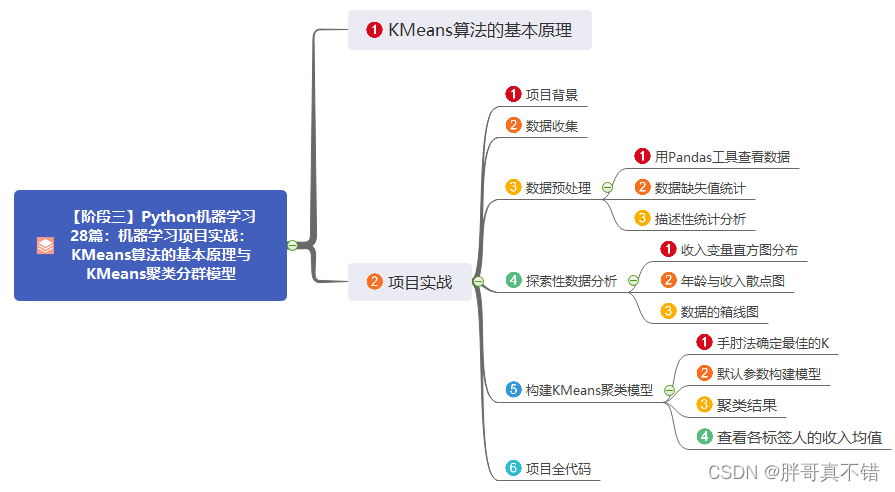
本篇的思维导图:
KMeans模型
KMeans算法的基本原理
KMeans算法名称中的K代表类别数量,Means代表每个类别内样本的均值,所以KMeans算法又称为K-均值算法。KMeans算法以距离作为样本间相似度的度量标准,将距离相近的样本分配至同一个类别。样本间距离的计算方式可以是欧氏距离、曼哈顿距离、余弦相似度等,KMeans算法通常采用欧氏距离来度量各样本间的距离。
KMeans算法的核心思想是对每个样本点计算到各个中心点的距离,并将该样本点分配给距离最近的中心点代表的类别,一次迭代完成后,根据聚类结果更新每个类别的中心点,然后重复之前操作再次迭代,直到前后两次分类结果没有差别。如下图所示的简单案例解释了KMeans算法的原理,该案例的目的是将8个样本点聚成3个类别(K=3)。
【阶段三】Python机器学习28篇:机器学习项目实战:KMeans算法的基本原理与KMeans聚类分群模型
news2026/2/11 7:40:11
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/163595.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
QListWidget 自定义 item的图标和文字的位置
目录前言思路一思路二思路二缺陷思路三思路四前言
楼主并没有完整的解决这个问题,如果你是着急寻找解决方案的就可以划走了,如果你对楼主的解决思路有兴趣,那么可以继续向下阅读。首先需求是可以控制QListWidgetItem的icon和text x轴的位置&…
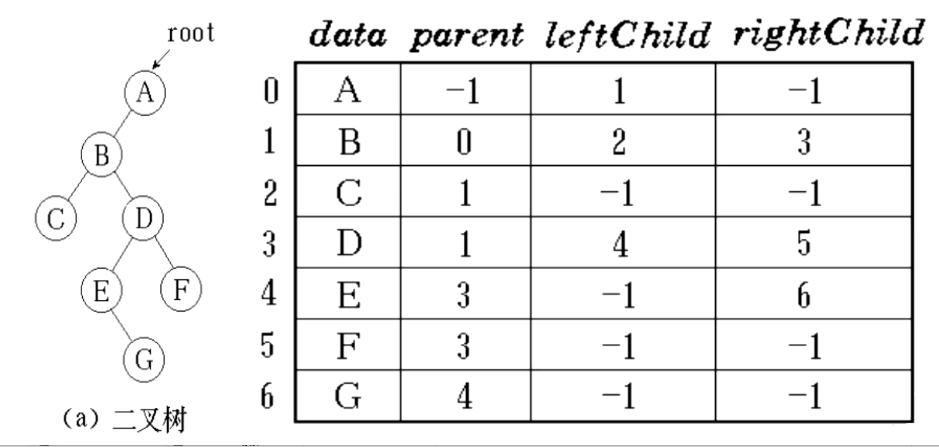
【树】树、二叉树的基础知识
树定义:树是n(n≥0)个结点的有限集合T。当n0时,称为空树;当n>0时,该集合满足如下条件: (1) 其中必有一个称为根(root)的特定结点,它没有直接前驱ÿ…
基于javaweb jsp+servlet学生宿舍管理系统
基于javaweb jspservlet学生宿舍管理系统 博主介绍:5年java开发经验,专注Java开发、定制、远程、文档编写指导等,csdn特邀作者、专注于Java技术领域 作者主页 超级帅帅吴 Java毕设项目精品实战案例《500套》 欢迎点赞 收藏 ⭐留言 文末获取源码联系方式 …
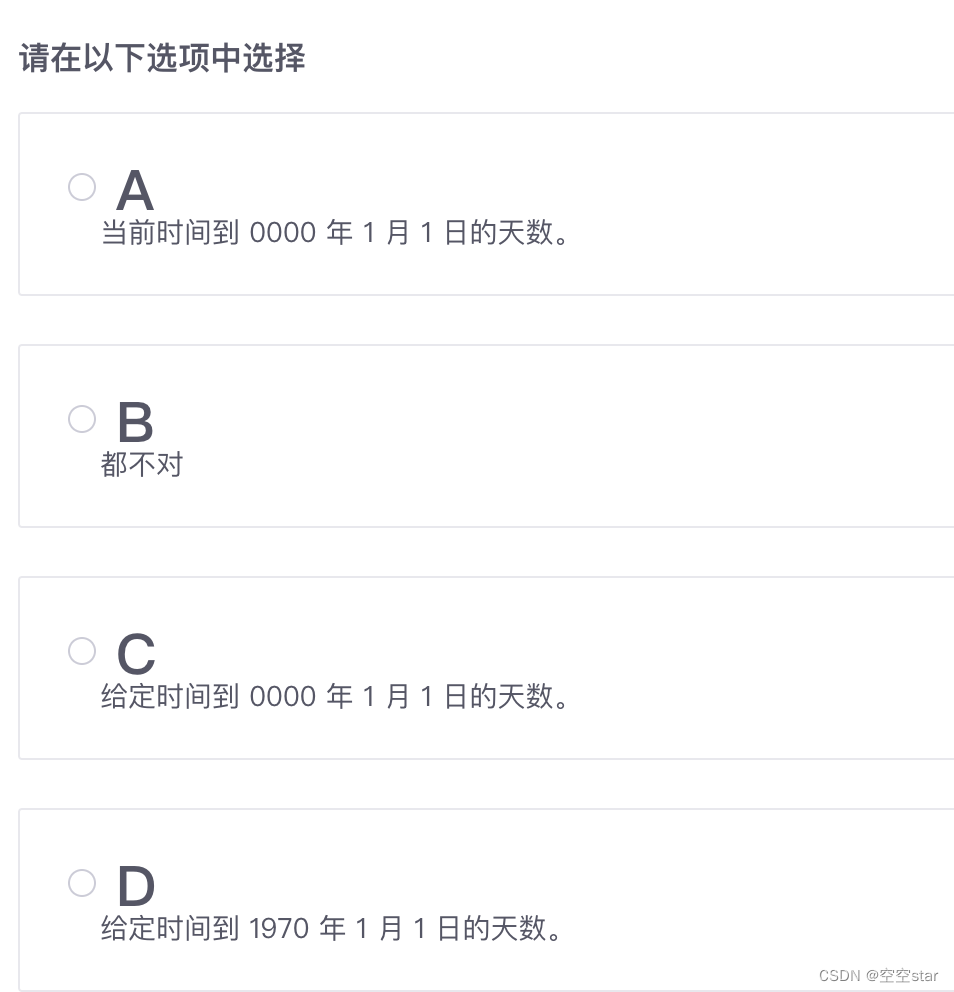
Mysql入门技能树-时间日期函数(一)-练习篇
DAY
Joe 需要从日期中提取当天是几号,下列哪些函数可以实现这个功能?
1.DAY 2.DAYOFMONTH 3.DAYOFYEAR 4.TO_DAYS 答案是:C
SELECT DAY(2023-02-14)SELECT DAYOFMONTH(2023-02-14)结果都是14
-- 返回 d 是一年中的第几天,范围…
【学习笔记】【Pytorch】九、非线性激活
【学习笔记】【Pytorch】九、非线性激活学习地址主要内容一、前言二、Pytorch的非线性激活三、nn.ReLU类的使用1.使用说明2.代码实现二、nn.Sigmoid类的使用1.使用说明2.代码实现学习地址
PyTorch深度学习快速入门教程【小土堆】.
主要内容
一、前言
我们知道人类大脑中的神…
【RabbitMQ】基础篇,学习纪录+笔记
目录 一.介绍
1.1MQ概述
1.2MQ优势和劣势
1.3常见的 MQ 产品
1.4RabbitMQ简介
1.5RabbitMQ中的相关概念
1.6RabbitMQ的安装
二.快速入门
2.1入门程序
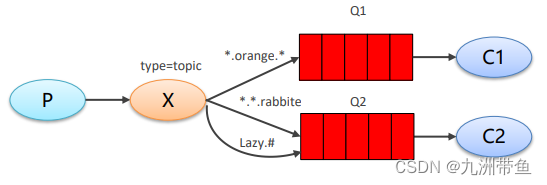
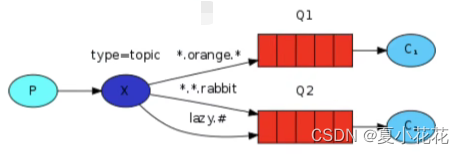
2.2工作模式
2.2.1Work queues 工作队列模式
2.2.2Pub/Sub 订阅模式
2.2.3Routing 路由模式
2.2.4Topics 通配符…

vite 4.0 来了,带你手撕 create-vite 源码
通过本文你将了解到以下内容:
1,npm create 具体执行流程2,minimist、prompts、kolorist三个库3,create-vite 的源码分析
vite源码下载:
//复制一份vite源码到自己的本地
git clone https://github.com/vitejs/vit…

抗击洪涝灾害,河道水雨情动态在线监测解决方案
一、项目背景我国是个多山的国家且位于东南季风区,降雨分布广泛还分布不均匀,这样一来使汛期高度集中。导致很多沿海城市以及临近河道的地区面临着河道决堤的威胁如何实时监测河道雨水情动态成了让人头疼的问题。在2022年1月,发改委、水利部在…
基于jsp+mysql+Spring的SpringBoot招聘网站项目(完整源码+sql)
基于jspmysqlSpring的SpringBoot招聘网站项目(完整源码sql)主要实现了管理员登录,简历管理,问答管理,职位管理,用户管理,职位申请进度更新,查看简历 博主介绍:5年java开发经验,专注Java开发、定制、远程、文档编写指导等,csdn特邀…
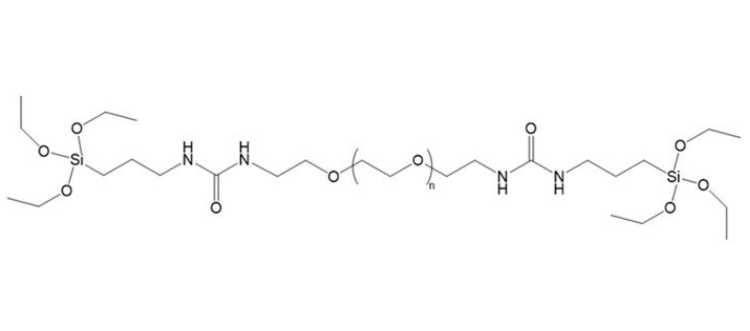
硅烷聚乙二醇硅烷,Silane-PEG-Silane同官能团科研试剂,化学结构式
产品名称:硅烷聚乙二醇硅烷,双硅烷聚乙二醇
中文别名:硅烷PEG硅烷,双硅烷聚乙二醇
英文名称:Silane-PEG-Silane
分子量:1k,2k,3.4k,5k,10k,20k…

面对一堆烂代码,重构,还是重新开发?
hello,大家好,我是张张,「架构精进之路」公号作者。 1、烂代码的形成 写烂代码很容易,但代码写成一坨屎,还能正常运行,那就要有点水平才行。 尤其是一些经验不足的新手,根本不在乎代码质量的重要…

小年 —— 送日历福利啦!(acwing)
acwing每日一题集日历除夕夜瓜分10000ac币啦! 手慢就没了┗|`O′|┛ 嗷~~ 上次在acwing上面留言送日历,结果送着送着,连老本都给送没了,这波集齐了把其他的也给发出来了 AcWing【集日历瓜分10000AC币活动】赠送1月日历…
基于Java SSM springboot健身管理系统设计和实现
基于Java SSM springboot健身管理系统设计和实现 博主介绍:5年java开发经验,专注Java开发、定制、远程、文档编写指导等,csdn特邀作者、专注于Java技术领域 作者主页 超级帅帅吴 Java毕设项目精品实战案例《500套》 欢迎点赞 收藏 ⭐留言 文末获取源码联…
Uniswap v3 详解(四):交易手续费
以普通用户的视角来看,对比 Uniswap v2,Uniswap v3 在手续费方面做了如下改动:
添加流动性时,手续费可以有 3个级别供选择:0.05%, 0.3% 和 1%,未来可以通过治理加入更多可选的手续费率Uniswap v2 中手续费…
《啊哈算法》第三章--枚举很暴力
从无到有学算法(看漫画学算法) (๑•̀ㅂ•́)و✧ 爱要坦荡荡 - 萧潇 - 单曲 - 网易云音乐 一,坑爹的奥数
枚举算法又叫穷举算法,非常的暴力,它的基本思想是“有序地去尝试每一种可能”
题目1
□3 x 6528 3□ x …
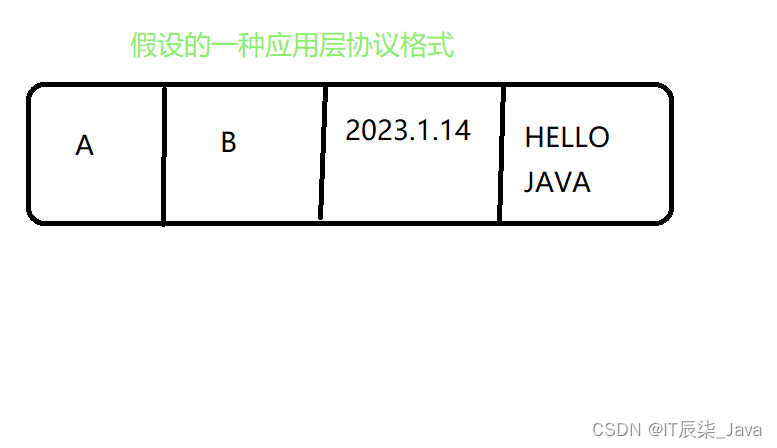
【JavaEE】网络初识之网络通信基础
✨哈喽,进来的小伙伴们,你们好耶!✨ 🛰️🛰️系列专栏:【JavaEE】 ✈️✈️本篇内容:网络初识之网络通信基础。 🚀🚀代码存放仓库gitee:JavaEE初阶代码存放! ⛵⛵作者简介…

Uniswap v3 详解(二):创建交易对/提供流动性
前文已经说过 Uniswap v3 的代码架构。一般来说,用户的操作都是从 uniswap-v3-periphery 中的合约开始。
创建交易对
创建交易对的调用流程如下: 用户首先调用 NonfungiblePositionManager 合约的 createAndInitializePoolIfNecessary 方法创建交易对&…
【软件测试】软件测试分类
1. 按照测试对象划分
界面测试
界面测试(简称UI测试),测试用户界面的功能模块的布局是否合理、整体风格是否一致、各个控件的放置位置是 否符合客户使用习惯,此外还要测试界面操作便捷性、导航简单易懂性,页面元素的可用性&…

U3751频谱分析仪
18320918653
U3751
频谱分析仪爱德万U3751特点:
频率范围:9kHz~8GHz 大输入电平:30dBm RBW:300Hz~3MHz 体积小,重量轻(5.6公斤),测量速度快 户外量测:W-CDMAÿ…