// 【思考】代码截屏,用荧光笔标写注释
挺清晰的,虽然不太整齐了(在文末有尝试这种方法~),就是感觉 // 注释没有那么突出和强调,友友们要不讨论一下,不知道你们看起来是什么感觉,我觉得牺牲一定的美观性,来换取清晰性和重点还是挺好的,就怕你们看着乱还不清晰 orz
目录
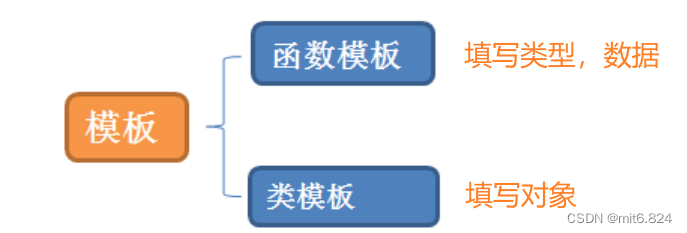
1. 泛型编程
2. 函数模板
2.1 函数模板概念
2.1 函数模板格式
2.2 函数模板的原理
2.3 函数模板的实例化
2.4 模板参数的匹配原则
3. 类模板
1. 泛型编程
如何实现一个通用的交换函数呢?
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}
//不同类型就需要重新进行重载
void Swap(double& left, double& right)
{
double temp = left;
left = right;
right = temp;
}使用函数重载虽然可以实现,但是有一下几个不好的地方:
1. 重载的函数仅仅是类型不同,代码复用率比较低,只要有新类型出现时,就需要用户自己增加对应的函数
2. 代码的可维护性比较低,一个出错可能所有的重载均出错
那能否告诉编译器一个模子,让编译器根据不同的类型利用该模子来生成代码呢?

如果在C++中,也能够存在这样一个模具,通过给这个模具中填充不同材料(类型),来获得不同材料的铸件 (即生成具体类型的代码),那将会节省许多头发。巧的是前人早已将树栽好,我们只需在此乘凉。
泛型编程:编写与类型无关的通用代码,是代码复用的一种手段。模板是泛型编程的基础。
2. 函数模板
2.1 函数模板概念
函数模板代表了一个函数家族,该函数模板与类型无关,在使用时被参数化,根据实参类型产生函数的特定类型版本。
2.1 函数模板格式
template <typename T1,typename T2...>
返回值类型 函数名(参数列表) {}
template<typename T>
void Sawp( T& left,T& right)
{
T temp = left;
left = right;
right= temp;
}注意:typename是用来定义模板参数关键字,也可以使用class(切记:不能使用struct代替class)
2.2 函数模板的原理
那么如何解决上面的问题呢?大家都知道,瓦特改良蒸汽机,人类开始了工业革命,解放了生产力。机器生产淘汰掉了很多手工产品。本质是什么,重复的工作交给了机器去完成。有人给出了论调:懒人创造世界。看一下下面这个函数模板
template<typename T> //模板定义的是类型
void Swap( T& left, T& right)
{
T temp = left;
left = right;
right = temp;
} 函数模板是一个蓝图,它本身并不是函数,是编译器用使用方式产生特定具体类型函数的模具。所以其实模板就是将本来应该我们做的重复的事情交给了编译器
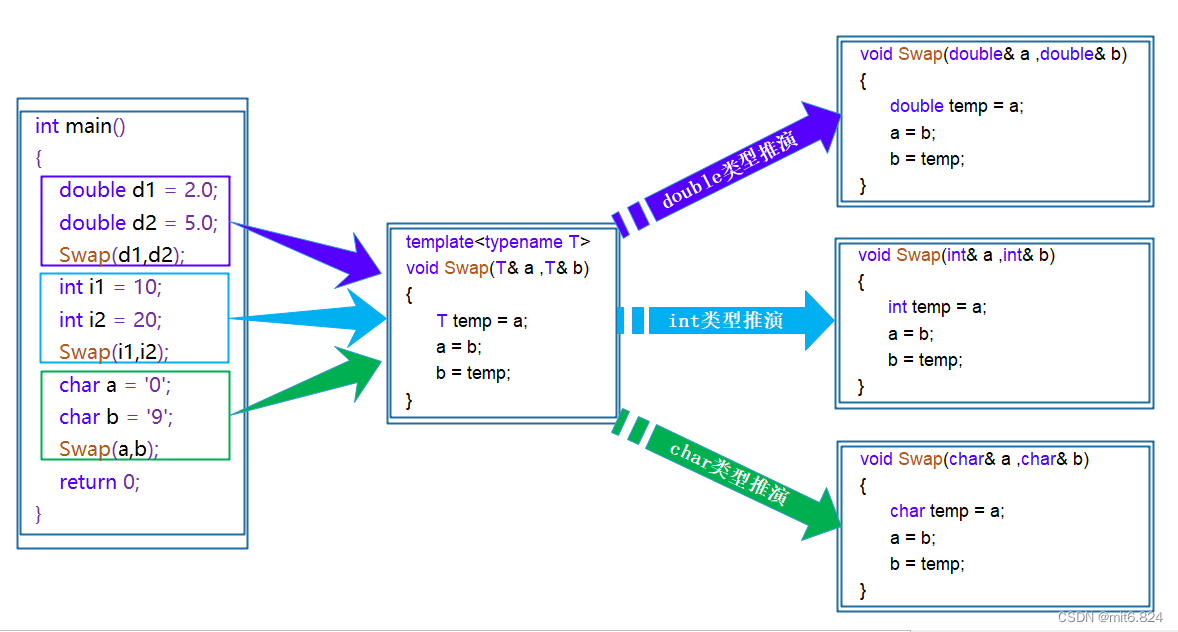
写的是T类型,编译器会自动识别传入数据的类型
在编译器编译阶段,对于模板函数的使用,编译器需要根据传入的实参类型来推演生成对应类型的函数以供调用。比如:当用double类型使用函数模板时,编译器通过对实参类型的推演,将T确定为double类型,然后产生一份专门处理double类型的代码,对于字符类型也是如此。
后面我们学到会发现swap有函数库,都不用自己定义了,直接使用库调用即可
2.3 函数模板的实例化
函数模板根据调用,自己推导模板参数的类型,实例化出对应的函数
用不同类型的参数使用函数模板时,称为函数模板的实例化。模板参数实例化分为:隐式实例化和显式实例化。
1. 隐式实例化:让编译器根据实参推演模板参数的实际类型
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
int main()
{
int a1 = 10, a2 = 20;
double d1 = 10.0, d2 = 20.0;
Add(a1, a2);
Add(d1, d2);
/*
该语句不能通过编译,因为在编译期间,当编译器看到该实例化时,需要推演其实参类型
通过实参a1将T推演为int,通过实参d1将T推演为double类型,但模板参数列表中只有一个T,
编译器无法确定此处到底该将T确定为int 或者 double类型而报错
注意:在模板中,编译器一般不会进行类型转换操作,因为一旦转化出问题,编译器就需要背黑锅
Add(a1, d1);
*/
// 此时有两种处理方式:1. 用户自己来强制转化 2. 使用显式实例化
Add(a, (int)d);//隐式转换的实现
return 0;
}
2. 显式实例化:在函数名后的<>中指定模板参数的实际类型
int main(void)
{
int a = 10;
double b = 20.0;
// 显式实例化
Add<int>(a, b);//在前面用尖括号声明,统一转化类型
return 0;
}如果类型不匹配,编译器会尝试进行隐式类型转换,如果无法转换成功编译器将会报错,但编译器的转化是不确定的,所以不要把未知交给编译器
注意:隐式变量的转化具有常性,传参要加const (const T& data)
2.4 模板参数的匹配原则
1. 一个非模板函数可以和一个同名的函数模板同时存在,而且该函数模板还可以被实例化为这个非模板函数
int Add(int left, int right)
{
return left + right;
}
// 通用加法函数
template<class T>
T Add(T left, T right)
{
return left + right;
}
void Test()
{
Add(1, 2); // 与非模板函数匹配,编译器不需要特化
Add<int>(1, 2); // 调用编译器特化的Add版本
}2. 对于非模板函数和同名函数模板,如果其他条件都相同,在调动时会优先调用非模板函数而不会从该模 板产生出一个实例。如果模板可以产生一个具有更好匹配的函数, 那么将选择模板
3. 模板函数不允许自动类型转换,但普通函数可以进行自动类型转换
3. 类模板
类模板实例化与函数模板实例化不同,类模板实例化需要在类模板名字后跟<>(然后由编译器实现),然后将实例化的类型放在<> 中即可,类模板名字不是真正的类,而显式实例化的结果才是真正的类。
T类统一的int/double等,多种种类可以设T1,T2等
以stack和vector来定义讲解 // stack和vector都是C++标准模板库(STL)中的容器。
1. stack(栈)是一种后进先出(LIFO)的数据结构,只允许在栈顶进行插入和删除操作。stack提供了push(入栈)、pop(出栈)、top(获取栈顶元素)等操作。利用类模板实现各种类型,如下:
#include<iostream>
using namespace std;
template<class T>//模板的作用就是编译器可以识别类型,进行转化
class Stack
{
public:
Stack(size_t capacity = 3)
{
_array = new T[capacity];//可以识别类型,也不用malloc啦~
_capacity = capacity;
_size = 0;
}
};
//惠普实验室 STL--标准模板库,常见的数据结构和算法的库
//要学习了解栈和队列
int main()
{
//显式实例化
Stack<int> s1;
Stack<double> s2;
Stack<char> s3;
return 0;
}2. vector(向量)是一种动态数组,可以根据需要动态调整大小。vector提供了随机访问、在末尾插入元素、在指定位置插入元素、删除元素等操作。vector的元素是连续存储的,支持通过下标快速访问元素。利用类模板实现各种类型,如下:
template<class T>
class Vector
{
public:
Vector(size_t capacity=10)
:_pDate(new T[capacity])
,_size(0)
,_capacity(capacity)
{}
// 使用析构函数演示:在类中声明,在类外定义。
~Vector();
void PushBack(const T& data);
void PopBack();
// ...
size_t Size() { return _size; }
T& operator[](size_t pos)
{
assert(pos < _size);
return _pData[pos];
}//相当于把类元素打包看成一个整体,实现之前对数组的一些简单功能
private:
T* _pData;
size_t _size;
size_t _capacity;
};
// 注意:类模板中函数放在类外进行定义时,需要加模板参数列表
template <class T>
Vector<T>::~Vector()
{
if (_pData)
delete[] _pData;
_size = _capacity = 0;
}普通类,类名和类型是一样的
类模板,类名和类型不一样
类名:Stack
类型:Stack<T>
【思考】:类和声明分离了怎么办
每个都要加 template<class T> + Stack<T>:: 来实现调用
挺重要的,有四个注意点如下: