主要参考
【GPT,GPT-2,GPT-3 论文精读【李沐论文精读】-2022.03.04】 https://www.bilibili.com/video/BV1AF411b7xQ/
大语言模型综述: https://blog.csdn.net/imwaters/article/details/137019747
GPT与chatgpt的关系
图源:LLMSurvey
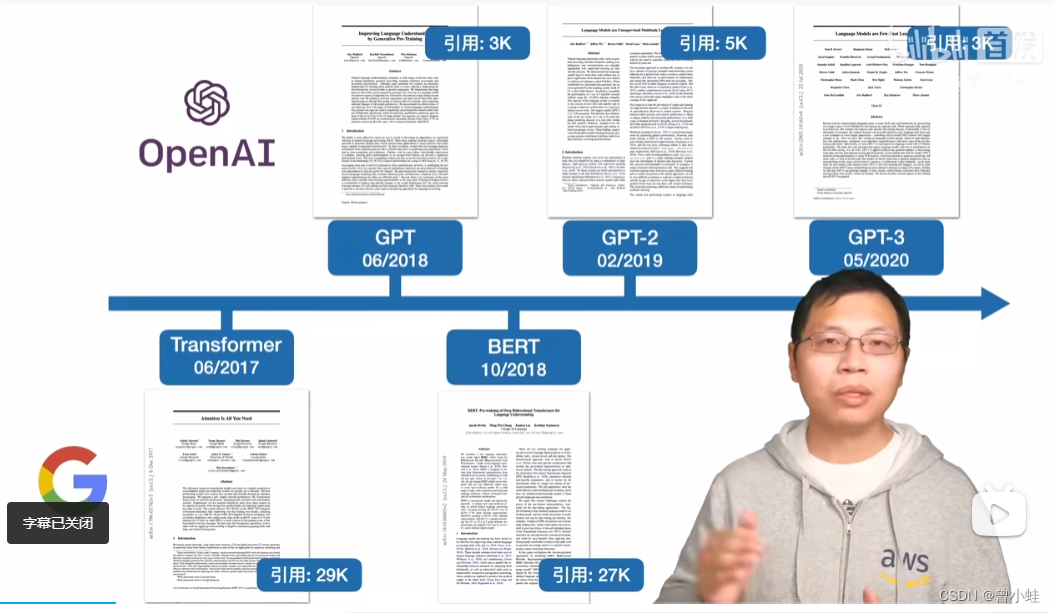
发展节点
2017.06 Transformer: 所有大语言模型LLMs的基础结构 , Attention is all you need !
2018.06 GPT: 只用Transformer解码器,只预测未来:Improving language understanding by Generative Pre-Traning
2018.10 BERT:对标GPT,完整transformer结构,完型填空 :Pre-training of Deep Bidirectional Transformers for Language Understanding
2019.02 GPT-2: 更大的数据集: Language Models are Unsupervised Multitast Learner
2020.05 GPT-3: 相对于GPT-2数据和模型都大了100倍 (极少数公司能做)GPT-3:Language models are few-shot learners
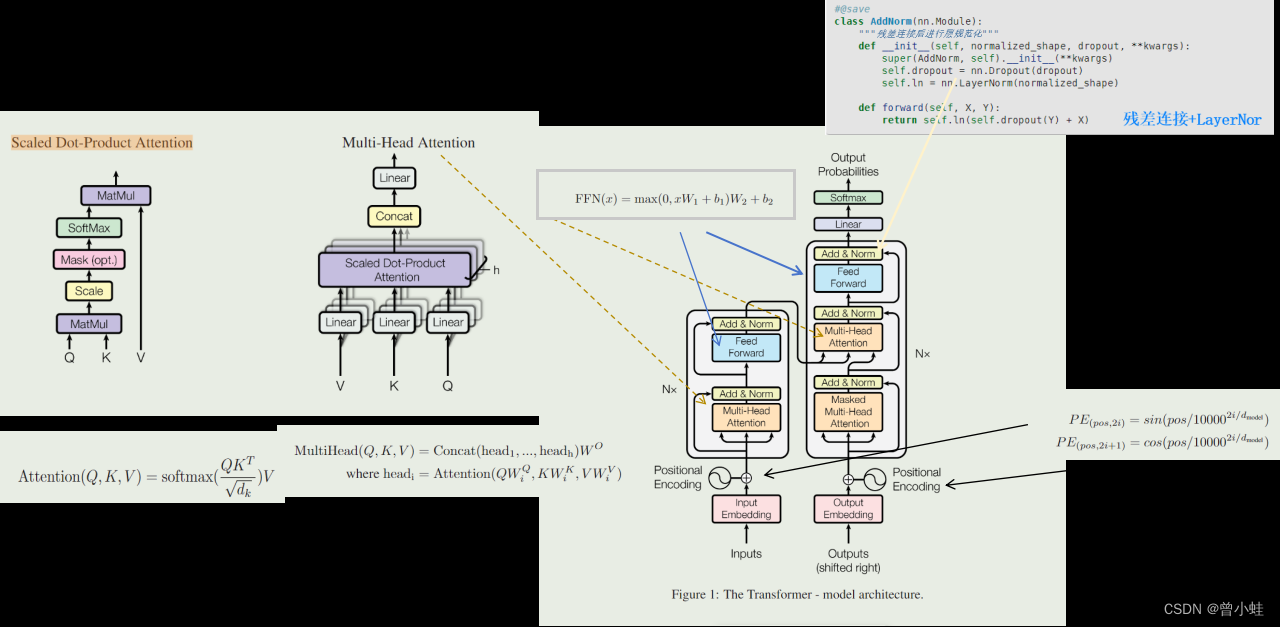
Transformer简介
论文:Attention is all you need
【68 Transformer【动手学深度学习v2】】 https://www.bilibili.com/video/BV1Kq4y1H7FL/
一、GPT-1: 使用大量没有标记文本无监督训练 (Generative Pre-Traning )
论文:利用生成式预训练来提高自然语言理解
Improving language understanding by Generative Pre-Traning
1.0 如何理解 GPT的名字含义(生成式预训练)?
生成式(Generative):这部分指的是模型的输出是生成性质的,意味着模型可以产生新的内容,而不仅仅是从输入中选择或者分类信息。在语言模型的上下文中,这通常意味着模型能够根据给定的文本提示生成自然语言文本,如回答问题、编写故事或者继续未完成的句子。
预训练(Pre-trained):预训练是指在模型被用于具体任务之前,它已经在大规模的数据集上接受了训练。这个过程使模型能够学习到语言的通用特征和模式。在预训练阶段,模型不是为了解决特定任务而训练的,而是为了学习语言的广泛应用,如语法、词汇、语义和常识关联。
1.1 二阶段训练模型:大量无标记文本 + 人工标注任务
通过在大规模无标签文本语料库上进行生成式预训练,并在每个特定任务上进行判别式微调,可以在多种自然语言理解任务上获得大幅度的提升
结构上,只用Transformer的编码器预测(预测未来)见下图左侧
损失函数上是与bert不同的
通过在大规模无标签文本语料库上进行生成式预训练,并在每个特定任务上进行判别式微调,可以在多种自然语言理解任务上获得大幅度的提升
1.2 结构与应用(预训练后,在有标注文本训练下流任务)
开始符号、结束符号、终止符
下图(左),表示Transformer架构和训练目标。
下图(右),表示 微调不同任务的输入转换示意。将所有结构化输入转换为由我们的预训练模型处理的标记序列,然后是线性+softmax 层。
其中,右侧绿色transformer块表示第一阶段得到的预训练模型
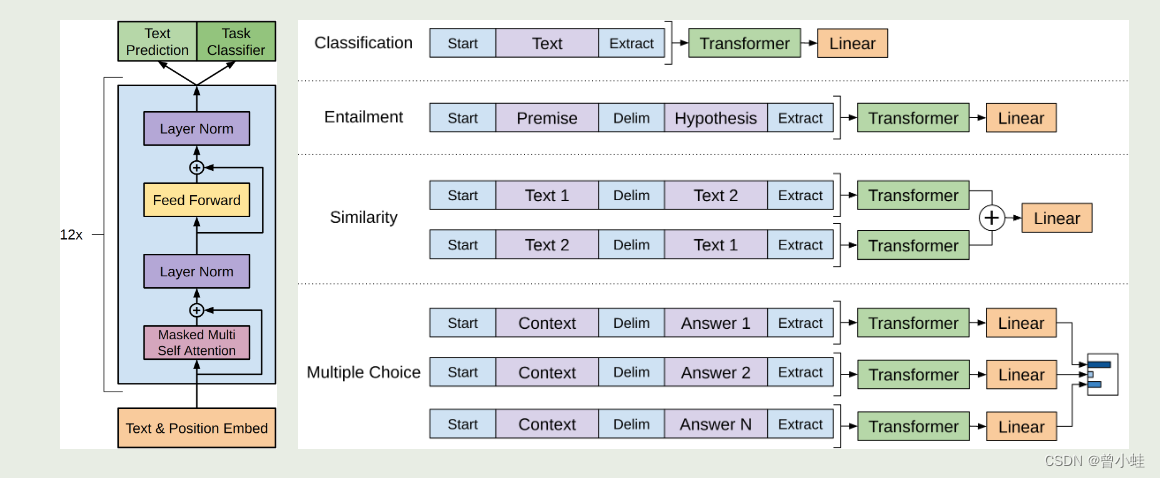
- “Extract” :指从模型的某个部分提取信息或特征的过程。模型会处理文本,提取和学习复杂的特征和模式。这个过程可以被视作是在“抽取”输入文本的语义和句法信息
- Delim”则可能是“Delimiter”的缩写,指的是分隔符。在自然语言处理任务中,分隔符用于区分文本中的不同部分
分隔符可以用来明确哪部分是前提(Premise),哪部分是假设(Hypothesis)。在处理输入数据时,模型会识别这些分隔符,以便正确地解析和处理各部分信息。
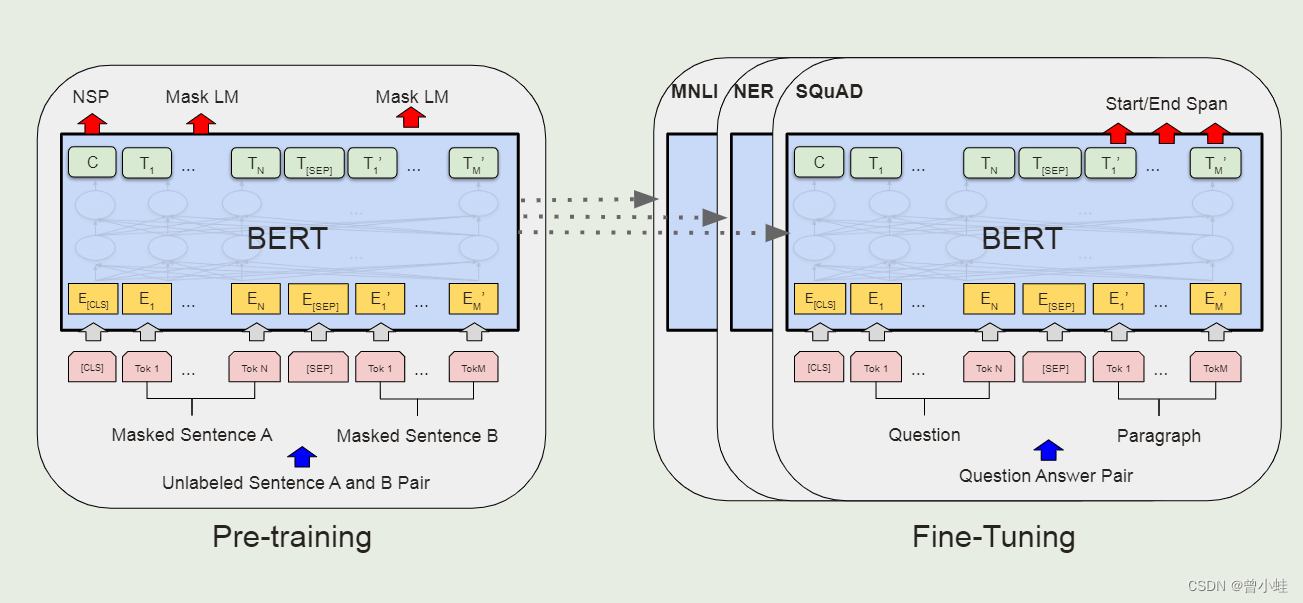
二、BERT简介 (与经典transformer一致)
pre-training + fine-tuning
名字来源于某动画(芝麻街系列),然后凑的名字
Bidirectional Encoder Representations from Transformers
2.1 bert 的整体预训练和微调流程(相同架构)
除了输出层,预训练和微调都使用相同的架构
预训练过程,输入两个句子,随机遮挡一些单词,让模型学习做完型填空
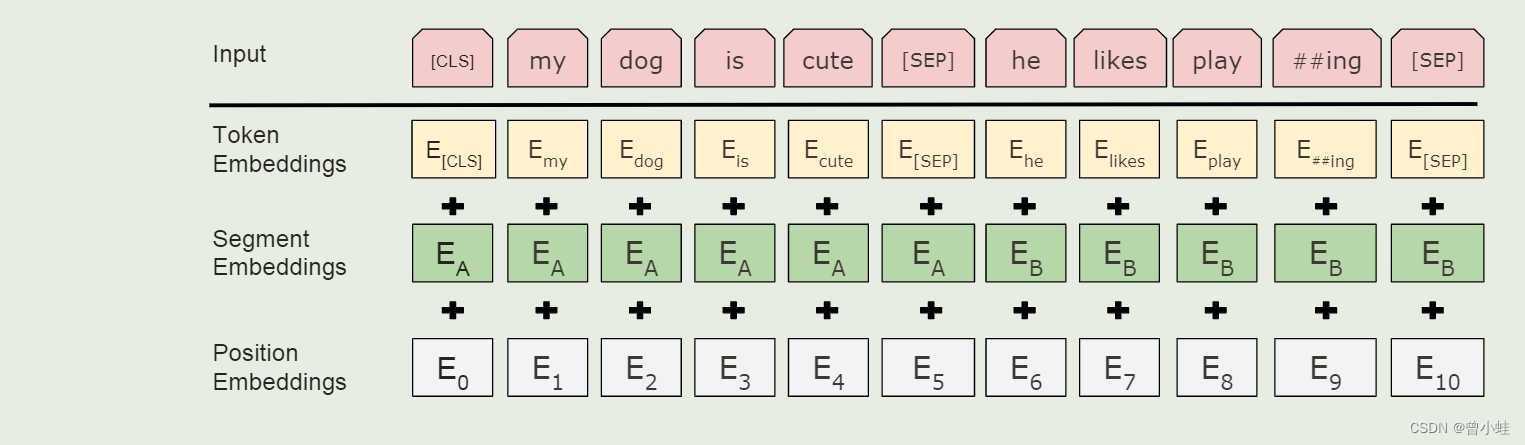
2.1.1 WordPiece embeddings (语言文字转化为embeding向量)
相关论文:1609.Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
将自然语言转化为 30000个token的词汇表的WordPoece embedding算法
2.1.2 实际的Bert输入表示
输入的句子对被打包成一个序列。我们以两种方式区分句子。
首先,我们将它们与特殊标记 ([sep]) 分开。其次,我们为每个词元(token)添加一个可学习embedding,表示它是属于句子 a 或句子 b。
如图 所示,我们将输入的embedding表示为 e,特殊 [cls] 令牌的最终隐藏向量表示为 c ∈ rh ,第 i 个输入标记的最终隐藏向量表示为
三、GPT-2: 语言模型是无监督的多任务学习器
论文:Language Models are Unsupervised Multitast Learner
参数15亿,Bert 1.3亿,参数相差大,但是性能差别不大, 主要创新点是zero-shot:
无监督训练后,不微调下游任务——没有任何参数或架构修改
输入更像自然语言
语言翻译:
(translate to french, english text, french text)
阅读理解
(answer the question, document, question, answer)
四、GPT-3 : 基于gpt-2,细节不明 (无监督训练,不需要参数更新就能学会各种任务)
20.05.Language models are few-shot learners
不用再进行模型参数更新,就能直接适应下游任务
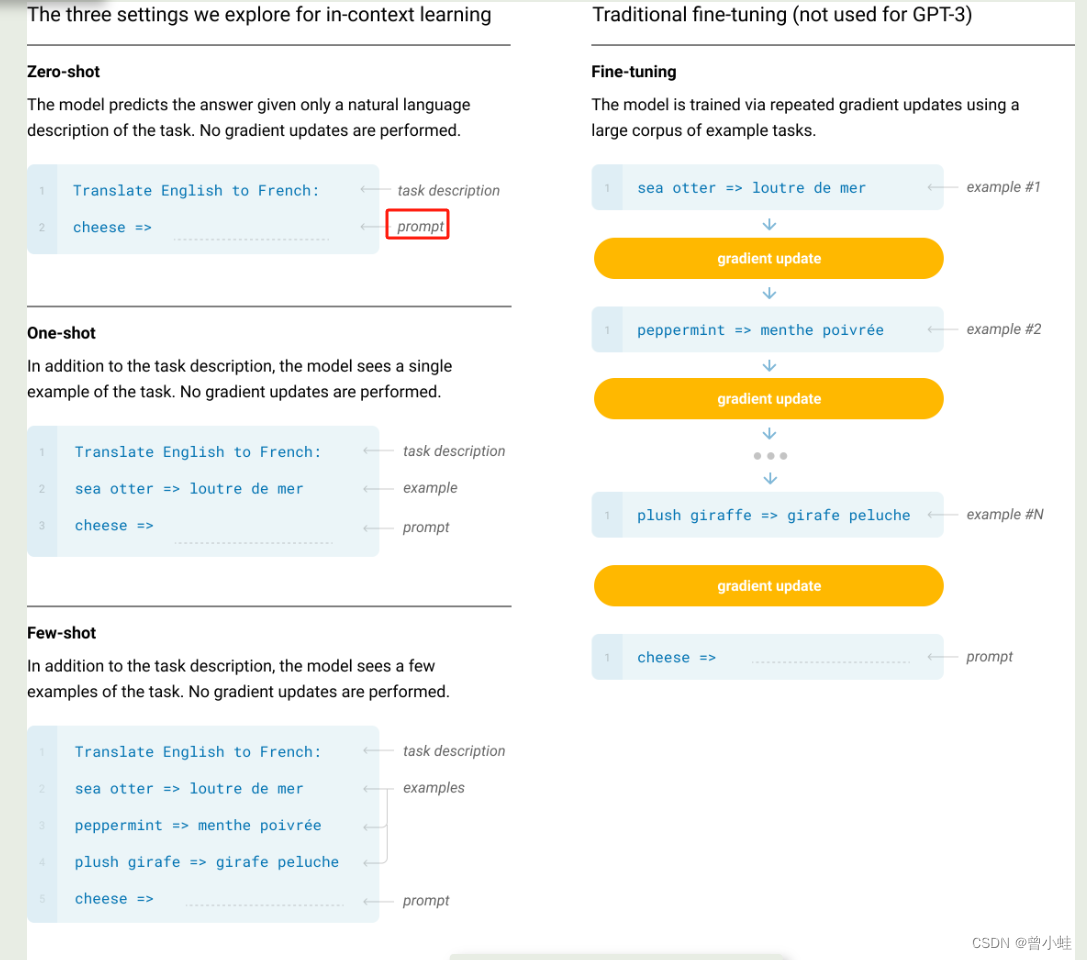
4.1 零样本、少样本学习的关系
zero-shot:零样本:表示不训练,也不给示例,直接说一句功能(例如翻译英文到中文)
one-shot :一张范例:表示给出一个范例
few-show:给出多个范例
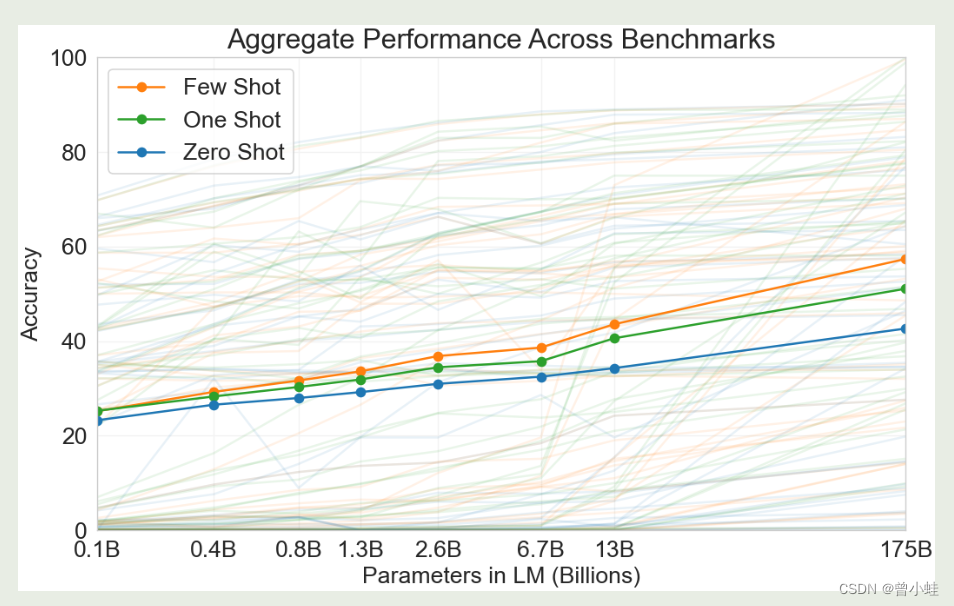
4.2 模型大小与少样本学习性能关系:少样本、零样本学习的准确率关系
实验表明:GPT3参数量扩大几百倍后,少量样本(few-shot)的学习,**准确率从20%左右到了50%**多
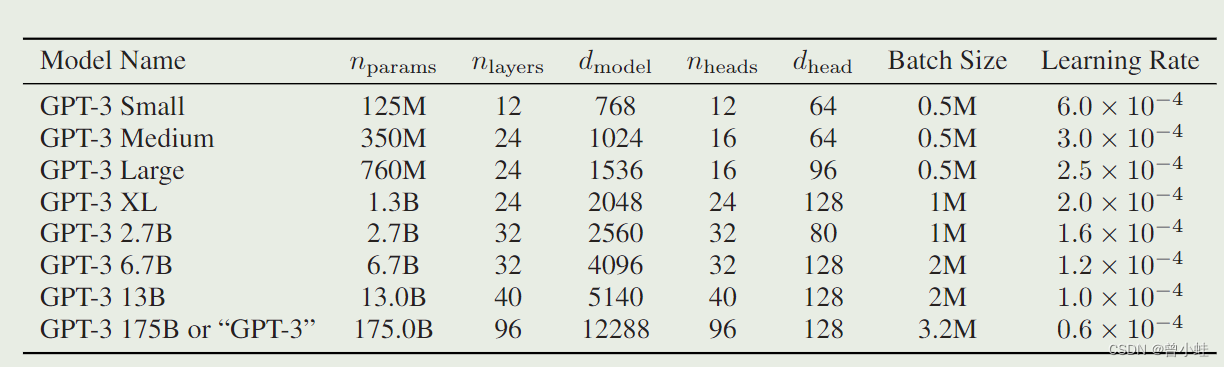
4.3 训练得到8个不同大小的模型
模型的大小、架构和学习超参数(令牌中的批量大小和学习率)。所有模型都训练了总共 300 亿个令牌。
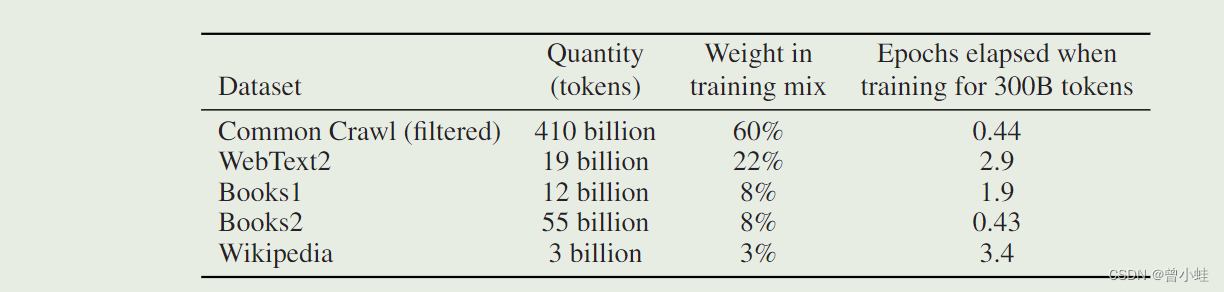
用的数据集
附录
作者信息
GPT-1

GPT-2

GPT-3