一部分(除文本数据集外,还有多模态图文数据集和中文对话数据集)。该文本数据集来源于100TB 高质量原始网页数据,其中还包含教育、科技等超过 50 个行业数据标签,经过清洗、隐私数据信息去除后剩余 5TB,而开源部分有 200GB。
SkyPile-150B,该数据集是一个大规模的综合中文数据集,数据来源于公开可获取的中文网页,其公开部分包含大约 233M 个网页,总共包含约 150B 个词元,620GB 的纯文本内容。为了确保数据质量,该数据集进行了严格的过滤、去重以及隐私数据的清除。此外,还使用了 fastText 等工具进一步筛除低质量数据。该数据集被用于训练 Skywork 模型。
书籍
书籍是人类知识与文化的重要载体,已经成为了重要的预训练数据源之一。书籍内容主要是长文本形式表达,能够帮助语言模型学习语言的长程依赖关系,并深入理解语言的内在逻辑与表达习惯。通常来说,书籍的语言表达更为严谨,整体上相对质量较高,并且能够覆盖多元化的知识体系。需要注意的是,书籍通常都是有着较为严格的版权限制,使用者需要按照版权的要求来判断是否能够使用某一书籍用于训练。目前,常用的书籍数据集包括下述几个数据集合。
BookCorpus,该数据集是一个免费小说书籍集合,包含了 11,038 本未出版书籍(大约有 74M 句子和 1B 个单词),涵盖了 16 种不同的主题类型(如浪漫、历史、冒险等),本地存储大概需要 5GB 左右。该数据集常被用于训练小规模的模型,如 GPT 和 GPT-2。同时,BooksCorpus 也被 MT-NLG 和 LLaMA 等模型所使用。该数据集原始数据集不再公开,但多伦多大学创建了一个镜像版本 BookCorpusOpen,可在 Hugging Face 上进行下载,该版本包含了共计 17,868 本书籍,本地存储大概需要 9GB 左右。至于在 GPT-3 中使用的 Books1和Books2数据集合,比 BookCorpus 规模更大,但目前也尚未对外公开。
Project Gutenberg,这是一个拥有 70K 部免费电子书的在线图书馆,目前还在持续更新中。主要收录了西方文学作品,包括小说、诗歌、戏剧等,大部分作品以纯文本形式提供,也有一些非文本内容例如音频和乐谱。收录中大部分作品为英语,也涵盖了法语、德语等多种语言,用户可以在其官方网站免费下载需要使用的电子书。
arXiv Dataset,arXiv 是一个收录了众多领域预印本论文的网站。为了更好地方便研究工作的使用,arXiv 官方在其网站上发布了一个机器可读的 arXiv 论文数据集,广泛涵盖了物理、数学和计算机科学等领域的论文文献,共包含约1.7M 篇预印本文章,每篇预印本都包含文本、图表、作者、引文、分类以及其他元数据等信息,总数据量约为 1.1TB,并在 Kaggle 上提供了公开下载。
S2ORC,该数据集源于学术搜索引擎 Semantic Scholar 上的学术论文,这些论文经过了清洗、过滤并被处理成适合预训练的格式。S2ORC 到目前为止已发布多个版本,最初的版本包含 81M 篇公开论文,目前已更新至 136M 篇。该数据集已在 Semantic Scholar 上提供了可公开下载的版本。此外,该数据集还有一个衍生数据集 peS2o,到目前为止已发布了两个版本,其中 v2 版本共计包含了约42B 词元,并且在 Hugging Face 提供了公开下载。
维基百科
维基百科(Wikipedia)是一个综合性的在线百科全书,由全球志愿者共同编写和维护,提供了高质量的知识信息文章,涵盖了历史、科学、文化艺术等多个领域。维基百科的数据具有以下几个特点: (1)专业性:维基百科的条目通常具有良好的结构性和权威性,不仅对于各种专业术语和概念进行了阐释,还揭示了它们在不同领域的应用和联系; (2)多语性:维基百科支持的语言种类繁多,有汉语、英语、法语、德语等一共 300 多种语言,是一个宝贵的多语言平行语料库; (3)实时性:维基百科的内容目前还在不断更新,对于知识信息的实时性维护较为及时,并且会定期发布其数据库的打包副本,供研究人员获取最新数据。除了通过维基百科的官方提供的下载方式,Hugging Face 上也有相应的维基百科数据集。在实际应用中,可以根据需求选择特定时间段或特定内容的数据。例如 LLaMA 使用的是 2022 年 6 月至 8 月的维基百科数据。
代码
代码是计算机程序设计和软件开发的基础,具有高度结构化与专业性的特点。对于预训练语言模型来说,引入包含代码的数据集可以增强模型的结构化推理能力与长程逻辑关系,能够提升模型理解和生成编程语言的能力。为了收集代码数据,现有的工作主要从互联网上爬取具有开源许可的代码。两个主要来源是公共代码仓库(例如 GitHub)和代码相关的问答平台(例如 StackOverflow)。下面是几个常用于预训练的代码数据集。
BigQuery,BigQuery 是一个谷歌发布的企业数据仓库,包含了众多领域的公共数据集,如社交、经济、医疗、代码等。其中的代码类数据覆盖各种编程语言,可以作为高质量的代码预训练语料。CodeGen 抽取了 BigQuery 数据库中的公开代码数据子集构成 BIGQUERY 进行训练,以得到多语言版本的 CodeGen。
The Stack,该数据集由 Hugging Face 收集并发布,是一个涵盖了 30 种编程语言的代码数据集,其数据来源于 GHArchive 项目中 2015 年 1 月 1 日至 2022年 3 月 31 日期间的 GitHub 活跃仓库。The Stack 最初的版本经过数据筛选、过滤以及许可证检测等处理后,最终数据量约为 3TB。同时,该数据集还在不断更新中,v1.2 版本的编程语言已扩展到了 358 种,并且许可证列表也得到了扩充,以收集更多数据,目前该版本数据量约为 6TB,可以在 Hugging Face 上进行下载。
StarCoder,该数据集是 BigCode 围绕 The Stack v1.2 进一步处理得到的代码数据集,是同名模型 StarCoder 的预训练数据。在数据处理上,其根据数据量、流行度排名等因素,从 The Stack v1.2 的 358 种编程语言中筛选出了 86 种语言,同时,为了确保数据质量,该项目还对数据进行了人工抽样审核,以确认数据为人类编写的正常代码,而不是文本或自动生成的代码。此外,数据处理过程还进行了对多种文件类型的过滤,以去除低质量数据。最终数据总量约为 783GB,同样可以通过 Hugging Face 进行下载。
混合型数据集
除了上述特定类型的数据集外,为了便于研发人员的使用,很多研究机构对于多种来源的数据集合进行了混合,发布了一系列包括多来源的文本数据集合。这些混合数据集往往融合了新闻、社交媒体内容、维基百科条目等各种类型的文本,减少了重复清洗数据、选择数据的繁重工程。
The Pile,该数据集是一个大规模、多样化且可公开下载的文本数据集, 由超过 800GB 的数据组成,数据来源非常广泛,包括书籍、网站、代码、科学论文和社交媒体数据等。该数据集由 22 个多样化的高质量子集混合而成,包括上面提到的 OpenWebText、维基百科等,并在混合时根据数据集质量为其设定不同的权重,以增大高质量数据集的影响,最终总数据量约为 825GB。 The Pile 数据集在不同参数规模的模型中都得到了广泛应用。例如,GPT-J (6B)、CodeGen (16B) 以及 Megatron-Turing NLG (530B)。
ROOTS,该数据集是一个涵盖了 59 种不同语言的多源多语数据集。该 数据集主要由两部分组成:约 62% 的数据来源于整理好的自然语言处理数据集及相关文档、利用 Common Crawl 收集的网页数据以及 GitHub 代码数据,约 38% 的数据来源于一个网页爬虫项目 OSCAR,并对其进行了内容过滤、去重和个人信息移除。ROOTS 数据集包含了 46 种自然语言,其中英语占比最大,约为 30%;同时包含了 13 种编程语言,其中 Java、PHP 和 C++ 占比超过一半,总数据量约为1.6TB,可以从 Hugging Face 上进行下载。该数据集用于训练 BigScience Workshop 提出的 BLOOM 模型。
Dolma,该数据集也包含了多种数据源,包括来自 Common Crawl 的网络文本、Semantic Scholar 学术论文、GitHub 代码、书籍、Reddit 的社交媒体帖子以及维基百科数据,由来自大约 200TB 原始文本的 3T 个词元组成。在 Dolma 的处理过程中,发布团队同时创建了一个高性能工具包,实现了四种常用的数据清洗和过滤方法:语言过滤、质量过滤、内容过滤以及去重。同时,Dolma 仍在不断更新中,目前 v1.6 的版本文件大小约为 5.4TB,可以在 Hugging Face 上进行下载。AI2 研究院基于 Dolma 数据集训练并发布了 OLMo,这是一个提供了完整的训练数据、代码、模型参数等资源的大语言模型。