前言
医疗知识的整合与人工智能一直是研究界的焦点,每一点进步都可能带来更好的患者体验和更高的治愈率。尽管医疗大型语言模型(LLM)前景广阔,但现有工作主要集中在中文和英文上,对于其他语言的多语言适配还有待进一步探索。
为了将最先进的LLM的好处普及到更广泛的用户群体,研究团队开发了Apollo系列多语言医疗LLM。这一举措类似于历史上将变革性技术如电力和疫苗普及到更广泛群体的努力,将LLM视为现代版的医疗基础创新。
-
Huggingface模型下载:https://huggingface.co/FreedomIntelligence/Apollo-7B
-
AI快站模型免费加速下载:https://aifasthub.com/models/FreedomIntelligence

模型特点
Apollo作为一个轻量级的多语言医疗LLM,具有以下优势:
-
可以作为大模型的代理模型(Proxy Tuning),在不需要接触敏感医疗训练数据的情况下,显著提升大模型的多语种医疗能力。
-
体积小,可直接部署在医疗设备上,无需联网即可提供本地化的医疗服务,提高效率。
-
计算资源要求低,更适合学术研究者探索医疗LLM领域的新思路和新问题。
ApolloCorpora:多语种医疗数据集
为了构建多语言医疗LLM,研究团队首先构建了高质量的ApolloCorpora数据集,覆盖了英语、中文、印地语、西班牙语、法语和阿拉伯语六种最广泛使用的语言,涵盖了全球61亿人口。
数据来源包括书籍、临床指南、百科全书、论文、在线论坛和考试等,共2.5万亿tokens。在数据处理过程中,研究团队还针对不同语言的医学特点进行了本地化特征保留。

Apollo:性能优良的轻量级多语言医疗LLM
基于ApolloCorpora,研究团队开发了Apollo系列多语言医疗LLM,其中包括0.5B、1.8B、2B、6B和7B等不同规模的模型。相较于传统的继续预训练和指令微调方法,Apollo采用了一种新的域适应方法:使用ChatGPT将预训练语料重写为问答对,并采用自适应采样策略,实现了更平滑的过渡。
这种相对较小规模的模型设计,使Apollo可以作为大模型的代理模型(Proxy Tuning)使用,在不需要直接训练大模型的情况下,即可显著提升其多语言医疗能力,从而保护医疗训练数据的隐私。

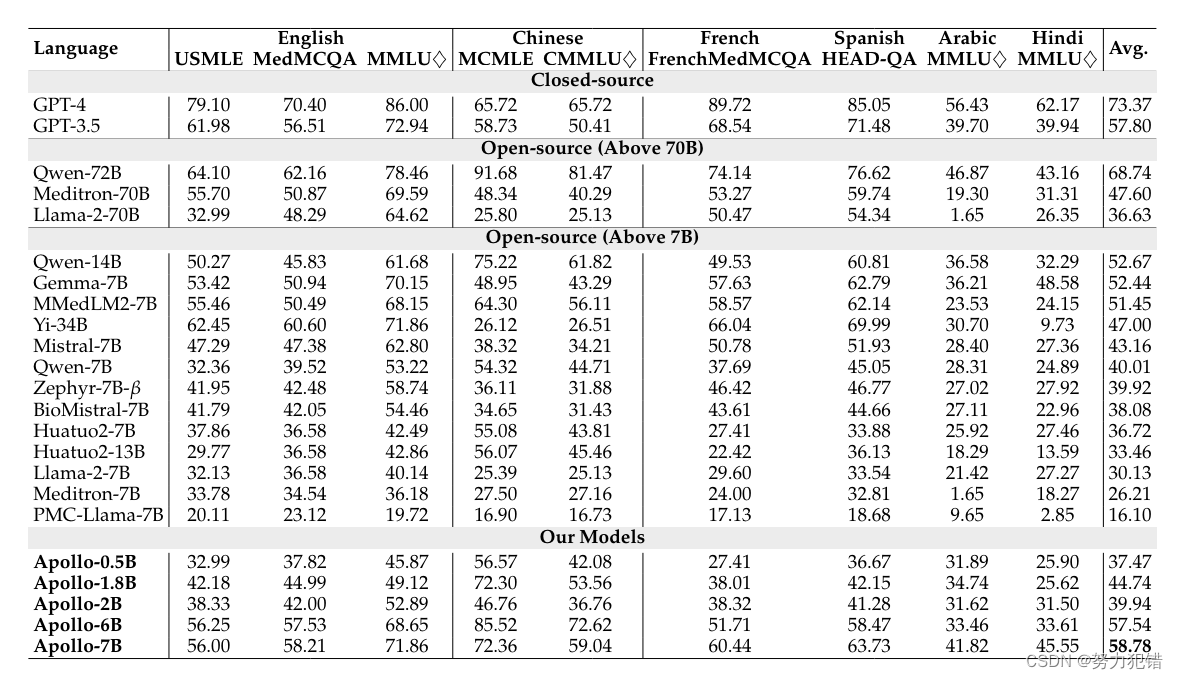
XMedBench:多语种医疗知识评测
为了全面评估多语言医疗LLM的性能,研究团队构建了XMedBench评测集,包括英语的MedQA、MMLU等,中文的CMMLU,西班牙语的HEAD-QA,法语的FrenMedMCQA,以及翻译自MMLU的阿拉伯语和印地语版本。
评测结果显示,虽然GPT-4和Qwen-72B在闭源和开源模型中排名第一,但Apollo系列模型在同等规模下取得了最佳性能。其中Apollo-7B的表现与GPT-3.5持平,Apollo-1.8B与Mistral-7B持平,Apollo-0.5B与Llama2-7B持平。
虽然阿拉伯语和印地语的支持仍有待进一步提高,但Apollo系列模型在英语、中文、法语和西班牙语等主流语言的医疗知识理解方面已经达到了领先水平。
总结
总的来说,Apollo系列模型的开源发布,为多语种医疗人工智能的发展注入了新动力,有望让全球61亿人受益于先进的医疗AI技术。未来,研究团队还计划进一步优化Apollo在视觉理解和生成等方面的能力,以及与大型语言模型的深度融合。
模型下载
Huggingface模型下载
https://huggingface.co/FreedomIntelligence/Apollo-7B
AI快站模型免费加速下载
https://aifasthub.com/models/FreedomIntelligence
![[华为OD]C卷 机场航班调度 ,XX市机场停放了多架飞机,每架飞机都有自己的航班号100](https://img-blog.csdnimg.cn/direct/35f7096d02d44fe29dfba0756625d85e.png)