一、引入
在深度学习和机器学习的世界中,神经网络是构建智能系统的重要基石,参数初始化是神经网络训练过程中的一个重要步骤。在构建神经网络时,我们需要为权重和偏置等参数赋予初始值。对于偏置,通常可以将其初始化为0或者较小的随机数。然而,对于权重w的初始化,我们通常会采用更加复杂的方法,以确保网络能够更好地学习数据的特征。
二、神经网络的结构
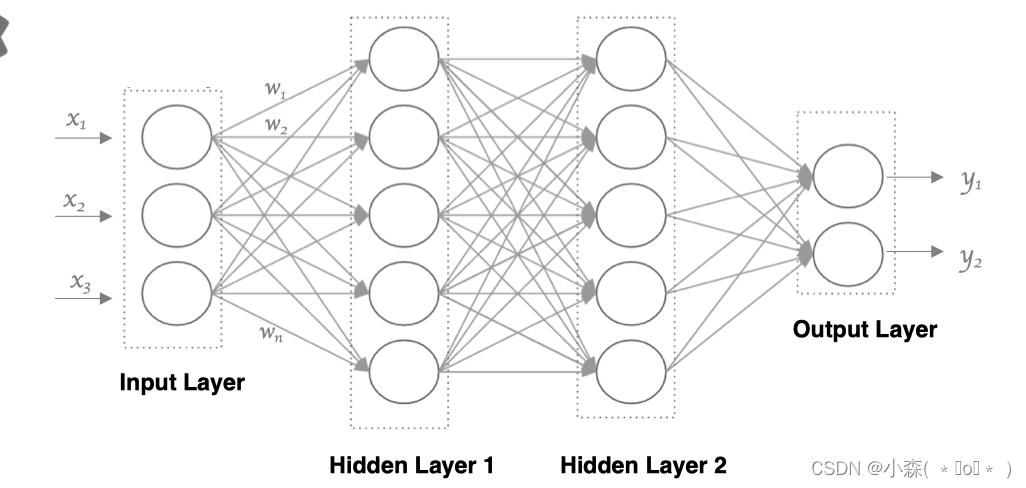
我们先给机器一个架构,如下图的两个隐藏层,还有这些神经元,还有给定激活函数,让机器去找w 的取值!就是找出一组参数使得输出效果好,这就是机器学习的意义。
常见的网络参数初始化方法:
- 均匀分布初始化:这种方法通过在特定区间内均匀随机地选择权重参数的初始值。通常,这个区间是(-1/√d, 1/√d),其中d是每个神经元的输入数量。这种初始化方式有助于打破神经元之间的对称性,促进网络的多样性和学习能力。
- 正态分布初始化:在这种初始化方法中,权重参数从均值为0,标准差为1的高斯分布中随机取样。这种方法可以确保权重参数有较小的初始值,有助于模型的稳定训练。
- 全零初始化:将所有权重和偏置参数初始化为零。虽然这种方法简单直接,但它可能导致所有神经元在学习过程中更新相同,从而引发梯度消失问题。
- 全一初始化:将所有权重和偏置参数初始化为一。与全零初始化类似,这种方法也可能导致对称性问题,因为所有神经元学到的东西会相同。
- 固定值初始化:使用某个固定的小数值来初始化所有的权重和偏置参数。
- Kaiming初始化(也称为He初始化):这是一种特别针对使用ReLU激活函数的神经网络设计的初始化方法。它根据前一层的神经元数量来设置权重的初始范围。
- Xavier初始化(也称为Glorot初始化):这种初始化方法根据前一层和后一层的神经元数量来计算权重的初始范围。这种方法旨在保持信号的方差不变,从而有效地初始化神经网络中的权重。
三、参数初始化代码
import torch
import torch.nn as nn
import torch.nn.init as init
# 均匀分布初始化
def uniform_init(m):
if isinstance(m, nn.Linear):
init.uniform_(m.weight, -1/(m.in_features**0.5), 1/(m.in_features**0.5))
if m.bias is not None:
init.constant_(m.bias, 0)
# 正态分布初始化
def normal_init(m):
if isinstance(m, nn.Linear):
init.normal_(m.weight, mean=0, std=1)
if m.bias is not None:
init.constant_(m.bias, 0)
# 全零初始化
def zero_init(m):
if isinstance(m, nn.Linear):
init.constant_(m.weight, 0)
if m.bias is not None:
init.constant_(m.bias, 0)
# 全一初始化
def one_init(m):
if isinstance(m, nn.Linear):
init.constant_(m.weight, 1)
if m.bias is not None:
init.constant_(m.bias, 0)
# 固定值初始化
def fixed_value_init(m, value):
if isinstance(m, nn.Linear):
init.constant_(m.weight, value)
if m.bias is not None:
init.constant_(m.bias, 0)
# Kaiming初始化(He初始化)
def kaiming_init(m):
if isinstance(m, nn.Linear):
init.kaiming_normal_(m.weight, mode='fan_in', nonlinearity='relu')
if m.bias is not None:
init.constant_(m.bias, 0)
# Xavier初始化(Glorot初始化)
def xavier_init(m):
if isinstance(m, nn.Linear):
init.xavier_uniform_(m.weight)
if m.bias is not None:
init.constant_(m.bias, 0)在PyTorch中,一般我们在构建网络模型时,每个网络层的参数都有默认的初始化方法,如果需要自定义参数的初始化,可以使用torch.nn.init模块中提供的各种初始化方法。例如,使用torch.nn.init.xavier_uniform_或torch.nn.init.kaiming_normal_来实现Xavier和Kaiming初始化。
↓ ↓ ↓ ↓ ↓ ↓ ↓
简化写法:
def func01():
linear = nn.Linear(5, 3) # 输入和输出维度
# 均匀分布
nn.init.uniform_(linear.weight)
print(linear.weight.data)
def func02():
# 固定值赋值
linear = nn.Linear(5, 3)
nn.init.constant_(linear.weight, 5)
print(linear.weight.data)
❄️torch.nn.init是 PyTorch 中用于初始化神经网络层(如线性层、卷积层等)权重和偏置的模块。这个模块提供了多种预定义的初始化方法,用户可以根据需要选择合适的方法来初始化网络参数。
❄️torch.nn是PyTorch中用于定义神经网络的模块,它包含了构建神经网络所需的各种层和损失函数。
- 网络层:
torch.nn提供了多种类型的网络层,包括线性层(Linear)、卷积层(Conv2d)、池化层(MaxPool2d)、循环层(如RNN)等,这些层是构建神经网络的基本单元。 - 损失函数:为了训练网络,需要计算损失函数,
torch.nn提供了多种损失函数,如交叉熵损失(CrossEntropyLoss)、均方误差损失(MSELoss)等。 - 激活函数:激活函数用于引入非线性,
torch.nn包含了常见的激活函数,如ReLU、Sigmoid、Tanh等。 - 优化器接口:虽然优化器本身不直接包含在
torch.nn模块中,但PyTorch提供了torch.optim模块,与torch.nn紧密集成,用于网络参数的优化。 - 容器类:
torch.nn还提供了一些容器类,如Sequential和ModuleList,它们帮助用户组织和管理网络中的各层。 - 功能性操作:除了网络层和损失函数,
torch.nn还提供了一些功能性操作,如functional子模块中的函数,它们对张量进行逐元素操作,如relu、softmax等。