在之前的文章中,我们学习了分类学习之支持向量机决策树支持向量机,并带来简单案例,学习用法。想了解的朋友可以查看这篇文章。同时,希望我的文章能帮助到你,如果觉得我的文章写的不错,请留下你宝贵的点赞,谢谢。
Spark-机器学习(7)分类学习之决策树-CSDN博客文章浏览阅读1.3k次,点赞29次,收藏26次。今天的文章,我们来学习分类学习之决策树,并带来简单案例,学习用法。希望大家能有所收获。同时,希望我的文章能帮助到每一个正在学习的你们。也欢迎大家来我的文章下交流讨论,共同进步。https://blog.csdn.net/qq_49513817/article/details/138294454今天的文章,我们来学习分类学习之随机森林,并带来简单案例,学习用法。希望大家能有所收获。
目录
一、随机森林
什么是随机森林?
spark随机森林
二、示例代码
完整代码
方法解析
代码效果
代码输出
拓展-spark随机森林
一、随机森林
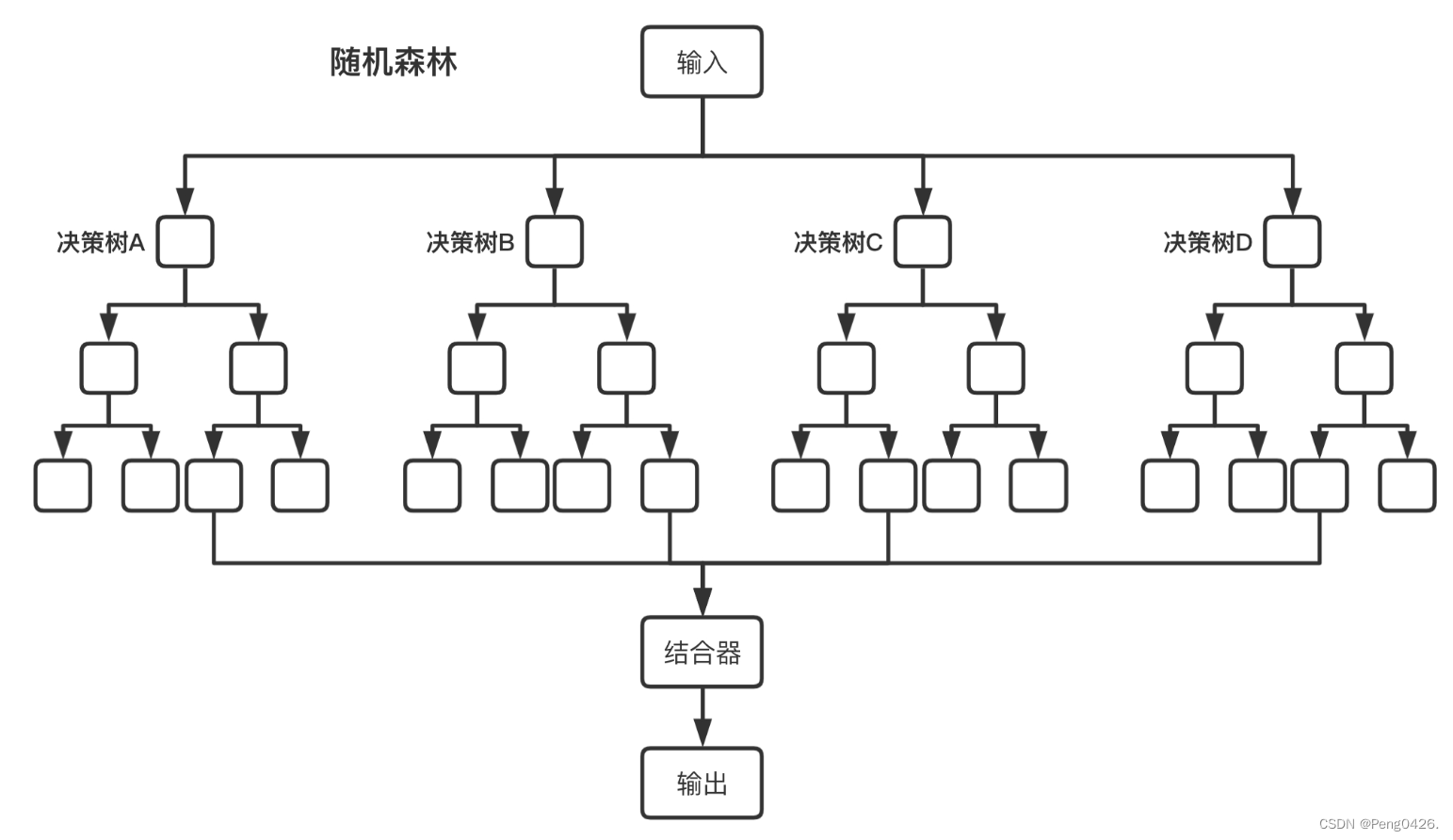 随机森林模型
随机森林模型
什么是随机森林?
随机森林(Random Forest) 是一种基于决策树的集成学习算法,由多棵决策树组成,且每棵树的建立都依赖于一个独立抽取的样本集。在分类问题中,随机森林通过集成学习的思想将多棵树(决策树)的预测结果进行汇总,从而得到最终的分类结果;在回归问题中,随机森林的输出则是所有决策树输出的平均值。
随机森林的优点:
- 高准确性:由于集成了多棵决策树,其预测结果通常比单棵决策树更准确。
- 鲁棒性:对于噪声和异常值有较好的容忍度,不容易过拟合。
- 易于并行化:由于每棵树的生成是独立的,因此可以很容易地进行并行化处理,提高计算效率。
- 能评估特征的重要性:通过计算特征在所有树中的平均不纯度减少量,可以评估每个特征在预测中的重要性。
随机森林的大致构建流程:
- 从原始数据集中随机抽取n个样本(有放回地抽样),作为训练集用于构建决策树。
- 当每个样本有m个特征时,随机从这m个特征中选择k个特征(k<m),然后利用这些特征来构建最佳的分裂点。这个过程在整棵树的每个节点上都会重复。
- 重复上述两个步骤,构建多棵决策树,形成随机森林。
- 对于分类问题,每棵决策树都输出一个分类结果,然后采用多数投票的方式决定最终的分类结果;对于回归问题,则输出所有决策树的平均值。
spark随机森林
Spark随机森林是Apache Spark中一种基于随机森林算法的机器学习模型,它利用Spark的分布式计算能力对大规模数据集进行高效处理。Spark随机森林模型由多棵决策树组成,每棵决策树都是基于随机抽样的训练子集和随机选择的特征子集构建的。
Spark随机森林的工作原理大致如下:
- 数据准备:将输入的训练数据划分为若干个随机子样本。对于每个子样本,从原始数据集中有放回地采样相同数量的样本,形成一个新的训练集。同时,对于每个决策树,还会随机选择一部分特征用于构建树。
- 决策树的构建:对于每个子样本和随机选择的特征,使用决策树算法(如ID3、C4.5或CART)构建一个决策树模型。决策树的构建过程包括选择最佳的特征进行节点划分、递归地构建子树,直到达到停止条件(如树的深度达到预设值)。
- 集成学习:将所有构建好的决策树组合成随机森林模型。在分类问题中,每个决策树会根据样本的特征进行预测,并统计最终的类别投票结果。根据多数表决原则,选择票数最多的类别作为随机森林模型的最终预测结果。在回归问题中,则输出所有决策树的平均值作为预测结果。
二、示例代码
下面的示例代码的主要作用是训练一个随机森林分类模型 ,通过直接在程序中模拟数据来达到我们展示一个随机森林的过程,仅作为学习阶段的示例。在工作中,外部数据往往庞大而复杂,需要我们花费更长的时间来处理数据,清洗数据和优化模型。
完整代码
import org.apache.spark.sql.SparkSession
import org.apache.spark.ml.classification.RandomForestClassifier
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.linalg.Vectors
object p8 {
def main(args: Array[String]): Unit = {
// 创建一个SparkSession
val spark = SparkSession
.builder()
.appName("Peng0426.")
.master("local[*]") // 在本地模式下运行,使用所有可用的核心
.getOrCreate()
import spark.implicits._
// 创建一个模拟的DataFrame
val data = Seq(
(1.0, Vectors.dense(0.0, 1.1, 0.1)),
(0.0, Vectors.dense(2.0, 1.0, -1.0)),
(0.0, Vectors.dense(2.0, 1.3, 1.0)),
(1.0, Vectors.dense(0.0, 1.2, -0.5)),
(0.0, Vectors.dense(1.0, 1.0, -0.1)),
(1.0, Vectors.dense(0.1, 0.1, -1.0))
).toDF("label", "features")
// 显示数据
data.show()
// 划分训练集和测试集(这里简单地将前4个样本作为训练集,后2个作为测试集)
val Array(trainingData, testData) = data.randomSplit(Array(0.67, 0.33))
// 训练随机森林模型
val rf = new RandomForestClassifier()
.setLabelCol("label")
.setFeaturesCol("features") // 因为我们已经有数值特征,所以不需要VectorIndexer
.setNumTrees(3) // 树的数量
// 使用训练数据拟合模型
val model = rf.fit(trainingData)
// 对测试数据进行预测
val predictions = model.transform(testData)
// 显示预测结果
predictions.select("label", "prediction", "features").show()
// 计算测试准确率
val evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("label")
.setPredictionCol("prediction")
.setMetricName("accuracy")
val accuracy = evaluator.evaluate(predictions)
// 输出准确率
println(s"Accuracy = $accuracy")
}
}方法解析
- SparkSession:这是Spark SQL的入口点,用于初始化Spark应用。
- RandomForestClassifier:这是Spark MLlib中的一个类,用于训练随机森林分类模型。
- MulticlassClassificationEvaluator:这是Spark MLlib中的一个类,用于评估多分类问题的模型性能。
- Vectors:这是Spark MLlib中用于表示特征向量的类。
- DataFrame:Spark SQL中的核心概念,用于表示分布式的数据集。
代码效果
- SparkSession:这是Spark SQL的入口点,用于初始化Spark应用。
- RandomForestClassifier:这是Spark MLlib中的一个类,用于训练随机森林分类模型。
- MulticlassClassificationEvaluator:这是Spark MLlib中的一个类,用于评估多分类问题的模型性能。
- Vectors:这是Spark MLlib中用于表示特征向量的类。
- DataFrame:Spark SQL中的核心概念,用于表示分布式的数据集。
代码输出
- 模拟数据集的展示(
data.show())。 - 预测结果的展示(
predictions.select("label", "prediction", "features").show())。 - 模型的准确率(
println(s"Accuracy = $accuracy"))。
运行代码查看输出
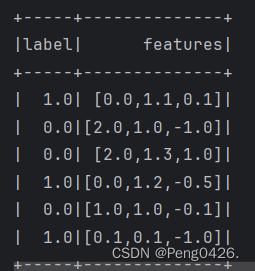
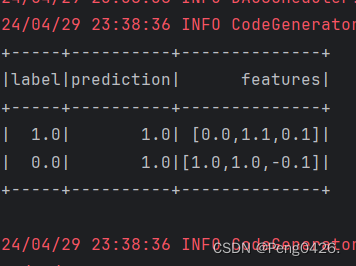
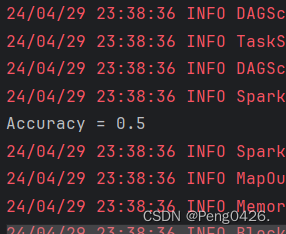
可以看到我们的数据集,预测结果和我们的准确率都输出成功。
应为我们的数据量小,数却又有3个,所以它的准确率为0.5也是没问题的,这个准确率并不算高。
拓展-spark随机森林
| 方法 | 描述 | 例子 |
|---|---|---|
| 随机森林 | 基于多个决策树的集成学习方法 | 使用Spark MLlib中的RandomForestClassifier进行鸢尾花分类 |
| 决策树 | 随机森林的基本构建单元 | 单一决策树用于分类或回归 |
| 集成学习 | 通过组合多个学习器来提高预测性能 | 随机森林通过平均多个决策树的预测结果来提高准确性 |
| 特征重要性 | 评估特征对模型预测的贡献程度 | 计算每个特征在随机森林中的重要性得分 |
| 袋外误差 | 使用未参与训练的数据评估模型性能 | 袋外误差估计作为随机森林模型性能的度量 |
| 参数调优 | 调整模型参数以优化性能 | 调整树的数量、最大深度、特征子集大小等参数 |
| 并行化 | 利用多核或多节点提高计算效率 | Spark利用分布式计算框架加速随机森林的训练和预测 |