原文地址:three-considerations-for-private-open-source-llm-instances
2024 年 4 月 29 日
在生产应用中使用商业 LLM APIs 会带来明确且经过充分研究的风险。因此,企业越来越多地转向利用开源的私有托管LLM实例,并通过RAG技术进行增强。
介绍
最近发表了三篇论文,所有论文都讨论了有关大型语言模型(LLM)的非常相似的观察结果。
这一观察围绕着模型不仅经历模型漂移而且随着时间的推移性能下降的问题。
因此,依赖于商业 LLM APIs 的生成式应用程序 (Gen-Apps) 和基于 LLM 的会话式 UI 发现自己很容易受到模型行为波动的影响。
虽然人们很容易将这些变化归因于LLMs的不确定性,但最近的研究提供了相反的证据。
这些研究表明,模型确实会随着时间的推移而发生变化,并且这些变化并不表示改进;相反,它们会导致性能下降。
在LLMs的背景下,非确定性是指模型针对相同输入生成不同输出的现象。
灾难性遗忘
最近的一项研究中引入了“灾难性遗忘”一词,描述了LLMs在接受新数据训练或针对特定任务进行微调时丢失或忽略先前获得的信息的倾向。
这种现象源于训练过程的固有局限性,训练过程通常会优先考虑最近的数据或任务而不是早期的数据或任务。
因此,模型对某些概念或知识的表示可能会恶化或被新信息覆盖,从而导致整体性能或准确性下降,特别是在需要广泛理解不同主题的任务中。
在需要持续学习或适应的场景中,此类挑战会被放大,因为随着时间的推移,模型可能很难维持平衡和全面的理解。
对LLM在持续微调过程中的灾难性遗忘(CF)的研究发现,CF普遍存在于不同LLM的持续微调中。
并且随着尺度的增加,模型在领域知识、推理和阅读理解方面的遗忘程度会更强。
该研究还指出,指令调整可能有助于缓解CF问题。
LLM 漂移
GPT-3.5 和 GPT-4 是两种广泛使用的大型语言模型 (LLM) 服务,随着时间的推移,这些模型的更新并不透明。
这项评估于2023 年 3 月和2023 年 6 月进行,涵盖了两种模型在不同任务中的版本。
GPT-3.5 和 GPT-4 的性能和行为随时间变化显着。
- GPT-4(2023 年 3 月)在识别质数与合数方面表现良好(准确率 84%),但 GPT-4(2023 年 6 月)表现不佳(准确率 51%),部分原因是跟随思路下降提示。
- 与 3 月份相比,GPT-3.5 6 月份在某些任务上有所改进。
- 与 3 月份相比,GPT-4 6 月份不太愿意回答敏感问题和民意调查问题。
- 6 月份,GPT-4 在多跳问题上表现更好,而 GPT-3.5 的表现有所下降。
- 与 3 月份相比,这两种模型在 6 月份的代码生成中都出现了更多的格式错误。
- 该研究强调了对法学硕士进行持续监控的必要性,因为他们的行为随着时间的推移而变化。
有证据表明,GPT-4 遵循用户指令的能力随着时间的推移而下降,从而导致行为漂移。
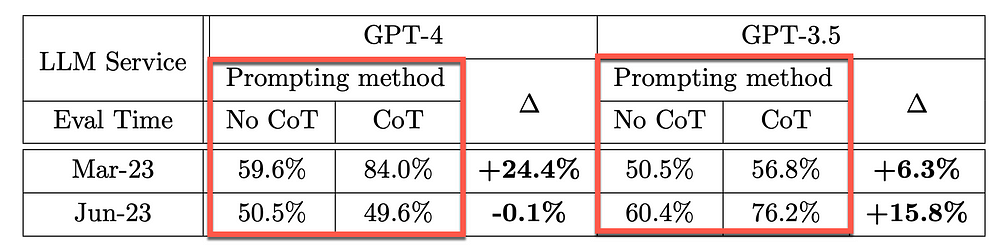
下表显示了主要测试的思想链 (CoT) 有效性随时间的变化。
来源
如果没有 CoT 提示,GPT-4 和 GPT-3.5 的准确率都相对较低。
在 CoT 的推动下,GPT-4 在 3 月份实现了24.4% 的准确率提升,6 月份则下降了-0.1%。 GPT-4 似乎确实失去了优化 CoT 提示技术的能力。
考虑到 GPT-3.5,CoT 提升从 3 月份的 6.3% 增加到 6 月份的 15.8%。
下图显示了四个月内模型准确性的波动。在某些情况下,弃用非常明显,准确率损失超过 60%。

来源
Prompt 漂移
Chaining,或也称为Prompt Chaining,是利用编程工具(在某些情况下是可视化的)来促进将大型语言模型提示链接或排序到应用程序中的过程;它主要创建一个会话式用户界面。
提示链的核心功能是将任务从一个链级联到另一个链。这种任务级联很可能会持续整个用户对话期间。
提示漂移是错误逐渐累积的过程,其原因可能是:
- 模型引发的偏离
- 问题提取不正确
- LLMs的随机性和创造性的惊喜
Chaining 可以作为模型引发偏离的保障,因为链接的每一步都定义了一个明确的目标。 ~来源
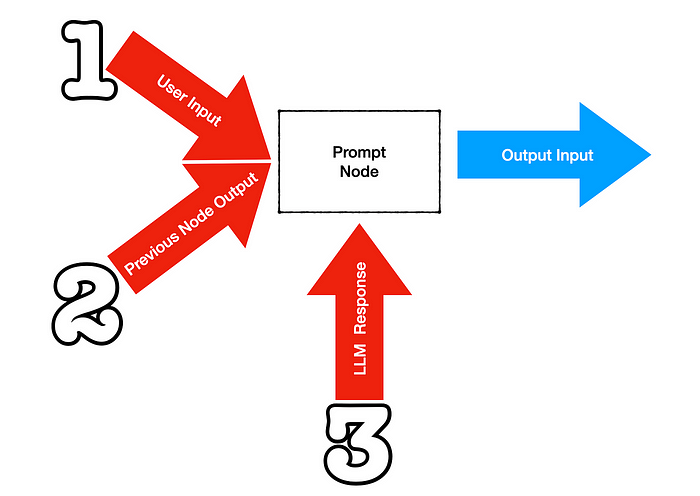
下图展示了作为更大链中一部分的单个节点或提示是如何受到影响而产生提示漂移的。
- 用户输入可能是意外的或无计划的,从而从节点产生不可预见的输出。
- 前一个节点的输出可能不准确或产生漂移,这种漂移在当前节点中会加剧。
- 由于 LLM 具有不确定性,因此 LLM 响应也可能是意外的。
应对提示漂移(错误级联)的方法之一是确保所使用的提示模板是全面的,并提供足够的上下文信息来消除 LLM 幻觉。
结束语
托管您自己的大型语言模型 (LLM) 实例可以让您对数字命运拥有无与伦比的控制权……组织可以实现高度的自主性、安全性和灵活性。
当您托管自己的 LLM 实例时,自主权占主导地位。
通过管理您的基础设施,您可以制定规则,确保您的模型根据您的特定需求和目标运行。这种自主权扩展到数据隐私和安全性,使您能够保护敏感信息并减轻与第三方依赖项相关的风险。
此外,托管您的LLMs使您能够对模型更新和优化进行精细控制。您可以定制训练数据集、微调参数并实施适合您领域的自定义算法,从而最大限度地提高性能和与应用程序的相关性。