数据库(MySQL)—— DQL语句(聚合,分组,排序,分页)
- 聚合函数
- 常见的聚合函数
- 语法
- 分组查询
- 语法
- 排序查询
- 语法
- 分页查询
- 语法
- DQL的执行顺序
我们今天来继续学习MySQL的DQL语句的聚合和分组查询,如果没看过上一篇的可以点击这里:
https://blog.csdn.net/qq_67693066/article/details/138371612
聚合函数
聚合函数将将一列数据作为一个整体,进行纵向计算。
常见的聚合函数
| 函数 | 功能 |
|---|---|
COUNT | 统计指定列或所有列的数量,返回行数 |
MAX | 返回指定列的最大值 |
MIN | 返回指定列的最小值 |
AVG | 计算指定列的平均值 |
SUM | 计算指定列的总和 |
语法
SELECT 聚合函数(字段列表) FROM 表名 ;
注意 : NULL值是不参与所有聚合函数运算的。
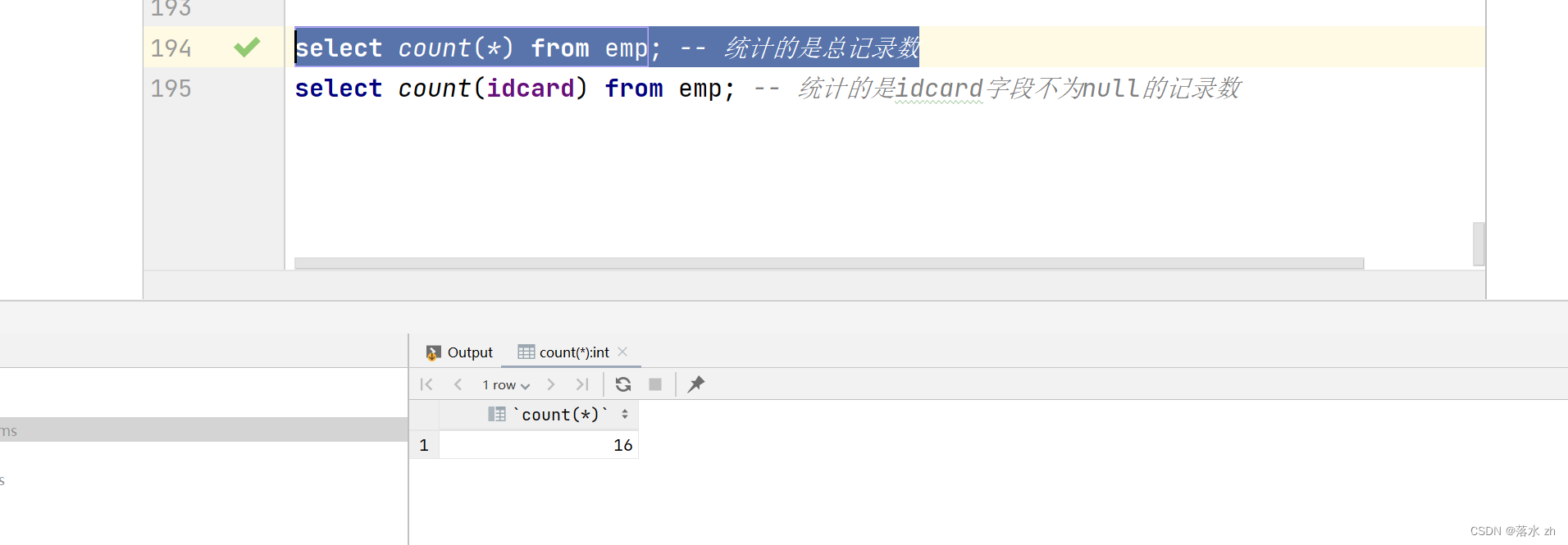
比如:统计该企业员工数量:
select count(*) from emp; -- 统计的是总记录数
select count(idcard) from emp; -- 统计的是idcard字段不为null的记录数
执行第一条语句的结果:
执行第二条语句的结果:
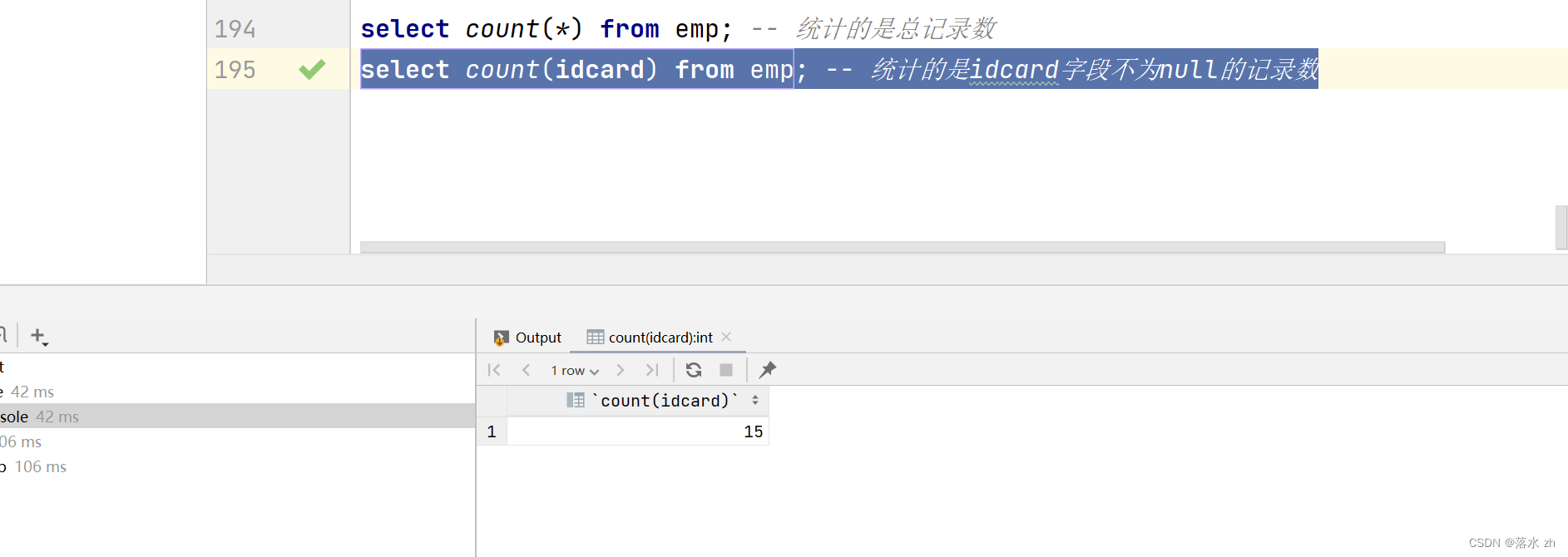
为什么会差一呢?因为有一个员工的idcard为空:
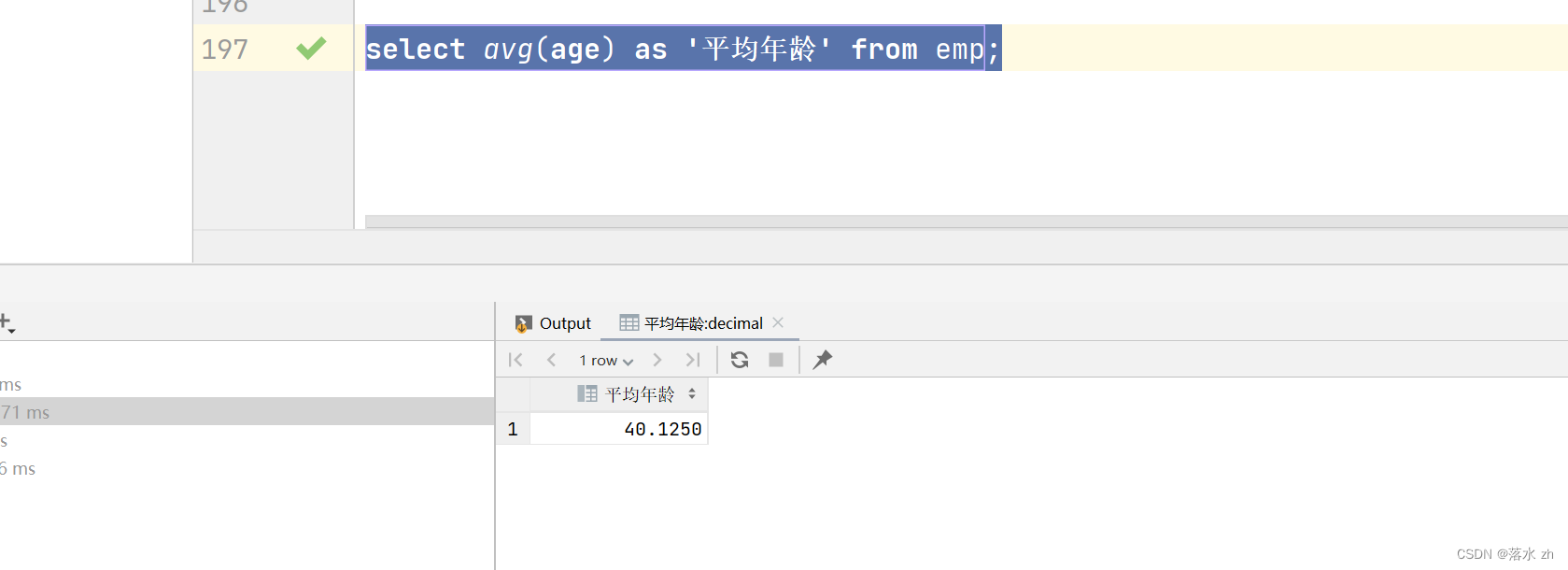
统计该企业员工的平均年龄:
select avg(age) from emp;
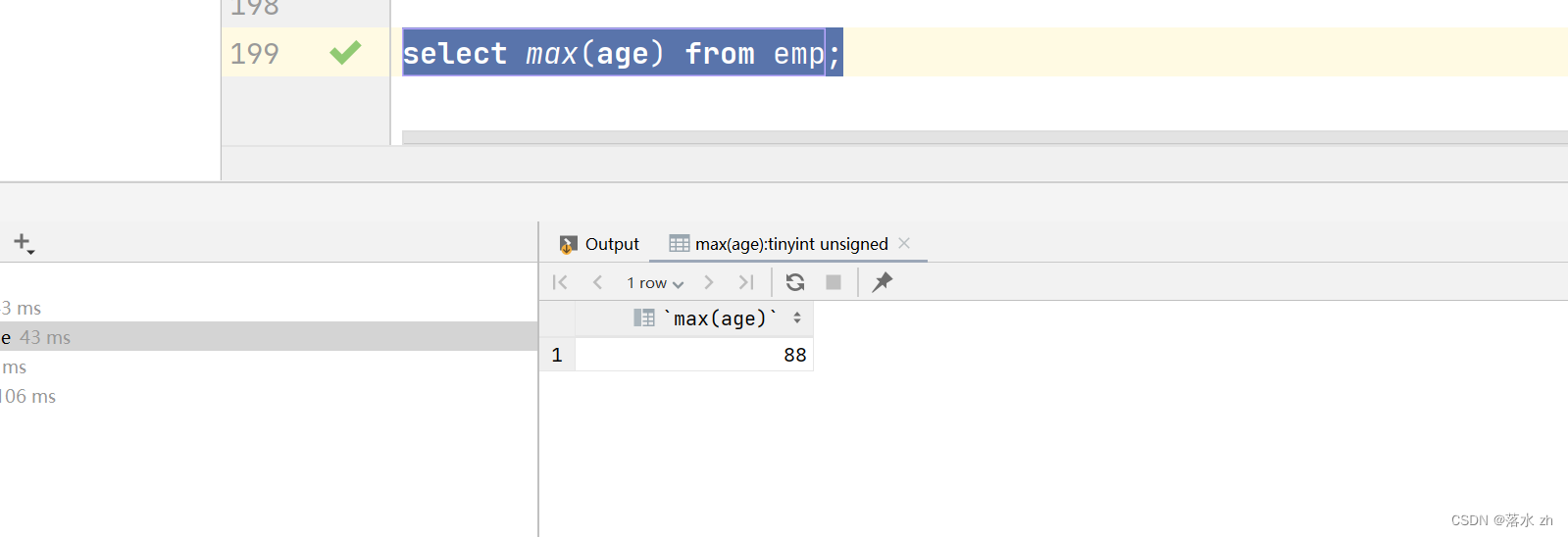
 统计该企业员工的最大年龄:
统计该企业员工的最大年龄:
select max(age) from emp;
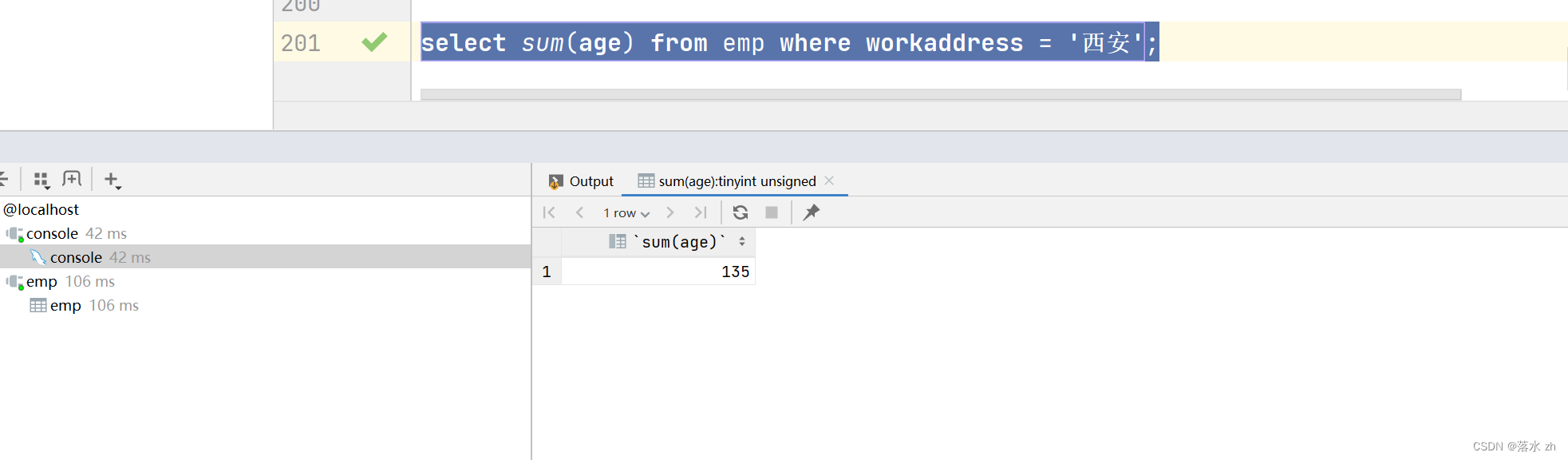
 统计西安地区员工的年龄之和:
统计西安地区员工的年龄之和:
select sum(age) from emp where workaddress = '西安';
分组查询
语法
SELECT 字段列表 FROM 表名 [ WHERE 条件 ] GROUP BY 分组字段名 [ HAVING 分组
后过滤条件 ];
where与having区别
执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组
之后对结果进行过滤。
判断条件不同:where不能对聚合函数进行判断,而having可以。
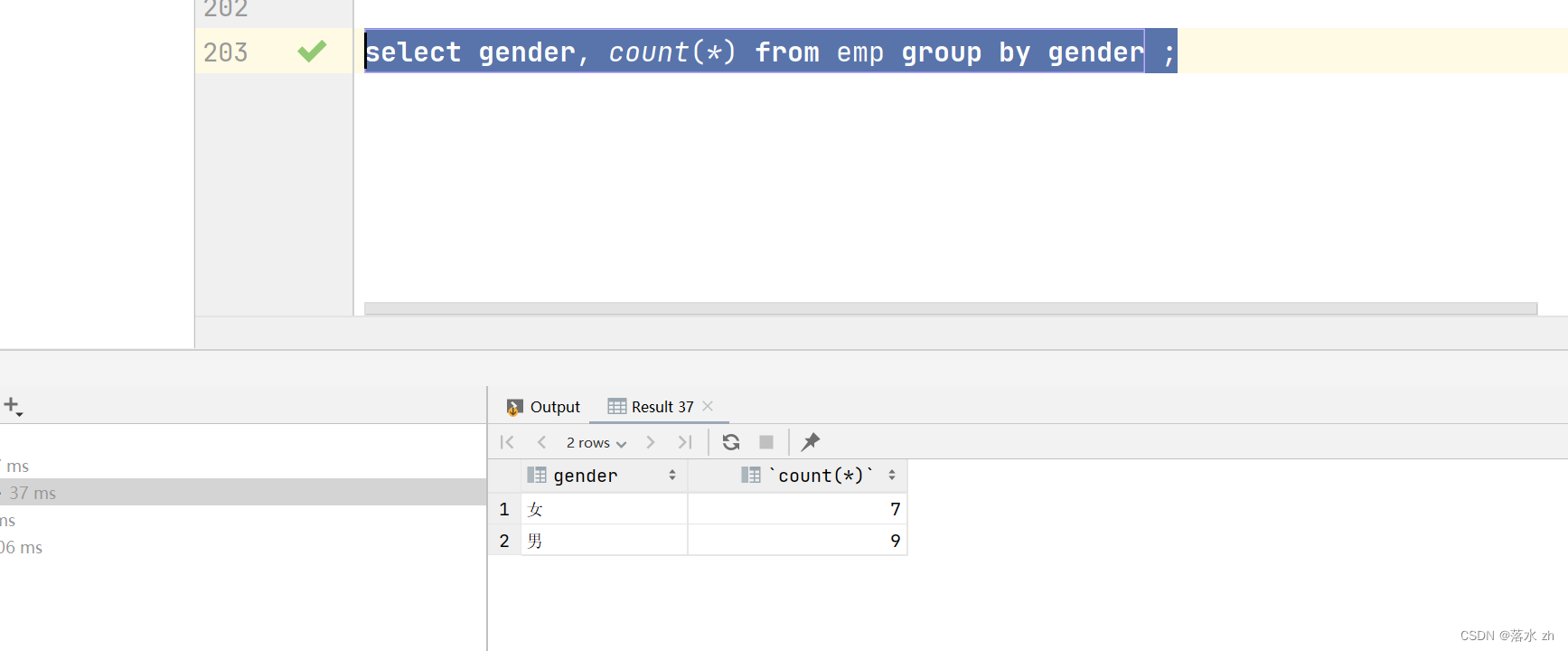
根据性别分组 , 统计男性员工 和 女性员工的数量:
-- 根据性别分组 , 统计男性员工 和 女性员工的数量
select gender, count(*) from emp group by gender ;
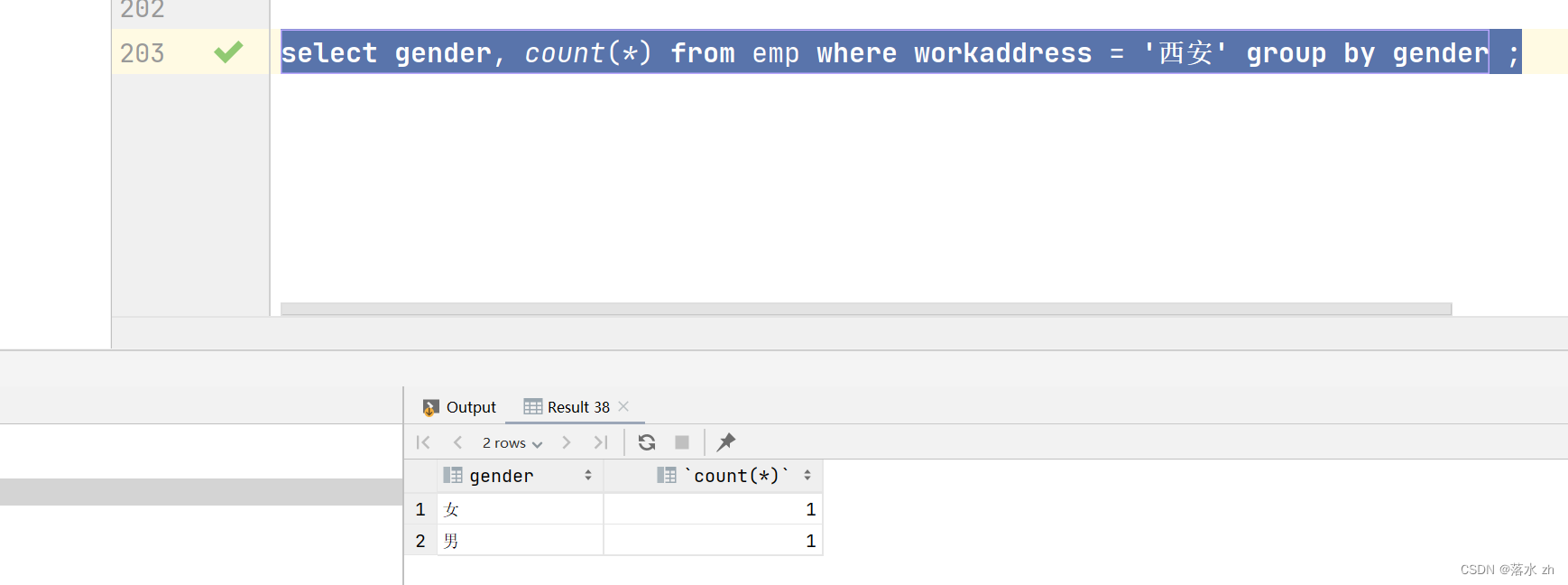
 我们可以修改一下条件:根据性别分组 , 统计在西安的男性员工 和 女性员工的数量:
我们可以修改一下条件:根据性别分组 , 统计在西安的男性员工 和 女性员工的数量:
select gender, count(*) from emp where workaddress = '西安' group by gender ;
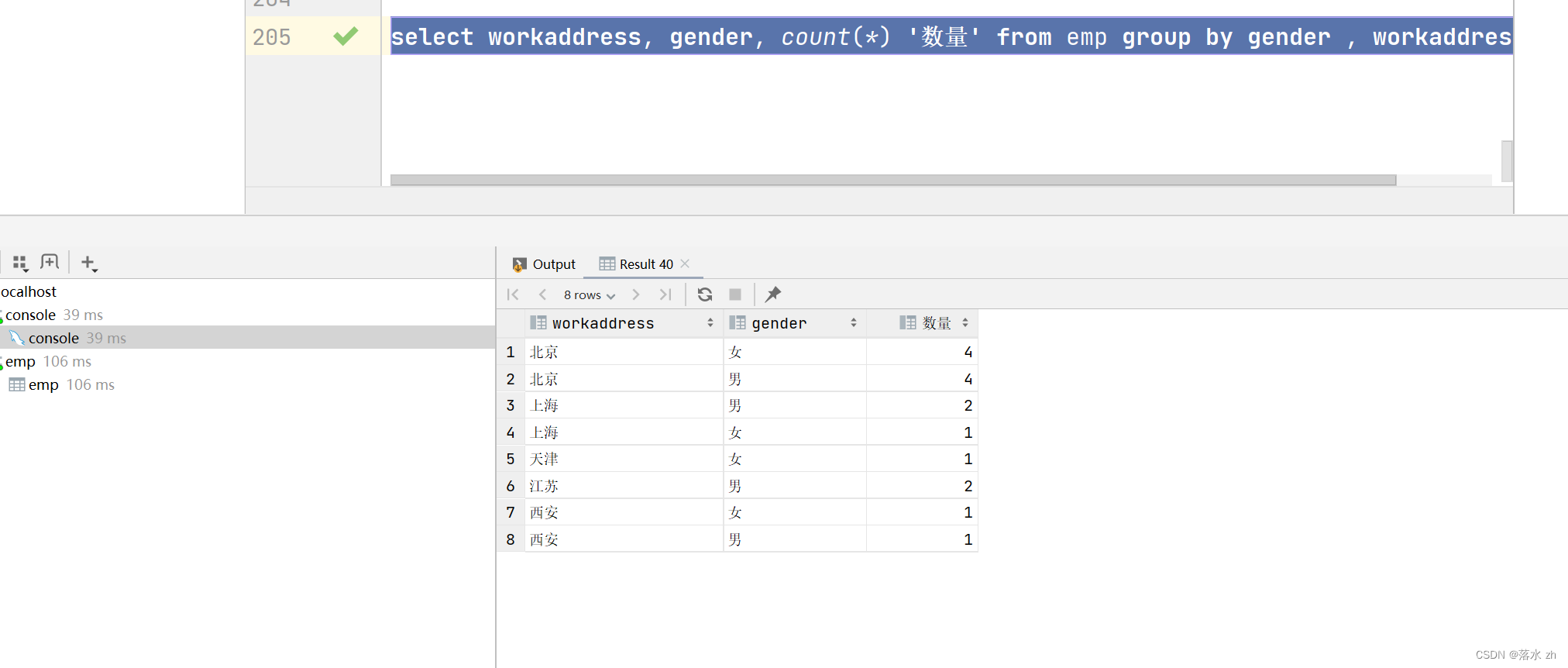
统计各个工作地址上班的男性及女性员工的数量:
select workaddress, gender, count(*) '数量' from emp group by gender , workaddress;
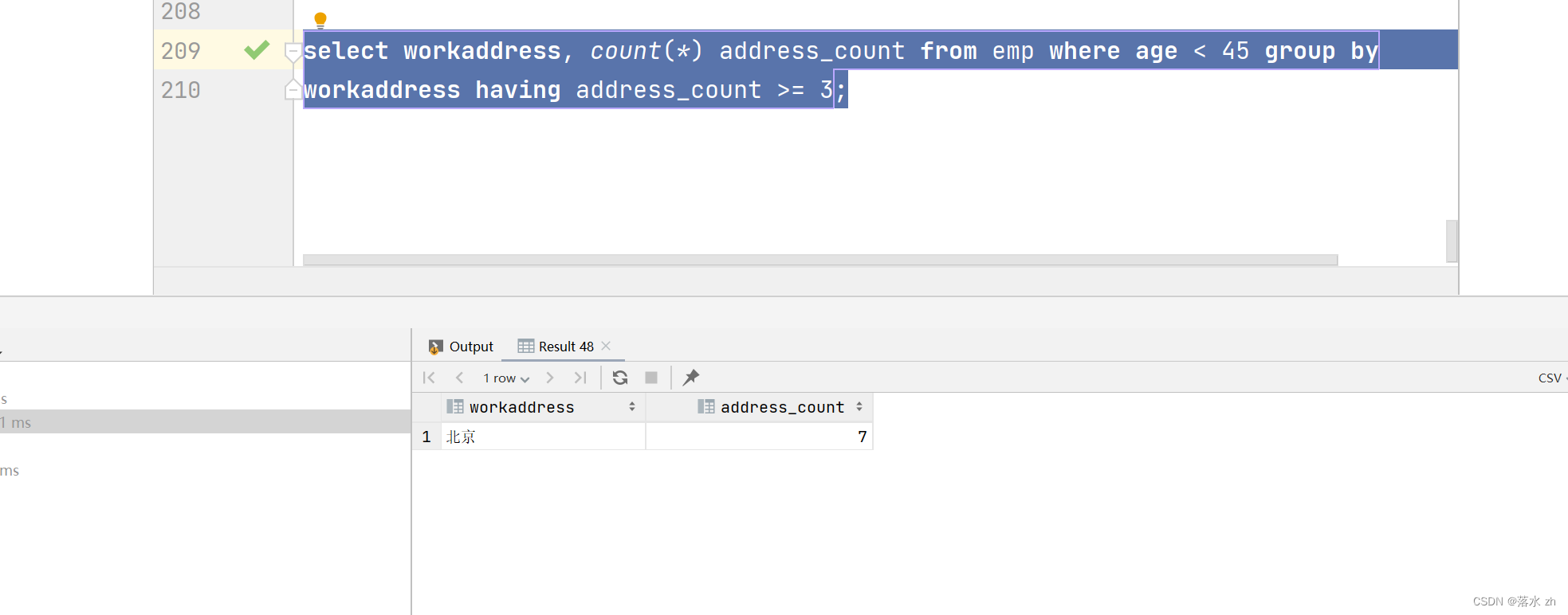
 查询年龄小于45的员工 , 并根据工作地址分组 , 获取员工数量大于等于3的工作地址:
查询年龄小于45的员工 , 并根据工作地址分组 , 获取员工数量大于等于3的工作地址:
select workaddress, count(*) address_count from emp where age < 45 group by
workaddress having address_count >= 3;
排序查询
排序在日常开发中是非常常见的一个操作,有升序排序,也有降序排序。
语法
SELECT 字段列表 FROM 表名 ORDER BY 字段1 排序方式1 , 字段2 排序方式2 ;
排序方式:
ASC : 升序(默认值)
DESC: 降序
注意事项:
- 如果是升序, 可以不指定排序方式ASC
- 如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序
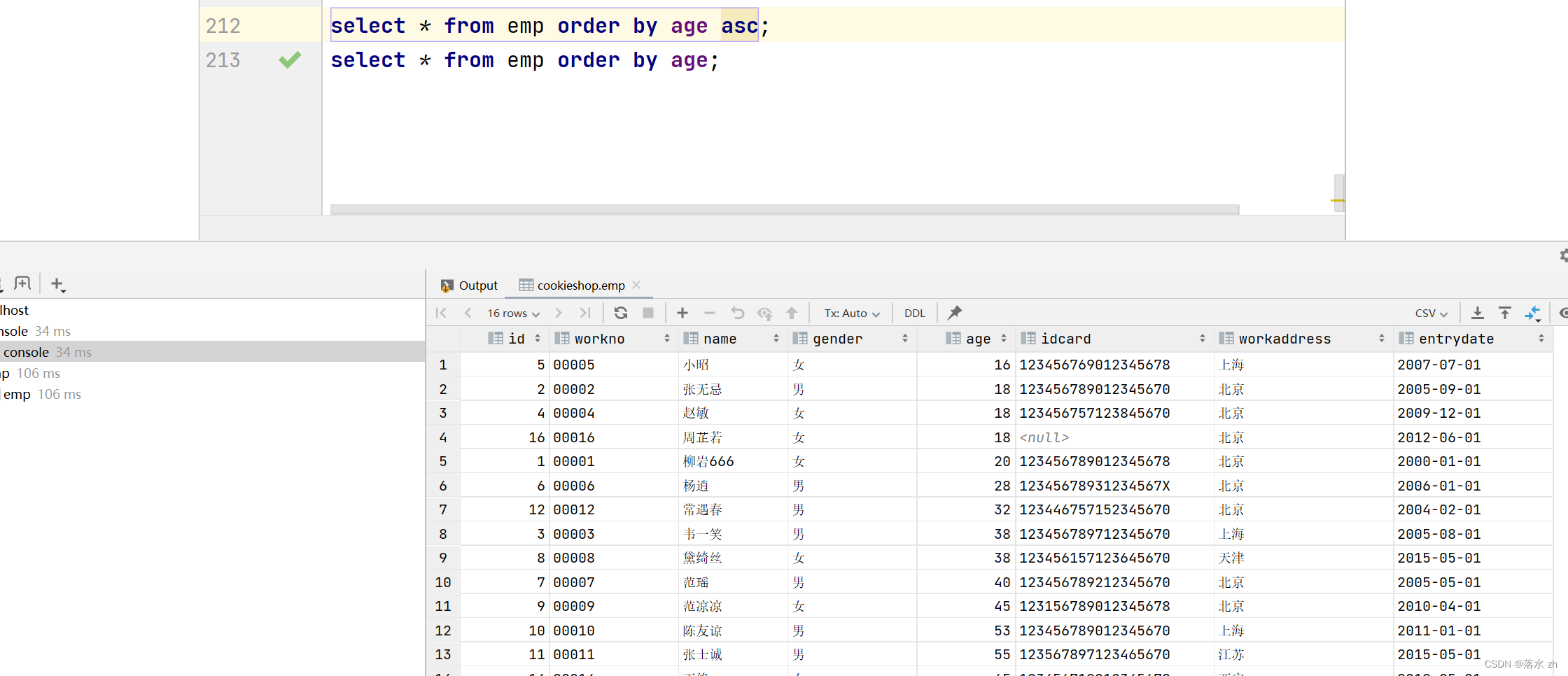
根据年龄对公司的员工进行升序排序:
select * from emp order by age asc;
select * from emp order by age;
根据入职时间, 对员工进行降序排序:
select * from emp order by entrydate desc;
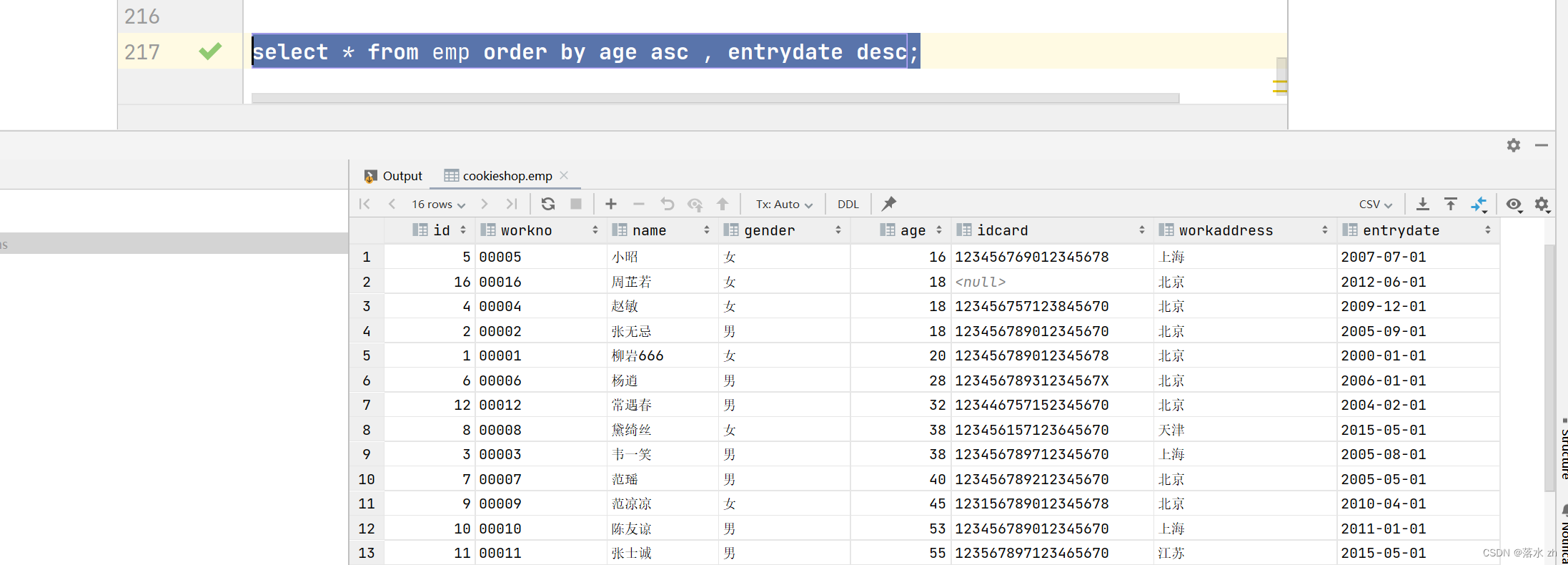
 根据年龄对公司的员工进行升序排序 , 年龄相同 , 再按照入职时间进行降序排序:
根据年龄对公司的员工进行升序排序 , 年龄相同 , 再按照入职时间进行降序排序:
select * from emp order by age asc , entrydate desc;
分页查询
分页操作在业务系统开发时,也是非常常见的一个功能,我们在网站中看到的各种各样的分页条,后台都需要借助于数据库的分页操作:
语法
SELECT 字段列表 FROM 表名 LIMIT 起始索引, 查询记录数;
注意事项:
- 起始索引从0开始,起始索引 = (查询页码 - 1)* 每页显示记录数。
- 分页查询是数据库的方言,不同的数据库有不同的实现,MySQL中是LIMIT。
- 如果查询的是第一页数据,起始索引可以省略,直接简写为 limit 10。
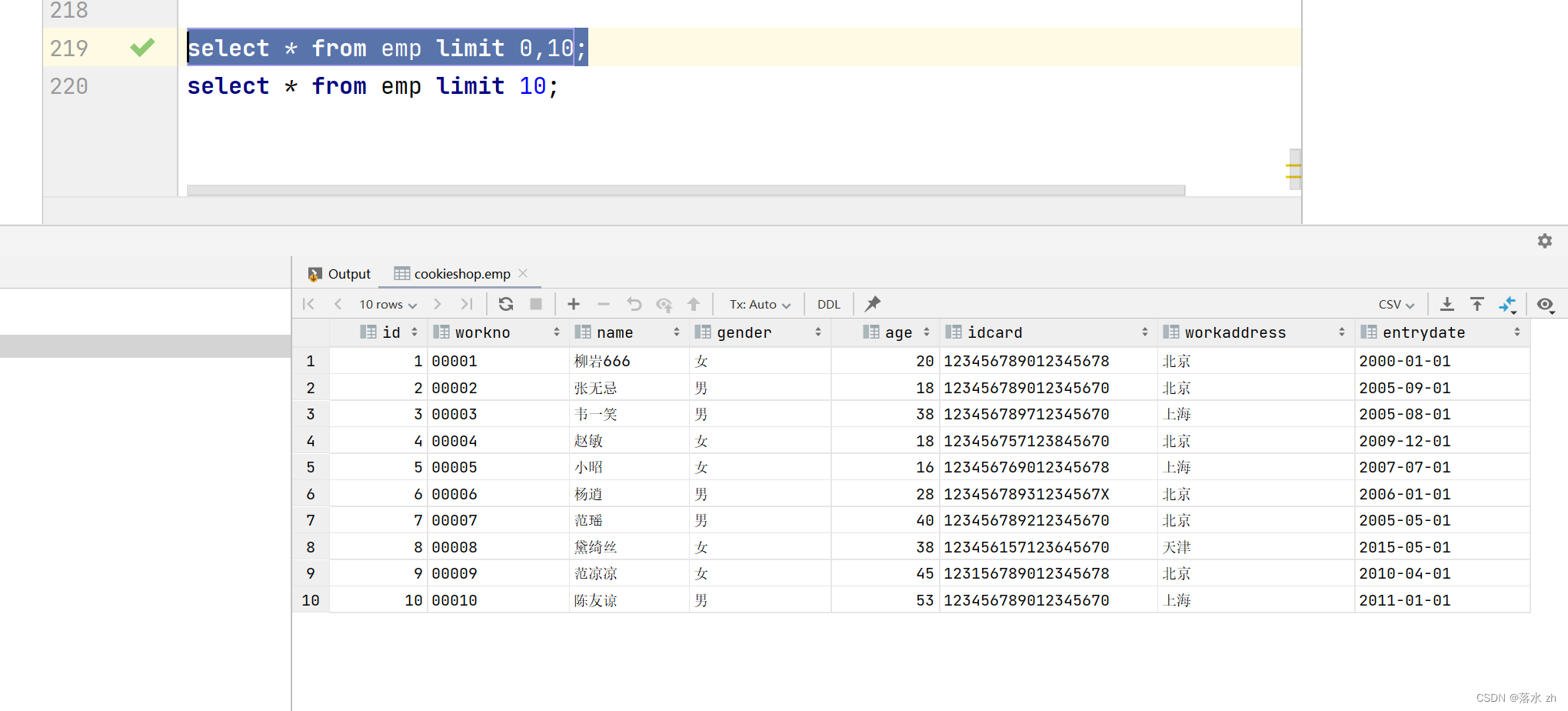
查询第1页员工数据, 每页展示10条记录:
select * from emp limit 0,10;
select * from emp limit 10;
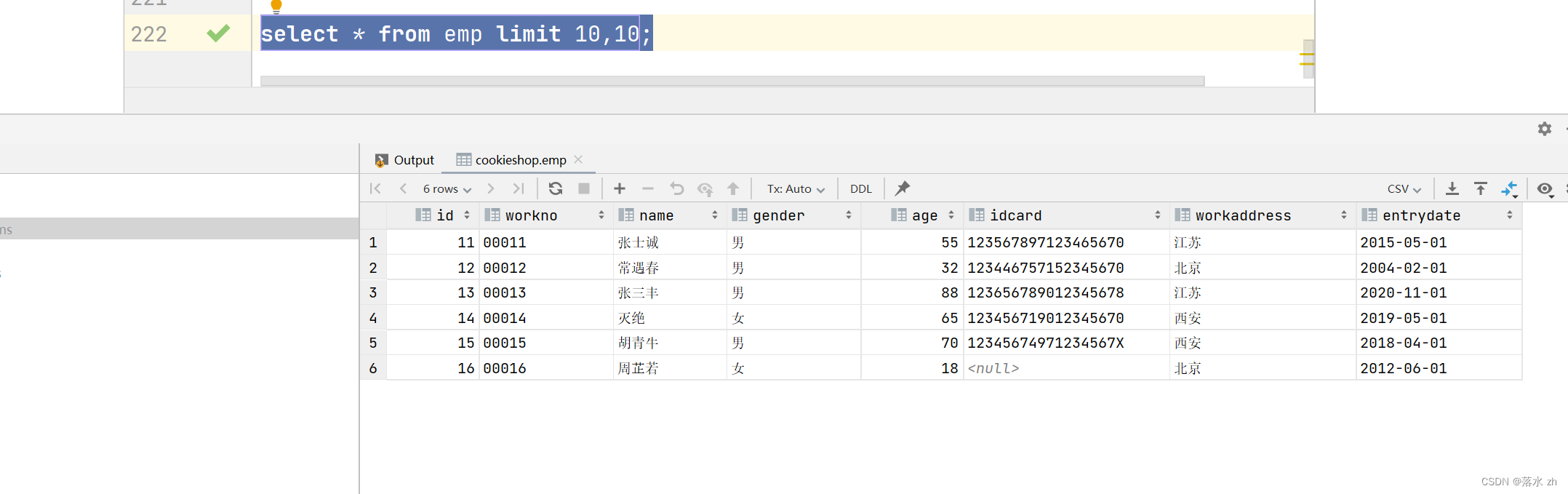
查询第2页员工数据, 每页展示10条记录 --------> (页码-1)*页展示记录数:
select * from emp limit 10,10;
DQL的执行顺序
我们之前写sql语句都只是按照编写顺序来书写的,但是实际执行的时候,并不是按照我们编写的顺序来执行的,而是有自己的执行顺序:
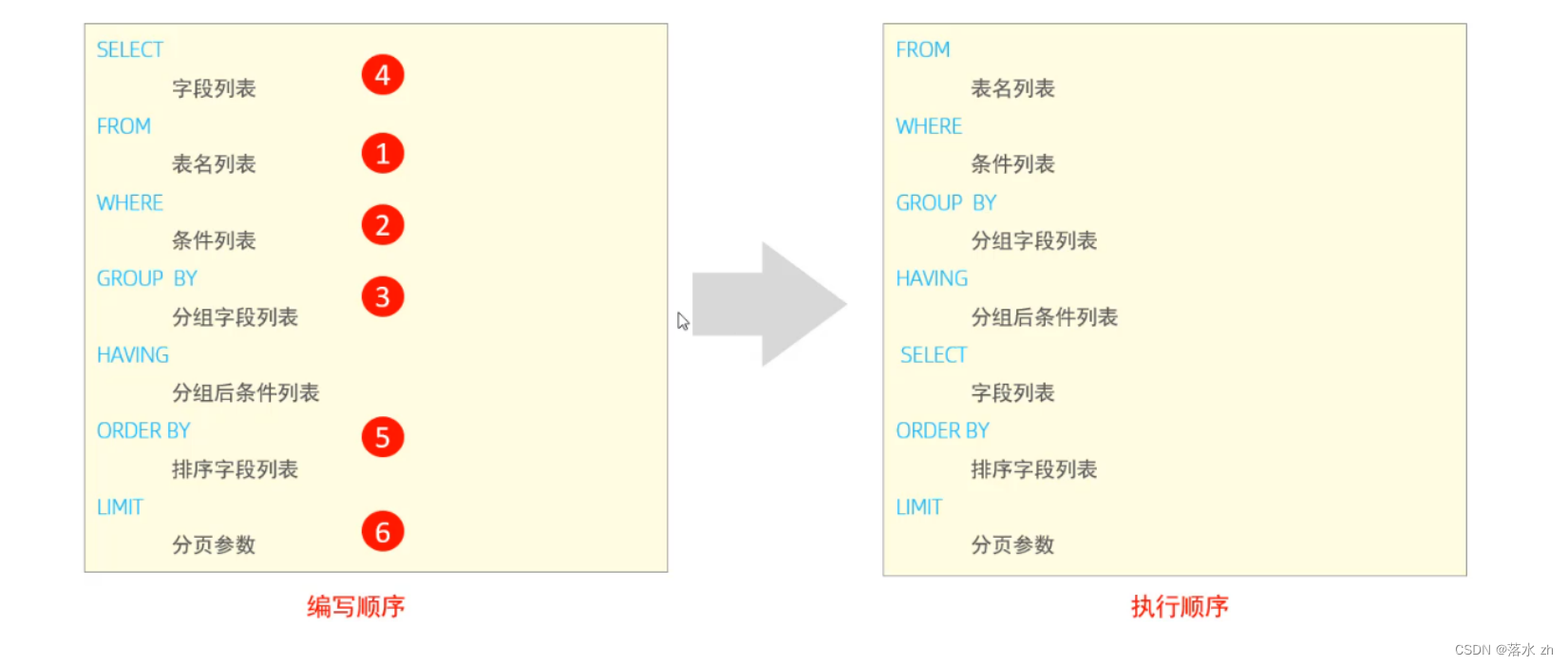
我们可以来验证一下:
查询年龄大于15的员工姓名、年龄,并根据年龄进行升序排序。
select name , age from emp where age > 15 order by age asc;
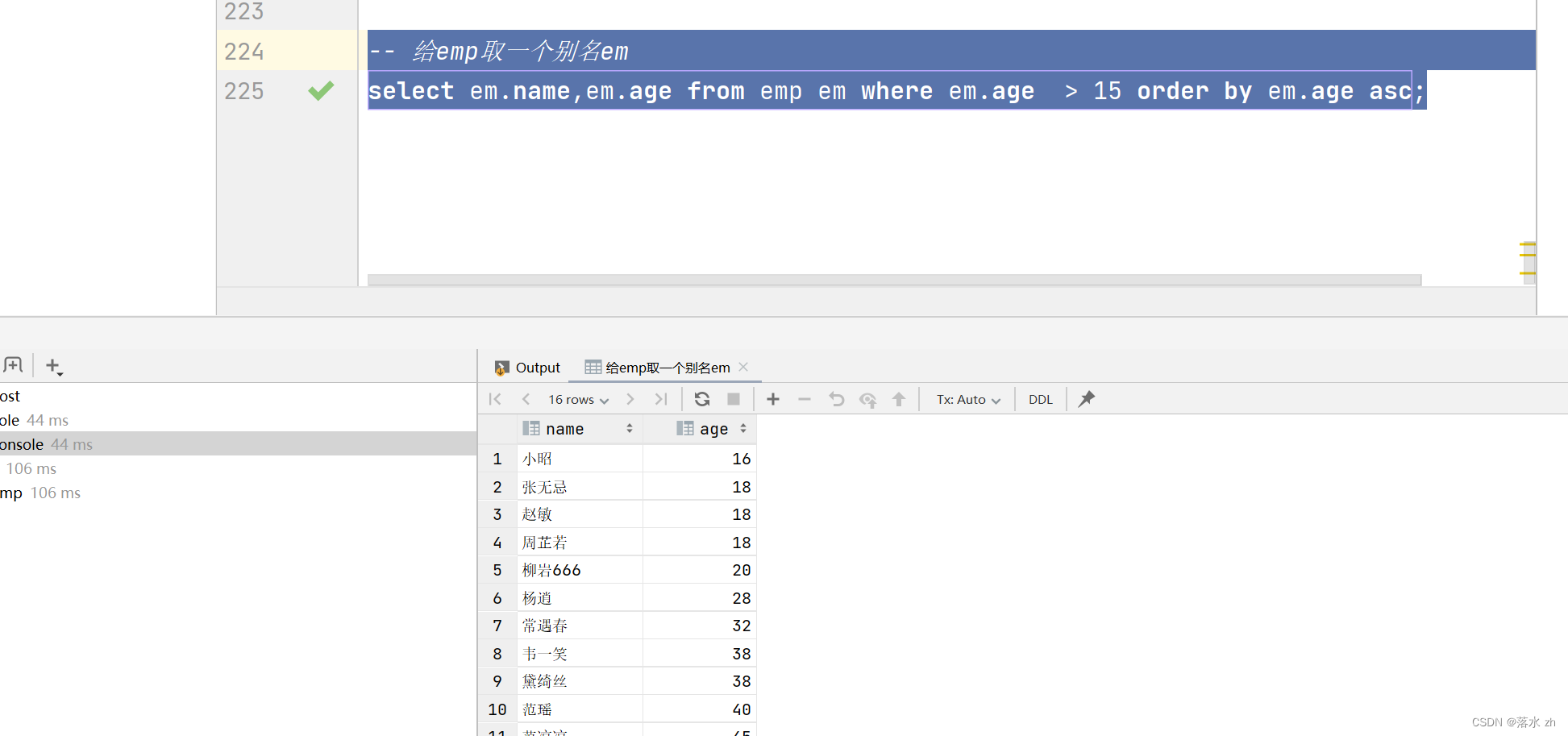
我们可以用别名来证明,现在我们对emp取个别名,因为按照逻辑,先从from开始执行:
-- 给emp取一个别名em
select em.name ,em.age from emp em where em.age > 15 order by em.age asc;
发现程序正常运行:
但是如果我们先给select中的age取了别名:

就会报错,说明select语句在from之后执行,但是如果是在order by里面使用就不会:
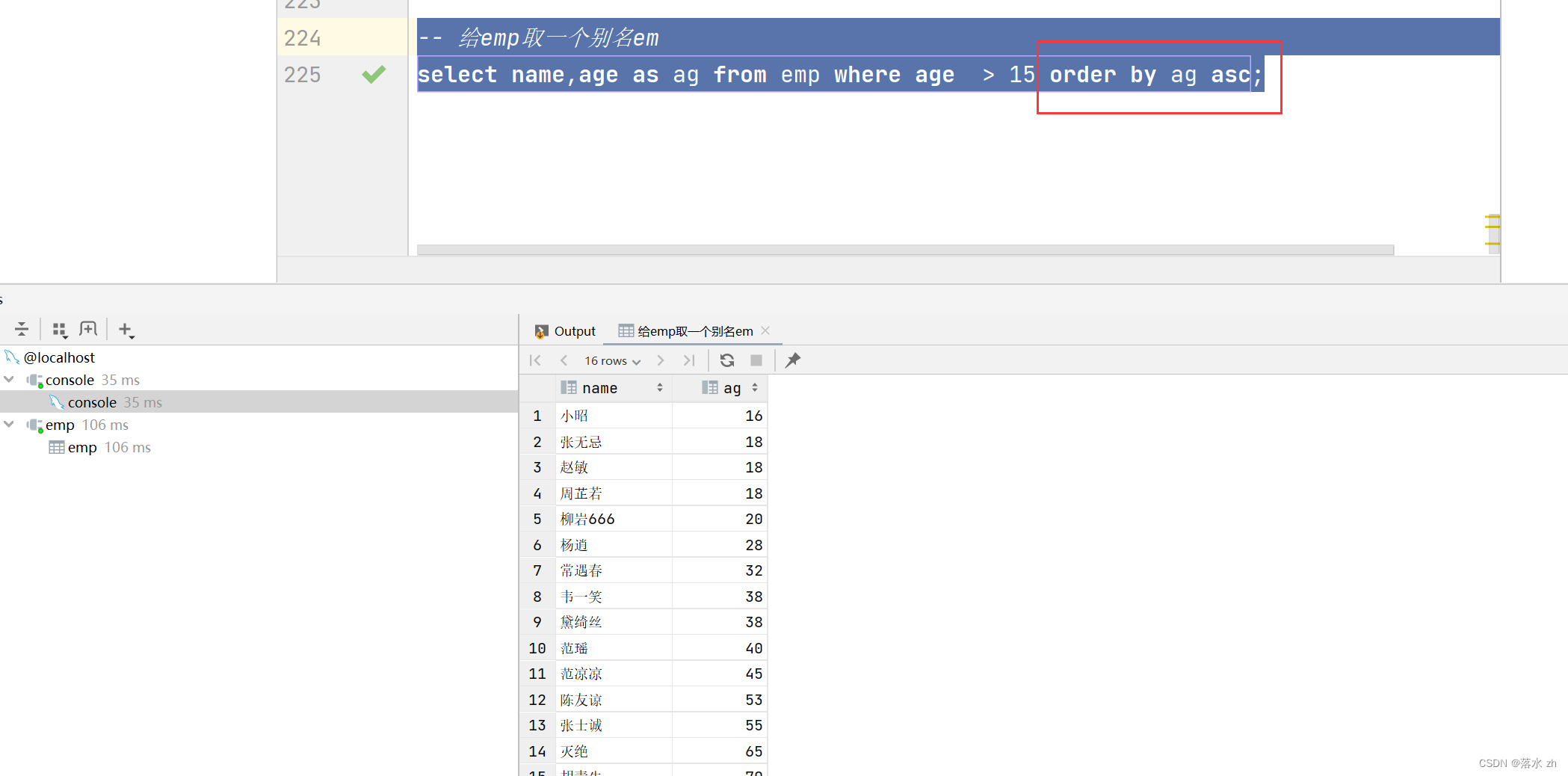 这说明order by是在select之后执行的。
这说明order by是在select之后执行的。