欢迎来到Cefler的博客😁
🕌博客主页:折纸花满衣
🏠个人专栏:题目解析

目录
- 👉🏻http概念初识
- http协议格式
- 👉🏻URL
- 👉🏻简单实现http协议(版本一)
- HttpProtocol.hpp
- 👉🏻http协议(版本二,增设解析请求行)
- HttpProtocol.hpp
- Main.cc
- 补充知识
- rz命令
- ifstream的seekg和tellg
👉🏻http概念初识
HTTP(Hypertext Transfer Protocol)是一种用于传输超文本数据(如HTML、CSS、JavaScript等)的应用层协议。它是万维网的基础,用于在客户端和服务器之间传输信息。以下是关于HTTP协议的一些重要信息:
特点:
-
无连接性(Connectionless):每个请求/响应对都是独立的,服务器在处理完一个请求后断开连接,等待下一个请求的到来。
-
无状态性(Stateless):每个请求之间没有关联,服务器不会保留之前请求的状态信息,每个请求都是独立处理的。
-
基于文本(Text-based):HTTP的请求和响应都是以纯文本的形式进行传输,易于阅读和调试。
-
灵活性(Flexibility):HTTP支持多种数据类型和方法,可以传输各种类型的数据,并支持多种应用场景。
工作原理:
-
客户端-服务器模型:HTTP是一种客户端-服务器模型的协议,客户端发送请求,服务器返回响应。
-
请求-响应模式:客户端向服务器发送请求,请求包括方法(GET、POST等)、URL、HTTP版本、请求头部等信息;服务器接收到请求后,返回相应的响应,包括状态码、响应头部、响应体等信息。
http底层的发送和传输协议就是依靠TCP协议实现的,http说白了就是在TCP协议的基础上增设和规范了数据的结构性。
请求方法:
- GET:请求指定的资源。
- POST:向指定资源提交数据进行处理请求。
- PUT:上传指定的URI,作为其表示。
- DELETE:请求服务器删除指定的资源。
- PATCH:对资源进行部分修改。
- HEAD:类似于GET请求,只不过服务器在响应中只返回首部,不返回实体的主体部分。
状态码:
- 1xx:信息性状态码。
- 2xx:成功状态码。
- 3xx:重定向状态码。
- 4xx:客户端错误状态码。
- 5xx:服务器错误状态码。
协议版本:
- HTTP/1.0:最初的版本,每次请求/响应建立一个新的连接。
- HTTP/1.1:持久连接,复用连接,支持管道化请求。
- HTTP/2.0:二进制协议,多路复用,头部压缩,服务器推送等特性。
安全性:
- HTTPS:HTTP的安全版本,使用SSL/TLS协议进行加密通信,保护数据的安全性和完整性。
HTTP协议在互联网中扮演着重要的角色,它的简单性和灵活性使得它成为了Web开发中不可或缺的一部分。
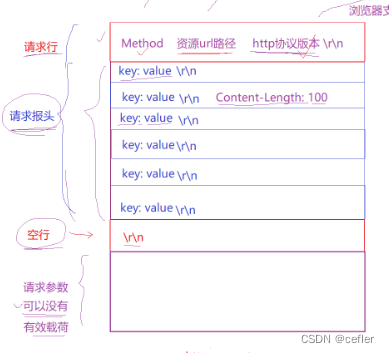
http协议格式
http协议主要分两个部分:请求和响应,
📃请求
- 首行: [方法] + [url] + [版本]
- Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示Header部分结束
- Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Heade中会有一个 Content-Length属性来标识Body的长度
📃响应
- 首行: [版本号] + [状态码] + [状态码解释]
- Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示Header部分结束
- Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有一个Content-Length属性来标识Body的长度; 如果服务器返回了一个html页面, 那么html页面内容就是在body中.

👉🏻URL
URL(Uniform Resource Locator)是统一资源定位符的缩写,是用于标识互联网上资源位置的一种标识符。它由多个部分组成,用于定位资源的地址以及指定访问该资源的方式。
💦 URL的结构:
一个标准的URL通常由以下几个部分组成:
- 协议(Protocol):指定访问资源所使用的协议或者规则,如 HTTP、HTTPS、FTP 等。
http://表示的是协议名称,表示请求时需要使用的协议,通常使用的是HTTP协议或安全协议HTTPS。HTTPS是以安全为目标的HTTP通道,在HTTP的基础上通过传输加密和身份认证保证了传输过程的安全性
-
主机名(Host):指定资源所在的主机或者服务器的域名或者IP地址。
-
端口号(Port):指定访问资源所使用的端口号。通常,如果使用默认端口号,则可以省略。
-
路径(Path):指定服务器上资源的路径。它是资源在服务器上的具体位置。
-
查询字符串(Query String):用于传递参数给服务器。它以
?开始,多个参数之间用&分隔。 -
片段标识符(Fragment Identifier):标识资源中的特定部分。它以
#开始,用于定位文档中的特定位置。

💦示例:
考虑以下示例URL:
https://www.example.com:8080/path/to/resource?param1=value1¶m2=value2#section3
-
协议(Protocol):HTTPS
-
主机名(Host):www.example.com(服务器地址)
-
端口号(Port):8080
-
路径(Path):/path/to/resource(在服务器下的资源路径)
-
查询字符串(Query String):param1=value1¶m2=value2
-
片段标识符(Fragment Identifier):section3
域名 www.example.com 可以分为以下三个部分:
-
子域名(Subdomain):在这个示例中,“www” 是子域名。它位于主域名之前,用于表示特定的服务、部门或者功能。通常,“www” 是用于指示该域名用于网站服务的子域名,但也可以使用其他的子域名,比如 “blog”、“shop” 等。
-
主域名(Domain):在示例中,“example.com” 是主域名。它是一个在互联网上唯一的名称,用于表示一个网站或者服务的整体身份。主域名通常由注册商注册,并且需要进行域名解析以映射到相应的IP地址。
-
顶级域名(Top-Level Domain,TLD):在示例中,“.com” 是顶级域名。顶级域名是域名体系中的最高层次,用于表示域名的类型或者所属的组织、地理位置等信息。常见的顶级域名包括 “.com”、“.net”、“.org” 等通用顶级域名,以及各个国家/地区的国家顶级域名(如 “.cn”、“.uk” 等)。
综上所述,www.example.com 这个域名可以分为 “www”(子域名)、“example”(主域名)和 “.com”(顶级域名)三个部分。
💦用途:
URL是互联网上资源的唯一标识符,用于在Web浏览器中定位和访问网页、图像、文件、视频等资源。通过URL,用户可以直接访问并获取到网络上的各种资源。
总之,URL是互联网上资源的地址标识符,它由多个部分组成,用于指定资源的位置和访问方式。
👉🏻简单实现http协议(版本一)
HttpProtocol.hpp
#pragma once
#include<iostream>
#include<string>
#include<vector>
using namespace std;
const string HttpSep = "\r\n";
class HttpRequest
{
public:
HttpRequest():
_req_blank(HttpSep)
{
}
bool Getline(string& str,string* line)//获取请求行的内容
{
//1.找到内容停止符的位置
auto pos = str.find(HttpSep);
if(pos==string::npos) return false;
//2.截取正文
*line = str.substr(0,pos);
//3.读取完后,将str中已提取的内容清空
str.erase(0,pos+HttpSep.size());
return true;
}
//反序列化
void Deserialize(string& request)
{
//1.先读请求行
string line;
bool ok = Getline(request,&line);
if(!ok) return;//如果读不到\r\n则退出
_req_line = line;
//2.再读报文每一行的内容
while(true)
{
bool ok = Getline(request,&line);//再接着往下读取
if(ok&&line.empty())
{
//如果读到了,但是内容为空
//则剩下的内容为
_req_content = request;
}
else if(ok&&!line.empty())
{
_req_header.push_back(line);
}
else
break;
}
}
void DebugHttp()
{
std::cout << "_req_line" << _req_line << std::endl;
for(auto &line : _req_header)
{
std::cout << "---> " << line << std::endl;
}
std::cout << "_req_blank: " << _req_blank << std::endl;
std::cout << "_req_content: " << _req_content << std::endl;
}
private:
string _req_line;//请求行
vector<string> _req_header;//用来存储请求数据中所有的请求行数据
string _req_content;//报文内容
string _req_blank;//空行
};
最后去网页访问我们的服务器,就可以得到这个
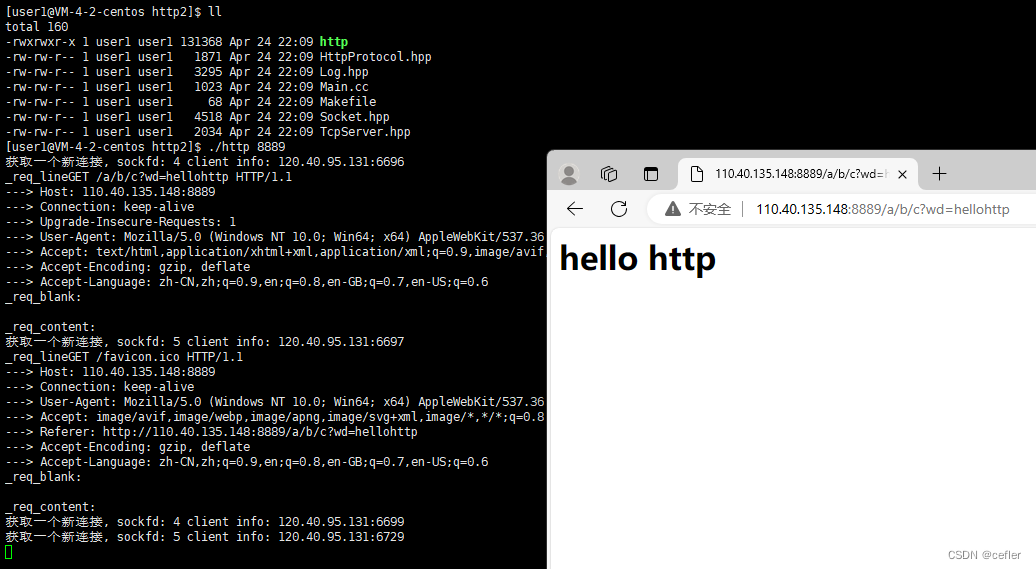
👉🏻http协议(版本二,增设解析请求行)
此次版本,我们主要给Http协议中增设解析请求行的功能,
将请求行解析为三部分:
- method:请求方法
- URL:资源地址
- http_version:http的版本
而后我们还要再对URL地址进行解析,可以得到
- path:资源的路径
- suffix:资源的后缀名
文件目录如下:
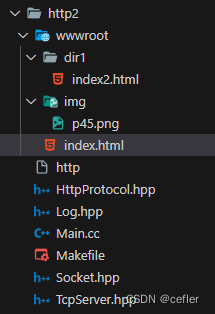
HttpProtocol.hpp
#pragma once
#include <iostream>
#include <string>
#include <vector>
#include <sstream>
using namespace std;
const string HttpSep = "\r\n";
const string homepage = "index.html";
const string wwwroot = "./wwwroot"; // 根目录
class HttpRequest
{
public:
HttpRequest() : _req_blank(HttpSep), _path(wwwroot)
{
}
~HttpRequest()
{
}
bool Getline(string &str, string *line) // 获取请求行的内容
{
// 1.找到内容停止符的位置
auto pos = str.find(HttpSep);
if (pos == string::npos)
return false;
// 2.截取正文
*line = str.substr(0, pos);
// 3.读取完后,将str中已提取的内容清空
str.erase(0, pos + HttpSep.size());
return true;
}
void Deserialize(string &request)
{
// 1.先读请求行
string line;
bool ok = Getline(request, &line);
if (!ok)
return; // 如果读不到\r\n则退出
_req_line = line;
// 2.再读报文每一行的内容
while (true)
{
bool ok = Getline(request, &line); // 再接着往下读取
if (ok && line.empty())
{
// 如果读到了,但是内容为空
// 则剩下的内容为
_req_content = request;
}
else if (ok && !line.empty())
{
_req_header.push_back(line);
}
else
break;
}
}
void ParseReqLine()
{
stringstream ss(_req_line);
ss >> _method >> _url >> _http_version;
if (_url == "/")
{
// 如果是在当前下目录,则直接令它的路径资源终点为index.html
_path += _url;
_path += homepage;
}
else
{
_path += _url;
}
}
void ParseSuffix()
{
auto pos = _path.rfind(".");
if (pos == string::npos)
_suffix = ".html";
else
_suffix = _path.substr(pos);
}
void Parse()
{
// 1.解析请求行
ParseReqLine();
// 2.解析资源后缀
ParseSuffix();
}
void DebugHttp()
{
std::cout << "_req_line" << _req_line << std::endl;
for (auto &line : _req_header)
{
std::cout << "---> " << line << std::endl;
}
std::cout << "_req_blank: " << _req_blank << std::endl;
std::cout << "_req_content: " << _req_content << std::endl;
std::cout << "Method: " << _method << std::endl;
std::cout << "url: " << _url << std::endl;
std::cout << "http_version: " << _http_version << std::endl;
}
// 接下来再整几个返回解析后内容的函数接口
string Url()
{
return _url;
}
string Path()
{
return _path;
}
string Suffix()
{
return _suffix;
}
private:
string _req_line; // 请求行
vector<string> _req_header; // 用来存储请求数据中所有的请求行数据
string _req_content; // 报文内容
string _req_blank; // 空行
// 解析之后的内容
string _method; // 请求方法
string _url; // 资源路径
string _http_version; // http版本
string _path; // 资源的具体文件路径位置,path包含在url中,所以需要从url中解析
string _suffix; // 请求资源的后缀
};
Main.cc
#include <iostream>
#include <memory>
#include <string>
#include <unistd.h>
#include <fstream>
#include "TcpServer.hpp"
#include "HttpProtocol.hpp"
string SuffixToType(const std::string &suffix) // 返回后缀名对应的http-type
{
if (suffix == ".html" || suffix == ".html")
return "text/html";
else if (suffix == ".png")
return "image/png";
else if (suffix == ".jpg")
return "image/jpeg";
else
{
return "text/html";
}
}
string GetFileContent(const string &path)
{
// 为了中间不出现字符解码出现问题
// 我们读取文件内容,而是以二进制形式读取
ifstream in(path, std::ios::binary); // 二进制读写
if (!in.is_open())
return "";
in.seekg(0, in.end); // 位置移到文件末尾
int filesize = in.tellg(); // 读取文件当前位置之前的大小
in.seekg(0, in.beg); // 读完大小后回到开头
string content; // 存储读到的二进制内容
content.resize(filesize);
in.read((char *)content.c_str(), filesize);
in.close();
return content;
}
// request: 我们认为我们已经读到了一个完整的请求了
std::string HandlerHttpRequest(std::string &request)
{
HttpRequest req;
// 1.反序列化+解析http信息+打印http信息
req.Deserialize(request);
req.Parse();
req.DebugHttp();
// 2.获取请求URL中的文件资源,即文件的内容
string content = GetFileContent(req.Path());
// 3.打印看看解析后,资源文件的后缀和对应的http格式类型
std::cout << "suffix: " << req.Suffix() << " Type: " << SuffixToType(req.Suffix()) << std::endl;
if (!content.empty())
{
//返回http状态+请求到的资源信息+Content-Type
std::string httpstatusline = "Http/1.0 200 OK\r\n";
std::string httpheader = "Content-Length: " + std::to_string(content.size()) + "\r\n";
httpheader += "Content-Type: " + SuffixToType(req.Suffix()) + "\r\n"; // 正文的类型
httpheader += "\r\n";
std::string httpresponse = httpstatusline + httpheader + content;
return httpresponse;
}
return "";
}
// ./server port
int main(int argc, char *argv[])
{
if (argc != 2)
{
std::cout << "Usage : " << argv[0] << " port" << std::endl;
return 0;
}
uint16_t localport = std::stoi(argv[1]);
std::unique_ptr<TcpServer> svr(new TcpServer(localport, HandlerHttpRequest));
svr->Loop();
return 0;
}
实现效果如下:
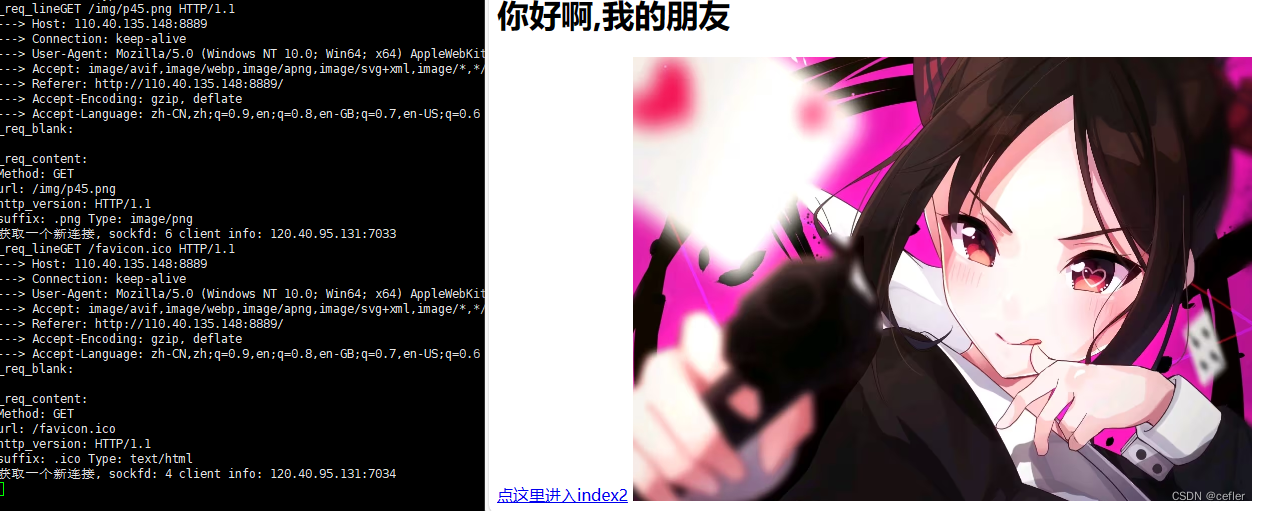
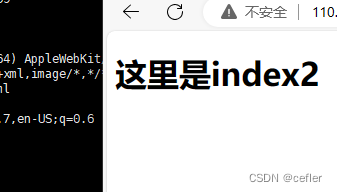
补充知识
rz命令
rz 命令是用于在 Linux 系统中接收文件的命令,通常用于在终端下通过串口或者 SSH 连接从另一台计算机发送文件到本地计算机。这个命令通常与 sz 命令一起使用,sz 用于发送文件,rz 用于接收文件。
使用 rz 命令时,通常会通过串口或者 SSH 连接到远程计算机,然后在远程计算机上执行 sz 命令发送文件,最后在本地计算机上执行 rz 命令来接收文件。
要使用 rz 命令接收文件,你需要先确保你的 Linux 系统上已经安装了支持该命令的终端软件,例如 minicom、screen、picocom 等,以及 sz 和 rz 命令所在的软件包。
在使用 rz 命令接收文件时,默认情况下文件会保存到当前工作目录下。如果你想要控制 rz 命令将接收的文件保存到特定的目录下,你可以在执行 rz 命令之前先切换到你想要保存文件的目录。
ifstream的seekg和tellg
在 C++ 中,ifstream 是用于从文件中读取数据的输入流类,seekg 和 tellg 是 ifstream 类的成员函数,用于在文件中定位和查询当前读取位置的偏移量。
-
seekg:seekg函数用于在文件中定位读取位置。它有多个重载形式,可以设置文件读取位置的绝对位置或相对位置。通常情况下,seekg函数的参数为一个streampos类型的偏移量,表示从文件开始位置的偏移量,但也可以使用ios_base::seekdir类型的参数指定相对于当前位置或者文件末尾的偏移量。 -
tellg:tellg函数用于查询当前读取位置的偏移量。它返回一个streampos类型的值,表示当前读取位置相对于文件开始位置的偏移量。
这两个函数通常用于实现文件的随机访问,可以在文件中自由移动读取位置。下面是一个简单的示例:
#include <iostream>
#include <fstream>
int main() {
std::ifstream file("example.txt", std::ios::binary); // 打开一个二进制文件用于读取
// 获取当前读取位置的偏移量
std::streampos currentPosition = file.tellg();
std::cout << "Current position: " << currentPosition << std::endl;
// 移动读取位置到文件末尾
file.seekg(0, std::ios::end);
// 获取文件末尾的偏移量
std::streampos endPosition = file.tellg();
std::cout << "End position: " << endPosition << std::endl;
// 将读取位置移动回文件开头
file.seekg(0, std::ios::beg);
// 读取文件内容
// ...
return 0;
}
这段代码演示了如何使用 seekg 和 tellg 函数在文件中定位和查询读取位置的偏移量。
如上便是本期的所有内容了,如果喜欢并觉得有帮助的话,希望可以博个点赞+收藏+关注🌹🌹🌹❤️ 🧡 💛,学海无涯苦作舟,愿与君一起共勉成长