Kafka高性能之道
Kafka高性能原因
高效使用磁盘
1)顺序写磁盘,顺序写磁盘性能高于随机写内存。
2)Append Only 数据不更新,无记录级的数据删除(只会整个segment删s除)。读操作可直接在page cache内进行。如果进程重启,JVM内的cache会失效,但page cache仍然可用。
3)充分利用Page Cache:I/O Scheduler将连续的小块写组装成大块的物理写从而提高性能。I/O Scheduler会尝试将一些写操作重新按顺序排好,从而减少磁盘头的移动时间。
4)充分利用所有空闲内存(非JVM内存):应用层cache也会有对应的page cache与之对应,直接使用pagecache可增大可用cache,如使用heap内的cache,会增加GC负担
5)可通过如下参数强制flush,但并不建议这么做。
log.flush.interval.messages=10000
log.flush.interval.ms=1000
6)支持多Directory(目录)。
零拷贝
传统方式实现:
先读取、再发送,实际经过 1~4 四次 copy。
分别是:
第一次:将磁盘文件,读取到操作系统内核缓冲区;
第二次:将内核缓冲区的数据,copy 到 application 应用程序的 buffer;
第三步:将 application 应用程序 buffer 中的数据,copy 到 socket 网络发送缓冲区(属于操作系统内核的缓冲区);
第四次:将 socket buffer 的数据,copy 到网卡,由网卡进行网络传输。
kafka 作为 MQ 也好,作为存储层也好,无非是两个重要功能,一是 Producer 生产的数据存到 broker,二是 Consumer 从 broker 读取数据;我们把它简化成如下两个过程:
网络数据持久化到磁盘 (Producer 到 Broker)
磁盘文件通过网络发送(Broker 到 Consumer)
批处理和压缩
1)Producer和Consumer均支持批量处理数据,从而减少了网络传输的开销。
2)Producer可将数据压缩后发送给broker,从而减少网络传输代价。目前支持Snappy,Gzip和LZ4压缩。
Partition
1)通过Partition实现了并行处理和水平扩展。
2)Partition是Kafka(包括kafka Stream)并行处理的最小单位。
3)不同Partition可处于不同的Broker,充分利用多机资源。
4)同一Broker上的不同Partition可置于不同的Directory。
ISR
1)ISR(in-sync-replica)实现了可用性和一致性的动态平衡。
//如果这个时间内follower没有发起fetch请求,被认为dead,从ISR移除
replica.log.time.max.ms=10000
//如果follower相比leader落后这么多以上消息条数,会被从ISR移除
replica.log.max.messages=4000
2)ISR可容忍更多的节点失败:Majority Quorum如果要容忍f个节点失败,至少需要2f+1个节点(zookeeper,journalnode)。ISR如果要容忍f个节点失败,至少需要f+1个节点。
3)如何处理Replica Crach:Leader crash后,ISR中的任何replica皆可竞选成为Leader。如果所有replica都crash,可选择让第一个recover的replica或者第一个在ISR中的replica成为leader。unclean.leader.election.enable=true
Kafka性能影响因子
性能影响因子
1)Producer:
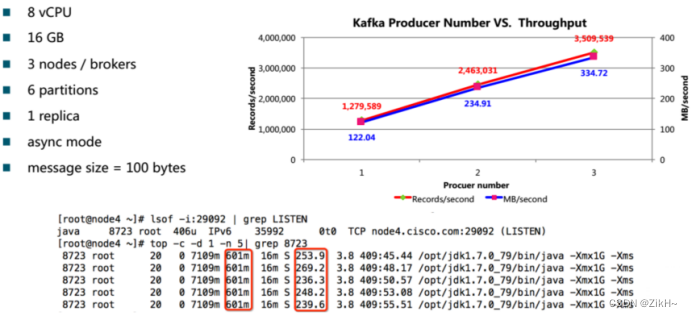
图-1 性能影响因子之producer
如图-1所示,producer个数和吞吐量成正比。
2)Consumer:
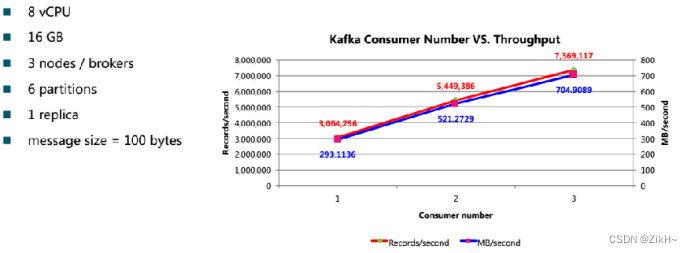
图-2 性能影响因子之consumer
如图-2所示,consumer个数在没有达到partition个数之前,和消费的吞吐量成正比。
3)Partition:
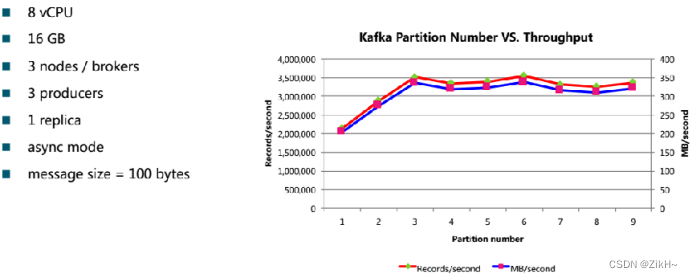
图-3 性能影响因子之partition
如图-3所示,分区个数和生产的吞吐量,在一定范围内,先增长,当达到某一个值之后趋于稳定,在上下浮动。
4)Message-size:
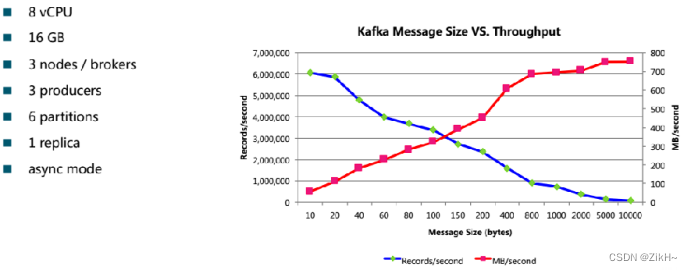
图-4 性能影响因子之message
如图-4所示,随着message size的增大,生产者对应的每秒生成的记录数在成下降趋势,生产的数据体积成上升趋势。
5)Replication:
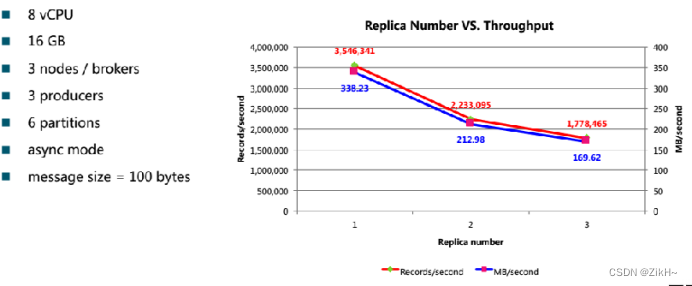
图-5 性能影响因子之replication
如图-5所示,副本越大,自然需要同步数据的量就越多,自然kafka的生成的吞吐量就越低。
性能检测方式
可以借助kafka脚本来查看kafka集群性能。
1)kafka-producer-perf-test.sh:通过该脚本查看kafka生产者的性能,如图-5 所示。

图-45生产性能评估
bin/kafka-producer-perf-test.sh --topic hadoop
–num-records 100000 \ -->测试生成多少条记录
–throughput 10000 \ —>生产者的吞吐量,约等于messages/sec
–record-size 10 \ -->每条消息的大小
–producer.config config/producer.properties
2)kafka-consumer-perf-test.sh:通过该脚本查看kafka消费者的性能,如图-6所示。

图-6 生产性能评估
读取到的结果:
start.time=2019-08-06 02:31:23:738 —>开始时间 end.time=2019-08-06
02:31:24:735 —>结束时间 data.consumed.in.MB=0.9534 —>总共消费的数据体积
MB.sec=0.9562 —>每秒钟消费数据体积
data.consumed.in.nMsg=100000 —>总共消费的数据记录数
nMsg.sec=100300.9027 —>每秒钟消费记录数
rebalance.time.ms=47 —>进行rebalance的时间
fetch.time.ms=950 —>抓取这10w条数据总共花费多长时间
fetch.MB.sec=1.0035 —>每秒钟抓取数据体积
fetch.nMsg.sec=105263.1579 —>每秒钟抓取数据记录数


![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-6.5](https://img-blog.csdnimg.cn/direct/af3bbc40a90646d1809e9eff2cc45597.png)