一、说明
在快速发展的人工智能和机器学习领域,一项创新因其对我们处理、理解和生成数据的方式产生深远影响而脱颖而出:Transformers。Transformer 彻底改变了自然语言处理 (NLP) 及其他领域,为当今一些最先进的 AI 应用程序提供动力。但究竟什么是变形金刚,它们如何以如此开创性的方式转换数据?本文揭开了 Transformer 模型内部工作的神秘面纱,重点介绍了编码器架构。我们将首先在 Python 中实现 Transformer 编码器,分解其主要组件。然后,我们将可视化 Transformer 在训练期间如何处理和调整输入数据。
虽然这篇博客没有涵盖所有架构细节,但它提供了一个实现和对变形金刚变革力量的整体理解。要深入了解变形金刚,我建议您查看优秀的斯坦福 CS224-n 课程。
我还建议遵循与本文关联的 GitHub 存储库以获取更多详细信息。😊
二、什么是 Transformer 编码器架构?

Attention Is All You Need 的 Transformer 模型
这张图片显示了原始的 Transformer 架构,它结合了编码器和解码器,用于序列到序列语言任务。
在本文中,我们将重点介绍编码器架构(图片上的红色块)。这就是流行的BERT模型在引擎盖下使用的内容:主要关注点是理解和表示数据,而不是生成序列。它可用于各种应用:文本分类、命名实体识别 (NER)、抽取式问答等。
那么,这种架构实际上是如何转换数据的呢?我们将详细解释每个组件,但这里是该过程的概述。
- 输入文本被标记化:Python 字符串被转换为标记(数字)列表
- 每个标记都通过嵌入层传递,该层为每个标记输出矢量表示
- 然后,使用位置编码层对嵌入进行进一步编码,添加有关序列中每个标记位置的信息
- 这些新的嵌入由一系列编码器层使用自注意力机制进行转换
- 可以添加特定于任务的头。例如,我们稍后将使用分类头将电影评论分类为正面或负面
重要的是要理解 Transformer 架构通过将嵌入向量从高维空间中的一种表示映射到同一空间中的另一个表示,并应用一系列复杂的转换来转换嵌入向量。
三、在 Python 中实现编码器体系结构
3.1 位置编码器图层
与 RNN 模型不同,注意力机制不使用输入序列的顺序。PositionalEncoder 类使用两个数学函数(余弦和正弦)将位置编码添加到输入嵌入中。

来自 Attention Is All You Need 的位置编码矩阵定义
请注意,位置编码不包含可训练的参数:有确定性计算的结果,这使得这种方法非常容易处理。此外,正弦和余弦函数的值介于 -1 和 1 之间,并且具有有用的周期性属性,以帮助模型学习有关单词相对位置的模式。
class PositionalEncoder(nn.Module):
def __init__(self, d_model, max_length):
super(PositionalEncoder, self).__init__()
self.d_model = d_model
self.max_length = max_length
# Initialize the positional encoding matrix
pe = torch.zeros(max_length, d_model)
position = torch.arange(0, max_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2, dtype=torch.float) * -(math.log(10000.0) / d_model))
# Calculate and assign position encodings to the matrix
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.pe = pe.unsqueeze(0)
def forward(self, x):
x = x + self.pe[:, :x.size(1)] # update embeddings
return x3.2 多头自我关注
自注意力机制是编码器架构的关键组件。让我们暂时忽略“多头”。注意是一种确定每个标记(即每个嵌入)所有其他嵌入与该标记的相关性的方法,以获得更精细和上下文相关的编码。

“它”如何注意序列中的其他单词?(《变形金刚图解》))
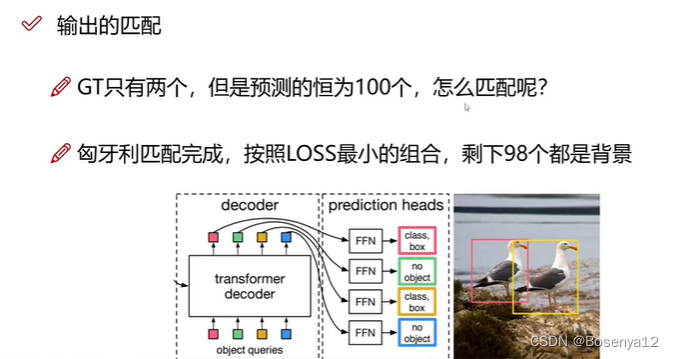
自我注意力机制有 3 个步骤。
- 使用矩阵 Q、K 和 V 分别转换输入 “query”、“key” 和 “value”。请注意,对于自注意力,query、key 和 values 都等于我们的输入嵌入
- 使用查询和键之间的余弦相似度(点积)计算注意力分数。分数按嵌入维度的平方根进行缩放,以在训练期间稳定梯度
- 使用 softmax 层使这些分数概率
- 输出是值的加权平均值,使用注意力分数作为权重
从数学上讲,这对应于以下公式。
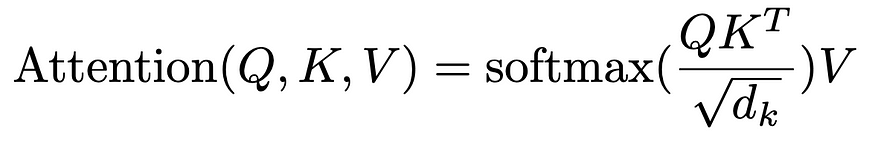
Attention Is All Your Need 中的注意力机制
“multi-head” 是什么意思?基本上,我们可以并行多次应用所描述的自我注意力机制过程,并连接和投影输出。这允许每个头在句子的不同语义方面进行讨论。
我们首先定义磁头的数量、嵌入的尺寸 (d_model) 和每个磁头的尺寸 (head_dim)。我们还初始化了 Q、K 和 V 矩阵(线性层)以及最终的投影层。
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
self.head_dim = d_model // num_heads
self.query_linear = nn.Linear(d_model, d_model)
self.key_linear = nn.Linear(d_model, d_model)
self.value_linear = nn.Linear(d_model, d_model)
self.output_linear = nn.Linear(d_model, d_model)当使用多头注意力时,我们像原始论文一样以缩小的维度(head_dim而不是d_model)应用每个注意力头,使总计算成本类似于具有全维的单头注意力层。请注意,这只是逻辑拆分。多注意力之所以如此强大,是因为它仍然可以通过单个矩阵运算来表示,这使得 GPU 上的计算非常高效。
def split_heads(self, x, batch_size):
# Split the sequence embeddings in x across the attention heads
x = x.view(batch_size, -1, self.num_heads, self.head_dim)
return x.permute(0, 2, 1, 3).contiguous().view(batch_size * self.num_heads, -1, self.head_dim)我们计算注意力分数并使用掩码来避免在填充标记上使用注意力。我们应用softmax激活来使这些分数具有概率。
def compute_attention(self, query, key, mask=None):
# Compute dot-product attention scores
# dimensions of query and key are (batch_size * num_heads, seq_length, head_dim)
scores = query @ key.transpose(-2, -1) / math.sqrt(self.head_dim)
# Now, dimensions of scores is (batch_size * num_heads, seq_length, seq_length)
if mask is not None:
scores = scores.view(-1, scores.shape[0] // self.num_heads, mask.shape[1], mask.shape[2]) # for compatibility
scores = scores.masked_fill(mask == 0, float('-1e20')) # mask to avoid attention on padding tokens
scores = scores.view(-1, mask.shape[1], mask.shape[2]) # reshape back to original shape
# Normalize attention scores into attention weights
attention_weights = F.softmax(scores, dim=-1)
return attention_weightsforward 属性执行多头逻辑拆分并计算注意力权重。然后,我们通过将这些权重乘以值来获得输出。最后,我们重塑输出并用线性层进行投影。
def forward(self, query, key, value, mask=None):
batch_size = query.size(0)
query = self.split_heads(self.query_linear(query), batch_size)
key = self.split_heads(self.key_linear(key), batch_size)
value = self.split_heads(self.value_linear(value), batch_size)
attention_weights = self.compute_attention(query, key, mask)
# Multiply attention weights by values, concatenate and linearly project outputs
output = torch.matmul(attention_weights, value)
output = output.view(batch_size, self.num_heads, -1, self.head_dim).permute(0, 2, 1, 3).contiguous().view(batch_size, -1, self.d_model)
return self.output_linear(output)3.3 编码器层
这是该架构的主要组件,它利用了多头自注意力。我们首先实现一个简单的类,通过 2 个密集层执行前馈操作。
class FeedForwardSubLayer(nn.Module):
def __init__(self, d_model, d_ff):
super(FeedForwardSubLayer, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()
def forward(self, x):
return self.fc2(self.relu(self.fc1(x)))现在,我们可以对编码器层的逻辑进行编码。我们首先对输入应用自我注意力,这给出了一个相同维度的向量。然后,我们将迷你前馈网络与层范数层一起使用。请注意,在应用规范化之前,我们还使用跳过连接。
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = FeedForwardSubLayer(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output)) # skip connection and normalization
ff_output = self.feed_forward(x)
return self.norm2(x + self.dropout(ff_output)) # skip connection and normalization3.4 把所有东西放在一起
是时候创建我们的最终模型了。我们通过嵌入层传递数据。这会将我们的原始标记(整数)转换为数值向量。然后,我们应用我们的位置编码器和几个 (num_layers) 编码器层。
class TransformerEncoder(nn.Module):
def __init__(self, vocab_size, d_model, num_layers, num_heads, d_ff, dropout, max_sequence_length):
super(TransformerEncoder, self).__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.positional_encoding = PositionalEncoder(d_model, max_sequence_length)
self.layers = nn.ModuleList([EncoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
def forward(self, x, mask):
x = self.embedding(x)
x = self.positional_encoding(x)
for layer in self.layers:
x = layer(x, mask)
return x我们还创建了一个 ClassifierHead 类,用于将最终嵌入转换为分类任务的类概率。
class ClassifierHead(nn.Module):
def __init__(self, d_model, num_classes):
super(ClassifierHead, self).__init__()
self.fc = nn.Linear(d_model, num_classes)
def forward(self, x):
logits = self.fc(x[:, 0, :]) # first token corresponds to the classification token
return F.softmax(logits, dim=-1)请注意,dense 和 softmax 层仅应用于第一个嵌入(对应于输入序列的第一个标记)。这是因为在标记文本时,第一个标记是 [CLS] 标记,它代表“分类”。[CLS] 标记旨在将整个序列的信息聚合到单个嵌入向量中,用作可用于分类任务的汇总表示。
注意:包含 [CLS] 标记的概念源自 BERT,它最初是针对下一句话预测等任务进行训练的。插入 [CLS] 标记以预测句子 B 跟随句子 A 的可能性,并使用 [SEP] 标记分隔 2 个句子。对于我们的模型,[SEP] 标记只是标记输入句子的末尾,如下所示。
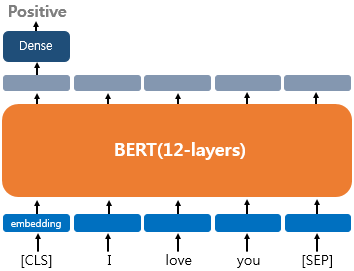
[CLS]BERT 架构中的代币(关于 AI 的一切))
仔细想想,这个单一的 [CLS] 嵌入能够捕获有关整个序列的如此多的信息,这真是令人震惊,这要归功于自注意力机制能够权衡和综合文本中每一段文本的重要性。
四、训练和可视化
希望上一节能让您更好地了解我们的 Transformer 模型如何转换输入数据。现在,我们将使用IMDB数据集(电影评论)为我们的二进制分类任务编写训练管道。然后,我们将可视化 [CLS] 令牌在训练过程中的嵌入,以了解我们的模型如何转换它。
我们首先定义超参数,以及 BERT 分词器。在 GitHub 存储库中,您可以看到我还编写了一个函数,以选择数据集的子集,其中只有 1200 个训练和 200 个测试示例。
num_classes = 2 # binary classification
d_model = 256 # dimension of the embedding vectors
num_heads = 4 # number of heads for self-attention
num_layers = 4 # number of encoder layers
d_ff = 512. # dimension of the dense layers in the encoder layers
sequence_length = 256 # maximum sequence length
dropout = 0.4 # dropout to avoid overfitting
num_epochs = 20
batch_size = 32
loss_function = torch.nn.CrossEntropyLoss()
dataset = load_dataset("imdb")
dataset = balance_and_create_dataset(dataset, 1200, 200) # check GitHub repo
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased', model_max_length=sequence_length)您可以尝试在以下句子中使用 BERT 分词器:
print(tokenized_datasets['train']['input_ids'][0])每个序列都应以标记 101 开头,对应于 [CLS],后跟一些非零整数,如果序列长度小于 256,则用零填充。请注意,在使用我们的“掩码”进行自注意力计算时,这些零被忽略。
tokenized_datasets = dataset.map(encode_examples, batched=True)
tokenized_datasets.set_format(type='torch', columns=['input_ids', 'attention_mask', 'label'])
train_dataloader = DataLoader(tokenized_datasets['train'], batch_size=batch_size, shuffle=True)
test_dataloader = DataLoader(tokenized_datasets['test'], batch_size=batch_size, shuffle=True)
vocab_size = tokenizer.vocab_size
encoder = TransformerEncoder(vocab_size, d_model, num_layers, num_heads, d_ff, dropout, max_sequence_length=sequence_length)
classifier = ClassifierHead(d_model, num_classes)
optimizer = torch.optim.Adam(list(encoder.parameters()) + list(classifier.parameters()), lr=1e-4)我们现在可以编写我们的训练函数:
def train(dataloader, encoder, classifier, optimizer, loss_function, num_epochs):
for epoch in range(num_epochs):
# Collect and store embeddings before each epoch starts for visualization purposes (check repo)
all_embeddings, all_labels = collect_embeddings(encoder, dataloader)
reduced_embeddings = visualize_embeddings(all_embeddings, all_labels, epoch, show=False)
dic_embeddings[epoch] = [reduced_embeddings, all_labels]
encoder.train()
classifier.train()
correct_predictions = 0
total_predictions = 0
for batch in tqdm(dataloader, desc="Training"):
input_ids = batch['input_ids']
attention_mask = batch['attention_mask'] # indicate where padded tokens are
# These 2 lines make the attention_mask a matrix instead of a vector
attention_mask = attention_mask.unsqueeze(-1)
attention_mask = attention_mask & attention_mask.transpose(1, 2)
labels = batch['label']
optimizer.zero_grad()
output = encoder(input_ids, attention_mask)
classification = classifier(output)
loss = loss_function(classification, labels)
loss.backward()
optimizer.step()
preds = torch.argmax(classification, dim=1)
correct_predictions += torch.sum(preds == labels).item()
total_predictions += labels.size(0)
epoch_accuracy = correct_predictions / total_predictions
print(f'Epoch {epoch} Training Accuracy: {epoch_accuracy:.4f}')可以在 GitHub 存储库中找到 collect_embeddings 和 visualize_embeddings 函数。它们存储训练集每个句子的 [CLS] 标记嵌入,应用称为 t-SNE 的降维技术使它们成为 2D 向量(而不是 256 维向量),并保存动画绘图。
让我们可视化结果。
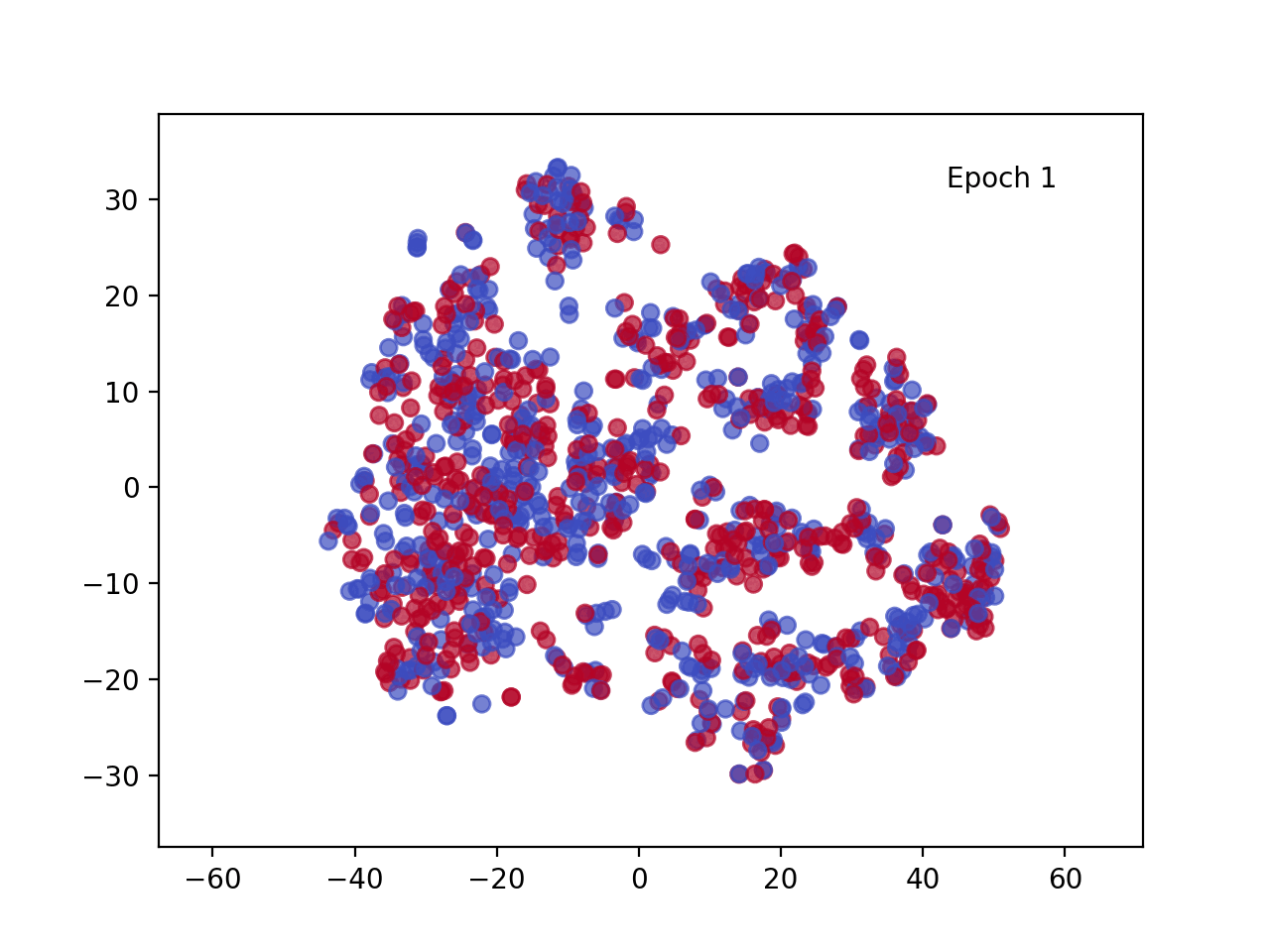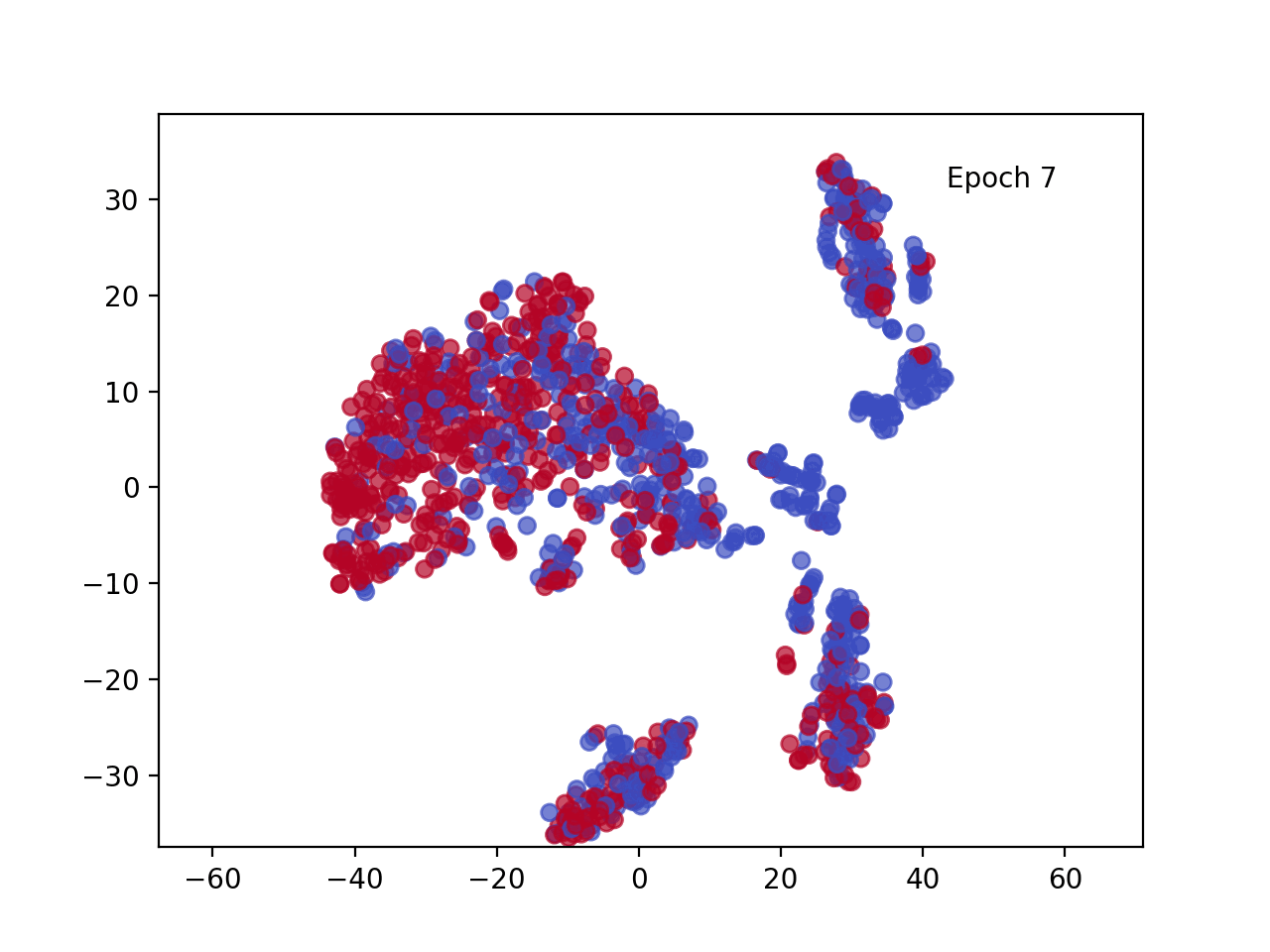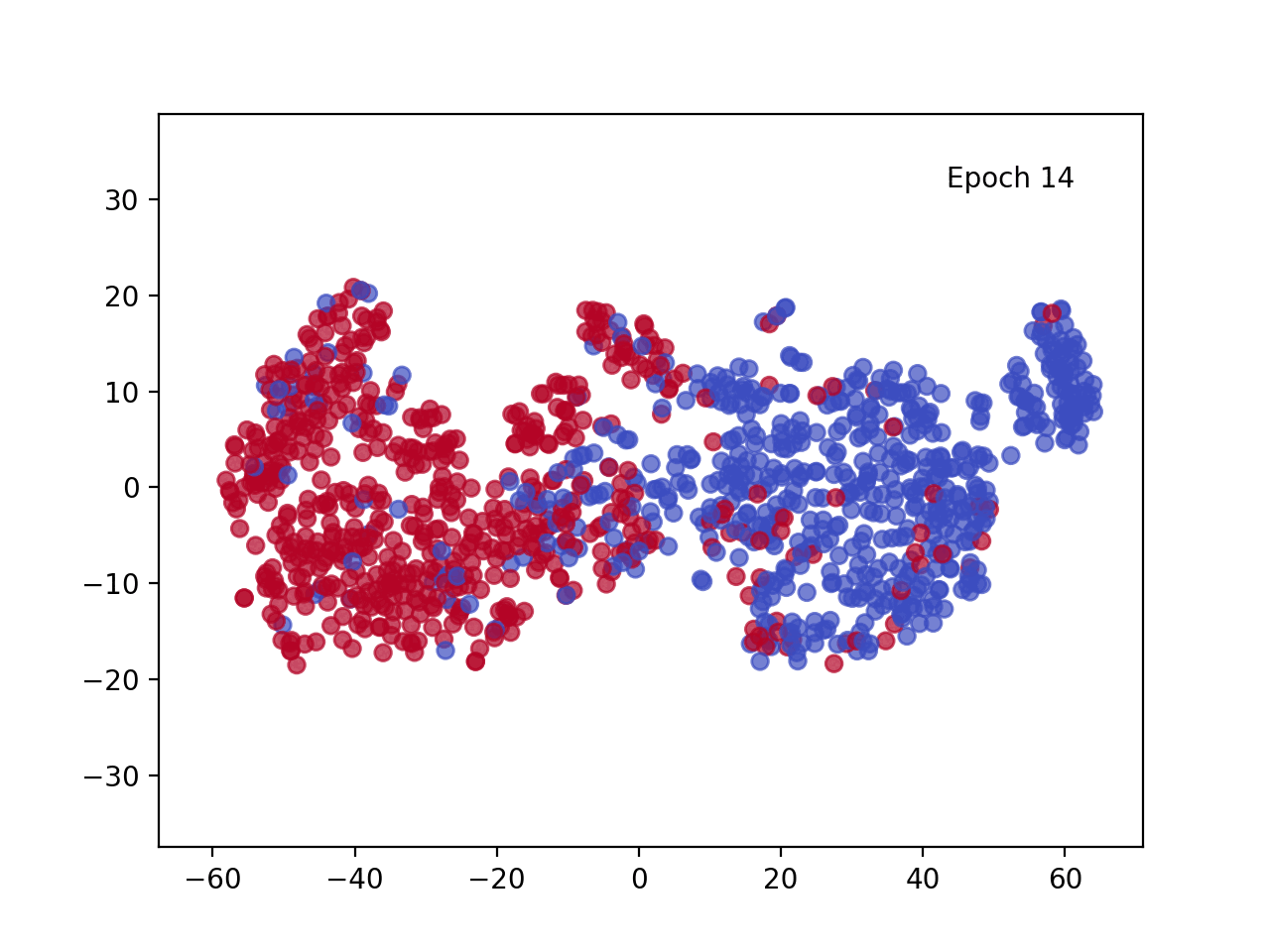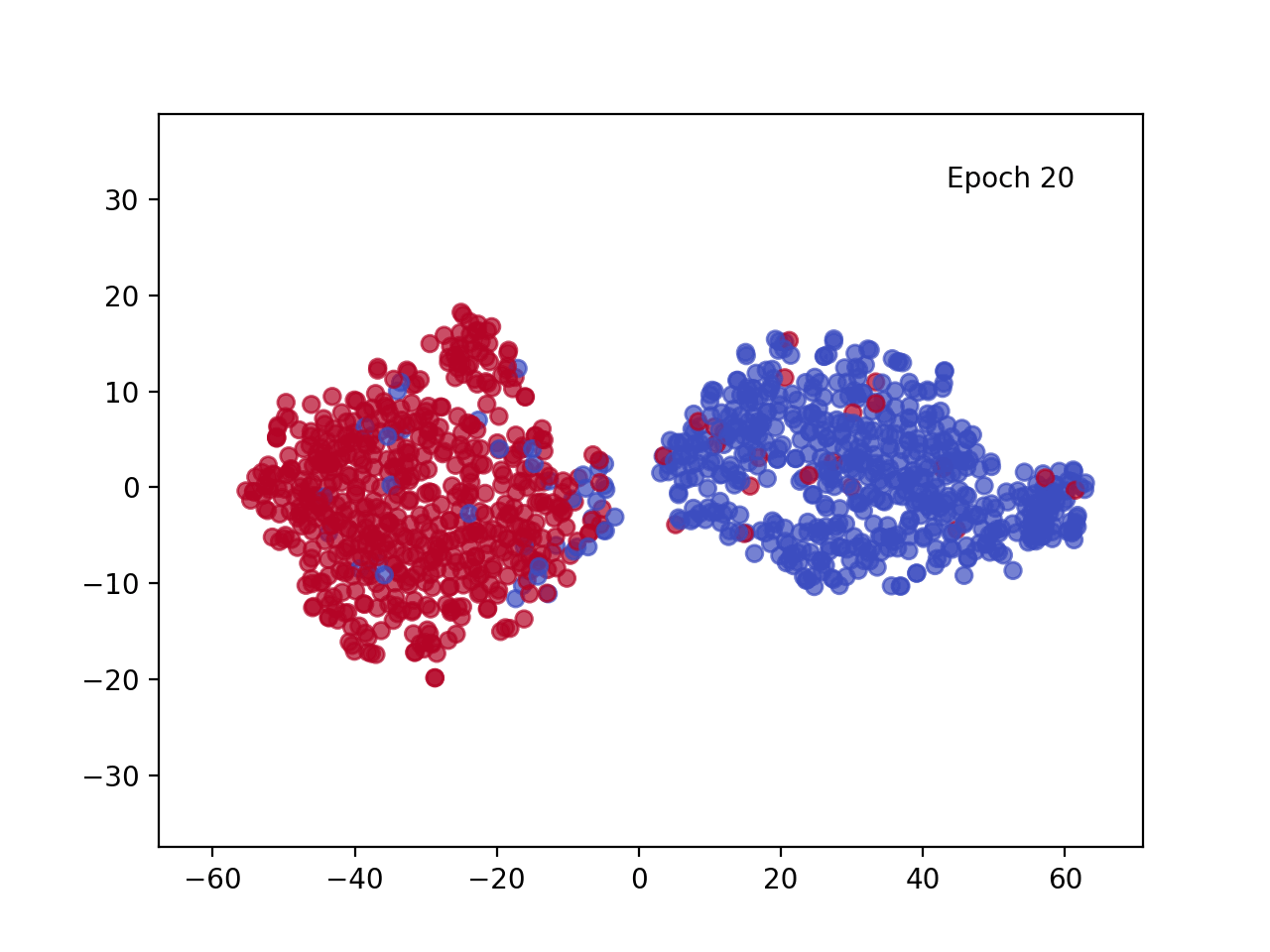
每个训练点的投影 [CLS] 嵌入(蓝色对应正句,红色对应负句)
观察每个训练点的投影 [CLS] 嵌入图,我们可以看到几个纪元后肯定(蓝色)和否定(红色)句子之间的明显区别。该视觉效果显示了 Transformer 架构随时间推移调整嵌入的卓越能力,并突出了自注意力机制的强大功能。数据的转换方式使得每个类的嵌入都很好地分离,从而大大简化了分类器头的任务。
五、结论
当我们结束对 Transformer 架构的探索时,很明显,这些模型擅长为给定的任务定制数据。通过使用位置编码和多头自注意力,变形金刚超越了单纯的数据处理:它们以前所未有的复杂程度解释和理解信息。动态权衡输入数据不同部分的相关性的能力允许对输入文本进行更细致的理解和表示。这增强了各种下游任务的性能,包括文本分类、问答、命名实体识别等。