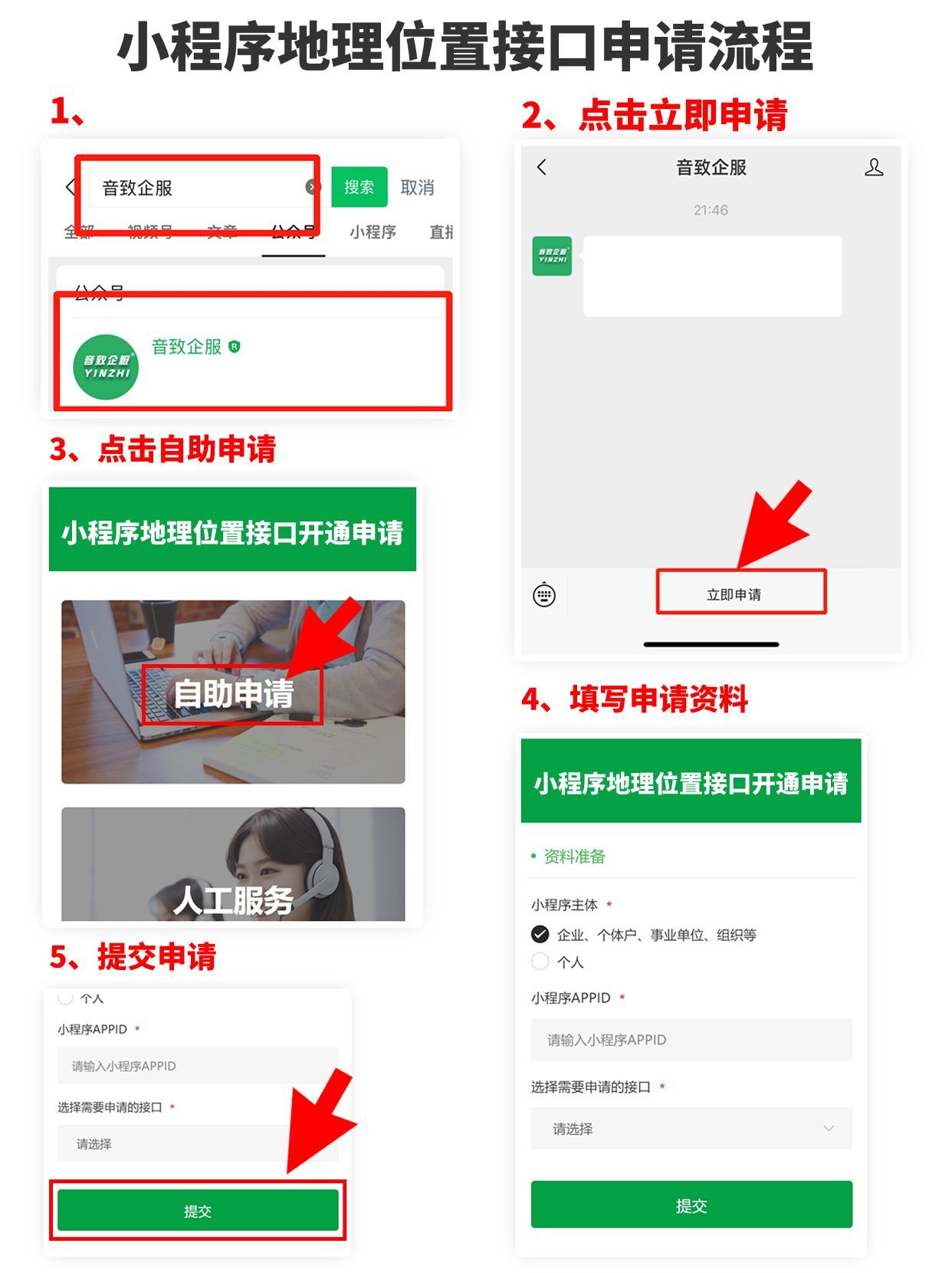
1. 数据集
fashion mnist是一个由10个类别图像组成的服装分类数据集,共包含60000张训练集图像和10000张测试集图像, 前者用于训练模型参数,后者用于评估模型性能。
2.1 数据集下载
先进行依赖库导入:
%matplotlib inline # jupyter魔法命令,用于显示matplotlib生成的图形。
import torch # 用于构建和训练深度学习模型。
import torchvision # pytorch视觉工具库,用于处理图像数据。
from torch.utils import data # 一些数据处理的工具类
from torchvision import transforms # 图像转换和增强
from d2l import torch as d2l
d2l.use_svg_display() # 使用svg来显示图片,清晰度更高
接下来使用框架内置函数来下载数据集并读取到内存中,数据集大概在100MB左右。
# ToTensor:图像预处理,将图像数据转为tensor格式
trans = transforms.ToTensor()
# 从网上下载训练数据集,并通过transform转换
mnist_train = torchvision.datasets.FashionMNIST(
root="../data", train=True, transform=trans, download=True)
# 从网上下载验证数据集,并通过tranform转换为张量
mnist_test = torchvision.datasets.FashionMNIST(
root="../data", train=False, transform=trans, download=True)
数据集下载和解析的过程如下,以train开头的为训练集,以t10k开头的为测试集:
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz
Using downloaded and verified file: ../data/FashionMNIST/raw/train-images-idx3-ubyte.gz
Extracting ../data/FashionMNIST/raw/train-images-idx3-ubyte.gz to ../data/FashionMNIST/raw
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-labels-idx1-ubyte.gz
Using downloaded and verified file: ../data/FashionMNIST/raw/train-labels-idx1-ubyte.gz
Extracting ../data/FashionMNIST/raw/train-labels-idx1-ubyte.gz to ../data/FashionMNIST/raw
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz to ../data/FashionMNIST/raw/t10k-images-idx3-ubyte.gz
100.0%
Extracting ../data/FashionMNIST/raw/t10k-images-idx3-ubyte.gz to ../data/FashionMNIST/raw
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-labels-idx1-ubyte.gz
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-labels-idx1-ubyte.gz to ../data/FashionMNIST/raw/t10k-labels-idx1-ubyte.gz
100.0%
Extracting ../data/FashionMNIST/raw/t10k-labels-idx1-ubyte.gz to ../data/FashionMNIST/raw
每张图像28*28像素,全部为灰度图像,通道数为1,形状如下:
len(mnist_train), len(mnist_test), mnist_train[0][0].shape, mnist_test[0][0].shape
> (60000, 10000, torch.Size([1, 28, 28]), torch.Size([1, 28, 28]))
数据图形示例如下:

1.2 数据读取
同前面的线性回归一样,我们采用小批量数据读取来训练和测试模型,所以需要封装一个小批量数据读取的迭代器。
batch_size = 256
workers = 4
train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=workers)
test_iter = data.DataLoader(mnist_test, batch_size, shuffle=False,
num_workers=workers))
- batch_size: 分批的批次大小
- shuffle: 置为True可以打乱样本顺序,随机读取
- num_workers: 使用多少个进程来并发读取数据
train_iter和test_iter都是一个数据迭代器,可以理解为集合中的iterator,只不过每次迭代的不是一条数据,而是batch_size大小的小批量数据集。
以train_iter为例输出下形状:
for X, y in train_iter:
print(X.shape, X.dtype, y.shape, y.dtype)
break
> torch.Size([256, 1, 28, 28]) torch.float32 torch.Size([256]) torch.int64
读数据是常见的性能瓶颈,训练之前最好先测试下数据读取速度。
timer = d2l.Timer()
for X, y in train_iter:
continue
f'{timer.stop():.2f} sec'
# 使用1个进程读取数据
> '10.63 sec'
# 使用4个进程读取数据
> '5.77 sec'
到这里,已经准备好Fashion-MNIST数据集,下面可以有它来训练和评估分类算法性能。
2. 模型
2.1 初始化模型参数
原始数据集中的每个样本都是28x28的图像,每个图像都有784个像素,可以理解为784个特征,我们可以把输入数据都看作长度为784的向量。
前文提到过,在softmax回归中,输出与类别一样多。 因为我们的数据集有10个类别,所以网络模型的输出维度为10。 因此,权重W将构成一个784x10的矩阵, 偏置b将构成一个长度为10的行向量。
num_inputs = 784
num_outputs = 10
# 与线性回归一样,使用正态分布初始化我们的权重W,偏置初始化为0。
W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)
b = torch.zeros(num_outputs, requires_grad=True)
2.2 定义softmax操作
参考前文,实现softmax由三个步骤组成:
- 对每个项求幂(使用exp);
- 对每一行求和(小批量中每个样本是一行),得到每个样本的规范化常数;
将每一行除以其规范化常数,确保结果的和为1。
数学表达式如下:
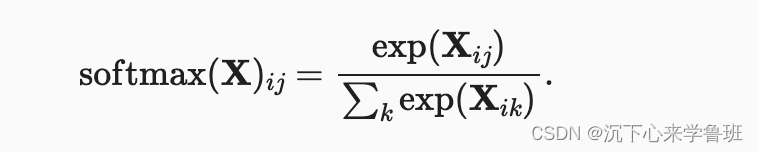
代码实现:
def softmax(X):
X_exp = torch.exp(X)
partition = X_exp.sum(1, keepdim=True) # 这里的1表示坐标轴1,即每一行的所有列求和
return X_exp / partition # 这里应用了广播机制
接下来验证是否正确,主要在于两方面:
- 所有元素是否为正
- 每一行的和是否为1
X = torch.normal(0, 1, (2, 5)) # 均值为0,标准差为1,2行5列的元素
X_prob = softmax(X)
X_prob, X_prob.sum(1)
> (tensor([[0.1686, 0.4055, 0.0849, 0.1064, 0.2347],
[0.0217, 0.2652, 0.6354, 0.0457, 0.0321]]),
tensor([1.0000, 1.0000]))
2.3 定义模型
模型定义了如何将输入数据通过网络映射到输出。
def net(X):
return softmax(torch.matmul(X.reshape((-1, W.shape[0])), W) + b)
- X.reshape((-1, W.shape[0])): 将输入X的形状由4维矩阵[256, 1, 28, 28]调整为2维矩阵[256, 784],0维为批量大小,1维为向量W的0维长度784
- 与线性回归一样,使用torch.matmul来计算矩阵X与向量W的矩阵向量积,再加上偏置b就是线性输出
- 对线性输出softmax就得到各个类别的预测概率
2.4 定义损失函数
前文提到,交叉熵可以认为是真实标签的预测概率的负对数。那在计算交叉熵之前要先拿到真实标签的预测概率。
拿下面的样本数据来说明,y_hat是一个包含2个样本在3个类别的预测概率, y是对应的真实标签,采用下标来表示类别。
y = torch.tensor([0, 2, 1])
y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5], [0.075, 0.88, 0.045]])
样本1中,第一类是正确的预测,预测概率为0.1;
样本2中,第三类是正确的预测,预测概率为0.5;
样本3中,第二类是正确的预测,预测概率为0.88;
方法一:采用循环:
result = []
for i in range(len(y)):
result.append(y_hat[i, y[i]])
torch.tensor(result)
> tensor([0.1000, 0.5000, 0.8800])
方法二:直接将y作为y_hat中概率的索引,因为y中存放的正确类别下标与y_hat中是对应的。
y_hat[[0, 1, 2], y]
> tensor([0.1000, 0.5000, 0.8800])
- y_hat[[0, 1, 2], y] 本质上与常规二维数组索引方式y_hat[i, j]形式相同,不同点在于i、j不再是具体的数字,因为要一次性取多个样本的预测值;
- i = [0, 1, 2]表示行方向上取第0、1、2三个样本;
- j = y表示三个样本列方向分别取第0, 2, 1个元素;
- 最终取出的元素是y_hat张量中第0行的第0列、第1行的第2列和第2行的第1列;
方法二比方法一要简单很多,由于是python内置语法,运行效率也更高。这样只需一行代码就可以实现交叉熵损失函数。
def cross_entropy(y_hat, y):
return - torch.log(y_hat[range(len(y_hat)), y])
cross_entropy(y_hat, y)
> tensor([2.3026, 0.6931, 0.1278])
- 第1个正确值的概率只有0.1,所以计算出来交叉熵损失2.3026就比较大;
- 第2个正确值的概率有0.5,所以交叉熵0.6931也有所收敛;
- 第3个正确值 的概率较高0.88, 所以交叉熵0.1278就比较小;
2.4 分类精度
给定预测概率分布y_hat,当我们必须输出预测类别时,我们通常会选择预测概率最高的类别来作为预测结果,但预测概率高的类别有时候不一定是正确预测,这时候就产生了错误预测。
就如同上面第一个样本数据中,预测概率最高的0.6并非正确类别,实际正确类别的预测概率只有0.1。
我们需要一个指标来衡量模型预测的正确率,称之为分类精度,它是正确预测数量与总预测数量之比。
以上面的y和y_hat示例数据为例,可以通过如下步骤来计算分类精度:
- 使用argmax获得每行中最大元素的索引来获得预测类别。
- 将预测类别与真实y元素进行等值比较,比较前需要将y_hat的数据类型转换为与y的数据类型一致,因为等式运算符“==”对数据类型很敏感,
- 结果是一个包含0(错)和1(对)的张量,进行求和就可以得到正确预测的数量。
代码实现如下:
def accuracy(y_hat, y): #@save
"""计算预测正确的数量"""
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1)
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())
以上面的数据来测试:
accuracy(y_hat, y) / len(y)
> 0.6666666666666666
- 第一个样本的预测错误,预测概率最大的索引2(概率0.6)与正确标签0不一致。
- 第二个样本的预测正确,预测概率最大的索引2(概率0.5)与正确标签2一致。
- 第三个样本的预测正确,预测概率最大的索引1(概率0.88)与正确标签1一致。
由于我们采用的是小批量多轮迭代训练,会有产生多轮预测数据,所以我们需要封装一个能支持多轮迭代的精度计算函数(主要用于训练后的精度测试)。
# @param net: 网络模型,用于对输入数据X进行类别预测,输出预测概率
# @param data_iter: 数据迭代器,每一轮迭代都包含输入数据X和对应的标签y
def evaluate_accuracy(net, data_iter): #@save
"""计算在指定数据集上模型的精度"""
metric = Accumulator(2) # 2个元素的累加器,用于统计正确预测数、预测总数;
with torch.no_grad():
for X, y in data_iter:
metric.add(accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
步骤解读:
- 先用模型net对输入X进行类别预测,得到预测概率;
- 再使用accuracy对预测结果和真实标签计算精度,并把精度和标签数量进行累加;
- 返回模型在数据集上的精度,正确预测数与总预测数的比值。
3. 训练
3.1 定义参数更新函数
这里我们复用线性回归中定义的参数优化函数sgd(小批量随机梯度下降),学习率设为0.1。
lr = 0.1
def updater(batch_size):
return d2l.sgd([W, b], lr, batch_size)
3.2 定义单轮迭代训练流程
def train_epoch_ch3(net, train_iter, loss, updater): #@save
"""训练模型一个迭代周期(定义见第3章)"""
# 长度为3的累加器,分别累加训练损失总和、训练准确度总和、样本数
metric = Accumulator(3)
for X, y in train_iter:
# 使用模型来计算得到预测概率
y_hat = net(X)
# 计算损失
l = loss(y_hat, y)
# 反向累积计算梯度
l.sum().backward()
# 更新优化参数
updater(X.shape[0])
# 累加损失、精度、样本数
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
# 返回训练损失和训练精度
return metric[0] / metric[2], metric[1] / metric[2]
3.3 定义整体训练流程
整体训练流程比较简单,就是循环执行多轮训练,每轮训练后参数都会得到更新,再拿测试数据集基于更新的参数去执行模型当前的表现,得到一个精度值。
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): #@save
"""训练模型(定义见第3章)"""
for epoch in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter)
print(f"epoch: {epoch + 1}, loss: {train_metrics[0]}, test_acc: {test_acc}")
3.4 运行训练
基于前面定义的模型,进行10次迭代训练:
num_epochs = 10
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, updater)
- num_epochs: 迭代训练次数
- net: 网络模型
- train_iter: 训练数据集
- test_iter: 测试数据集,用于测试模型训练后的性能
- cross_entropy: 损失函数
- updater: 参数优化器
整个训练过程中的损失和测试精度变化:
epoch: 1, loss: 0.7857203146616618, test_acc: 0.7882
epoch: 2, loss: 0.5686315283457438, test_acc: 0.7985
epoch: 3, loss: 0.5252757650375366, test_acc: 0.8192
epoch: 4, loss: 0.5007046510060629, test_acc: 0.8231
epoch: 5, loss: 0.4856935443242391, test_acc: 0.8196
epoch: 6, loss: 0.4738648806254069, test_acc: 0.8249
epoch: 7, loss: 0.46540179011027016, test_acc: 0.8299
epoch: 8, loss: 0.45916082598368324, test_acc: 0.8271
epoch: 9, loss: 0.45219682502746583, test_acc: 0.833
epoch: 10, loss: 0.4484250022888184, test_acc: 0.8328
可以看出,随着训练的不断迭代,损失在持续减小,测试精度虽然有略微起伏,但总体上也是在不断提升。
4. 预测
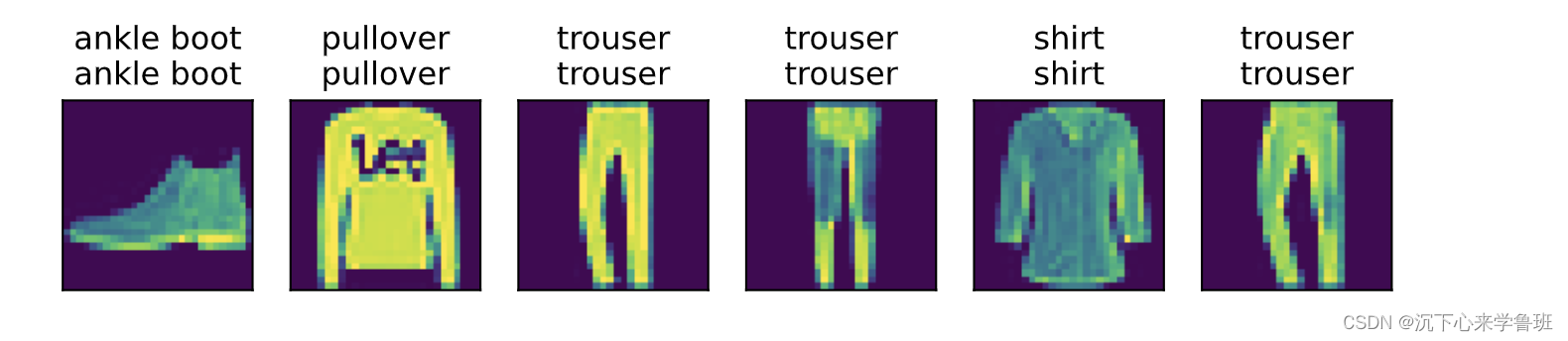
使用训练好的模型对图像进行分类预测,比较图像的实际标签和模型预测是否相同:
def predict_ch3(net, test_iter, n=6): #@save
"""预测标签(定义见第3章)"""
for X, y in test_iter:
break
trues = d2l.get_fashion_mnist_labels(y)
preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1))
titles = [true +'\n' + pred for true, pred in zip(trues, preds)]
d2l.show_images(
X[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])
predict_ch3(net, test_iter)
结果如下:
总结
本文softmax分类模型与前面线性回归模型的整体训练过程比较相似:先读取数据,再定义模型和损失函数,然后使用优化算法训练模型。大多数常见的深度学习模型都有类似的训练过程。





![[游戏陪玩系统] 陪玩软件APP小程序H5游戏陪玩成品软件源码-线上线下可爆改家政,整理师等功能](https://img-blog.csdnimg.cn/direct/e756cae400a140589a61e53490c5d280.png)