InternVL和GPT-4V都是多模态模型,但它们在性能、参数量以及应用领域上有所不同。
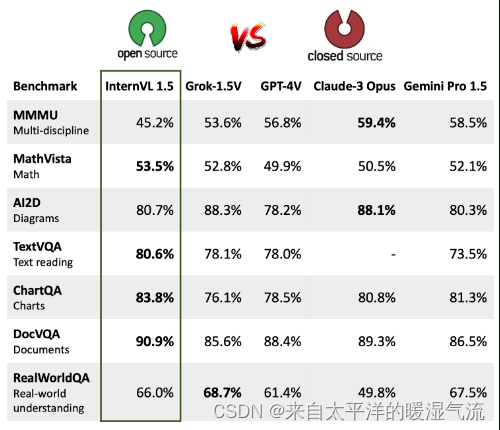
InternVL是一个开源的多模态模型,其参数量为60亿,覆盖了图像/视频分类、检索等关键任务,并在32个视觉-语言基准测试中展现了卓越性能[2]。InternVL通过全新的渐进式对齐策略,与大语言模型(LLM)组合构造多模态对话系统,具备ViT-22B同等强大的视觉能力[5]。此外,InternVL在视觉感知、跨模态检索、多模态对话等多个任务上实现了32项最先进的性能[6],并且在opencompass上的排名超过了各种闭源模型[8]。
GPT-4V是微软发布的一个大型模型,它在数学推理方面达到了49.9%的准确率,显著优于排名第二的模型[7][9][10]。GPT-4V在多模态医疗诊断领域的性能也得到了评估,尽管离临床应用与实际决策还有距离[12]。此外,GPT-4V在自动驾驶技术的新视野中开辟了新的可能性,展现了其在场景理解、因果推理和实时决策制定方面的能力[22]。
从性能对比来看,InternVL和GPT-4V各有优势。InternVL以其开源特性、较大的参数量和在多个视觉-语言基准测试中的卓越性能脱颖而出[2][5][6]。而GPT-4V则在特定领域如数学推理和自动驾驶技术中展现了其强大的能力[7][9][10]。因此,两者之间的性能对比取决于具体的应用场景和需求。如果用户需要一个强大的多模态模型用于广泛的视觉-语言任务,InternVL可能是更好的选择[2][5][6]。而对于需要在特定领域内进行深入研究或应用的用户,GPT-4V可能提供更专业的支持[7][9][10]。
InternVL模型的具体技术架构和渐进式对齐策略是如何实现的?
InternVL模型通过其具体技术架构和渐进式对齐策略实现了在互联网级别数据上视觉大模型与语言大模型的精细对齐。具体来说,InternVL模型的视觉编码器参数量达到了60亿(InternVL-6B),这一设计使得模型能够处理复杂图片中的细微视觉信息并完成图生文任务[24]。该模型首次提出了对比-生成融合的渐进式对齐技术,这种技术有效地实现了视觉大模型与语言大模型之间的精准匹配[26]。
渐进式对齐策略的具体实现方式是通过一种训练策略逐步进行的。这个过程从大规模嘈杂数据上的对比学习开始,逐渐过渡到精致和高质量数据上的生成学习[25]。InternVL的训练分为三个递进阶段:视觉语言对比训练、视觉语言生成训练和监督微调。这些阶段有效地利用了来自不同来源的公共数据,从网络上嘈杂的图像文本对到高质量的标题、VQA和多模态对话数据集[28]。这种分阶段的训练方法不仅提高了模型的性能,也增强了其在各种视觉任务中的应用能力,如纯视觉感知、图文检索、图文生成、图文多模态生成和对话等[33]。
此外,InternVL模型还通过将ViT模型扩展到60亿参数并与语言模型对齐,构建出目前最大的14B开源视觉基础模型。这表明InternVL模型在视觉感知、跨模态检索、多模态对话等广泛任务中具有强大的能力[29]。通过这种设计,InternVL模型不仅推动了视觉与视觉语言基础模型的发展与应用,还实现了视觉感知任务的最新性能、多模式对话系统的构建和与大型语言模型的链接[30]。
GPT-4V在多模态医疗诊断领域的应用案例有哪些?
GPT-4V在多模态医疗诊断领域的应用案例主要包括以下几个方面:
- 医学影像分析:GPT-4V能够对医学影像进行准确的识别和分析,包括成像模态、成像位置和成像轴面的识别。它能够判断出是MRI、CT等不同类型的医学影像,并指出拍摄部位(如胸部或头部)以及拍摄的轴面(如横断面或矢状面)[39]。
- 医学诊断和治疗:GPT-4V在医学诊断和治疗方面的应用体现在其能够提供临床决策支持。例如,在USMLE(美国医学执照考试)中,GPT-4V的表现超过了其他两个先进的大型语言模型(LLMs),显示出其在临床决策支持方面的潜力[37]。
- 医学大数据分析:GPT-4V的应用还扩展到了医学大数据分析领域,尽管具体的案例细节未在证据中提及,但可以推断,其在处理和分析大量医学数据方面具有潜在的能力[34]。
- 医学报告生成:GPT-4V能够基于病理图像生成结构化且详细的报告,描述图像特征。这表明它不仅能够理解和分析医学影像,还能将这些信息转化为易于理解的报告,为医生提供辅助诊断的信息[43]。
- 医学视觉问答(VQA)和视觉定位(Visual Grounding):GPT-4V在医学视觉问答和视觉定位方面的应用,通过生成放射学报告、进行医学视觉问答和视觉定位展示了其在处理和理解医学影像方面的多模态能力[35][36]。
- 临床相关性确认:在具体的病例分析中,GPT-4V能够针对提供的图像提出相关建议,例如,在一个迷走神经刺激器的X射线VQA示例中,GPT-4V能够指出未检测到急性心肺异常,并建议考虑临床相关性进一步确认[41]。
GPT-4V在多模态医疗诊断领域的应用案例涵盖了从医学影像分析、医学诊断和治疗、医学大数据分析到医学报告生成等多个方面,展现了其在医疗领域内的广泛应用潜力。
InternVL与GPT-4V在图像/视频分类和检索任务上的性能对比数据是什么?
InternVL和GPT-4V在图像/视频分类和检索任务上的性能对比数据如下:
- GPT-4V在SSV1数据集上的性能表现不佳,其top-1准确率仅为4.6%,与clip基线一致[44]。这表明GPT-4V在特定的视觉识别任务上存在明显的性能瓶颈。
- InternVL被描述为能够广泛应用于视觉感知任务(例如图像级或像素级识别)、视觉语言任务(例如零样本图像/视频分类、零样本图像)并实现最先进的性能/视频文本检索[46]。此外,InternVL在零样本图像分类和图像-文本检索等对比任务中表现出色[49]。
- 在另一项研究中,InternVL相比于最先进的clip模型,在分类准确率上取得了平均1.8%的提升[47]。这表明InternVL在图像分类任务上具有较强的性能。
- GPT-4V支持多个图像作为输入,因此可以应用于视频中跨帧的关联视觉对象[48]。这表明GPT-4V在处理多图像输入方面具有一定的能力,但具体的性能数据未在证据中给出。
InternVL在图像/视频分类和检索任务上表现优于GPT-4V,尤其是在零样本图像分类和图像-文本检索任务上。GPT-4V虽然在处理多图像输入方面显示出一定的能力,但在特定的视觉识别任务上存在性能瓶颈。因此,如果考虑将这些技术应用于实际的图像/视频分类和检索任务,InternVL可能是更优的选择。
GPT-4V在自动驾驶技术中的具体应用场景和效果评估报告。
GPT-4V在自动驾驶技术中的具体应用场景和效果评估报告主要集中在几个方面:情景理解、意图识别、驾驶决策以及处理分布外(OOD)情况的能力。
- 情景理解:GPT-4V展现出了卓越的情景理解能力,这包括了对驾驶时的天气和光照条件的识别,不同国家的交通信号灯和标志的识别,以及不同类型摄像头拍摄的内容的理解[55]。这种能力使得GPT-4V能够准确评估周围环境,为自动驾驶车辆提供必要的信息。
- 意图识别:GPT-4V在识别交通参与者的意图方面表现出色。它能够利用多视角图像和时间照片实现对环境的完整感知,准确识别交通参与者之间的动态互动,并推断出这些行为背后的潜在动机[58]。这一点对于确保自动驾驶车辆的安全行驶至关重要。
- 驾驶决策:在驾驶决策方面,GPT-4V展现了超越现有自动驾驶系统的潜力。它不仅能够在corner case中利用其先进的理解能力来处理分布外的情况,还能做出明智的驾驶决策[51][60]。这意味着GPT-4V能够在复杂和不确定的驾驶环境中保持高度的安全性和可靠性。
- 处理分布外(OOD)情况的能力:GPT-4V特别强调了其在处理分布外情况方面的能力。这表明GPT-4V不仅能够应对常规的驾驶场景,还能够适应那些未见过或罕见的情况,从而大大增强了自动驾驶系统的鲁棒性和适应性[58]。
GPT-4V在自动驾驶技术中的应用展现了其在情景理解、意图识别、驾驶决策以及处理分布外情况方面的强大能力。这些能力使得GPT-4V成为推动自动驾驶技术发展的重要力量,有望在未来实现更安全、更智能的自动驾驶解决方案。
InternVL开源模型的社区反馈和实际使用情况如何?
InternVL开源模型在社区中的反馈和实际使用情况显示了其在多模态大模型领域的应用和发展。首先,从性能角度来看,InternVL被列为增强大型视觉语言模型性能的著名示例之一,这表明它在技术上具有一定的先进性和实用性[63]。此外,InternVL在与EVA-CLIP-18B模型的比较中,实现了平均1.8%的分类准确率提升,这一数据进一步证明了InternVL在实际应用中的有效性和优越性[64]。
然而,也有证据显示InternVL在某些方面存在不足。例如,在真实视障场景测试集VizWiz中,XVERSE-V的表现超过了InternVL-Chat-V1,这可能意味着InternVL在特定应用场景下的表现不是最优的[62]。尽管如此,这种比较并不足以全面否定InternVL的整体表现和价值,因为每个模型都有其特定的优势和局限性。
InternVL开源模型在社区中的反馈和实际使用情况总体上是积极的,它被认为是增强大型视觉语言模型性能的有效工具之一。尽管存在一些局限性,但这些局限性并不影响其在多模态大模型领域的应用价值和发展潜力。
参考资料
1. Gpt-4v (20240409) 测试报告 - 知乎 - 知乎专栏 [2024-04-25]
2. InternVL:开源版GPT4V - 沸点 - 稀土掘金 [2024-04-27]
3. 如何评价GPT-4V(ision)? - 知乎
4. GPT-4V被超越?SEED-Bench多模态大模型测评基准更新 - TechBeat [2023-12-12]
5. InternVL:开源社区最强的多模态大模型 - 知乎专栏
6. 项目详情| SOTA!模型社区 [2023-12-27]
7. GPT-4V数学推理如何?微软发布MathVista基准,评测报告长达112页 [2023-11-14]
8. InternVL V1.5当前最强开源多模态大模型 - 知乎 - 知乎专栏 [2024-04-18]
9. GPT-4V数学推理如何?微软发布MathVista基准,评测报告长达112页 [2023-11-13]
10. GPT-4V数学推理如何?微软发布MathVista基准,评测报告长达112页 [2023-11-13]
11. 开源多模态LLM InternVL 1.5:具备OCR能力可解读4K图片 - 站长之家 [2024-04-30]
12. GPT-4V医疗领域全面测评,离临床应用与实际决策尚有距离 [2023-11-06]
13. InternVL-V1.2来了,最强的MMMU性能开源实现 - 知乎专栏 [2024-02-21]
14. 上海AI 实验室发布新一代书生·视觉大模型 - 开源中国 [2024-01-30]
15. 原创AI:上海AI实验室近期科研成果速览(部分)
16. InternVL:60亿参数视觉语言基础模型填补多模态AGI的差距 - 凤凰网 [2023-12-28]
17. InternVL 1.5:缩小开源模型与商业模型在多模态理解方面的差距 [2024-04-28]
18. InternVL:GPT-4V开源替代方案最接近GPT-4V 表现的可商用开源模型 [2024-04-30]
19. AI领域新突破:InternVL 1.5模型在多模态理解上取得显著进展 [2024-04-30]
20. 最接近GPT-4V的开源多模态大模型 [2024-04-28]
21. OpenGVLab/InternVL-Chat-V1-5 · Hugging Face - 齐思 - 奇绩创坛 [2024-04-26]
22. GPT-4V自动驾驶深度评测首发(AI Lab) - 知乎 - 知乎专栏
23. A Deep Dive into GPT-4V: Capabilities, Limitations, and the Future of ... [2023-11-05]
24. 上海AI实验室发布新一代书生·视觉大模型
25. InternVL 原创 - CSDN博客 [2023-12-28]
26. AI 相关话题- NXP(恩智浦)半导体IC芯片全系列-亿配芯城
27. 上海AI实验室发布新一代书生·视觉大模型 - 凤凰网
28. 刷新多个SOTA!多模态大模型InternVL开源视觉基础模型扩展到60亿个参数,可实现像素级识别 作者: 人工智能技术与时代人物风云 来源 ... [2024-01-02]
29. InternVL使用入口地址Ai模型最新工具和软件app下载 - AIbase
30. InternVL:扩展视觉基础模型并对通用视觉语言任务进行对齐 | BriefGPT - AI 论文速递
31. 刷新多个SOTA!多模态大模型InternVL开源视觉基础模型扩展到60亿 ... [2024-01-02]
32. OpenGVLab/清华/南大/商汤/港大/港中文/中科大开源InternVL,首次将大规模视觉编码器与LLMs进行对齐,检测/分割/对话 ... [2023-12-26]
33. 上海AI实验室发布新一代书生·视觉大模型,视觉核心任务开源领先
34. GPT-4V:AI在医疗领域的应用原创 - CSDN博客 [2023-11-06]
35. A Comprehensive Study of GPT-4V's Multimodal Capabilities in Medical ... [2023-11-04]
36. A Comprehensive Study of GPT-4V's Multimodal Capabilities in Medical ...
37. PDF Performance of Multimodal GPT-4V on USMLE with Image: Potential for ... [2023-10-26]
38. GPT-4V:AI在医疗领域的应用 - 搜狐 [2023-11-06]
39. 医疗领域gpt-4v初测评 - 知乎 - 知乎专栏
40. 人工打分平均超越GPT-4V、支持2D/3D放射影像 - 澎湃新闻 [2023-12-05]
41. 诊断所有病例| GPT-4V 在多模态医学诊断方面的能力进行系统评估 [2023-12-31]
42. GPT-4V:AI在医疗领域的应用 - 知乎专栏 [2023-11-05]
43. 128个案例,GPT-4V医疗领域全面测评,离临床应用与实际决策尚有 ... [2023-11-06]
44. GPT4Vis: What Can GPT-4 Do for Zero-shot Visual Recognition?-全文翻译+解读
45. InternVL InternVL InternVL 1.5:开源多模态LLM 最高支持解读4K图片,有OCR能力,中文能力优秀。 在线体验 ...
46. InternVL: Scaling up Vision Foundation Models and ... - X-MOL [2023-12-25]
47. Eva-clip-18b:性能最强的开源clip视觉大模型 - Oschina - 中文开源技术交流社区 [2024-02-11]
48. 在视觉提示中加入「标记」,微软等让GPT-4V看的更准、分的更细 [2023-10-24]
49. ViT-22B被取代了!60亿视觉参数刷爆多模态榜单!上海AI Lab提出InternVL! - 知乎 [2023-12-26]
50. 探索GPT-4:语言与视觉能力在视觉识别任务的表现 - 知乎专栏
51. GPT-4V在自动驾驶上应用前景如何?面向真实场景的全面测评来了 [2023-11-22]
52. GPT-4V大模型在自动驾驶真实场景下的评测 - 腾讯 [2023-11-13]
53. 来了来了!GPT-4V大模型在自动驾驶真实场景下的评测 - CSDN博客 [2023-11-13]
54. AI技术的新里程碑:GPT-4V在自动驾驶领域的探索 - 百度开发者中心 [2024-01-21]
55. GPT-4V在自动驾驶上应用前景如何?面向真实场景的全面测评来了 [2023-11-20]
56. 看看GPT-4V是怎么开车的,必须围观,大模型真的大有作为!!!
57. 看看GPT-4V是怎么开车的,必须围观,大模型真的大有作为!!! [2023-11-19]
58. Gpt-4v在自动驾驶上应用前景如何?面向真实场景的全面测评来了 - 知乎 [2023-11-20]
59. 看看GPT-4V是怎么开车的,必须围观,大模型真的大有作为!!! [2023-11-18]
60. GPT-4V在自动驾驶上应用前景如何?面向真实场景的全面测评来了 [2023-11-20]
61. 项目详情| SOTA!模型社区
62. 国产多模态大模型开源!无条件免费商用,性能超Claude 3 Sonnet [2024-04-30]
63. MoE-LLaVA:大型视觉语言模型的专家组合 - Unite.AI [2024-04-23]
64. EVA-CLIP-18B:性能最强的开源CLIP视觉大模型 - 智源社区 [2024-02-08]









![[软件工具]批量根据文件名查找PDF文件复制到指定的地方,如何批量查找文件复制,多个文件一起查找复制](https://img-blog.csdnimg.cn/img_convert/692bd908f35322a9272095f8fd0df5d0.webp?x-oss-process=image/format,png)