1. 背景
RocketMQ 5.x 的演进目标之一是云原生化,在云原生和 Serverless 的浪潮下,需要解决 RocketMQ 存储层存在两个瓶颈。
- 数据量膨胀过快,单体硬件无法支撑
- 存储的低成本和速度无法兼得
众多云厂商也希望提供 Serverless 化的 RocketMQ 来降低成本,为用户提供更加极致弹性的云服务。
2. 使用
2.1 Broker 配置
要测试分级存储,需要在 broker.conf 中添加如下配置:
# tiered
messageStorePlugIn=org.apache.rocketmq.tieredstore.TieredMessageStore
tieredBackendServiceProvider=org.apache.rocketmq.tieredstore.provider.PosixFileSegment
tieredStoreFilePath=e:\\data\\rocketmq\\node\\tieredstore
tieredStorageLevel=FORCE分级存储各个配置的含义表如下:
| 配置 | 默认值 | 单位 | 作用 |
|---|---|---|---|
| messageStorePlugIn | 扩展 MessageStore 实现,如果要用分级存储,设置成org.apache.rocketmq.tieredstore.TieredMessageStore | ||
| tieredMetadataServiceProvider | org.apache.rocketmq.tieredstore.metadata.DefaultMetadataStore | 分级存储元数据存储实现 | |
| tieredBackendServiceProvider | org.apache.rocketmq.tieredstore.provider.MemoryFileSegment | 分级存储数据存储实现 | |
| tieredStoreFilepath | 分级存储数据文件保存位置(POSIX provider) | ||
| tieredStorageLevel | NOT_IN_DISK | 分级存储读取策略,默认 NOT_IN_DISK,即只有在本地存储中不存在时才会读取分级存储。其他选项为:DISABLE,禁用分级存储;NOT_IN_MEM,消息不在内存(Page Cache)时读分级存储;FORCE,强制读取分级存储 | |
| tieredStoreFileReservedTime | 72 | hour | 分级存储消息保存时间 |
| commitLogRollingInterval | 24 | hour | 分级存储 CommitLog 强制滚动时间 |
| readAheadCacheEnable | true | 从分级存储读取时是否启用预读缓存 | |
| readAheadMessageCountThreshold | 4096 | 从分级存储时每次读取消息数量阈值 | |
| readAheadMessageSizeThreshold | 16 * 1024 * 1024 | byte | 从分级存储中每次读取消息的长度阈值 |
| readAheadCacheExpireDuration | 15000 | ms | 预读缓存过期时间,没有读写操作 15s 后过期 |
| readAheadCacheSizeThresholdRate | 0.3 | 比例 | 最大预读缓存大小,为 JVM 最大内存的一定比例 |
| tieredStoreMaxPendingLimit | 10000 | 分级存储写文件最大同时写文件数量 |
目前 RocketMQ 源码中内置了两种分级存储 FileSegment 的实现
- MemoryFileSegment:使用内存作为二级存储
- PosixFileSegment:使用磁盘文件作为二级存储
他们都是实验性的,这里选择了 PosixFileSegment。
要实现其他存储介质的分级存储,只需要扩展 FileSegment 实现一个新的 FileSegment 类即可。
2.2 数据组织结构
对启用了分级存储的 Broker 进行压测,一段时间后分级存储目录中的文件:
/e/data/rocketmq/node/tieredstore
`-- [ 0] 212d6b50_DefaultCluster
`-- [ 0] broker-a
| `-- [ 0] rmq_sys_INDEX
| `-- [ 0] 0
| `-- [ 0] INDEX
| `-- [572M] cfcd208400000000000000000000
`-- [ 0] topic-tiered
|-- [ 0] 0
| |-- [ 0] COMMIT_LOG
| | |-- [1024M] 1f329fef00000000001073741775
| | |-- [1024M] cfcd208400000000000000000000
| | `-- [707M] dcb86ff200000000002147483550
| `-- [ 0] CONSUME_QUEUE
| |-- [ 60M] 40d473e300000000000104857600
| `-- [100M] cfcd208400000000000000000000
|-- [ 0] 1
| |-- [ 0] COMMIT_LOG
| | |-- [1024M] 1f329fef00000000001073741775
| | |-- [1024M] cfcd208400000000000000000000
| | `-- [707M] dcb86ff200000000002147483550
| `-- [ 0] CONSUME_QUEUE
| |-- [ 60M] 40d473e300000000000104857600
| `-- [100M] cfcd208400000000000000000000
|-- [ 0] 2
| |-- [ 0] COMMIT_LOG
| | |-- [1024M] 1f329fef00000000001073741775
| | |-- [1024M] cfcd208400000000000000000000
| | `-- [707M] dcb86ff200000000002147483550
| `-- [ 0] CONSUME_QUEUE
| |-- [ 60M] 40d473e300000000000104857600
| `-- [100M] cfcd208400000000000000000000
`-- [ 0] 3
|-- [ 0] COMMIT_LOG
| |-- [1024M] 1f329fef00000000001073741775
| |-- [1024M] cfcd208400000000000000000000
| `-- [707M] dcb86ff200000000002147483550
`-- [ 0] CONSUME_QUEUE
|-- [ 60M] 40d473e300000000000104857600
`-- [100M] cfcd208400000000000000000000其中索引文件单独存放,每个 Topic 的队列都单独有 CommitLog 和 ConsumeQueue
CommitLog 为消息数据,与本地存储不同,每个 Topic 的队列都拆分单独一组的 CommitLog 文件,每个 1G
ConsumeQueue 为消费索引
INDEX 为索引文件,单独目录存放
3. 概要设计
3.1 技术架构选型
分级存储的方案中一个重要的选择是直写还是转写。
- 直写:用高可用的存储或分布式文件系统直接替换本地块存储。优点是池化存储。
- 转写:热数据使用本地块存储先顺序写,压缩之后转储到更廉价的存储系统中。优点是降低冷数据的长期存储成本。
最理想的终态可以是两者的结合,RocketMQ 自己来做数据转冷。因为消息系统自身对如何更好的压缩数据和加速读取的细节更了解,在转冷的过程中能够做一些消息系统内部的格式变化来加速冷数据的读取,减少 IO 次数、配置不同的 TTL 等。
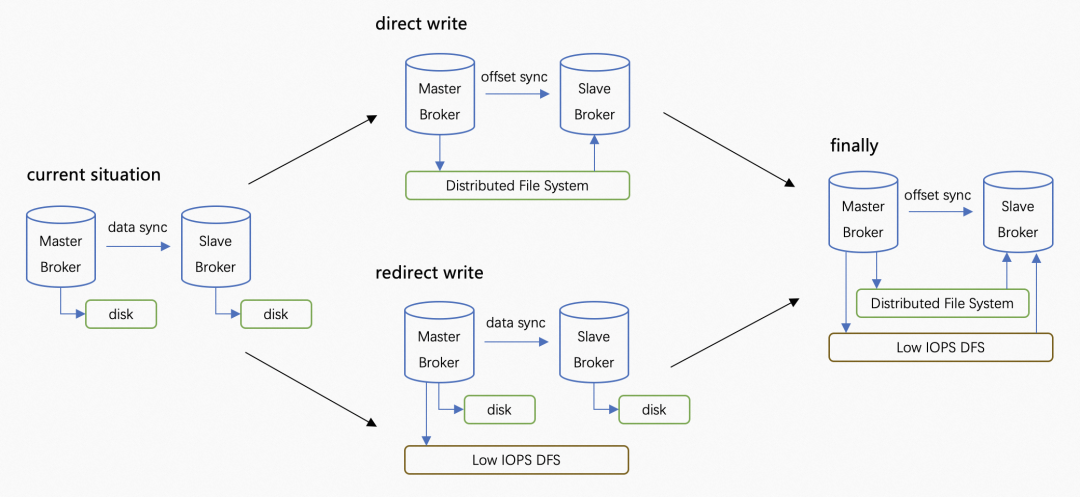
目前的分级存储方案考虑到商业和开源技术架构的一致性,选择先实现转写模式。具体包括以下一些考虑:
- 成本:将大部分冷数据卸载到更便宜的存储系统中后,热数据的存储成本可以显著减小,更直接的降低存储成本。
- 可移植性:直写分布式文件系统通常需要依赖特定 SDK,配合 RDMA 等技术来降低延迟,对应用不完全透明,运维、人力、技术复杂度都有一定上升。保留成熟的本地存储,只需要实现与其他存储后端的适配层就可以轻松切换多种存储后端。
- 延迟与性能:通常分布式文件系统跨可用区部署,消息写多数派成功才能被消费,存在跨可用区的延迟。直接写本地磁盘的延迟会小于跨可用区的延迟,其延迟在热数据读写的情况下也不是瓶颈。
- 可用性: 转写模式下,整个系统弱依赖二级存储,更适合开源与非公有云场景。
3.2 存储模型与抽象
分级存储的模型与本地存储的模型一一对应,结构上也类似。最大的区别在于分级存储模型的组织形式,其 CommitLog 不再将所有队列的消息数据都存在一起,而是按照队列的维度拆分存储。
下表展示了本地存储与分级存储模型的对应关系。
| 本地存储 | 分级存储 | 说明 |
|---|---|---|
| MappedFile | FileSegment | 对应单个文件,MappedFile 是 mmap 实现的内存映射文件,FileSegment 是分级存储中文件的句柄 |
| MappedFileQueue | FlatAppendFile | 多个 MappedFile/FileSegment 组成的链表,只有最后一个文件是可写的,前面的都是不可变的 |
| CommitLog | FlatCommitLogFile | MappedFileQueue/FlatAppendFile 的封装,CommitLog 是由所有队列的消息数据构成的文件,FlatCommitLogFile 存储单个队列中的消息数据 |
| ConsumeQueue | FlatConsumeQueueFile | MappedFileQueue/FilatAppendFile 的封装,消费索引文件,保存着每个消息在 CommitLog 中的物理偏移量,用于消费每个队列的时候查询消息。本地存储的 ConsumeQueue 详解见 这篇文章 |
| FlatMessageFile | 分级存储引入的概念,表示单个队列的消息文件,组合 FlatCommitLogFile 和 FlatConsumeQueueFile,并提供一系列操作接口 | |
| IndexFile | IndexStoreFile | 索引文件,也由一组文件构成,用于根据 Key 查询消息。本地存储的 IndexFile 类似一个 HashMap,hash 冲突时,value 是头插法构造成的一个链表。分级存储的 IndexStoreFile 最后一个文件格式与本地存储的 IndexFile 类似,但是列表前面的文件在写入完毕后会经过压缩。本地存储的 IndexFile 讲解见 这篇文章 |
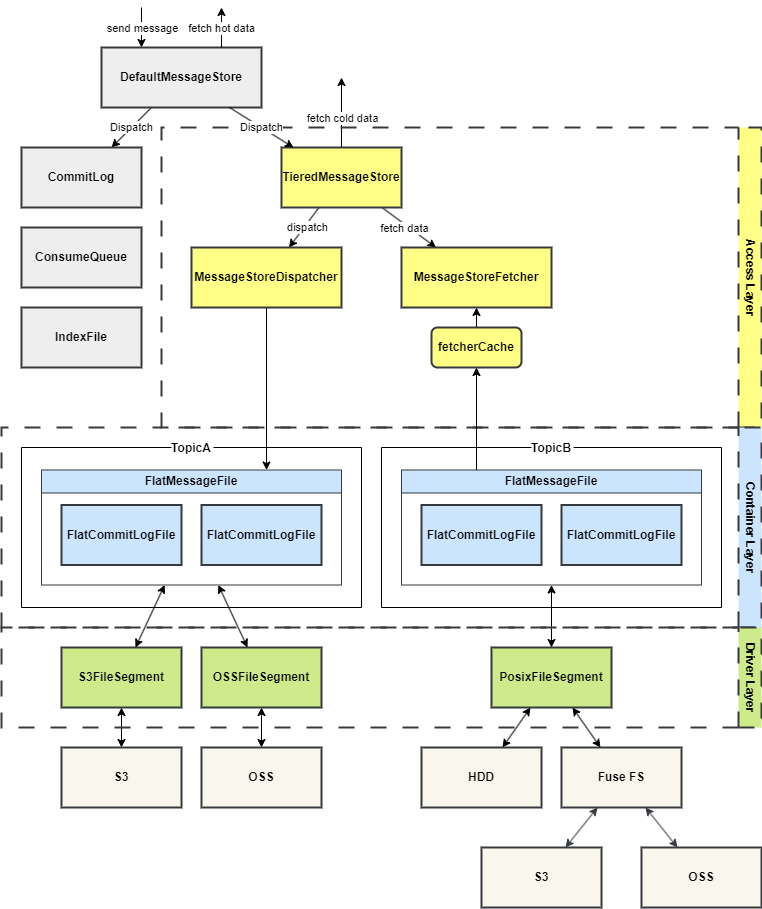
3.3 分层设计
分级存储的实现分为 3 层,从上至下分别是接入层、容器层、驱动层。
- 驱动层最为底层,负责实现逻辑文件到具体的分级存储系统的映射。实现
FileSegment接口,目前提供了内存和本地磁盘的实现。 - 容器层为上面提到的存储模型除了
FileSegment以外的其他分级存储抽象。 - 接入层作为操作分级存储数据的入口,包含整个分级存储的
MessageStore,以及从分级存储读数据的 Fetcher 和写数据的 Dispatcher。
3.4 写消息
写消息经过一次重构,由原来的实时上传改为攒批,纯异步上传。在相同流量下性能提升了 3 倍以上。
写消息逻辑由分级存储消息分发器处理,它被注册到默认存储的分发器链中,在其他分发器都分发完毕后被调用,在这里被调用只是为了创建队列的文件容器和持久化队列的元数据。
分级存储消息分发器是一个服务线程,每 20s 进行一次扫描,依次扫描所有的队列,决定是否要上传消息。
触发上传的条件有两个:距离上次提交达到一定时间(默认 30s),或者等待上传的消息超过一定数量(默认 4096)。
上传的过程是:
- 先将等待上传的这部分消息放入刷盘缓冲区
- 为这些消息创建消费队列,也是将消费队列数据放入刷盘缓冲区
- 判断缓冲区中的消息是否达到阈值(等到到一定时间或者缓冲区中消息到一定数量),如果达到阈值,则用一个专门的消息上传线程池异步上传已被放入缓冲区的消息。
- 上传的过程中,先批量上传消息数据,上传成功后再批量上传消费索引数据(最后如果开启索引构建的话,再构建索引)
3.5 读消息
3.5.1 读取策略
在分级存储的情况下,随着时间的推移,消息的存储位置也会经历 内存(Page Cache)-> 本地存储 -> 二级存储 这样的转变。
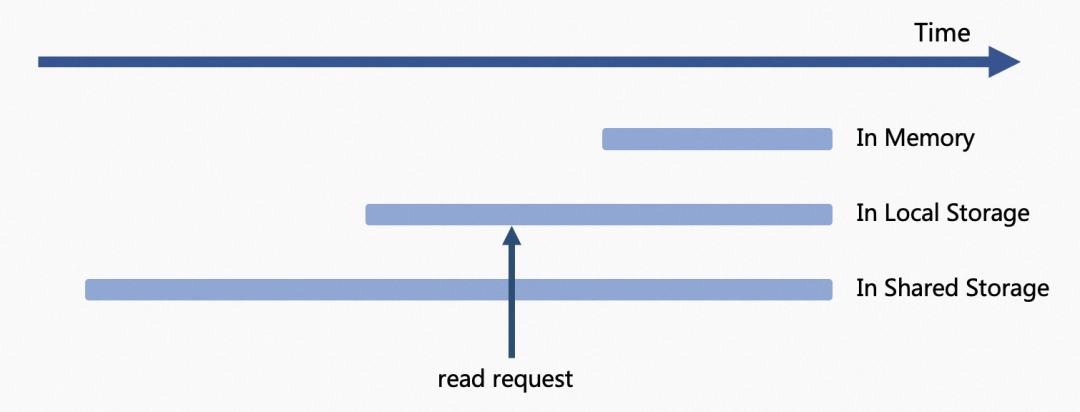
RocketMQ 分级存储把读取策略抽象了出来,供用户自行配置,默认是 NOT_IN_DISK。
- DISABLE:禁用分级存储,所有 fetch 请求都将由本地消息存储处理。
- NOT_IN_DISK:只有 offset 不在本地存储中的 fetch 请求才会由分级存储处理。
- NOT_IN_MEM:只有 offset 不在内存中的 fetch 请求才会由分级存储处理。
- FORCE:所有 fetch 请求都将由分级存储处理。
3.5.2 读取流程
为了加速从二级存储读取的速度和减少整体上对二级存储的请求次数,引入了预读缓存的设计。
首先根据读取策略,查询已提交二级存储的 offset 和消息是否在内存中这些信息来判断是否要走二级存储读取。
优先从预读缓存读取消息。(如果开启预读缓存功能)
如果从缓存中读到消息,直接返回。如果没有读到消息,立即从二级存储中拉取消息,拉取到后放入缓存,然后返回。
- 从二级存储读取消息的过程:先读取消费队列数据,然后用消费队列数据查询消息数据,确定要读取消息数据的长度,最后从分级存储中读取消息数据并返回。
3.6 索引设计
3.6.1 索引重排
索引文件 是为了根据 Key 查询消息而创建的。它的组织结构近似一个 HashMap,Key 为消息的 Key 进行 hash 之后的值,Value 包含了消息物理偏移量等信息。
当发生哈希冲突时(消息 Key 经过 hash 之后可能相同),采用链表的形式处理冲突,将新插入的 Value 插入 hash 槽的开头(头插法)。这样,每个 hash 槽就对应了一条按照插入时间倒序排列的链表。
但是这样的结构组成文件之后,读取一个 hash 槽对应的链表时,由于每个 Value 插入时间不是连续的,它们会分布在文件的不同位置,这样查询时就存在多次随机读。
冷存储的 IOPS 代价是十分昂贵的,所以在分级存储中面向查询进行优化,如下图所示。

新的索引文件将每个 hash 槽所对应的 Value 重新排列,在文件中连续存储和读取,不再使用非连续的链表形式。这样可以让查询时的多次随机 IO 变成一次 IO。
3.6.2 索引构建流程
分级存储的索引文件分为三个状态:
- UNSEALED:初始状态,类似主存索引文件格式(顺序写),存储在本地磁盘上,正在被写入。一般只有最后一个索引文件处于该状态。路径为
{storePath}/tiered_index_file/{时间戳} - SEALED:已经或正在被压缩成新格式的索引文件,还未上传到外部存储。路径为
{storePath}/tiered_index_file/compacting/{时间戳} - UPLOAD:已经上传到二级存储。
索引文件在消息上传到二级存储后开始构建,每次写入只会写入文件列表最后一个处于 UNSEALED 状态的文件。当一个索引文件写满后,把它改为 SEALED 状态,并新建一个 UNSEALED 的索引文件。
索引文件服务启动一个线程,每 10s 扫描一次,找到创建时间最早的处于 SEALED 状态的索引文件,压缩并上传到二级存储。
压缩的过程会在 compacting 目录创建一个新格式的索引文件,然后遍历老索引文件,将内容重新排列后写入新的索引文件,最后将新索引文件内容上传到二级存储。上传完成之后会删掉处于本地的新老索引文件。
3.7 重启恢复和元数据
在 Broker 重启后,需要重新加载分级存储文件句柄到内存。之前加载过的二级存储文件信息通过元数据的形式保存在本地文件中,专门用于 Broker 重启之后的恢复。
元数据文件默认保存的位置是 ${ROCKETMQ_HOME}/store/config/tieredStoreMetadata.json。
元数据文件分为两类:一类是保存 Topic、Queue 数据的;另一类是保存所有分级存储文件句柄(FileSegment)的。每当有新的 Topic 或 Queue 的消息被分发到分级存储,对应的 Topic 和 Queue 的元数据会被创建和持久化;每当新的分级存储文件句柄(FileSegment)被创建,对应的文件句柄元数据也会被创建和持久化。
在重启后,分级存储系统会读取持久化在本地的 Topic、Queue 元数据,在内存中重建 Queue,然后再读取文件句柄的元数据,在内存中恢复所有分级存储的文件句柄。
4. 详细设计
分级存储的代码位于一个单独的模块 tieredstore,由 TieredMessageStore 这个类承载。
4.1 接入方式
RocketMQ 支持以插件的方式引入自定义的存储实现,分级存储就是通过实现 AbstractPluginMessageStore 来作为插件进行接入的。AbstractPluginMessageStore 实现了 MessageStore 接口,可以作为 Broker 的存储实现。
4.1.1 分级存储初始化
在 BrokerController 初始化时,调用 initializeMessageStore() 方法,会先进行默认存储的初始化。
默认存储有两种类型
DefaultMessageStore,为使用磁盘文件存储的默认存储实现RocksDBMessageStore,使用 RocksDB 进行存储实现,为了支持百万队列而引入
然后如果配置了插件存储,则将实例化插件存储,作为 Broker 中真正使用的存储实现。最后,将默认存储作为一个引用传入插件存储,这样,在插件存储中仍然可以调用默认存储。
4.1.2 分级存储调用
写消息
在存储消息时,TieredMessageStore 并没有重写消息存储的方法,而是直接调用了默认存储的消息保存,先将消息存至默认的本地存储中。
分级存储在这里的接入方法是:在默认存储的消息分发器中添加分级存储的消息分发器实例。这样,消息在存储到 CommitLog 之后会先分发到 ConsumeQueue 和 IndexFile,然后分发到分级存储。
读消息
查询时,TieredMessageStore 重写了 getMessageAsync 方法,根据配置的分级存储消息读取策略进行判断,如果是读本地存储,则使用本地存储的引用调用其 getMessageAsync 方法,如果是读分级存储则调用分级存储 fetcher 获取消息。
4.2 存储模型
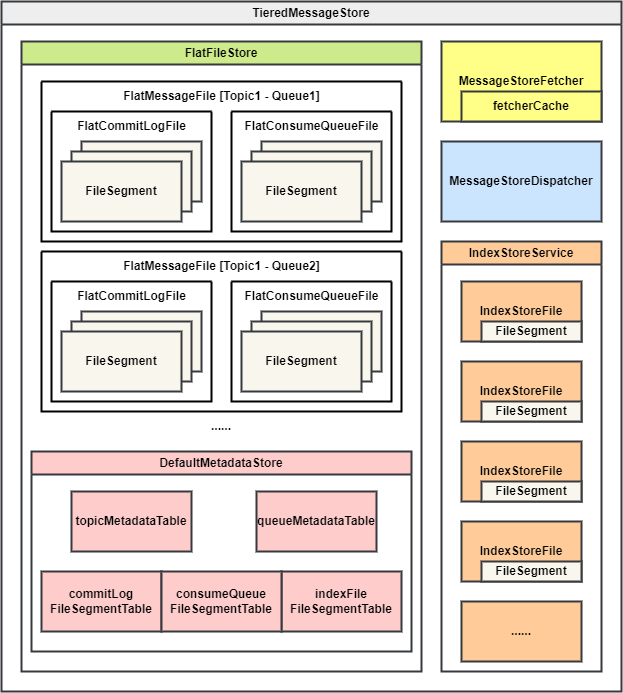
如上图所示,TieredMessageStore 中包含了分级存储所有的存储模型,下面来分别介绍
FlatFileStore:分级存储中消息文件存储的实现,内部有一个 Map 作为分级存储文件容器,Key 是队列,Value 是该队列的分级存储文件,以
FlatMessageFile的形式存储FlatMessageFile:表示单个队列的存储实现,它封装了
FlatCommitLogFile和FlatConsumeQueueFile对象,并且提供了读/写消息等操作接口。FlatCommitLogFile:分级存储
CommitLog文件,类似本地存储的CommitLog,由一组FileSegment队列构成。区别是分级存储的CommitLog是以队列维度保存的。这是为了方便连续地读取单个队列中的消息。如果仍然以本地存储的方式将所有队列的
CommitLog统一存储,同一队列的消息数据可能会横跨更多的文件,为分级存储带来更多的 IOPS 压力,这对分级存储来说是非常昂贵的。FlatConsumeQueueFile:分级存储队列消费索引,类似本地存储的
ConsumeQueue,由一组FileSegment队列构成。保存着消息位置(指向FlatCommitLogFile的偏移量)- FlatAppendFile:
FlatCommitLogFile和FlatConsumeQueueFile都扩展了这个类,它类似本地存储的MappedFileQueue,是零个或多个定长FileSegment组成的链表。其中最多只有最后一个FileSegment是可写的,前面的文件都是只读的。- FileSegment:类似本地存储的
MappedFile,分级存储中的文件最小单元。
- FileSegment:类似本地存储的
- FlatAppendFile:
DefaultMetadataStore:分级存储元数据存储实现,用于存储 Topic、Queue、FileSegment 等元数据信息
- topicMetadataTable:Map,存储分级存储中 Topic 的元数据和额外属性
- queueMetadataTable:Map,存储分级存储中 Queue 元数据和额外属性
- commitLogFileSegmentTable:分级存储
CommitLog的FileSegment文件元数据 - consumeQueueFileSegment:分级存储
ConsumeQueue的FileSegment文件元数据 - indexFileSegmentTable:分级存储
IndexFile的FileSegment文件元数据
MessageStoreFetcher:分级存储消息读取器,负责处理分级存储读取请求。
- fetcherCache:读取器预读缓存,为了加速从二级存储读取的速度和减少整体上对二级存储请求数而设置。在读取前查询和读取缓存;从二级存储读到数据后放入缓存。
MessageStoreDispatcher:分级存储消息分发器,是一个服务线程,定时将本地已经攒批的数据上传到分级存储。
IndexStoreService:分级存储索引服务,内部包含了由
IndexStoreFile构成的索引文件表,以及当前正在写入的索引文件的引用。同时提供了索引文件操作的接口。- IndexStoreFile:分级存储索引文件,类似本地存储的
IndexFile,底层是分级存储FileSegment。
- IndexStoreFile:分级存储索引文件,类似本地存储的
4.3 写消息
初始化分级存储时会将分级存储 dispatcher 注册到 CommitLog 的 dispatcher 链当中。
在消息写入 CommitLog 后,reput 线程会扫描 CommitLog 中的消息,然后依次运行 dispatcher 链中的 dispatcher,生成 ConsumeQueue 和 IndexFile。在这之后,会执行分级存储 dispatcher 方法。分级存储的 dispatcher 仅仅根据扫描到的消息创建分级存储对应的队列目录和空的分级存储 FileSegment 文件,上传数据的流程为定时发起。

MessageStoreDispatcherImpl 是分级存储消息分发器的实现,用于将本地存储的消息提交到分级存储中。它是一个服务线程,每 20s 运行一次,判断缓冲区中等待上传的消息是否达到阈值,如果达到则将本地存储中的这批消息提交到分级存储。
每 20s,它遍历当前分级存储中所有的 FlatMessageFile(也就是遍历每个 Queue),对他们执行 dispatchWithSemaphore 方法。
这个方法获取信号量,然后将执行异步上传操作,当前默认允许的同时上传的 Queue 数量为 2500。
doScheduleDispatch 方法执行消息数据的获取、缓冲和上传。
每次上传的数据量是有一个阈值的,满足了阈值条件其中之一才进行上传,否则等待下一次扫描。
- 超时:上次提交到当前时间是否超过分级存储存储的提交时间阈值(30s)
- 缓冲区满:当前队列等待提交的消息数量超过阈值(4096)
该方法的第一步是找到本次上传数据的偏移量起始和结束位置。在这之前需要明确一些概念。
RocketMQ 在多副本的情况下,消息被写入 CommitLog 之后更新 max offset(图中黄色部分),但这些消息还需要同步到其他副本。多副本中多数派的最小位点(低水位)为 commit offset,而在这之间的消息是正在等待副本同步的。允许上传到分级存储的消息(也就是上传数据的结束位置最多)是 commit offset 之前。
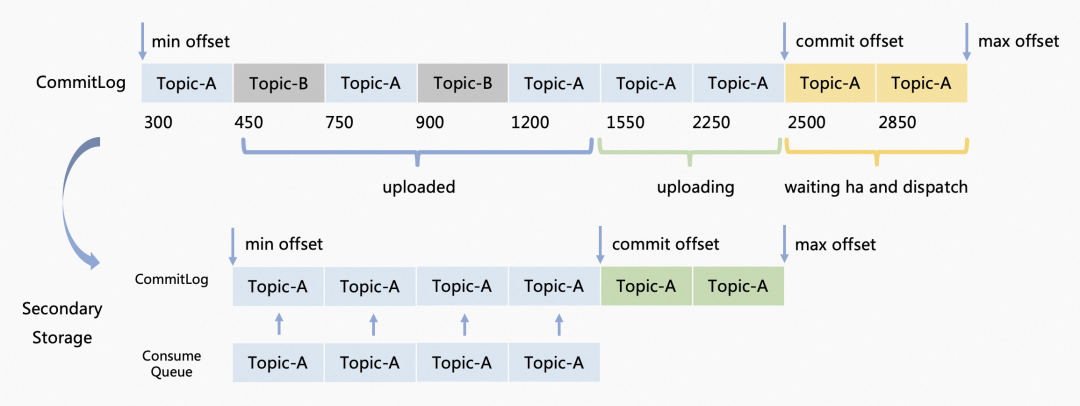
起始位置的计算方式如下:
- 如果这个队列的分级存储 FileSegment 为空(刚初始化),那么起始位置即该 FileSegment 文件对应的队列起始偏移量。
- 如果这个 FileSegment 已经初始化过,那么为分级存储 ConsumeQueue 当前的 maxOffset。因为分级存储的 CommitLog 和 ConsumeQueue 上传是一系列操作,必须保证消息上传到这两个文件成功才视作上传成功。所以应该以 ConsumeQueue 的 max offset 为准。
明确了起始位置之后,要计算当次上传的结束位置。单次上传最大消息数据量也有一个阈值,默认为 4M,如果队列中等待上传的消息量超过 4M,则截断上传,否则全部上传。
上传到分级存储的操作也分为两步,append 和 commit。
- append:将数据放入上传缓冲区,等待批量上传。这个过程在这里是同步的。分级存储文件的 max offset 包含了放入缓冲区中等待上传的消息数据。
- commit:真正将数据上传到二级存储,为异步操作。分级存储文件中的 commit offset 为已经上传到分级存储的消息数据。
doScheduleDispatch 整个分发逻辑为:
- 从起始位置到结束位置遍历队列逻辑偏移量
- 根据偏移量获取本地存储中的 ConsumeQueue 单元
- 根据 ConsumeQueue 单元查找本地存储 CommitLog,获取消息数据
- 将消息数据 append 到分级存储 CommitLog 中的缓存
- 提交一个分级存储的 DispatchRequest,append 到分级存储 ConsumeQueue 的缓存
- 异步执行 commit,先将 CommitLog 缓存中的数据上传到分级存储,然后将 ConsumeQueue 缓存中的数据上传到二级存储。上传完成之后更新 commit offset,然后释放 CommitLog 缓冲区和 ConsumeQueue 分发请求缓冲区。
- 如果开启 IndexFile,则调用
constructIndexFile构造分级存储 IndexFile,具体逻辑后面会讲
对于上传失败的情况,在 doScheduleDispatch 开始时进行判断,分级存储 ConsumeQueue 的 commit offset 是否大于等于 max offset,如果不是则重试上次上传,也就是把上次还在缓冲区的数据重新上传一次。
4.4 读消息
读消息的逻辑引入预读缓存,以加快读取速度、减少对分级存储的访问。读消息的逻辑也经过一次重构,原先的预读缓存使用了拥塞控制算法,每次预读消息量类似拥塞窗口采用加法增、乘法减的流量控制机制,但存在 OOM 的问题。重构后采用更简单明了的预读策略:当缓存中的数据大小大于缓存配置大小的 80% 时就直接走分级存储,解决了 OOM 的问题。
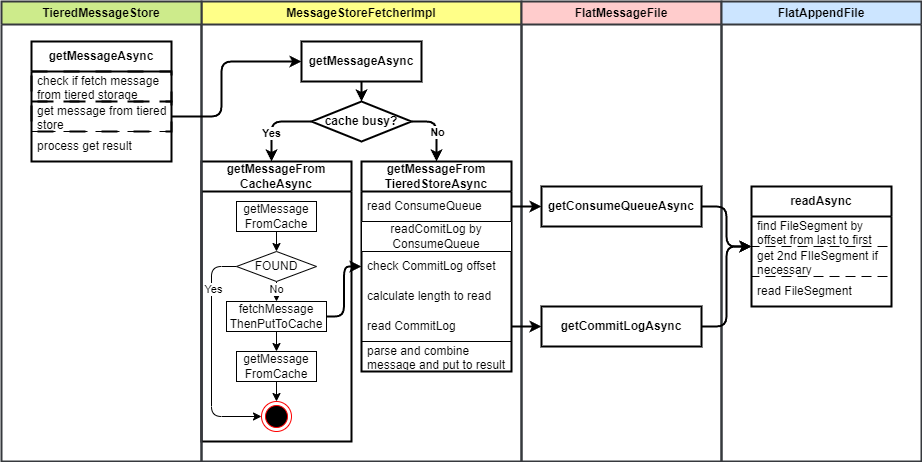
4.4.1 TieredMessageStore 读消息
如果使用分级存储,TieredMessageStore 则会作为 Broker 使用的 MessageStore,读消息时会调用 getMessageAsync 方法。它的逻辑是
- 根据用户配置的分级存储读取策略,检查是否需要从分级存储中读取消息。分级存储读取策略如下,默认为
NOT_IN_DISK:- DISABLE:禁用分级存储,所有 fetch 请求都将由本地消息存储处理。
- NOT_IN_DISK:只有 offset 不在本地存储中的 fetch 请求才会由分级存储处理。
- NOT_IN_MEM:只有 offset 不在内存中的 fetch 请求才会由分级存储处理。
- FORCE:所有 fetch 请求都将由分级存储处理。
- 如果是从分级存储进行读取,则调用
MessageStoreFetcherImpl的getMessageAsync方法,从分级存储读取消息数据。如果是从本地存储读取,则调用本地存储MessageStore的引用,读取本地存储中的消息数据。 - 如果从分级存储没有找到消息,会从本地存储再读取一次。如果从分级存储中找到,更新分级存储的统计信息。
4.4.2 预读缓存设计
预读缓存是使用 Caffeine 库来创建的内存缓存。最大可用的内存默认为 JVM 内存的 30%,缓存项在 15s 内没有被使用则清理,使用消息 buffer 大小计算内存使用量。
4.4.3 MessageStoreFetcher 读消息
MessageStoreFetcherImpl#getMessageAsync 方法需要判断走预读缓存读消息还是直接走分级存储,根据判断结果来调用读取消息的方法。判断依据是预读缓存占用的内存是否超过阈值(即超过预读缓存最多可用内存的 80%)。
缓存的 Key 是 topic@queueId@offset 字符串,Value 是 SelectBufferResult
从分级存储读取
先来看直接走分级存储读取的场景,会调用 getMessageFromTieredStoreAsync 方法,该方法逻辑如下
- 根据要读取消息的偏移量和最大读取消息数量获取分级存储 ConsumeQueue
- 根据 ConsumeQueue 读取分级存储 CommitLog
- 从 ConsumeQueue Buffer 中解析出第一条和最后一条消息的 commitLog offset,并验证是否合法
- 获取整体要读的消息长度,如果长度超过阈值,则缩小单次读取长度(从最后一条消息开始往前缩小,直到缩到只有一条消息)
- 从分级存储 CommitLog 中读取消息
- 读取到消息数据后进行处理,将返回结果解析成消息对象,放入返回结果中返回
从预读缓存读取
然后来看走预读缓存的场景,如果预读缓存中没有消息,会走到上面分级存储读取的方法来读取消息然后放入预读缓存。
getMessageFromCacheAsync 逻辑如下:
- 先尝试从缓存中读消息,根据消息逻辑偏移量一条一条从缓存中查询消息。
- 如果从缓存中读取到消息,即便没有达到 maxCount 也直接返回。
- 如果缓存中没有读到,调用
fetchMessageThenPutToCache方法:- 它先调用
getMessageFromTieredStoreAsync方法从分级存储查询消息 - 然后将读到的消息放入缓存
- 它先调用
- 最后再查询缓存,将结果返回
4.4.4 FlatAppendFile 读消息
FlatAppendFile 是分级存储 FileSegment 列表的封装,readAsync 方法会找到要读取的 FileSegment,然后调用 FileSegment 的 readAsync 方法进行读取,逻辑如下:
- 从后往前遍历 FileSegment,找到包含 offset 的 FileSegment
- 获取 offset 所在的 FileSegment,以及它后面一个 FileSegment(如果要读取的数据跨越了两个 FileSegment)
- 读取 FileSegment 的数据,合并后返回
4.5 索引文件
分级存储中的索引文件也是以一组 FileSegment 的形式存在。
概要设计中讲到,为了减少分级存储索引文件的 IOPS,所以在设计上对分级存储中保存的 IndexFile 文件格式进行了优化。在分级存储索引项刚开始构建时,这个索引文件处于未压缩状态,文件内容格式与本地存储的索引文件相同。在一个索引文件写满后,会重排该索引文件,写到一个新的文件中,最后上传到分级存储。
4.5.1 索引文件类设计
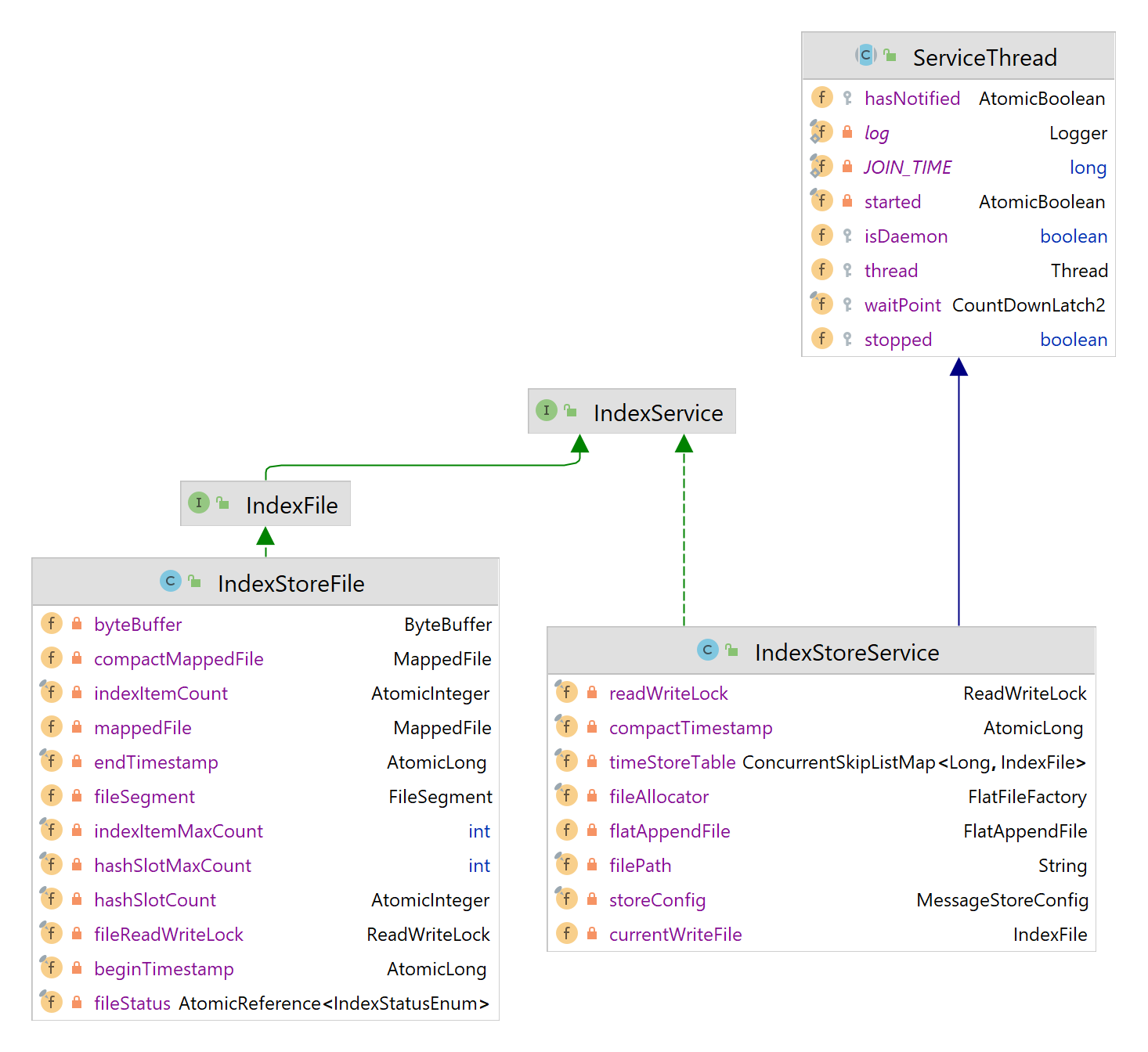
IndexService 接口中包含了对索引文件操作的封装:putKey 和 queryAsync,两个索引文件类实现了这个接口。
- IndexStoreFile:表示单个索引文件,包含了压缩前的索引文件引用、压缩后索引文件引用、上传到二级存储的索引文件引用。
- fileStatus:索引文件状态
- UNSEALED:初始状态,类似主存索引文件格式(顺序写),存储在本地磁盘上,正在被写入。一般只有最后一个索引文件处于该状态。路径为
{storePath}/tiered_index_file/{时间戳} - SEALED:已经或正在被压缩成新格式的索引文件,还未上传到外部存储。路径为
{storePath}/tiered_index_file/compacting/{时间戳} - UPLOAD:已经上传到二级存储。
- UNSEALED:初始状态,类似主存索引文件格式(顺序写),存储在本地磁盘上,正在被写入。一般只有最后一个索引文件处于该状态。路径为
- mappedFile:UNSEALED 状态下索引文件引用,类似本地 IndexFile 的格式
- compactMappedFile:SEALED 状态下的索引文件,经过重排后的格式
- fileSegment:UPLOAD 状态下的索引文件,已上传二级存储
- fileStatus:索引文件状态
- IndexStoreService:IndexStoreFile 文件的容器,内部有排序的 IndexStoreFile 表,实现了索引文件读写接口,作为索引文件操作的入口。也是一个服务线程,用于扫描和重排已经写满的索引文件。
- timeStoreTable:索引文件表,根据创建时间排序的跳表,Key 是创建时间
- currentWriteFile:正在写入的索引文件,也是 timeStoreTable 中的最后一个索引文件
4.5.2 索引文件读写
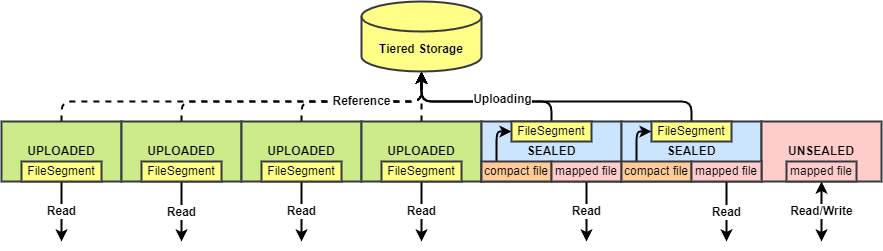
IndexStoreService 作为索引文件的容器和操作入口,保存着索引文件的跳表。该列表最多只允许有一个 UNSEALED 的文件,处理写入请求。
写分级存储索引
索引文件的写入在前面写过的分级存储 ConsumeQueue 数据上传完成之后被调用,入口是 MessageStoreDispatcherImpl#constructIndexFile,它会调用 IndexStoreService#putKey 方法进行写入。putKey 中会找到当前 UNSEALED 状态的索引文件,调用它的 putKey 方法写入,最多重试 3 次。如果文件写满,则创建新的索引文件后,都写入失败则打印错误日志。
索引文件仅在根据 Key 查消息时使用,没有它的情况下也能正常消费消息,所以在多次写入失败的情况下可以放弃写入,它的写入顺序也是最靠后的。
单个索引文件的写入逻辑如下:
- 判断是否已经写满(索引数量超过最大值,默认 2000w),如果写满则将索引文件状态置为 SEALED 等待压缩,返回文件已满
- 将索引项先写入本地的一个临时索引文件中
读分级存储索引
读索引的调用链如图所示,一般由 RocketMQ Admin client 发送 QueryMessage 请求触发,从下到上进行调用

IndexStoreService#queryAsync 作为分级存储索引文件读取的入口,逻辑如下:
- 获取查询时间范围内的所有索引文件
- 逆序遍历索引文件,调用它的
queryAsync方法异步查询索引项 - 等待所有查询任务完成,将所有索引文件的查询结果放入结果列表
单个索引文件的读取逻辑如下:
- 根据索引文件状态判断从哪里读取
- UNSEALED/SEALED 状态:从本地未压缩的临时索引文件查询,读取方式和读取普通的本地索引文件类似
- UPLOADED:从已上传分级存储的 FileSegment 中读取
- 根据 key 的 hashCode 计算 hash 槽位置
- 读取 hash 槽中的索引项起始位置和总长度
- 根据索引项起始位置和索引项总长度从 FileSegment 读取索引项
- 从读到的索引项开始遍历,根据索引项的时间戳范围和 hashCode 过滤索引项,直到找到足够的索引项
4.5.3 索引文件重排
4.5.3.1 重排流程
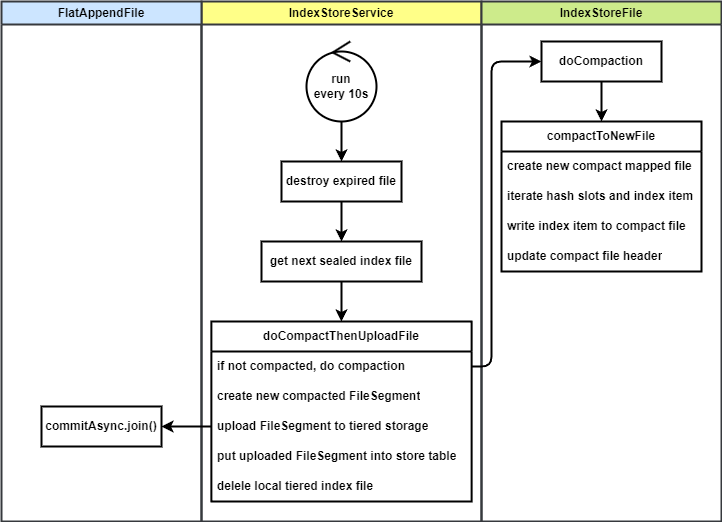
索引文件重排的入口是 IndexStoreService,它是一个服务线程,每 10s 进行一次扫描,找到索引文件表中下一个 SEALED 状态的索引文件,准备重排和上传。
重排和上传的入口函数是 doCompactThenUploadFile,它的逻辑如下
- 如果这个文件还没有被重排,调用
IndexStoreFile#doCompaction进行重排- 创建一个新的本地内存映射文件,作为重排后的文件,它的目录也是单独的。在没有上传成功之前,重排前后的两个文件同时存在,老文件用来读取,新文件用来上传。
- 未重排文件:
{storePath}/tiered_index_file/{时间戳} - 重排后文件:
{storePath}/tiered_index_file/compacting/{时间戳}
- 未重排文件:
- 遍历老文件的 hash 槽和索引项,将索引项和 hash 槽写入新文件,此时进行重排
- 更新新文件的头信息
- 创建一个新的本地内存映射文件,作为重排后的文件,它的目录也是单独的。在没有上传成功之前,重排前后的两个文件同时存在,老文件用来读取,新文件用来上传。
- 用重排后新索引文件的 ByteBuffer 在分级存储索引文件的 FlatAppendFile 中创建一个 FileSegment
- 上传该 FileSegment 到分级存储
- 上传完成之后将该 FileSegment 封装成 IndexStoreFile(UPLOADED 状态),放入
IndexStoreService的跳表(覆盖原来未上传的)。 - 删除本地的新老格式的索引文件
4.5.3.2 重排细节
左边是老的索引文件格式,这里不再赘述。重排的目标是在查询时减少对分级存储的 IOPS,也就是说在查询某个 Key 对应 hash 槽的所有索引项时,最好可以连续读。
所以重排之后的结构就呼之欲出:原来 hash 槽的链表项,在文件中的位置是随机的,通过链表指针的方式连接起来。新的格式直接将同一 hash 槽的索引项在物理位置上连续排列,去掉链表指针也可以节省每个索引项占用的大小(4 Byte)。
重排后的文件相对重排之前:
- Header 不变、hash 槽和索引项数量不变
- hash 槽大小从 4 Byte 扩大到 8 Byte,多了索引项总长度,方便一次性把这个 hash 槽的所有索引项查出来
- 0~4byte:hash 槽索引项的起始位置
- 5~8byte:这个 hash 槽所有索引项的总长度
- 索引项经过排序,去掉了链表指针,从 32byte 变为 28byte
4.6 重启恢复和元数据
分级存储的元数据是专门为了恢复分级存储文件引用而设置的,在分级存储相关的 Topic、Queue 或者 FileSegment 文件发生新建/删除时,索引文件会更新并持久化到本地文件中,在重启恢复分级存储模块时读取。
4.6.1 元数据
DefaultMetadataStore 作为分级存储元数据管理类,它扩展了 ConfigManager 类。
ConfigManager 是 RocketMQ 一些动态配置(比如 topic 配置、消费组偏移量等)也用到的配置文件抽象类,它已经实现了 load 和 persist 方法,用于持久化到本地文件和从本地文件读取。扩展它之后只需要实现 decode 方法,定义持久化哪些数据。这里持久化了 5 组元数据表,以 json 的格式存储在 {storePath}/config/tieredStoreMetadata.json。
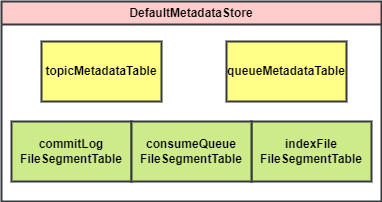
元数据文件包括两类:
Topic、Queue的数据,在FlatMessageFile创建时更新,入口是FlatMessageFile构造函数。FileSegment数据,包含创建时间、起始偏移量、大小、状态等。在 FileSegment 创建时更新,入口是FlatAppendFile#rollingNewFile。
一个简单的元数据文件示例如下:
{
"commitLogFileSegmentTable":{
"broker-a\\topic-tiered\\0":{0:{
"baseOffset":0,
"beginTimestamp":1713719372709,
"createTimestamp":1713719498811,
"endTimestamp":1713719488780,
"path":"broker-a\\topic-tiered\\0",
"sealTimestamp":0,
"size":557667000,
"status":0,
"type":0
}
}
},
"consumeQueueFileSegmentTable":{
"broker-a\\topic-tiered\\0":{0:{
"baseOffset":0,
"beginTimestamp":1713719372709,
"createTimestamp":1713719498817,
"endTimestamp":1713719488008,
"path":"broker-a\\topic-tiered\\0",
"sealTimestamp":0,
"size":32417620,
"status":0,
"type":1
}
}
},
"indexFileSegmentTable":{},
"queueMetadataTable":{
"topic-tiered":{0:{
"maxOffset":0,
"minOffset":0,
"queue":{
"brokerName":"broker-a",
"queueId":0,
"topic":"topic-tiered"
},
"updateTimestamp":1713719498827
}
}
},
"topicMetadataTable":{
"topic-tiered":{
"reserveTime":-1,
"status":0,
"topic":"topic-tiered",
"topicId":2,
"updateTimestamp":1713719372725
}
},
"topicSerialNumber":2
}4.6.2 重启恢复
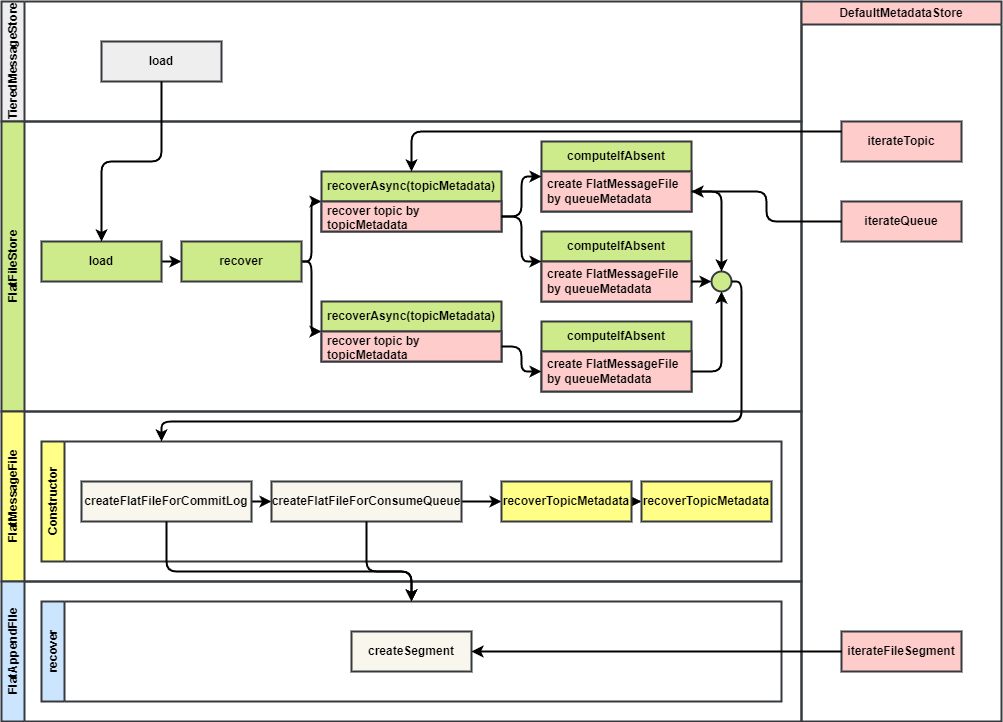
恢复的入口是 TieredMessageStore#load 方法,它调用分级存储 FlatFileStore#load 方法,先恢复分级存储,然后调用本地存储的 load 方法恢复本地存储。
FlatFileStore 的 load 方法中先清空所有分级存储文件,然后调用 recover 进行分级存储文件恢复,最后启动定时任务,每分钟扫描和清理过期文件。
recover 方法逻辑如下:
- 遍历 Topic 元数据,调用
recoverAsync(toicMetadata)并发恢复 Topic,恢复之前获取信号量避免并发度过高 - 遍历该 Topic 中的 Queue 元数据,调用
computeIfAbsent(MessageQueue)为每个队列初始化分级存储消息数据文件 FlatMessageFile。初始化分级存储消息数据文件时,会递归恢复 CommitLog、ConsumeQueue、IndexFile 的分级存储文件(也遍历元数据来恢复) FlatMessageFile的构造函数中会调用createFlatFileForCommitLog和createFlatFileForConsumeQueue来恢复对应的 FileSegment- 这两个方法也会调用元数据存储的
iterateFileSegment遍历 FileSegment 的元数据来构造 FileSegment
5. 源码解析
太长放不下,请移步 https://hscarb.github.io/rocketmq/20240429-rocketmq-tieredstore.html 查看
参考资料
- Tiered storage README.md
- RIP 57 Tiered storage for RocketMQ
- RIP 65 Tiered Storage Optimization
- Refactoring and improving Tiered Storage Implementation
- [RIP-65] Support efficient random index for massive messages
- [Enhancement] Performance Improvement and Bug Fixes for the Tiered Storage Module
- RocketMQ 多级存储设计与实现
- 谈谈 RocketMQ 5.0 分级存储背后一些有挑战的技术优化
- RocketMQ5源码(七)分层存储
欢迎关注公众号【消息中间件】(middleware-mq),更新消息中间件的源码解析和最新动态!

本文由博客一文多发平台 OpenWrite 发布!