EDA或探索性数据分析是一项耗时的工作,但是由于EDA是不可避免的,所以Python出现了很多自动化库来减少执行分析所需的时间。EDA的主要目标不是制作花哨的图形或创建彩色的图形,而是获得对数据集的理解,并获得对变量之间的分布和相关性的初步见解。我们在以前也介绍过EDA自动化的库,但是现在已经过了1年的时间了,我们看看现在有什么新的变化。
为了测试这些库的功能,本文使用了两个不同的数据集,只是为了更好地理解这些库如何处理不同类型的数据。
YData-Profiling
以前被称为Pandas Profiling,在今年改了名字。如果你搜索任何与EDA自动化相关的内容时,它都会作为第一个结果出现,这也是有充分理由的。
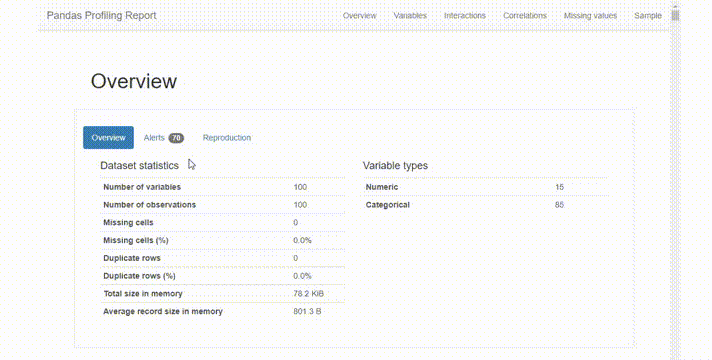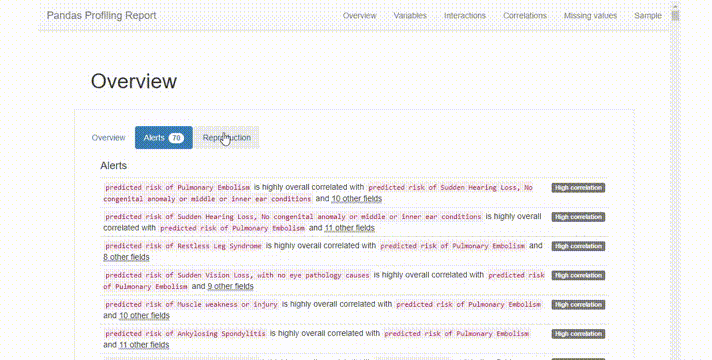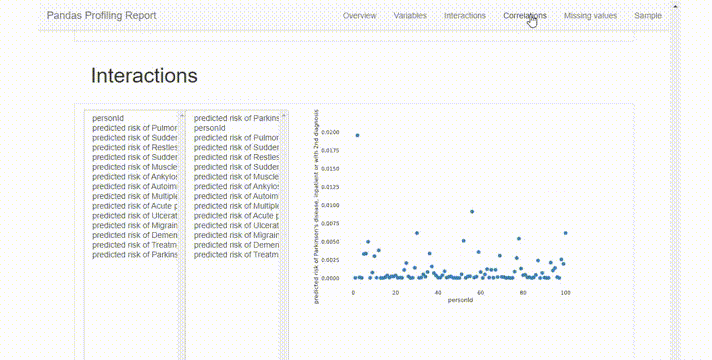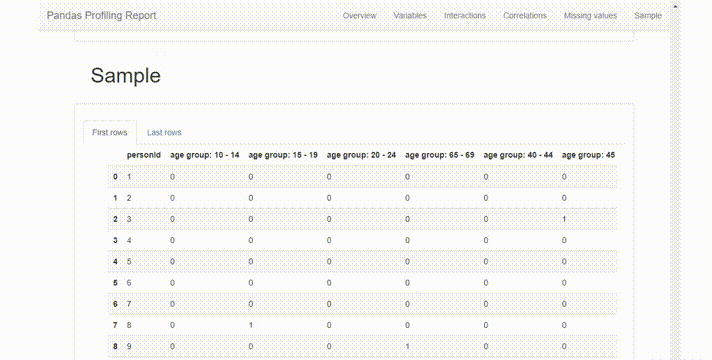
这个库最有用和最常用的是ProfileReport()命令。它生成整个数据集的详细摘要,报告对于获得数据的概览非常有用,特别是如果你不知道从哪里或如何开始分析(通常是这种情况)。这对于那些想要节省时间的新手或有经验的分析师来说非常有用。该报告提供单变量分布,突出数据质量问题,并创建相关性。让我们看一下患者风险概况数据的报告:
patient_data = pd.read_csv('/kaggle/input/patient-risk-profiles/patient_risk_profiles.csv')
zomato_data=pd.read_csv('/kaggle/input/zomato-data-40k-restaurants-of-indias-100-cities/zomato_dataset.csv')
from ydata_profiling import ProfileReport
patient_report=ProfileReport(patient_data)
patient_report
zomato_report=ProfileReport(zomato_data)
zomato_report
这份报告在很直观,也非常全面,它提供了一个很好的概述:
变量统计的简明概述,缺失值的百分比,重复值等。
在Alerts选项卡的简单文本中高亮显示数据质量问题,如高相关性,类不平衡等。
在variables 选项卡中给出了所有变量的单变量分析。有助于了解该变量的分布和统计特性。
点击变量下的“More Details”可以提供对各种其他统计数据,直方图,常见值和极值的更深入分析。基本上包含了一般我们想要知道的所有信息。
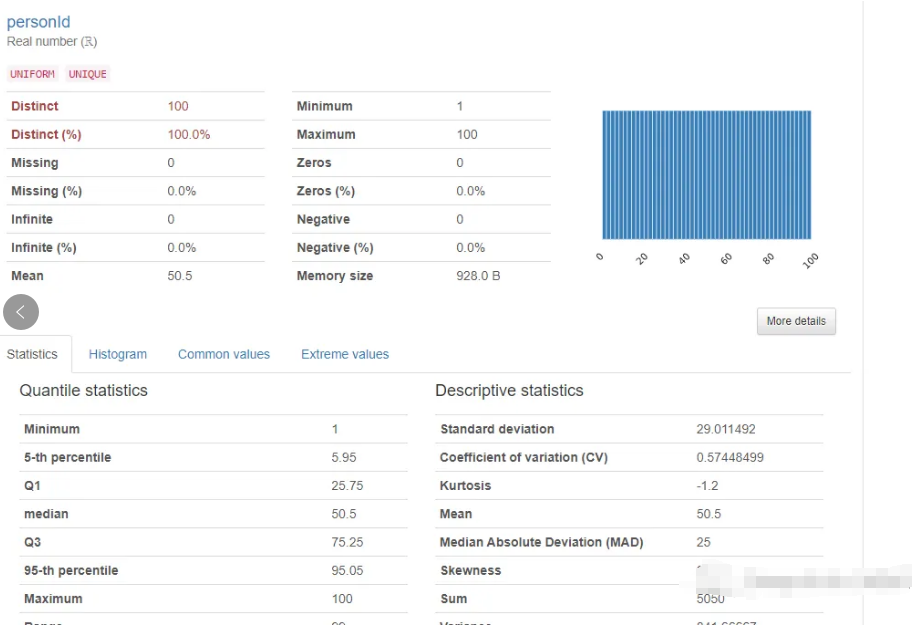
对于文本变量,报告生成了一个类似于NLP的概述,如下所示:

Interactions选项卡可以进行双变量分析,其中x轴变量在左列,y轴变量在右列。可以混搭来观察变量之间的相关性。这里唯一的限制是可用的图表类型只有散点图,所以如果想使用不同类型的图表,必须手动绘制。

在Correlations 下,可以观察到所有变量的热图。但是由于变量数量太多,热图几乎难以辨认,所以最好是用自定义参数绘制手动热图。
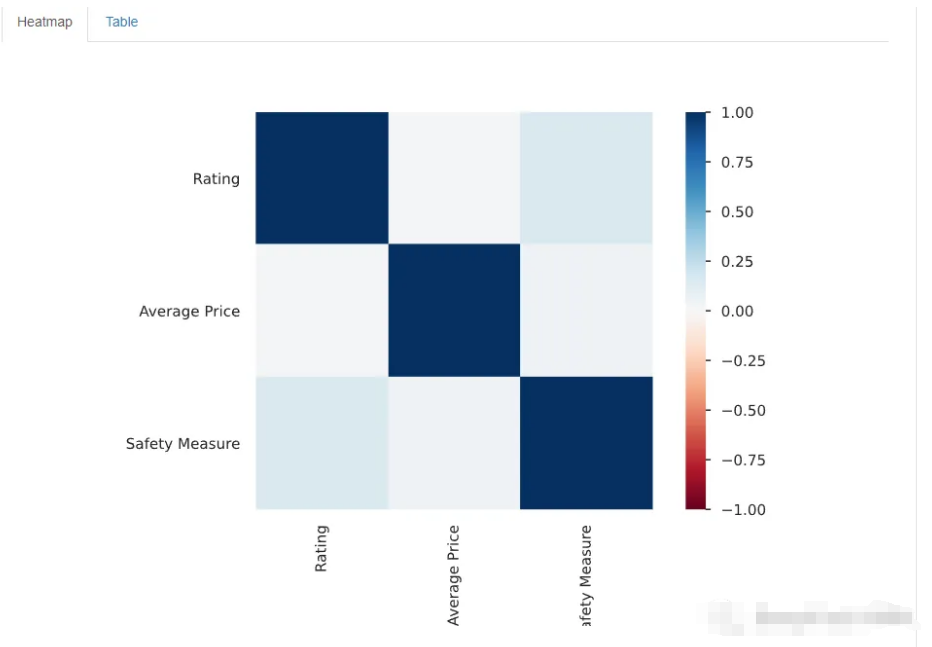
最后还显示了缺失值和相应的列,以及重复的行(如果有的话)。
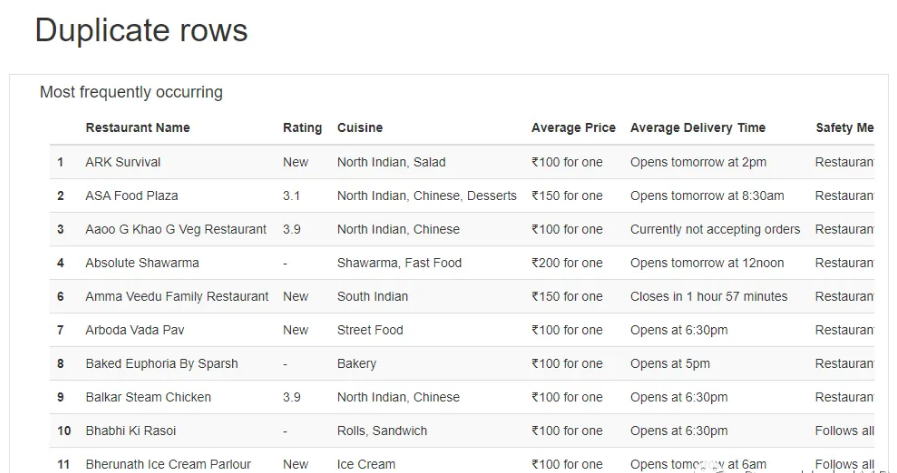
现YData报告对于在新数据集上获得立足点并找到进一步调查的方向非常有用。因为Pandas Profiling算是最早 的一个自动化EDA库了,并且YData对它做了非常大的更新。但是在较大数据集的情况下生成报告所需的时间很长,并且有时会崩溃。
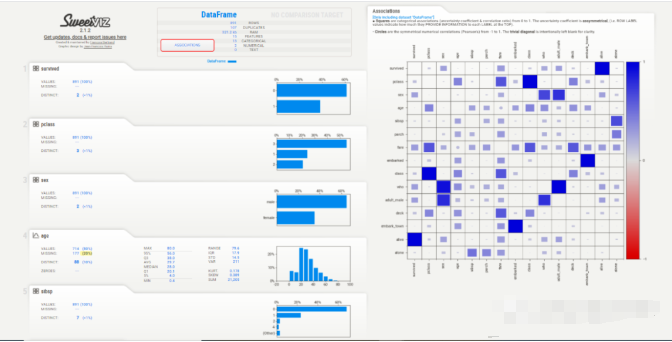
SweetViz
这是我自己最喜欢用的自动化库。它有三个主要函数可用于汇总数据集
analyze() -汇总单个数据集并生成报告。
compare() -比较两个df,如’ train ‘和’ test '。它只会比较常见的功能。
compare_intra() -比较相同数据集的子集。例如,同一数据中的“男性”和“女性”统计数据。
如果在Jupyter或Kaggle中工作,可以使用show_notebook()来呈现报告,在本地可以使用show_html()在新的浏览器窗口中打开报告。
import sweetviz as sv
patient_report_2=sv.analyze(patient_data)
patient_report_2.show_notebook(w="100%", h="full")
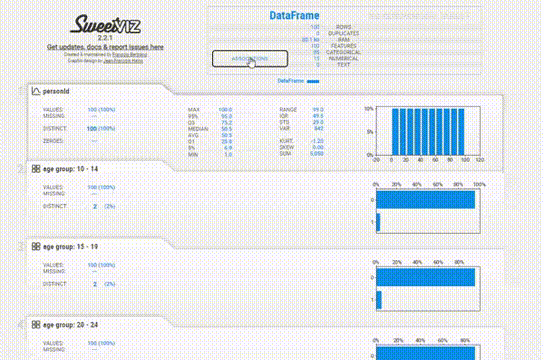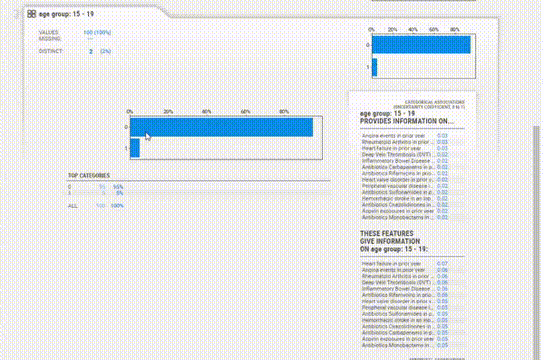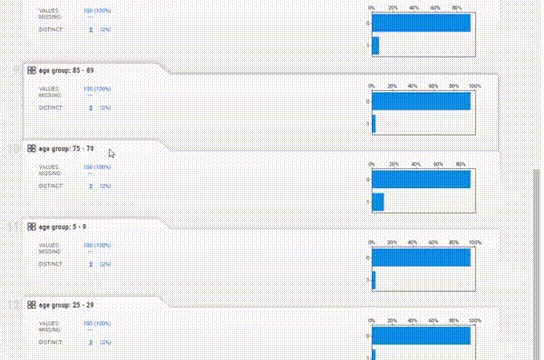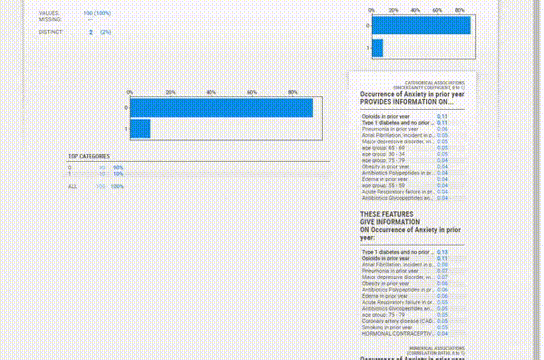
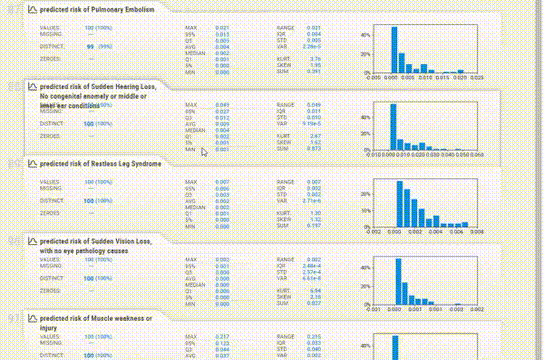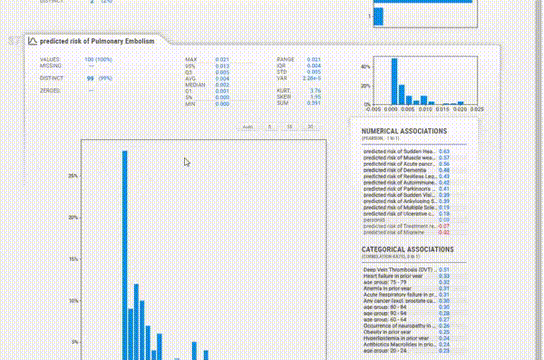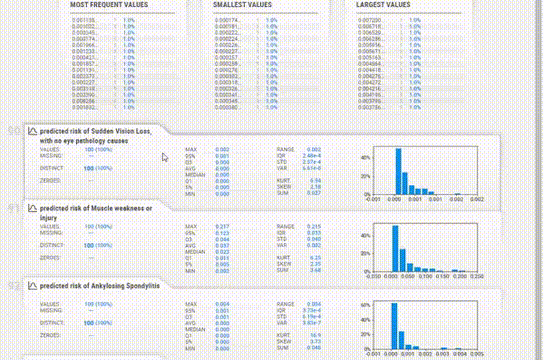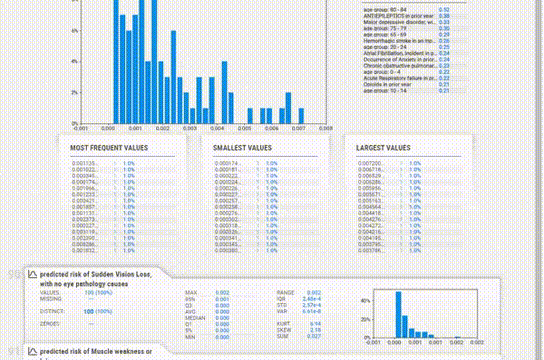
该报告与YData类似,提供了类似的信息,但UI感觉有点过时。
Association 选项卡创建了一个热图,提供了对变量相关性的洞察,由于变量的数量很大,热图是难以辨认的,对我们没有用处。所以可以使用explore_correlations()函数导出相关矩阵,并使用这些数据绘制带有自定义参数的热图。
为每个变量提供的信息更加简洁。缺失值、惟一值、分布甚至相关性都在每个变量部分中一起给出,所以不必在各个模块之间跳转以查看信息。
对于直方图,箱的数量也可以改变。统计信息可以在右上角查看,频繁值和极值也可以在底部看到。
但是它除了热图之外没有提供双变量分析,因此无法看到两个变量如何相互作用,这与YData不同。
在分析文本数据时,所提供的信息主要基于类和百分比分布,这比YData报告中少了很多
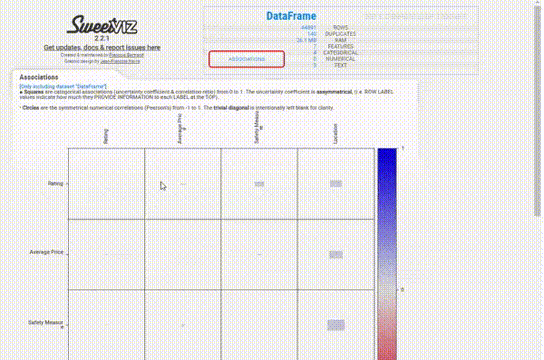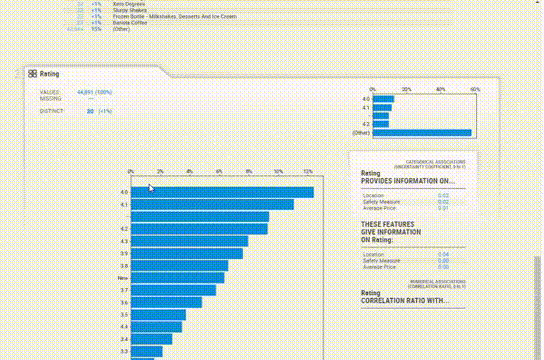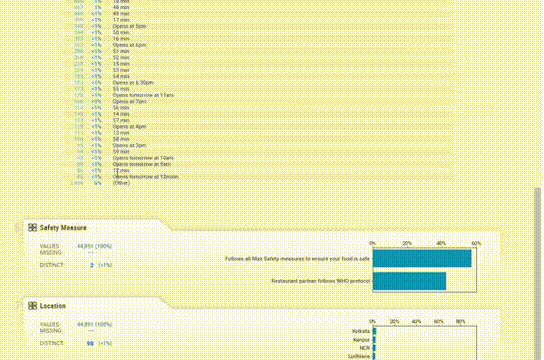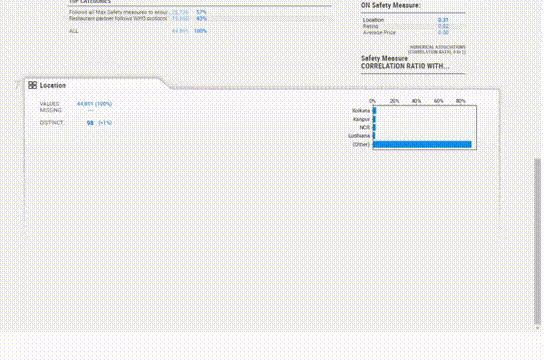
SweetViz给出了数据集的一个很好的概述,并且作为任何分析的起点都是很好的,关键是它运行的速度很快。
D-Tale
D-Tale只需一行代码就可以创建一个完全交互的界面,其中有大量的选项可随意使用。只需点击一个按钮就可以完成一些事情,不需要编写许多行代码。几乎所有你想通过编码做的事情都有一个UI功能,可以通过下拉菜单轻松获得。
import dtale
patient_report=dtale.show(patient_data)
patient_report
也可以在单独的浏览器中打开报表,而不是在jupyter中工作。这可以提供更大的空间来探索数据及其特性。只需点击左上角箭头,选择“Open in New Tab”。
这个菜单包含了一个列表中所有可用的功能,这些功能也在顶部的行中被划分为自动隐藏,所以需要保将光标悬停在列上方以查看工具栏,这是一个对于新手不好的地方。
Actions:在这个类别下,你可以使用pandas函数来实现聚合、数据清理、数据转换等功能。所有这些都是交互式的,只需点击鼠标即可。最棒的是,当你将鼠标悬停在每个功能上时,每个功能的解释都会弹出。可以使用Clean column从文本数据中删除标点符号,并且只需单击几下即可标准化文本数据。这是一个非常方便的特性,特别是对于新手来说。
Visualize:这是最有用的分类,给出了整个数据集的漂亮摘要。类似于pandas的describe()方法。
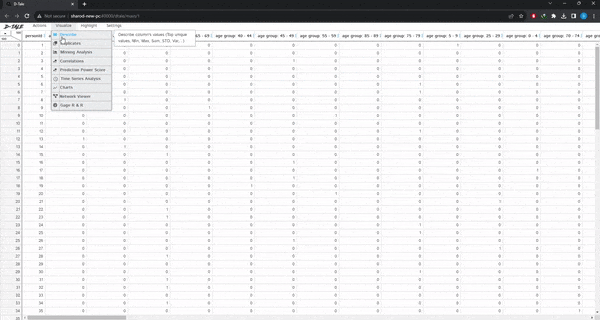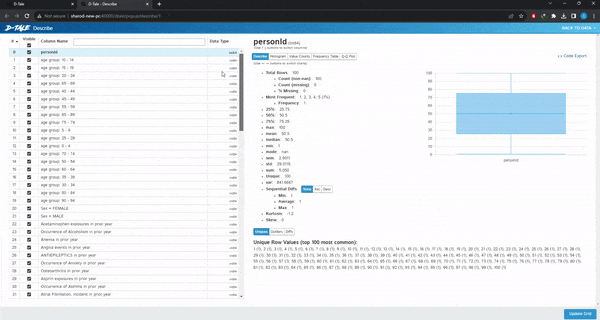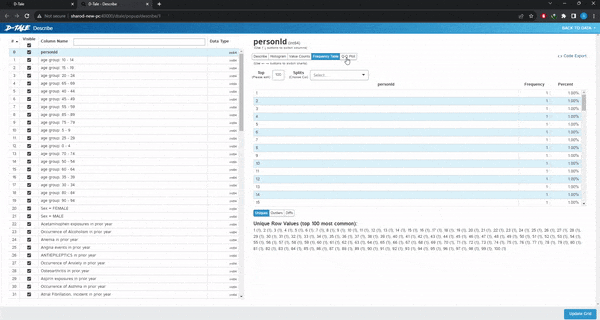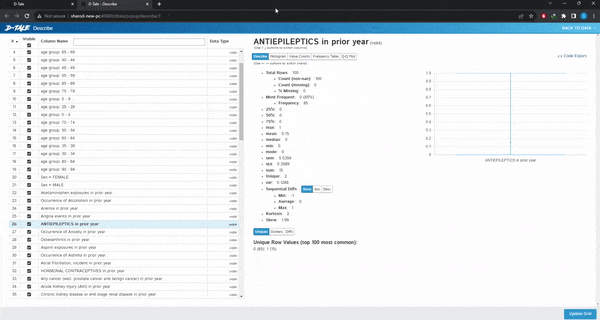
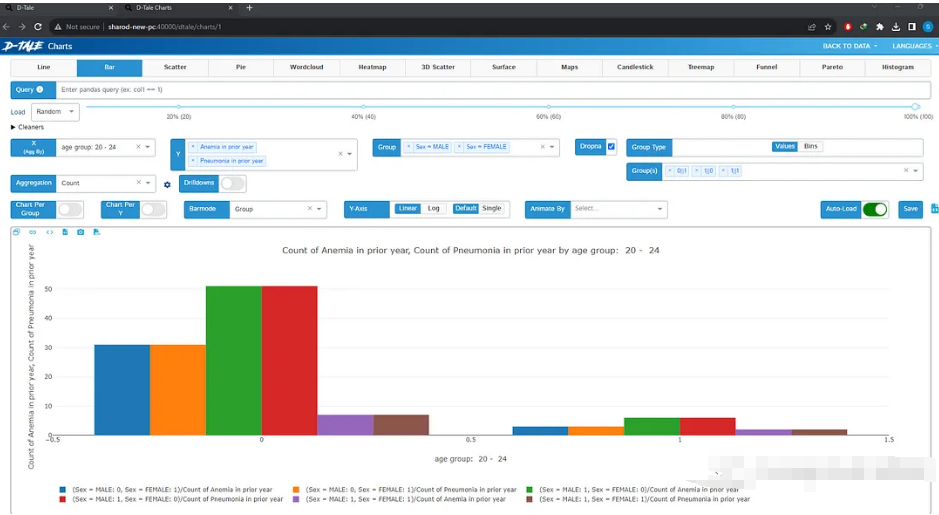
可以做缺失值分析、时间序列分析、查找相关性或创建图表。选择想要的图表类型,选择x和y变量,如果需要,选择组,图形将自动加载。也可以选择多个变量或组。不需要代码,只需点击几下就可以绘制完整的图表。
还可以单击列标题以显示更多选项,包括列分析,更改数据类型,查找重复项,重命名列,删除或更改位置等。这些任务可以通过编写基本代码轻松完成,但是使用这个工具可以节省很多时间。你也可以编辑任何单元格的值,只需点击它,就像在excel中一样。
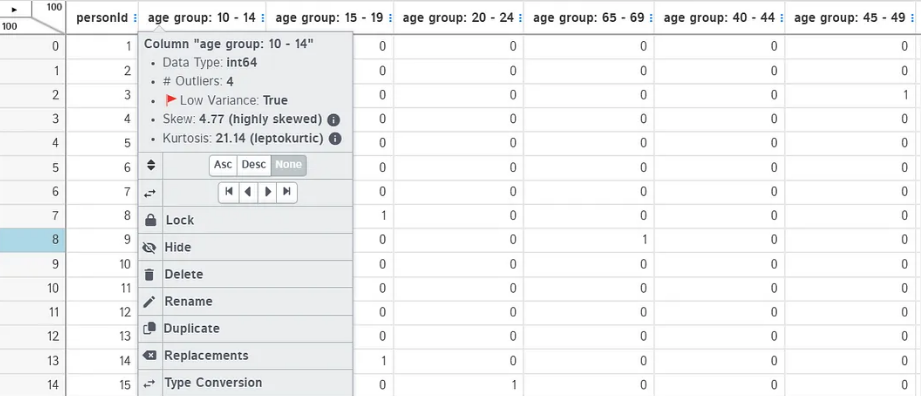
这个库可以说是EDA的第二步,通过自动化EDA我们对数据有了一定了解后使用这个库,可以在数据清理、预处理和可视化方面节省很多时间。
Klib
Klib是一个有趣的小库,非常容易使并且创建了非常有用的视觉效果。它还包含清理和预处理数据的功能。它还将一些非常常见的预处理步骤(这些步骤可能很繁琐)合并为单个命令,这些命令可以运行以获得相同的结果。这个库是由著名的数据科学教育家Krish Naik推荐的,所以值得一试。
df = pd.DataFrame(data)
# klib.describe - functions for visualizing datasets
- klib.cat_plot(df) # returns a visualization of the number and frequency of categorical features
- klib.corr_mat(df) # returns a color-encoded correlation matrix
- klib.corr_plot(df) # returns a color-encoded heatmap, ideal for correlations
- klib.corr_interactive_plot(df, split="neg").show() # returns an interactive correlation plot using plotly
- klib.dist_plot(df) # returns a distribution plot for every numeric feature
- klib.missingval_plot(df) # returns a figure containing information about missing values
# klib.clean - functions for cleaning datasets
- klib.data_cleaning(df) # performs datacleaning (drop duplicates & empty rows/cols, adjust dtypes,...)
- klib.clean_column_names(df) # cleans and standardizes column names, also called inside data_cleaning()
- klib.convert_datatypes(df) # converts existing to more efficient dtypes, also called inside data_cleaning()
- klib.drop_missing(df) # drops missing values, also called in data_cleaning()
- klib.mv_col_handling(df) # drops features with high ratio of missing vals based on informational content
- klib.pool_duplicate_subsets(df) # pools subset of cols based on duplicates with min. loss of information
我尝试了一些可视化功能,下图显示了所有变量的热图,上面的三角形被消去了(这是默认的),这是一个很好的特性。它使图表更具可读性。由于变量的数量非常多,因此很难看到相关性,但默认的配色方案可以让我们看到相关性较高的地方聚集在一起,用深蓝色标记。
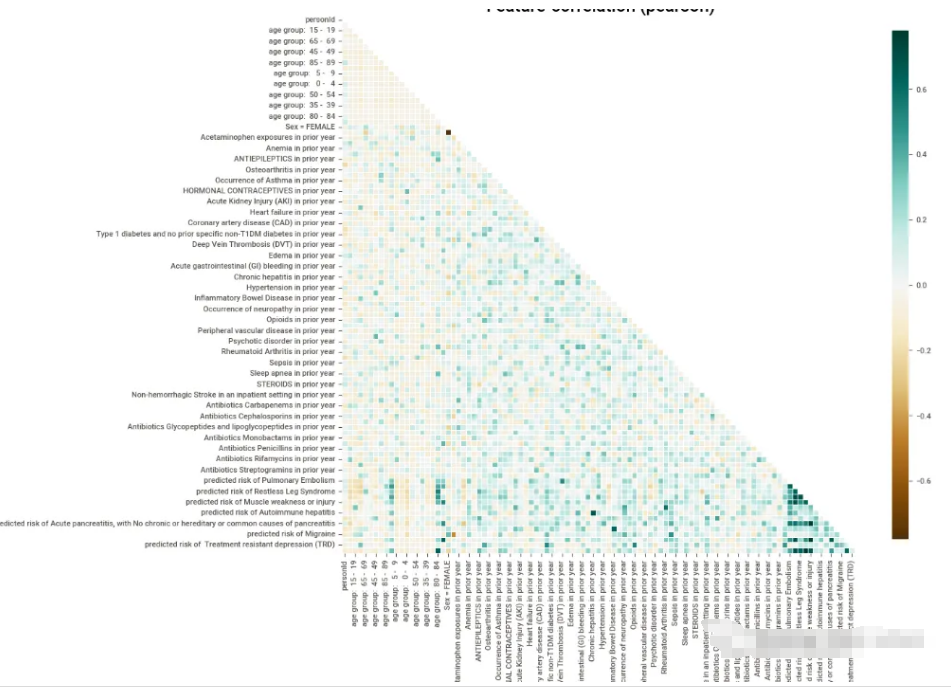
图表的配色方案很好,信息也很清晰。但是信息水平不像前几个库那样密集,这对于那些只希望看到某些特定数据而不希望被信息淹没的人来说是件好事。但是为了获得数据的概览,必须编写更多行代码来获得想要的内容。
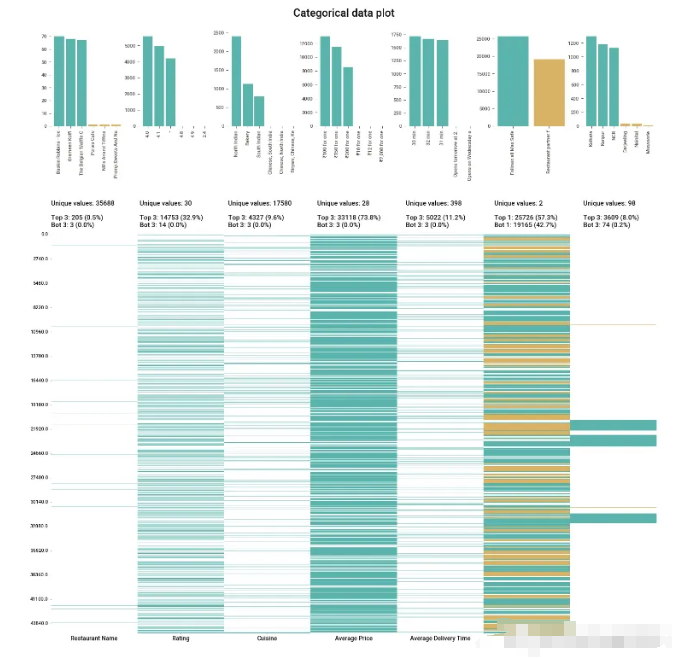
这个库很有趣,它肯定是工具箱中一个有用的工具,但我发现它在预处理的时候会更有用,因为许多常用的预处理技术已经被压缩成单行命令,可以直接执行节省编码时间。
Dabl
数据分析基线库- Dabl。这个库在执行时需要确定一个目标变量,将目标列作为y轴进行绘图。虽然这个库仍在开发中,但是它可以直接帮你进行双变量分析,这通常是我们真正想看到的。每个变量相对于目标变量的表现。
import dabl
import matplotlib.pyplot as plt
dabl.plot(patient_data, target_col='predicted risk of Pulmonary Embolism')
plt.show()
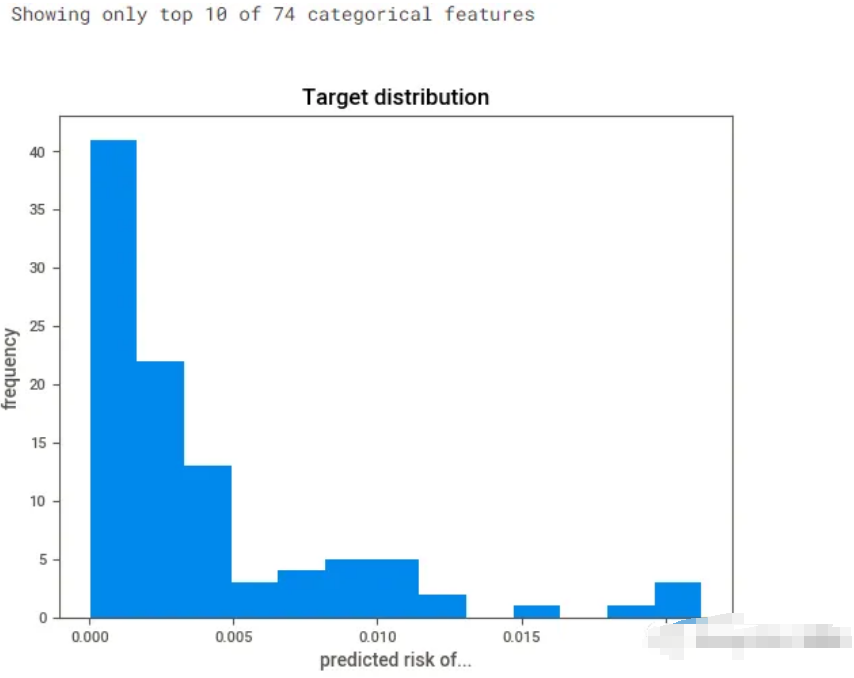
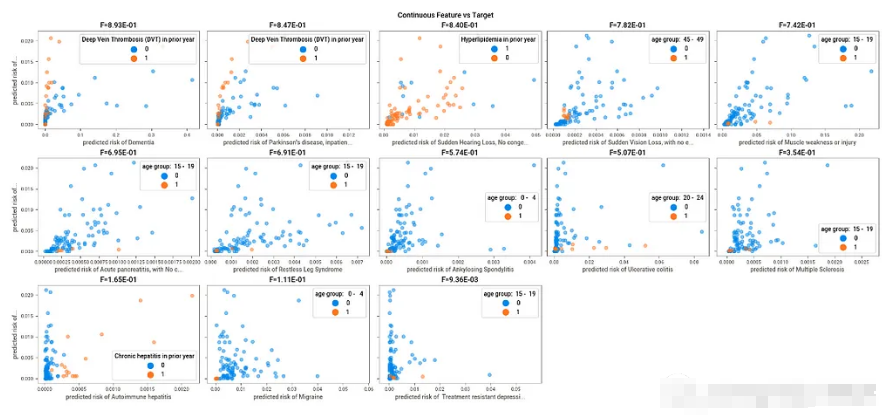
这与seaborn中的pairplot()命令非常相似。
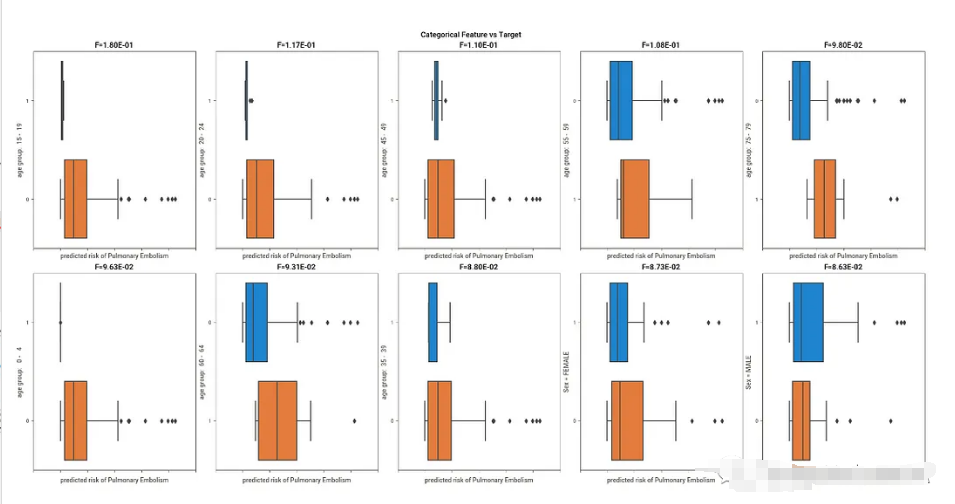
Dabl也有一些数据清理功能,并开始引入一些基本的机器学习模型,但是我觉得这些功能都太多了,没有必要。
这是一个不错的库,具有良好的双变量分析和一些额外的数据清理功能。如果已经确定了目标变量,并且只是希望观察它与其他特征的行为,那么它可能非常有用。
Sketch
它是一个基于LLM(大型语言模型)的库,只有三个命令,其中一个使用OpenAI API。这导致它有大小限制,所以我们必须取数据的一个子集。
就像其他LLM(ChatGPT)一样,Sketch使用自然语言来处理查询并产生类似人类的输出。它利用人工智能将数据分析过程转化为对话。
这三个命令是ask()、howto()和apply()。最后一个使用OpenAI的API,对数据生成很有用。第一个函数ask()将导致会话输出,而howto()将导致给出如何实现目标的代码。两者如下所示:
query="How do I plot a chart of all missing values ?"
query2="I want an overview of this dataset"
patient_data_subset=patient_data.iloc[:, :19]

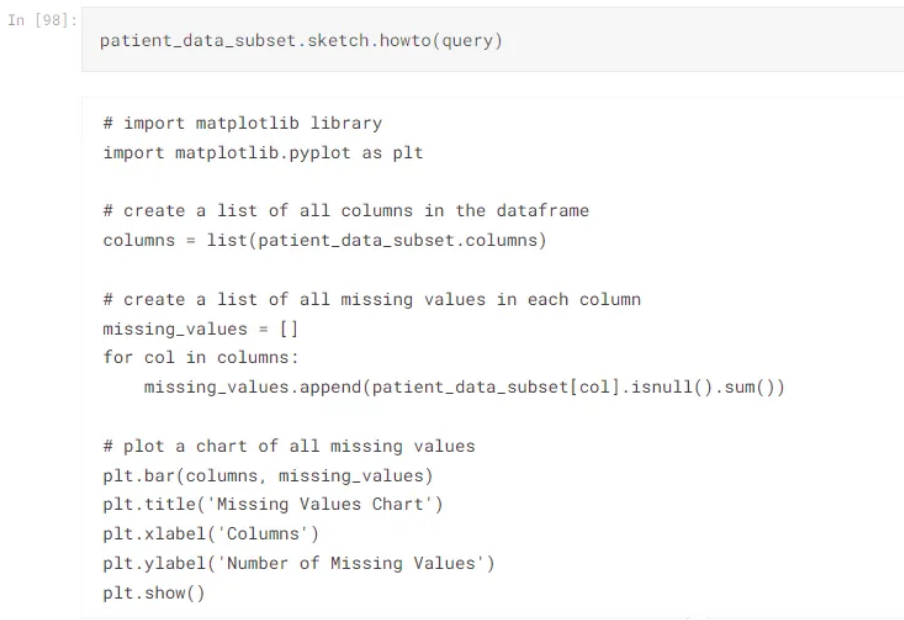
以对话的形式探索数据集是非常有趣的,从一个查询到下一个查询,直到获得所需的信息。新手和老手都可以使用howto()函数来快速生成代码块,不必从头编写整个代码,节省了时间。
Sketch允许在Jupyter中使用类似GPT的功能。但是ChatGPT也直接支持了Jupyter,可以集成到开发环境中,这使得这个库变得多余,但是如果你希望通过使用OpenAIs API密钥来避免复杂性,简单地使用Sketch作为python包是最简单的方法。
这个库可以很有趣,但是也只是有趣,并不能作为自动EDA来推荐,我提到他只是因为他包含了LLM的功能,不建议在线上使用。
总结
YData Profiling执行起来很简单,UI很直观,给了我所有的信息,这是开始EDA过程的一个很好的切入点。
D-Tale不仅是EDA过程的一个很好的起点,而且可以用来轻松地预处理数据,最主要是不需要编写任何代码,这使得它非常节省时间,并且任何人都可以轻松访问。
SweetViz的UI有点过时,但它提供了相当数量的信息,最主要的时他可以比较两个数据集。