文章目录
- 数据精度
- CUDA概念
- 线程&线程块&线程网络&计算核心
- GPU规格参数
- 内存
- GPU并行方式
- 数据并行
- 流水并行
- 张量并行
- 混合专家系统
数据精度
- FP32 是单精度浮点数,用8bit 表示指数,23bit 表示小数;
- FP16 是半精度浮点数,用5bit 表示指数,10bit 表示小数;
- BF16 是对FP32单精度浮点数截断数据,即用8bit 表示指数,7bit 表示小数

- 为什么聚焦半精度?
- 内存占用更少:fp16 模型占用的内存只需 fp32 模型的一半:
- 模型训练时,可以用更大的batchsize;
- 模型训练时,GPU并行时的通信量大幅减少,大幅减少等待时间,加快数据的流通;
- 计算更快:主流 GPU 都有针对 fp16 的计算进行优化,在这些 GPU 中,半精度的计算吞吐量可以是单精度的 2-8 倍;
CUDA概念
线程&线程块&线程网络&计算核心
- CUDA中线程可以分成三个层次:线程、线程块和线程网络。
- 线程(Thread):CUDA 中基本执行单元,由硬件支持、开销很小,每个线程执行相同代码;
- 线程块(Block):若干线程的分组,Block 内一个块至多512个线程、或1024个线程(根据不同的 GPU 规格),线程块可以是一维、二维或者三维的;
- 线程网络(Grid):若干线程块 Block 的网格,Grid 是一维和二维的
- GPU 有很多线程,在CUDA里被称为 Thread,同一组 Thread归为一个Block,而Block 又会被组织成一个Grid。

- GPU 上有很多计算核心[ Streaming Multiprocessor (SM)], SM 是一块硬件,包含固定数量的运算单元,寄存器和缓存。
- 在具体的硬件执行中,一个SM会同时执行一组线程,在CUDA 里叫warp,直接可以理解这组硬件线程warp会在这个 SM 上同时执行一部分指令,一组的数量一般为32或者64个线程。
- 一个 Block 会被绑定到一个SM上,这些线程组会被相应的调度器来进行调度,在逻辑层面上1024个线程同时执行,但实际上在硬件上是一组线程同时执行。假如一个SM同时能执行 64个线程,但一个Block 有1024个线程,那这 1024 个线程是分 1024 / 64 = 16 1024/64=16 1024/64=16次执行
- GPU 在管理线程的时候是以block为单元调度到 SM 上执行。每个 block 中以warp(一般32个线程或64线程) 作为一次执行的单位(真正的同时执行)
- 一个GPU包含多个 SM ,而每个SM包含多个 Core,SM 支持并发执行多达几百的Thread 。
- 一个Block只能调度到一个 SM 上运行,直到Thread Block运行完毕。一个SM可以同时运行多个Block (因为有多个 Core)
GPU规格参数
不同的GPU规格参数不一样,执行参数不同,比如 Fermi 架构:
- 每一个SM上最多同时执行 8 个 Block。(不管 Block 大小)
- 每一个SM上最多同时执行 48 个 warp。
- 每一个SM上最多同时执行 48 × 32 = 1536 48 \times 32=1536 48×32=1536 个线程。
内存
- 一个 Block 会绑定在一个 SM 上,同时一个 Block内的Thread共享一块 ShareMemory(一般是SM的一级缓存,越靠近SM的内存就越快)。
- GPU和CPU也一样有着多级 Cache 还有寄存器的架构,把全局内存的数据加载到共享内存上再去处理可以有效的加速。

GPU并行方式
- 数据并行(Data Parallelism):在不同的GPU上运行同一批数据的不同子集;
- 流水并行(Pipeline Parallelism):在不同的GPU上运行模型的不同层;
- 张量并行(Tensor Parallelism):将单个数学运算(如矩阵乘法)拆分到不同的GPU上运行;
- 混合专家系统(Mixture-of-Experts):只用模型每一层中的一小部分来处理

数据并行
- 将整个模型放在一块GPU里,再复制到每一块GPU上,同时进行正向传播和反向误差传播,相当于加大batch_size。
- 每个GPU都加载模型参数,这些GPU称为工作节点(workers),为每个GPU分配分配不同的数据子集同时进行处理,分别求解梯度,然后求解所有节点的平均梯度,每个节点各自进行反向传播
- 各节点的同步更新策略
- 单独计算每个节点上的梯度
- 计算节点之间的平均梯度(阻塞,涉及大量数据传输,影响训练速度)
- 单独计算每个节点相同的新参数
-
Pytorch对于数据并行有很好的支持,数据并行也是最常用的GPU并行加速方法之一。
-
将模型按层分割,不同的层被分发到不同的GPU上运行。每个GPU上只有部分参数,因此每个部分的模型消耗GPU的显存成比例减少,常用于GPU显存不够,无法将一整个模型放在GPU上
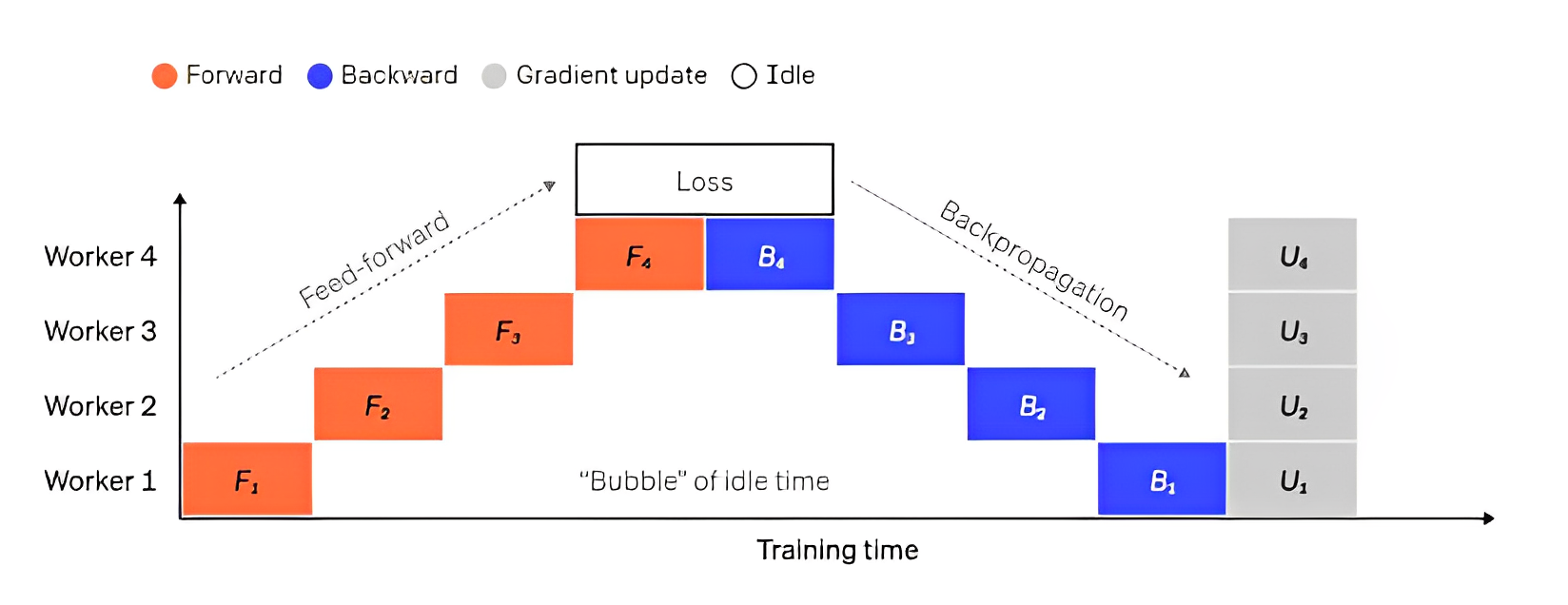
流水并行
- layer的输入和输出之间存在顺序依赖关系,因此在一个GPU等待其前一个GPU的输出作为其输入时,朴素的实现会导致出现大量空闲时间。这些空闲时间被称作“气泡”,而在这些等待的过程中,空闲的机器本可以继续进行计算。
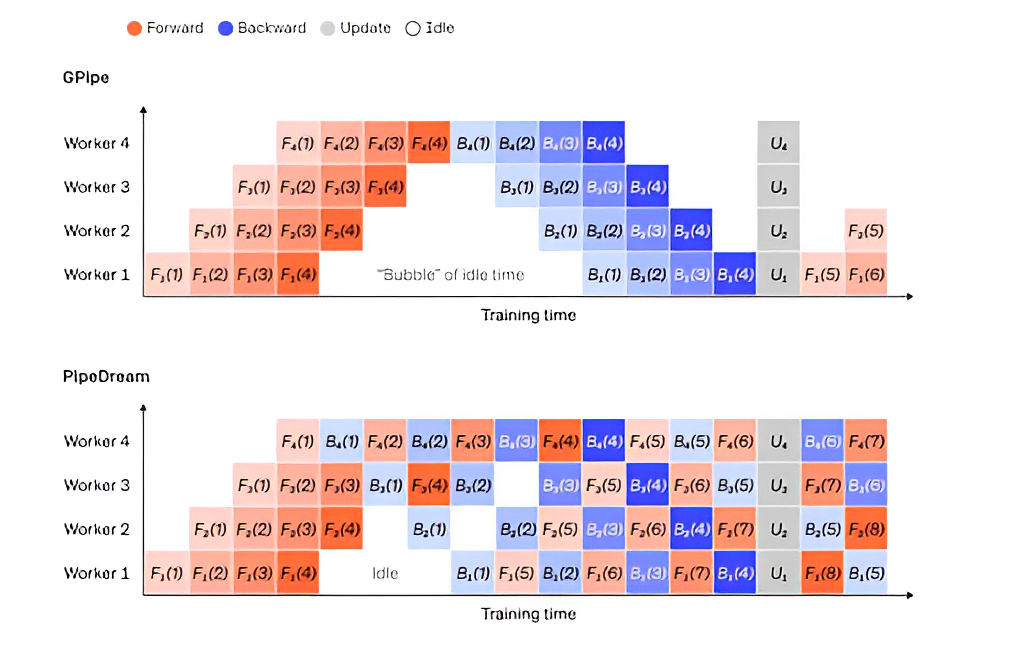
张量并行
-
张量并行:如果在一个layer内“水平”拆分数据。许多现代模型(如Transformer)的计算瓶颈是将激活值与权重相乘。
-
矩阵乘法可以看作是若干对行和列的点积:可以在不同的 GPU 上计算独立的点积,也可以在不同的 GPU 上计算每个点积的一部分,然后相加得到结果。
-
无论采用哪种策略,都可以将权重矩阵切分为大小均匀的“shards”,不同的GPU负责不同的部分,要得到完整矩阵的结果,需要进行通信将不同部分的结果进行整合
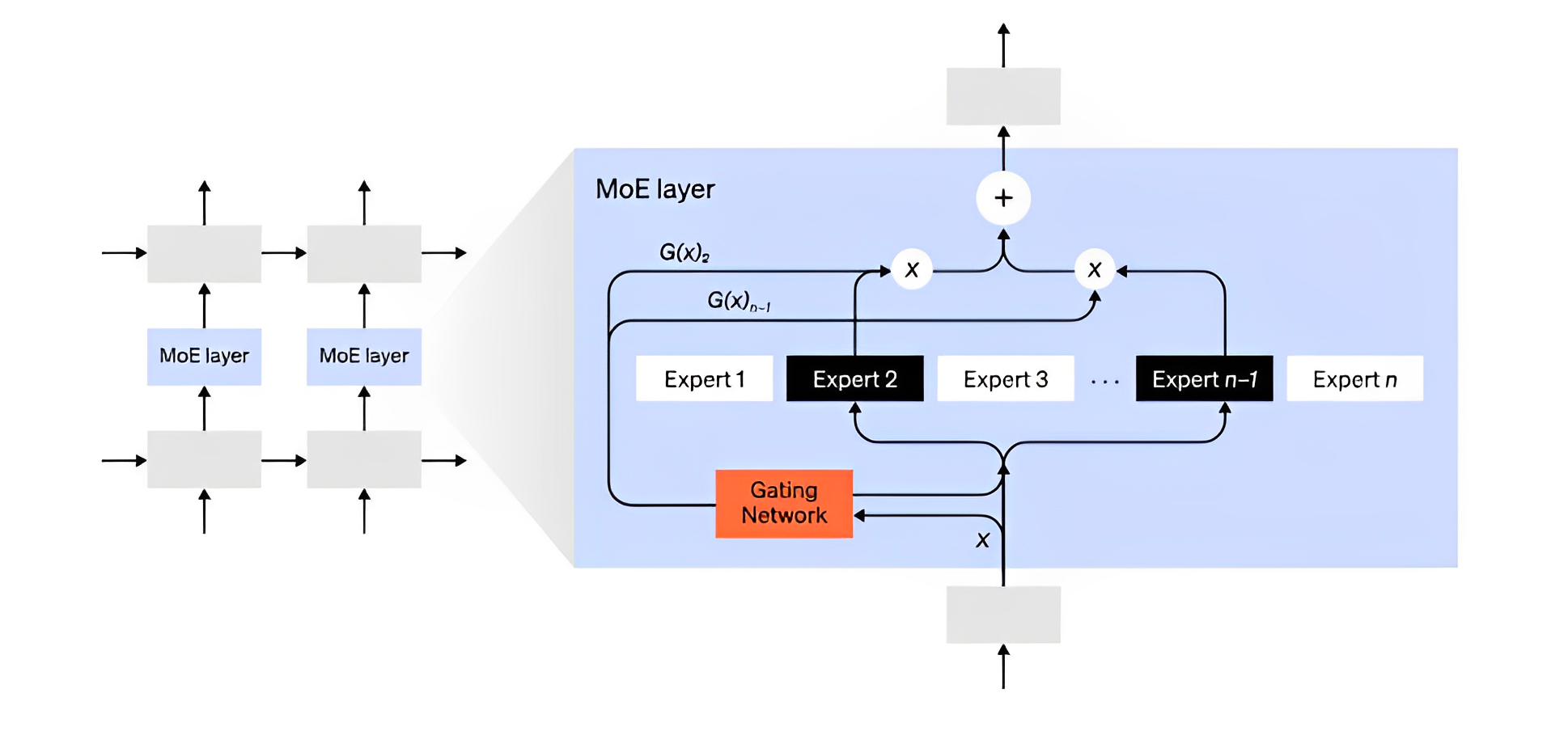
混合专家系统
- 混合专家系统(MoE)是指,对于任意输入只用一小部分网络用于计算其输出。在拥有多组权重的情况下,网络可以在推理时通过门控机制选择要使用的一组权重,这可以在不增加计算成本的情况下获得更多参数。
- 每组权重都被称为“专家(experts)”,理想状态下,网络能够学会为每个专家分配专门的计算任务不同的专家可以托管在不同的GPU上,为扩大模型使用的GPU数量提供一种明确的方法。