一、基本环境
python版本:3.8.5
APScheduler==3.10.4
Django==3.2.7
djangorestframework==3.15.1
SQLAlchemy==2.0.29
PyMySQL==1.1.0
二、django基本设置
2.1、新增一个app
该app用来写apscheduler相关的代码
python manage.py startapp gs_scheduler
2.2、修改配置文件settings.py
#使用pymysql做客户端
import pymysql
pymysql.install_as_MySQLdb()
INSTALLED_APPS = [
'rest_framework', #注册restful 应用
'gs_scheduler', #注册新增的app
]
#配置mysql
MYSQL_HOST = '127.0.0.1'
MYSQL_PORT = 3306
MYSQL_USER = 'root'
MYSQL_PASSWORD = 'admin-root'
MYSQL_NAME = 'study_websocket'
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'HOST': MYSQL_HOST,
'PORT': MYSQL_PORT,
'USER': MYSQL_USER,
'PASSWORD': MYSQL_PASSWORD,
'NAME': MYSQL_NAME,
}
}2.3、gs_scheduler创建urls.py
1、gs_scheduler/urls.py
from django.urls import path
from . import views
urlpatterns = [
]2、根路由urls.py
from django.contrib import admin
from django.urls import path,include
urlpatterns = [
path('admin/', admin.site.urls),
path('api/scheduler/',include('gs_scheduler.urls')),
]三、配置gs_scheduler应用
3.1、配置api接口
这些接口,用来展示定时任务的运行情况
1、urls.py
from django.urls import path
from . import views
urlpatterns = [
path('run_next/', views.JobNextRunTimeAPIView.as_view()),#定时任务下次运行
path('run_history/',views.JobRunTimeHistory.as_view()),#定时任务运行历史
path('run_error/',views.JobRunErrorHistory.as_view()), #定时任务最近运行错误
]
2、models.py
from django.db import models
# Create your models here.
import sqlite3
from gs_scheduler.management.commands.config import MYSQL_HOST,MYSQL_NAME,MYSQL_PORT,MYSQL_PASSWORD,MYSQL_USER,MYSQL_CHARSET
from datetime import datetime,timedelta
from django.conf import settings
import pymysql
from concurrent.futures import ThreadPoolExecutor
#时间戳转时间字符串
def timestamp_to_time_str(timestamp):
# 使用 datetime 模块将时间戳转换为 datetime 对象
dt = datetime.fromtimestamp(timestamp)
# 将 datetime 对象格式化为时间字符串
time_str = dt.strftime('%Y-%m-%d %H:%M:%S')
return time_str
class MysqlDB:
DATETIME_FORMAT = '%Y-%m-%d %H:%M:%S'
# 创建数据库连接池
def __init__(self):
self.conn = pymysql.connect(
host=MYSQL_HOST,
port=MYSQL_PORT,
user=MYSQL_USER,
password=MYSQL_PASSWORD,
db=MYSQL_NAME,
charset=MYSQL_CHARSET,
cursorclass=pymysql.cursors.DictCursor
)
# 执行数据库增删改查
def _execute_sql(self,query):
sql,args = query
try:
with self.conn.cursor() as cursor:
# 执行sql语句
if args:
if isinstance(args,(tuple,list)):
# args = (value1,value2)
cursor.execute(sql,args)
else:
# args = value1
cursor.execute(sql,(args,))
else:
cursor.execute(sql)
# 不同类型sql,设置不同返回值
if sql.strip().lower()[:6] == 'select':
#查询语句
rows = cursor.fetchall() or []
return rows
elif sql.strip().lower()[:4] == 'show':
#查看表是否存在
result = cursor.fetchall()
return result
else:
#增删改语句
self.conn.commit()
return True
except Exception as e:
print('sql执行失败',e)
pass
# 线程池执行sql语句
def start_sql_with_pool(self, sql:str,args=None):
with ThreadPoolExecutor() as executor:
result = executor.submit(self._execute_sql, (sql,args)).result()
return result
#创建记录定时任务历史表(调度器使用)
def create_apscheduler_history(self):
#创建表语句:表名不能是占位符
sql = """CREATE TABLE apscheduler_history (
id INTEGER AUTO_INCREMENT PRIMARY KEY,
job_id VARCHAR(128),
run_time DATETIME,
is_error TINYINT,
error_msg VARCHAR(256) NULL)"""
#判断表存在不,不存在再创建
results = self.start_sql_with_pool('SHOW TABLES')
is_exist = False
for dic in results:
if dic['Tables_in_{}'.format(MYSQL_NAME,)] == 'apscheduler_history':
is_exist = True
#表不存在才创建
if not is_exist:
# print('表不存在,执行创建表')
create = self.start_sql_with_pool(sql)
# 创建索引
self.start_sql_with_pool(db.conn.cursor().execute("CREATE INDEX run_time_index ON apscheduler_history (run_time)"))
return True
# 将任务运行的结果记录到数据库中(调度器使用)
def insert_into_apscheduler_history(self, data_list: list):
if len(data_list) == 4: # 异常执行的任务
sql = """
INSERT INTO apscheduler_history (job_id,run_time,is_error,error_msg) VALUES (%s,%s,%s,%s)
"""
else: # 正常执行的任务
sql = """
INSERT INTO apscheduler_history (job_id,run_time,is_error) VALUES (%s,%s,%s)
"""
#使用线程池执行插入语句
self.start_sql_with_pool(sql,data_list)
# 删除8小时前的历史记录(调度器使用)
def delete_8hour_before_history(self):
before_8hour = (datetime.now() - timedelta(hours=8)).strftime('%Y-%m-%d %H:%M:%S')
sql = '''
DELETE FROM apscheduler_history WHERE run_time < %s'''
self.start_sql_with_pool(sql,(before_8hour,))
# 查询每个任务的下次运行时间(api展示)
def fetch_all_next_run_time(self):
sql = 'SELECT id,next_run_time FROM apscheduler_jobs'
# 获取查询结果
rows = self.start_sql_with_pool(sql)
for row in rows:
row['next_run_time'] = timestamp_to_time_str(row['next_run_time'])
return rows
# 查询所有任务最近10次运行记录(api展示)
def fetch_all_run_history(self):
'''
:param query:'SELECT id,next_run_time,job_state FROM apscheduler_jobs'
:return:
'''
#获取所有定时任务id
data_list = self.fetch_all_next_run_time()
id_list = (dic.get('id') for dic in data_list)
# 创建一个游标对象
sql = """
SELECT id,job_id,run_time FROM apscheduler_history WHERE is_error=0 AND job_id = %s ORDER BY run_time DESC LIMIT 10
"""
ret_list = []
for id in id_list:
# 执行查询
rows = self.start_sql_with_pool(sql,(id,)) or []
dic = {'id': id, 'last_run_time': [], 'msg': '最近10次运行时间'}
for row in rows:
run_time = row.get('run_time')
run_time = run_time.strftime(self.DATETIME_FORMAT) if isinstance(run_time,datetime) else run_time
dic['last_run_time'].append(run_time)
ret_list.append(dic)
return ret_list
# 获取任务最近运行失败情况(api展示)
def fetch_all_error_history(self):
data_list = self.fetch_all_next_run_time()
id_list = (dic.get('id') for dic in data_list)
sql = """
SELECT run_time,error_msg FROM apscheduler_history WHERE is_error=1 AND job_id = %s ORDER BY id DESC LIMIT 5
"""
ret_list = []
for id in id_list:
# 获取查询结果
rows = self.start_sql_with_pool(sql, (id,)) or []
dic = {'id': id, 'last_run_time': [], 'msg': '最近5次执行失败'}
for row in rows:
run_time = row.get('run_time')
run_time = run_time.strftime(self.DATETIME_FORMAT) if isinstance(run_time,datetime) else run_time
error = row.get('error_msg')
dic['last_run_time'].append({'run_time': run_time, 'error': error})
ret_list.append(dic)
return ret_list
# 关闭连接
def close(self):
self.conn.close()
if __name__ == '__main__':
db = MysqlDB()
db.create_apscheduler_history()
# for i in range(1,10):
# db.insert_into_apscheduler_history(['send_to_big_data','2024-05-01 13:{}:12'.format(str(i).zfill(2)),1,'执行失败了'])
# db.delete_8hour_before_history()
# ret = db.fetch_all_run_history()
# print(ret,'history')
# ret = db.fetch_all_next_run_time()
# print(ret,'next')
# ret = db.fetch_all_error_history()
# print(ret,'error')
db.close()
3、views.py
from django.shortcuts import render
# Create your views here.
from rest_framework.views import APIView
from rest_framework.response import Response
from .models import MysqlDB
#任务下次运行时间
class JobNextRunTimeAPIView(APIView):
authentication_classes = []
def get(self,request):
db = MysqlDB()
data = db.fetch_all_next_run_time()
db.close()
ret = {
'code':200,
'status':'success',
'data':data,
}
return Response(ret)
#任务最近运行历史
class JobRunTimeHistory(APIView):
authentication_classes = []
def get(self,request):
db = MysqlDB()
data = db.fetch_all_run_history()
db.close()
ret = {
'code':200,
'status':'success',
'data':data
}
return Response(ret)
#任务最近运行错误
class JobRunErrorHistory(APIView):
authentication_classes = []
def get(self,request):
db = MysqlDB()
data = db.fetch_all_error_history()
db.close()
ret = {
'code': 200,
'status': 'success',
'data': data
}
return Response(ret)3.2、在gs_scheduler创建
1、config.py 代码
该文件存放的是启动APScheduler调度器的一些配置数据
import os
from apscheduler.jobstores.memory import MemoryJobStore #内存做后端存储
#from apscheduler.jobstores.redis import RedisJobStore #redis做后端存储
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore #mysql等做后端存储
# from django.conf import settings
from study_apscheduler import settings
#mysql://root:ldc-root@127.0.0.1:3306/jobs?charset=utf8
MYSQL_CONFIG = settings.DATABASES.get('default')
MYSQL_USER = MYSQL_CONFIG.get('USER')
MYSQL_PASSWORD = MYSQL_CONFIG.get('PASSWORD')
MYSQL_HOST = MYSQL_CONFIG.get('HOST')
MYSQL_PORT = MYSQL_CONFIG.get('PORT')
MYSQL_NAME = MYSQL_CONFIG.get('NAME')
MYSQL_CHARSET = 'utf8mb4'
URL = 'mysql://{}:{}@{}:{}/{}?charset={}'.format(MYSQL_USER,MYSQL_PASSWORD,MYSQL_HOST,MYSQL_PORT,MYSQL_NAME,MYSQL_CHARSET)
#时区
TIME_ZONE = 'Asia/Shanghai'
#job的默认配置
JOB_DEFAULTS = {
'coalesce': True, #系统挂掉,任务积攒多次为执行,True是合并成一次执行,False是执行所有的次数。 持久化存储才有效
'max_instances': 3 # 同一个任务同一时间最多只能有3个实例在运行。
}
#job的存储后端
JOB_STORE = {
'default': SQLAlchemyJobStore(url=URL)
}
#监听事件对应的情况
LISTENER={
1:'调度程序启动',
2:'调度程序关闭',
4:'调度程序中任务处理暂停',
64:'将任务存储添加到调度程序中',
8192:'任务在执行期间引发异常',
4096:'任务执行成功',
}
2、task.py
所有的定时任务都存放在这里
import os
from datetime import datetime, timedelta, date
from gs_scheduler.models import MysqlDB
from utils.log_util import info_log
from utils.send_monitor_data import SendData
#推送到数据仓的告警信息:5分钟执行一次
send_to_big_data = SendData().send
#清除定时任务历史运行记录
def delete_apscheduler_history():
db = MysqlDB()
db.delete_8hour_before_history()
if __name__ == '__main__':
print(os.path.dirname(os.path.dirname(os.path.dirname(__file__))))3、crontab.py
实例化调度器
# 导入所需的调度器类和触发器类
from apscheduler.schedulers.background import BackgroundScheduler #后台运行
from apscheduler.schedulers.blocking import BlockingScheduler #主进程运行,需要单独运行
from apscheduler.triggers.interval import IntervalTrigger #时间间隔
from apscheduler.triggers.cron import CronTrigger #复杂的定时任务
from apscheduler.triggers.date import DateTrigger #一次性定时任务
from django.core.management.base import BaseCommand
from apscheduler import events
from pytz import timezone
from threading import RLock
from datetime import datetime, timedelta
from gs_scheduler.models import MysqlDB
#定时任务
from .task import delete_apscheduler_history
from .task import send_to_big_data
#日志
from utils.log_util import info_log
from .config import LISTENER
from .config import TIME_ZONE,JOB_DEFAULTS,JOB_STORE
#脚本运行:python manage.py crontab
class Command(BaseCommand):
TIME_FORMAT = '%Y-%m-%d %H:%M:%S'
#初始化调度器
def _scheduler_obj(self):
scheduler = BlockingScheduler()
scheduler.configure(
timezone = TIME_ZONE, #时区
job_defaults=JOB_DEFAULTS, #job的默认配置
jobstores=JOB_STORE, #job的存储后端
)
return scheduler
#添加任务
def _add_job(self,scheduler:BlockingScheduler):
#每5分钟执行一次推送告警到大数据仓
scheduler.add_job(
send_to_big_data,
trigger=IntervalTrigger(minutes=1),
id='send_to_big_data',
replace_existing=True,
coalesce=True,
)
#每隔8个小时,清除历史的记录
scheduler.add_job(
delete_apscheduler_history,
trigger=IntervalTrigger(hours=8),
id='delete_apscheduler_history',
replace_existing=True,
coalesce=True,
)
#添加监听器
def _listener(self,event:events):
code = event.code
run_time = datetime.now().strftime(self.TIME_FORMAT)
msg = LISTENER.get(code)
db = MysqlDB()
if msg:
if code == 4096:
#成功运行
job_id = event.job_id
#记录到数据库中
db.insert_into_apscheduler_history([job_id,run_time,0])
elif code == 8192:
#运行异常了
job_id = event.job_id
#记录到数据库中
db.insert_into_apscheduler_history([job_id,run_time,1,msg])
else:
info_log(msg)
db.close()
def start(self):
scheduler = self._scheduler_obj()
# 创建记录运行记录
db = MysqlDB()
db.create_apscheduler_history()
db.close()
# 设置监听器
scheduler.add_listener(self._listener)
# 设置定时任务
self._add_job(scheduler)
try:
# print('{},定时器启动成功,等待定时任务执行...'.format(datetime.now().strftime(self.TIME_FORMAT)))
scheduler.start()
except KeyboardInterrupt:
scheduler.shutdown()
# python manage.py crontab运行 就是调用该方法
def handle(self, *args, **options):
self.start()
#伴随django,在后台运行的。 在wsgi.py 文件中,调用BackRunScheduler().start()
class BackRunScheduler(Command):
# 初始化调度器
def _scheduler_obj(self):
scheduler = BackgroundScheduler()
scheduler.configure(
timezone=TIME_ZONE, # 时区
job_defaults=JOB_DEFAULTS, # job的默认配置
jobstores=JOB_STORE, # job的存储后端
)
return scheduler3.3、启动方式:
方式一: python manage.py crontab (生产环境,推荐使用此方式,单独运行)
方式二:在settings.py中,调用BackRunScheduler().start() , 后台运行
四、测试
4.1、启动
启动django项目:python manage.py runserver 8080
启动定时器:python manage.py crontab
4.2、等待一段时间
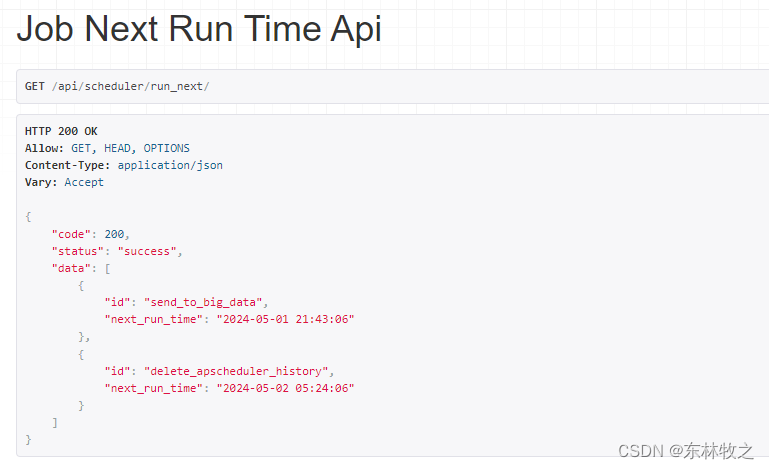
1、查询任务下次执行时间
请求:http://127.0.0.1:8080/api/scheduler/run_next/
2、查询任务最近运行情况
请求:http://127.0.0.1:8080/api/scheduler/run_next/

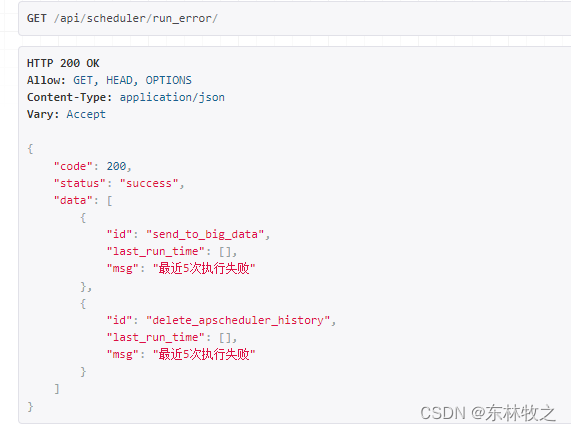
3、查询任务最近异常情况
请求:http://127.0.0.1:8080/api/scheduler/run_error/
五、源代码下载
码云地址:
django应用定时器: django下使用定时器的方法![]() https://gitee.com/liuhaizhang/django-application-timer/
https://gitee.com/liuhaizhang/django-application-timer/
目前有两套代码:一个以mysql存储任务,一个用sqlite存储任务