来源:投稿 作者:175
编辑:学姐
要深入理解深度学习,从零开始创建的经验非常重要,从自己可以理解的角度出发,尽量不使用外部完备的框架前提下,实现我们想要的模型。本系列文章的宗旨就是通过这样的过程,让大家切实掌握深度学习底层实现,而不是仅做一个调包侠。
本文介绍RNN,一种用于处理序列数据的神经网络。
循环神经网络
循环神经网络(Recurrent Neural Network,RNN)是包含循环连接的网络,即有些单元是直接或间接地依赖于它之前的。
本文我们学习一种叫做Elman网络的循环网络,或称为简单循环网络(本文中的RNN都代表该网络)。隐藏层包含一个循环连接作为其输入。即,基于当前输入和前一时刻隐藏状态计算当前隐藏状态。
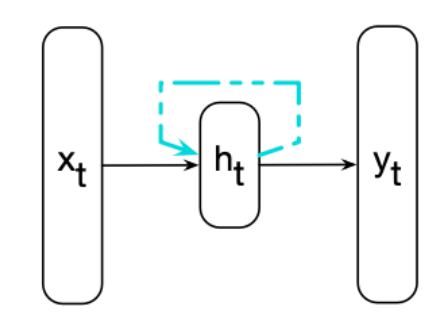
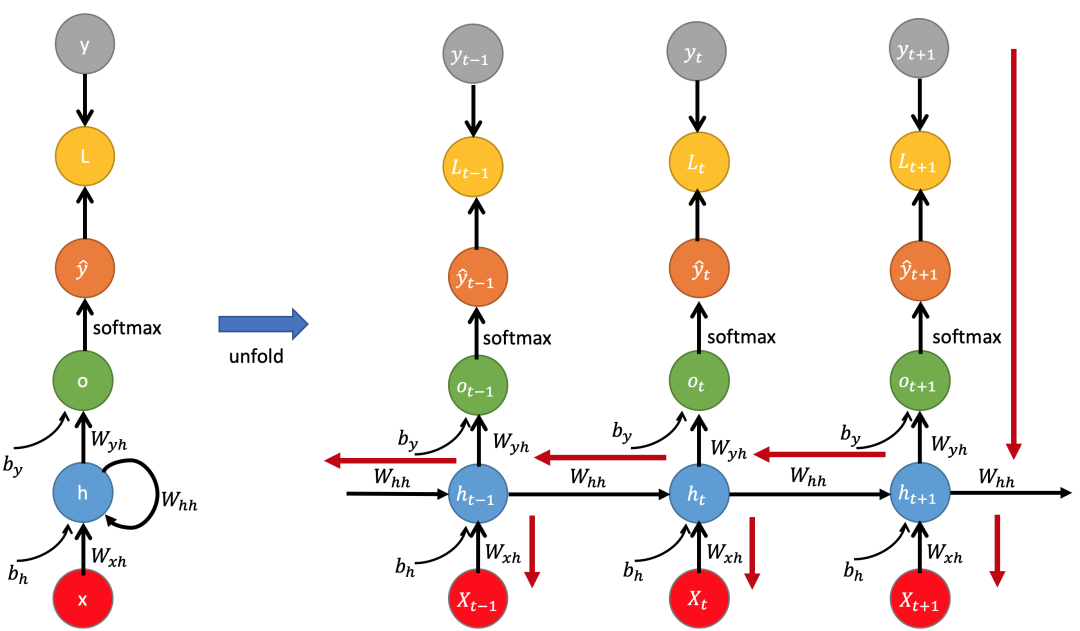
上图展示了RNN的结构,与普通前馈网络一样,表示当前输入的向量乘以权重矩阵,然后经过非线性激活函数来计算隐藏单元的值。然后用于计算相应的输出。
该网络在处理序列时,一次(一个时间步)顺序地处理序列中的一个元素,与我们之前看到的基于窗口的方法不同。我们使用下表来表示时间,这样,表示时刻(时间步)的输入向量。与前馈网络的关键区别在于上图虚线显示的循环连接。此连接使用上一个时刻隐藏层的值来增强对于当前时刻隐藏层计算的输入。
前一时刻的隐藏层提供了一种记忆(或上下文)的功能,可以提供之前的信息为未来做决定提供帮助。重要的是,这种方法理论上不需要对前文的长度进行限制,不过实际上过远的信息很难有效的保留。
前向传播
RNN中的前向传播(推理)过程和前馈网络差不多。但在使用RNN处理一个序列输入时,需要将RNN按输入时刻展开,然后将序列中的每个输入依次对应到网络不同时刻的输入上,并将当前时刻网络隐藏层的输出也作为下一时刻的输入。
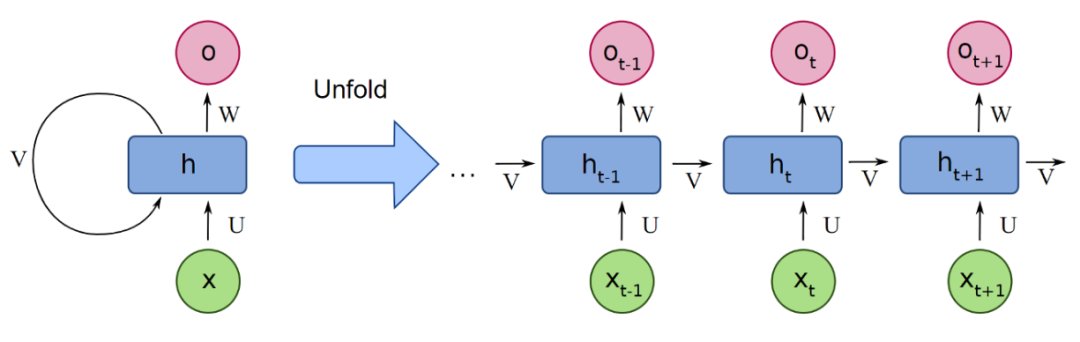
循环网络处理序列输入的示意图,图片来自https://medium.com/deeplearningbrasilia/deep-learning-recurrent-neural-networks-f9482a24d010
为了计算时刻t的输入对应的输出
(图中是
),我们需要先计算隐藏状态
。为了计算它,让输入
乘以权重矩阵
以及前一时刻的隐藏状态
乘以权重矩阵
。然后把它们的结果加起来,并经过一个激活函数
,通常为
函数,计算当前的隐藏状态
。此时,我们可以通过
来生成输出向量
:

这里要注意维度。我们用,
,
分别代表输入、隐藏和输出层的大小。那么这三个权重矩阵的维度是:
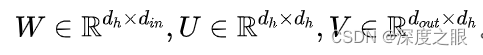
如果是多分类问题, 由softmax函数计算而成:

可以看到,时刻t的计算需要前一个时刻t-1的隐藏层激活值(隐藏状态)。显然,这是一种递归形式的定义,从序列开始到序列结束。每个时刻的输入经过层层递归,对最终的输出产生一定影响,每个时刻的隐藏状态承载了1~t时刻的全部输入信息,因此循环神经网络中的隐藏单元也被称为记忆单元。

上图简单神经网络的前向推理。
注意,矩阵U,W,V在每个时刻都是共享的,每个时刻都会计算一个和
。
这里初始时隐藏状态。
学习
我们有三个权重要更新:输入层到隐藏层的权重W;前一时刻隐藏层到当前时刻隐藏层的权重U;隐藏层到输出层的权重V。
但更新时与前馈网络不同,主要有两点。
- 为了计算时刻t的损失,我们需要时刻t-1的隐藏状态;
- 时刻t的隐藏状态同时影响了时刻t的输出和时刻t+1的隐藏状态。
所以,也影响了时刻t+1的输出和损失。因此,要评估累积的损失,我们需要知道它对当前输出以及后续输出的影响。
RNN的沿着时间反向传播,图片来自https://mmuratarat.github.io/2019-02-07/bptt-of-rnn
此时,需要修改反向传播算法,形成两阶段的算法来训练RNN中的权重。第一阶段,在第一次传播中,我们执行正向推理,如上图右边黑色箭头所代表的方向(从左到右),计算,在每个时刻累积损失,同时保存隐藏状态的值,以便在第二阶段使用。
在第二阶段,我们反向处理序列,从最后的输出往前计算梯度,即从右到左,如上图红色箭头所示。比如计算了处的梯度后,得到的损失还需要在前一步处使用。这种方法被称为沿着时间反向传播(Backpropagation Through Time,BPTT)。
我们说这里介绍的是Elman网络,那还有其他什么网络吗?
另一种称为Jordan网络。可以用以下公式来说明它们的区别:
Elman网络:
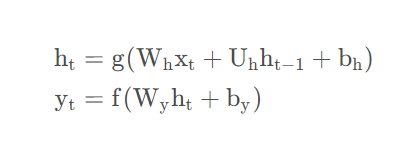
Jordan网络:
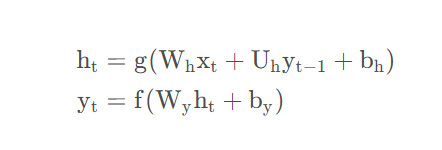
其中为输入向量;h_t为隐藏状态;y_t为输出;W,U,b是参数;f和g为激活函数。
RNN作为语言模型
RNN的这种特性,非常适用于语言模型。可以一次处理序列中的一个单词,基于当前的单词和上一个隐藏状态来预测下一个单词。可以看到,RNN没有N-Gram中N的限制,因为隐藏状态原则上可以表示前面所有单词的信息。
输入序列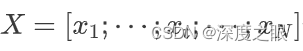 包含一系列大小
包含一系列大小![]() 为的独热向量,而输出
为的独热向量,而输出是代表词典中所有单词概率分布的向量。在每个时刻中,模型通常使用嵌入矩阵E来查看嵌入向量(而不是直接使用独热向量),然后与前一时刻的隐藏状态拼接来计算当前的隐藏状态。然后用于生成输出,它会喂给softmax层生成整个词典上的概率分布。即,在时刻t:

由![]() 计算的向量可以看成是由
计算的向量可以看成是由提供的对整个词典的所有单词得分。将该得分传入sofmtax归一化后得到概率分布。某个单词i ii作为下一个单词的概率由
![]() 表示,即
表示,即的第i个元素:

整个序列的概率就是序列中每个元素的概率之积,我们会使用![]() 代表时刻i的真实单词
代表时刻i的真实单词。那么,整个句子率
就可以计算为:
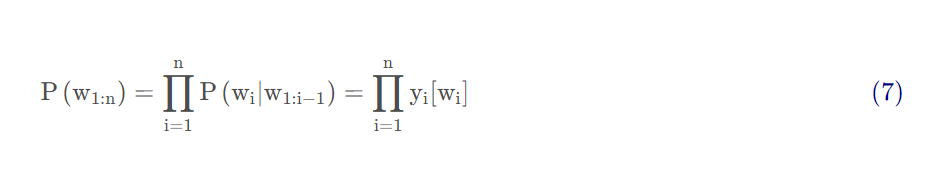
为了训练一个RNN作为语言模型,我们使用文本语料作为训练材料,让模型在每个时刻预测下一个单词。然后训练模型最小化预测真正下一个单词的误差,使用交叉熵作为损失函数:

在语言建模任务下,正确的分布单词,通常被表示为独热向量,对应正确单词位置为1,元素都为0这样,为语言建模的交叉熵损失由模型为正确单词赋予的概率决定。所以在时刻t的损失就是模型赋予下个单词的负对数概率:

因此,在输入的每个单词t位置处,模型将正确的标记序列作为输入,并使用它们来计算可能的下一个单词的概率分布,从而计算下一个标记
的模型损失。然后我们移动到下一个单词,此时我们忽略模型对下一个单词的预测,而是使用正确的标记
的序列来估计标记
的概率,这种方法被称为tearch forcing。
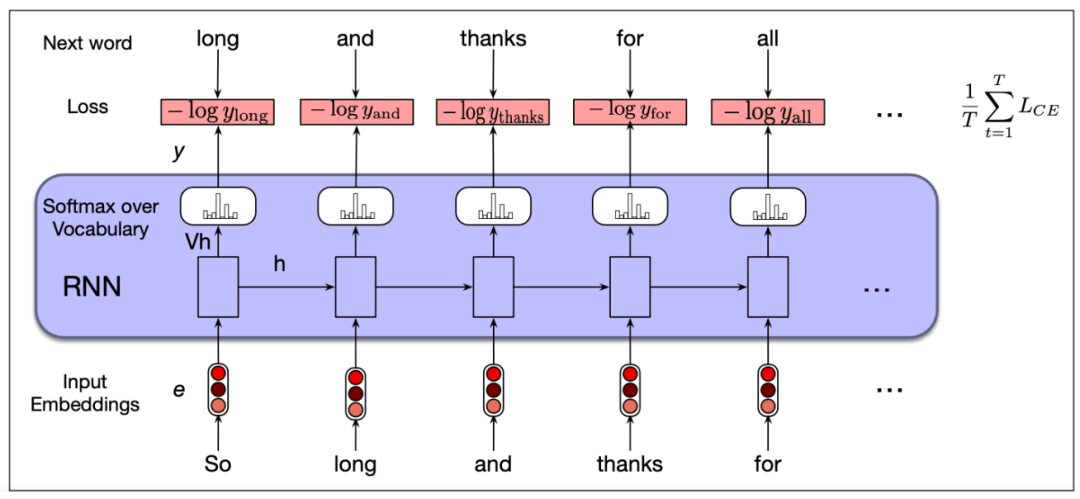
通过梯度下降来调整网络中的权值,以最小化训练序列上的平均交叉熵损失。上图说明了该训练过程。
可以发现,输入嵌入矩阵E和最后一层权重矩阵V(计算结果经过softmax)很相似。E的列向量代表在训练过程中学习到的词汇表中每个单词的词嵌入,目的是让具有相似含义和特征的单词具有相似的嵌入。并且,由于这些嵌入的长度对应于隐藏层的大小,因此嵌入矩阵的形状为
![]() 。
。
最后一层矩阵V提供了一种方法,通过计算,对词典中每个单词的可能性进行评分。这得到了一个维度
![]() 。也就是说,V的行提供了第二组学习的词嵌入。这就引出了一个明显的问题——有必要同时拥有两者吗?
。也就是说,V的行提供了第二组学习的词嵌入。这就引出了一个明显的问题——有必要同时拥有两者吗?
权重绑定(weight tying) 是一种避免这种权重冗余的方法,只需在输入和softmax层上使用同一组嵌入的方法。也就是说,我们在计算的开始和结束时都不用V,而是使用E。

这种改进,除了提升了模型困惑度之外,还显著减少了模型所需的参数量。
我们已经学习了RNN的基础知识,在实际应用上通常不是仅使用我们学到的这种RNN。而是会使用堆叠RNN和双向RNN。下面分别来了解它们。
堆叠NN
我们到此为止所学的例子中,RNN的输入都是由单词嵌入向量组成,而输出是预测单词有用的向量。但是,我们也可以使用一个RNN的整个输出作为另一个RNN的输入,通过这种方向将多个RNN网络堆叠起来。
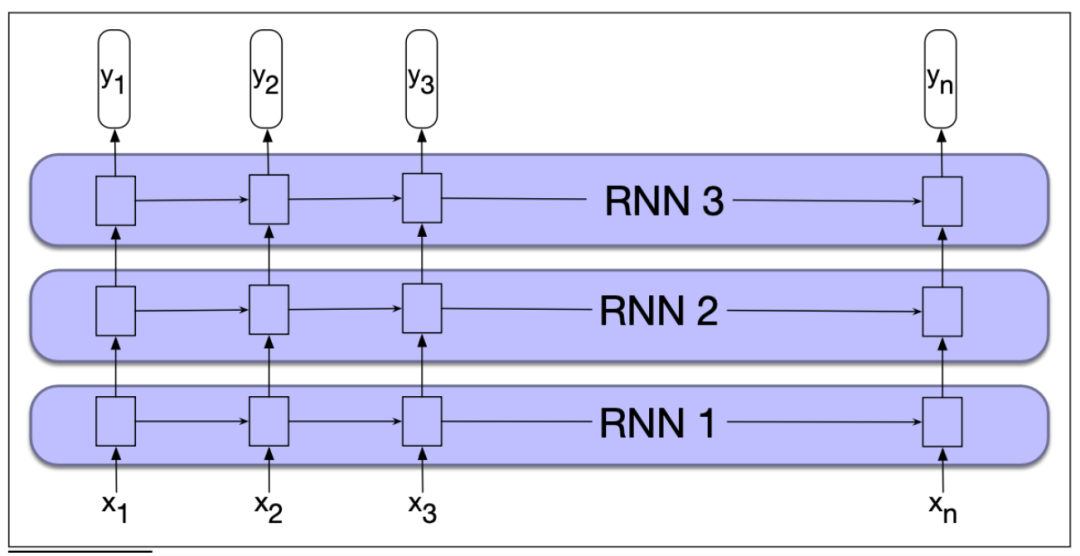
如上图所示,我们堆叠了三个RNN。
堆叠的RNN通常优于单层RNN。可能的一个原因是,网络在不同层抽象了不同的表示。堆叠RNN的初始层产生的表示可以作为深层有用的抽象——这很难在单词RNN中产生。但是,随着堆叠层数的增加,训练成本也迅速上升。
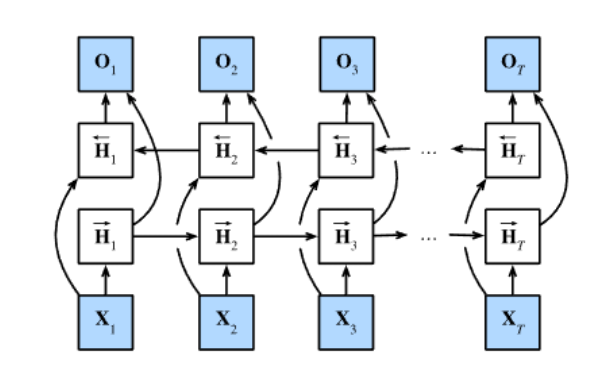
双向RNN
另一种应用较多的是双向RNN,我们上面学到的是从左到右依次处理序列中的每个元素。但在很多情况下,如果能访问整个序列再做决定,得到的效果会更好。此时就需要双向RNN。
一种实现方式时通过两个独立的RNN网络,一个按照之前的顺序从左往右读;另一个按照逆序从右往左读。在每个时刻t tt,拼接它们生成的表示。
References
Speech and Language Processing
关注下方《学姐带你玩AI》🚀🚀🚀
神经网络系列知识持续更新中
码字不易,欢迎大家点赞评论收藏!





![[前端笔记——HTML介绍] 2.开始学习HTML](https://img-blog.csdnimg.cn/b87e66ae4268487db4f42d059edc6b6a.png)