Python 基于 OpenCV 视觉图像处理实战 之 OpenCV 简单人脸检测/识别实战案例 之七 简单进行人脸检测并添加面具特效实现
目录
Python 基于 OpenCV 视觉图像处理实战 之 OpenCV 简单人脸检测/识别实战案例 之七 简单进行人脸检测并添加面具特效实现
一、简单介绍
二、简单进行人脸检测并添加面具特效实现原理方法
1. detect_faces(frame)
2. resize_mask(mask, face_width, face_height)
3. overlay_mask(mask, frame, face_x, face_y, face_width, face_height, offset_x=0, offset_y=0, angle=0)
三、简单进行人脸检测并添加面具特效实现案例实现简单步骤
四、注意事项
一、简单介绍
Python是一种跨平台的计算机程序设计语言。是一种面向对象的动态类型语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。Python是一种解释型脚本语言,可以应用于以下领域: Web 和 Internet开发、科学计算和统计、人工智能、教育、桌面界面开发、软件开发、后端开发、网络爬虫。
这里使用 Python 基于 OpenCV 进行视觉图像处理,......
OpenCV 提供了一些已经训练好的级联分类器,这些级联分类器以XML文件的方式保存在以下路径中:
...\Python\Lib\site-packages\cv2\data\OpenCV提供了一些经过预训练的人脸检测器模型文件,这些文件通常包含在OpenCV的安装包中。你也可以在OpenCV的官方GitHub页面或者OpenCV官方网站的下载页面找到这些模型文件的下载链接。
一般来说,你可以从以下位置获取OpenCV的预训练模型文件:
- OpenCV GitHub Release 页面:在 Releases · opencv/opencv · GitHub 找到你需要的版本,然后在下载的压缩包中找到位于 opencv\data 目录下的人脸检测器模型文件。
- OpenCV 官方网站下载页面:访问 OpenCV 官方网站 Releases - OpenCV ,下载你需要的版本,并在相应的压缩包中查找人脸检测器模型文件。
请确保下载与你使用的OpenCV版本兼容的模型文件。
该案例效果

二、简单进行人脸检测并添加面具特效实现原理方法
视频中检测人脸并添加特效是一种在视频流或视频文件中实时或离线检测人脸,并在检测到的人脸位置上添加各种视觉效果或特效的技术。这种技术通常用于视频编辑、增强现实、虚拟现实、社交媒体滤镜等应用中。
实现这种技术的一般步骤包括:
人脸检测: 首先,在每个视频帧中使用人脸检测算法检测人脸的位置和大小。常用的人脸检测算法包括Haar级联检测器、深度学习基于卷积神经网络的检测器等。
特效添加: 一旦检测到人脸,就可以在人脸位置上添加各种特效或效果。这些特效可以是图像、视频、动画等。例如,可以添加面具、滤镜、贴纸、变形等。
特效跟踪: 在视频中,人脸位置和姿态可能会随时间变化,因此需要在连续的视频帧之间跟踪人脸,并相应地调整添加的特效,以确保其与人脸保持一致。这可能需要使用跟踪算法,如光流法、卡尔曼滤波器等。
性能优化: 实时视频处理需要考虑性能问题,包括算法的速度、内存占用和电源消耗。因此,需要对算法进行优化,以实现快速和高效的视频处理。
用户交互: 对于一些应用,例如社交媒体滤镜,用户可能希望能够与添加的特效进行交互,例如调整特效的位置、大小、颜色等。因此,需要提供用户友好的界面来实现这种交互。
总的来说,视频中检测人脸并添加特效是一项复杂的技术,涉及多个步骤和算法,并需要综合考虑性能、用户体验和实时性等因素。
当我们运行此代码时,它首先打开视频文件。然后,它会逐帧读取视频,对每一帧进行以下处理:
人脸检测:
- 使用OpenCV的Haar级联分类器来检测视频帧中的人脸。
- 首先将视频帧转换为灰度图像,因为Haar级联分类器对灰度图像的效果更好。
- 然后使用
detectMultiScale方法在灰度图像中检测人脸,返回每个检测到的人脸的位置和尺寸。面具叠加:
- 对于每个检测到的人脸,计算人脸的中心坐标和尺寸。
- 根据人脸的中心坐标和尺寸,在人脸的位置上叠加面具。
- 面具的大小会根据人脸的尺寸进行调整,以确保与人脸尺寸匹配。
- 如果检测到多个人脸,将为每个人脸叠加面具。
面具位置调整:
- 通过按键控制面具在视频帧上的位置。
- 按下键盘上的"W"、"A"、"S"、"D"键,分别向上、向左、向下、向右移动面具。
角度计算:
- 尝试检测人脸区域中的眼睛位置。
- 如果检测到两只眼睛,则计算两只眼睛的中心坐标,并根据它们的位置计算人脸的偏转角度。
- 这个角度可以用来调整面具的旋转,使其与人脸的角度保持一致。
- 角度计算是根据两只眼睛的位置确定的,因为眼睛通常是人脸的重要特征,角度计算的准确性取决于眼睛检测的准确性。
案例涉及到了以下关键函数:
detect_faces(frame)resize_mask(mask, face_width, face_height)overlay_mask(mask, frame, face_x, face_y, face_width, face_height, offset_x=0, offset_y=0, angle=0)
下面对每个函数进行详细说明,包括参数、功能和返回值:
1.
detect_faces(frame)参数:
frame: 要检测人脸的视频帧,必须是BGR格式的图像。功能:
- 使用Haar级联分类器检测视频帧中的人脸。
- 将视频帧转换为灰度图像,并在灰度图像中检测人脸。
- 返回检测到的人脸区域的坐标和尺寸。
返回值:
faces: 检测到的人脸区域的列表,每个人脸由一个包含(x, y, w, h)四个元素的元组表示,分别表示人脸区域的左上角坐标和宽度、高度。2.
resize_mask(mask, face_width, face_height)参数:
mask: 要调整大小的面具图像,必须是BGR格式的图像。face_width: 人脸的宽度,即要调整的目标宽度。face_height: 人脸的高度,即要调整的目标高度。功能:
- 调整面具的大小,使其与人脸尺寸匹配。
返回值:
- 调整大小后的面具图像。
3.
overlay_mask(mask, frame, face_x, face_y, face_width, face_height, offset_x=0, offset_y=0, angle=0)参数:
mask: 要叠加到视频帧上的面具图像,必须是BGR格式的图像。frame: 要叠加面具的视频帧,必须是BGR格式的图像。face_x: 人脸的中心点的x坐标。face_y: 人脸的中心点的y坐标。face_width: 人脸的宽度。face_height: 人脸的高度。offset_x(可选): 面具在x方向上的偏移量,默认为0。offset_y(可选): 面具在y方向上的偏移量,默认为0。angle(可选): 面具的旋转角度,默认为0。功能:
- 将面具叠加到视频帧上,覆盖在人脸区域上。
- 面具的位置会根据人脸中心点的位置和偏移量进行调整。
- 可以通过旋转角度参数调整面具的旋转角度,使其与人脸的角度保持一致。
返回值:
- 叠加面具后的视频帧。
在本例中,我们使用了基于人眼位置的简单方法来估计人脸的偏转方向,但是这种方法可能不够精确。如果需要更准确地估计人脸的旋转角度,可以考虑使用更高级的技术,比如基于人脸关键点的姿态估计算法,或者使用深度学习模型,例如人脸姿态估计的深度学习模型,比如3D人脸重建等。
人脸偏转角度的计算确实是一个比较复杂的问题,因为它涉及到人脸在三维空间中的旋转。常见的方法包括使用人脸关键点检测或者深度学习模型来获取人脸姿态。这些方法可以更准确地估计人脸的旋转角度,但是也更加复杂。
如果你希望更准确地估计人脸的旋转角度,可以尝试使用这些更高级的技术。
三、简单进行人脸检测并添加面具特效实现案例实现简单步骤
1、编写代码
2、运行效果

3、具体代码
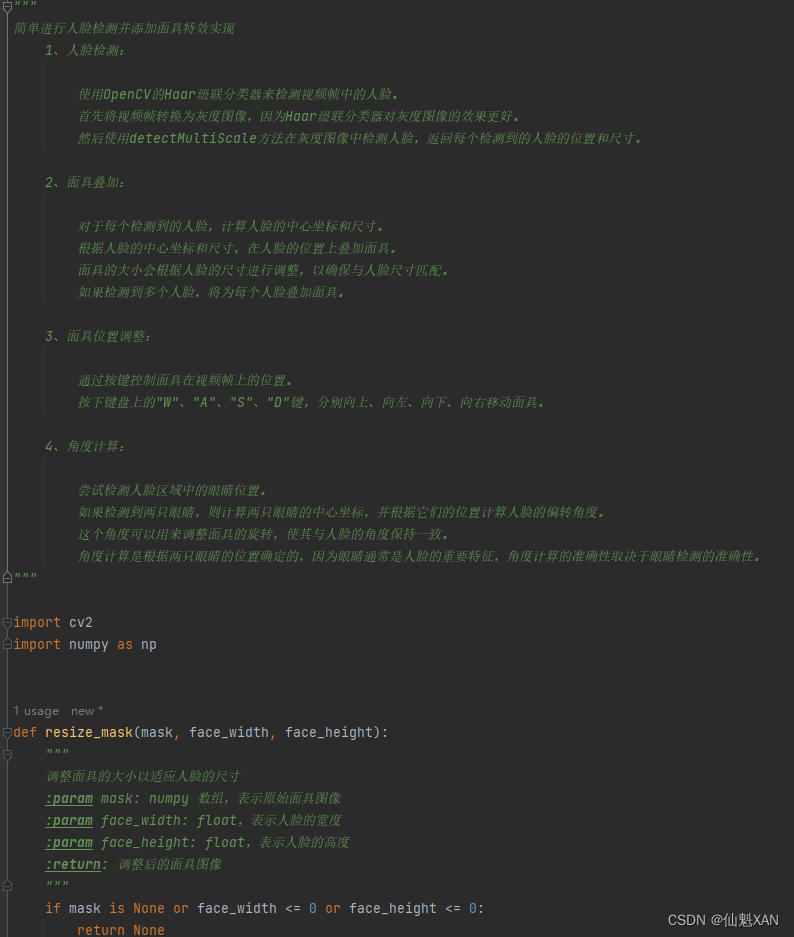
"""
简单进行人脸检测并添加面具特效实现
1、人脸检测:
使用OpenCV的Haar级联分类器来检测视频帧中的人脸。
首先将视频帧转换为灰度图像,因为Haar级联分类器对灰度图像的效果更好。
然后使用detectMultiScale方法在灰度图像中检测人脸,返回每个检测到的人脸的位置和尺寸。
2、面具叠加:
对于每个检测到的人脸,计算人脸的中心坐标和尺寸。
根据人脸的中心坐标和尺寸,在人脸的位置上叠加面具。
面具的大小会根据人脸的尺寸进行调整,以确保与人脸尺寸匹配。
如果检测到多个人脸,将为每个人脸叠加面具。
3、面具位置调整:
通过按键控制面具在视频帧上的位置。
按下键盘上的"W"、"A"、"S"、"D"键,分别向上、向左、向下、向右移动面具。
4、角度计算:
尝试检测人脸区域中的眼睛位置。
如果检测到两只眼睛,则计算两只眼睛的中心坐标,并根据它们的位置计算人脸的偏转角度。
这个角度可以用来调整面具的旋转,使其与人脸的角度保持一致。
角度计算是根据两只眼睛的位置确定的,因为眼睛通常是人脸的重要特征,角度计算的准确性取决于眼睛检测的准确性。
"""
import cv2
import numpy as np
def resize_mask(mask, face_width, face_height):
"""
调整面具的大小以适应人脸的尺寸
:param mask: numpy 数组,表示原始面具图像
:param face_width: float,表示人脸的宽度
:param face_height: float,表示人脸的高度
:return: 调整后的面具图像
"""
if mask is None or face_width <= 0 or face_height <= 0:
return None
mask_height, mask_width = mask.shape[:2]
mask = cv2.resize(mask, (int(face_width), int(face_height)))
return mask
def overlay_mask(mask, frame, face_x, face_y, face_width, face_height, offset_x=0, offset_y=0, angle=0):
"""
将面具叠加到视频帧上
:param mask: numpy 数组,表示面具图像
:param frame: numpy 数组,表示视频帧图像
:param face_x: float,表示人脸中心点的 x 坐标
:param face_y: float,表示人脸中心点的 y 坐标
:param face_width: float,表示人脸的宽度
:param face_height: float,表示人脸的高度
:param offset_x: 可选参数,表示在 x 方向上的偏移量,默认为0
:param offset_y: 可选参数,表示在 y 方向上的偏移量,默认为0
:param angle: 可选参数,表示旋转角度,默认为0
:return: 叠加了面具的视频帧图像
"""
if mask is None or frame is None or face_width <= 0 or face_height <= 0:
return None
# 获取面具的大小和位置
mask_height, mask_width = mask.shape[:2]
# 计算旋转后的面具图像
mask_center = (mask_width // 2, mask_height // 2)
mask_matrix = cv2.getRotationMatrix2D(mask_center, angle, 1)
rotated_mask = cv2.warpAffine(mask, mask_matrix, (mask_width, mask_height))
# 获取旋转后的面具覆盖的区域
mask_y = int(face_y - face_height / 2 + offset_y)
mask_y_end = int(mask_y + face_height)
mask_x = int(face_x - face_width / 2 + offset_x)
mask_x_end = int(mask_x + face_width)
# 确保旋转后的面具图像在视频帧内
mask_x_start = max(mask_x, 0)
mask_x_end_clip = min(mask_x_end, frame.shape[1])
mask_y_start = max(mask_y, 0)
mask_y_end_clip = min(mask_y_end, frame.shape[0])
mask_width_clip = mask_x_end_clip - mask_x_start
mask_height_clip = mask_y_end_clip - mask_y_start
mask_x_end_local = mask_width_clip + max(mask_x - mask_x_start, 0)
mask_y_end_local = mask_height_clip + max(mask_y - mask_y_start, 0)
mask_x_local = max(mask_x - mask_x_start, 0)
mask_y_local = max(mask_y - mask_y_start, 0)
# 调整面具大小
resized_mask = resize_mask(rotated_mask, mask_width_clip, mask_height_clip)
# 将面具叠加到视频帧上
for c in range(0, 3):
try:
frame[mask_y_start:mask_y_end_clip, mask_x_start:mask_x_end_clip, c] = \
resized_mask[mask_y_local:mask_y_end_local, mask_x_local:mask_x_end_local, c] * (
resized_mask[mask_y_local:mask_y_end_local, mask_x_local:mask_x_end_local, 3] / 255.0) + \
frame[mask_y_start:mask_y_end_clip, mask_x_start:mask_x_end_clip, c] * (
1.0 - resized_mask[mask_y_local:mask_y_end_local, mask_x_local:mask_x_end_local, 3] / 255.0)
except ValueError:
pass
return frame
def detect_faces(frame):
"""
检测视频帧中的人脸
:param frame: numpy 数组,表示视频帧图像
:return: 包含检测到的人脸信息的列表
"""
if frame is None:
return []
# 使用人脸检测器检测人脸
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
eye_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_eye.xml')
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30))
# 获取人脸区域中的眼睛位置
for (x, y, w, h) in faces:
roi_gray = gray[y:y+h, x:x+w]
eyes = eye_cascade.detectMultiScale(roi_gray)
if len(eyes) >= 2:
# 计算人脸的偏转角度
eye_centers = np.array([(x + ex + ew // 2, y + ey + eh // 2) for (ex, ey, ew, eh) in eyes])
angle = np.arctan2(eye_centers[1][1] - eye_centers[0][1], eye_centers[1][0] - eye_centers[0][0]) * 180 / np.pi
angle = np.clip(angle, -45, 45) # 将角度限制在[-45, 45]范围内
print("angle = " + str(angle))
return faces, angle
return faces, 0
def main():
# 加载面具图像
mask = cv2.imread('Images/Cat_FaceMask.png', cv2.IMREAD_UNCHANGED)
# 打开视频文件
cap = cv2.VideoCapture('Videos/GirlFace.mp4')
# 初始化面具位置偏移
offset_x = 0
offset_y = -65
while True:
# 读取一帧视频
ret, frame = cap.read()
if not ret:
break
# 检测人脸和角度
faces, angle = detect_faces(frame)
# 对每张人脸应用面具
for (x, y, w, h) in faces:
# 将面具叠加到人脸上
# frame = overlay_mask(mask, frame, x + w // 2, y + h // 2, w, h, offset_x, offset_y, angle) # 这里变化太大,与视频不太符合,暂时不用
frame = overlay_mask(mask, frame, x + w // 2, y + h // 2, w, h, offset_x, offset_y)
# 显示结果
cv2.imshow('Masked Faces', frame)
# 检测按键输入
key = cv2.waitKey(1)
if key == ord('q'): # 按 'q' 键退出
break
elif key == ord('w'): # 上移面具
offset_y -= 5
elif key == ord('s'): # 下移面具
offset_y += 5
elif key == ord('a'): # 左移面具
offset_x -= 5
elif key == ord('d'): # 右移面具
offset_x += 5
# 释放视频捕获对象
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
main()
四、注意事项
- 参数安全校验:
- 对于函数的输入参数进行了必要的安全校验,确保输入参数的有效性和合理性,以避免程序崩溃或出现意外错误。
- 面具位置调整:
- 面具的位置可以通过按键进行调整,但需要确保面具不会超出视频帧的范围,否则会出现图像溢出或越界的情况。
- 角度计算:
- 在计算人脸的偏转角度时,需要确保眼睛的检测是准确的,否则可能导致角度计算不准确。
- 此外,还对计算得到的角度进行了限制,确保角度范围在[-45, 45]内,以避免面具旋转过度。