你好,我是 shengjk1,多年大厂经验,努力构建 通俗易懂的、好玩的编程语言教程。 欢迎关注!你会有如下收益:
- 了解大厂经验
- 拥有和大厂相匹配的技术等
希望看什么,评论或者私信告诉我!
文章目录
- 一、 前言
- 二、准备工作
- 2.1 电脑
- 2.2 组件安装
- 三、 安装
- 3.1 下载源码
- 3.2 下载模型
- 3.3 python 依赖安装
- 3.4 将下载好的大模型转为量化GGML 格式
- 3.5 编译项目通过 exe 文件运行大模型
- 3.6 运行
- 3.6.1 普通的方式运行
- 3.6.2 交互方式运行
- 3.7 python 绑定
- 3.7.1 python 环境安装
- 3.7.2 pyton 访问
- 3.7 总结
- 四、其他
- 4.1 模型量化
- 4.2 如报错可参考
- 五、 参考网址
- 六、总结
一、 前言
在上一篇文章中window 安装大模型 chatglm-6b,可以运行效率很低,所以这一次我们安装 chatglm.cpp,github 上说这个是 C++实现的,可以在笔记本上实时回复用户问题,我们一起看一下能不能实时回复
二、准备工作
2.1 电脑
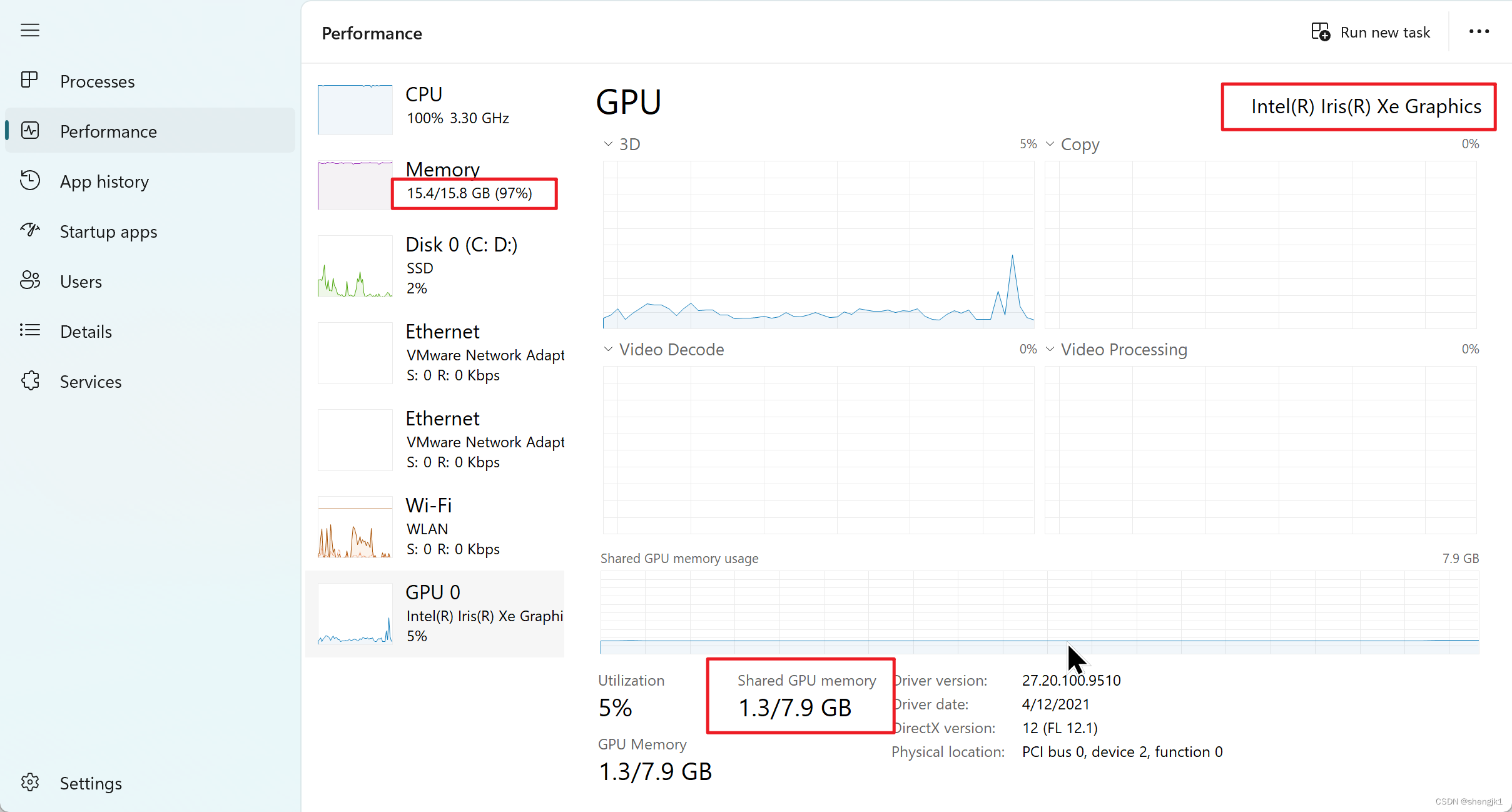
这是我工作使用的电脑配置,16G内存,Intel® 集成显卡。这里要吐槽一下,程序员千万不要使用 window,随便装点什么东西就很麻烦,用不了 mac 就用 linux,我这是公司电脑,后悔没早点装 unbantu 系统。
注意:这个电脑无法使用英伟达的GPU 具体参考 关于 AssertionError: Torch not compiled with CUDA enabled 问题
2.2 组件安装
VS studio 2022
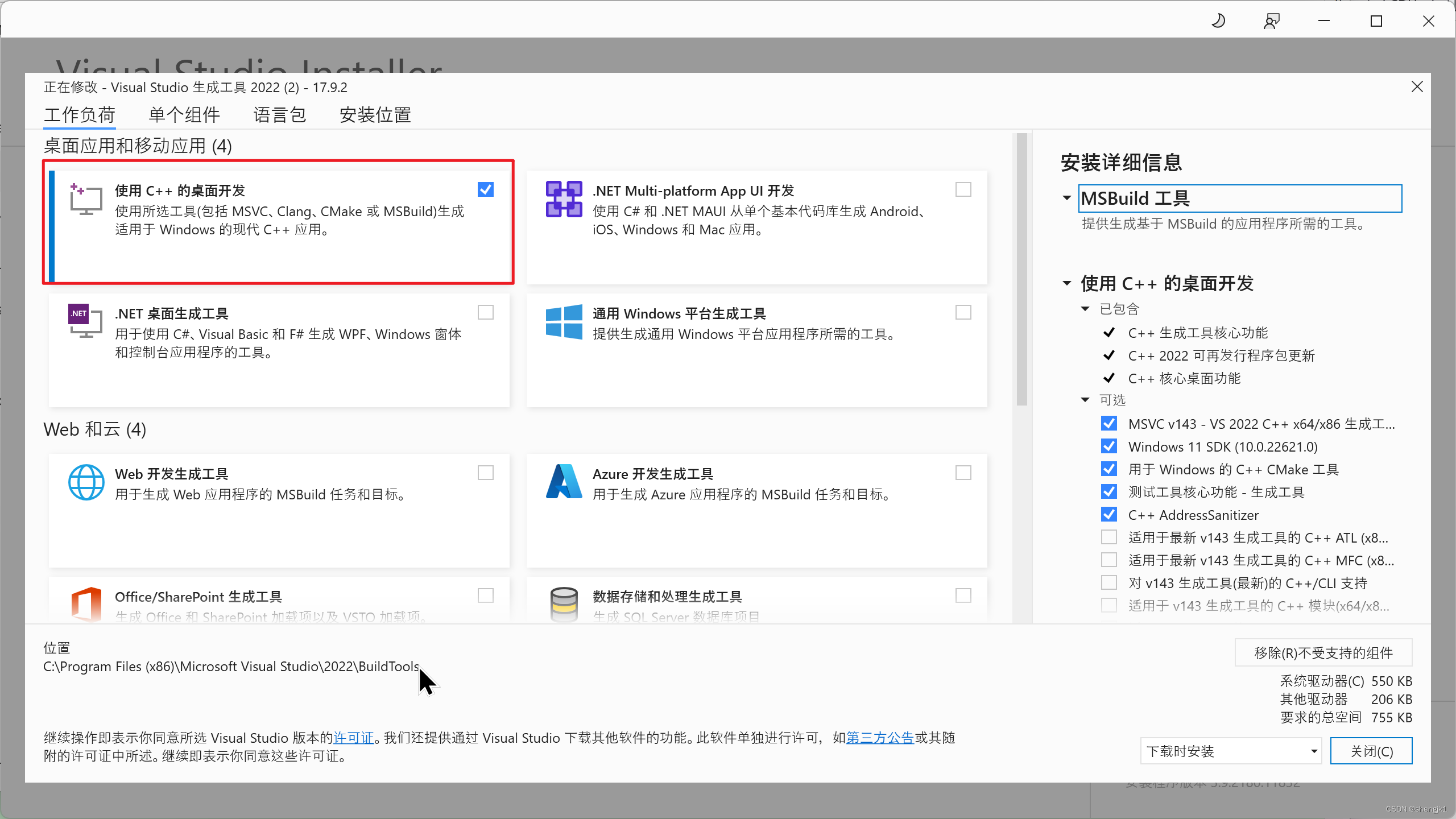
cmake
TDM-GCC,注意,安装的时候直接选择全部安装就好。安装完在cmd中运行”gcc -v”测试是否成功即可( 我的电脑需要重启后才能执行 gcc -v )
三、 安装
3.1 下载源码
git clone --recursive https://github.com/li-plus/chatglm.cpp.git && cd chatglm.cpp
3.2 下载模型
目前支持的模型:
ChatGLM-6B: THUDM/chatglm-6b, THUDM/chatglm-6b-int8, THUDM/chatglm-6b-int4
ChatGLM2-6B: THUDM/chatglm2-6b, THUDM/chatglm2-6b-int4
ChatGLM3-6B: THUDM/chatglm3-6b
CodeGeeX2: THUDM/codegeex2-6b, THUDM/codegeex2-6b-int4
Baichuan & Baichuan2: baichuan-inc/Baichuan-13B-Chat, baichuan-inc/Baichuan2-7B-Chat, baichuan-inc/Baichuan2-13B-Chat
这里以 THUDM/chatglm2-6b-int4 为例( 模型的量化版本,电脑配置比较高的可以试试 chatglm2-6b 或者 chatglm3-6b,毕竟在量化模型的基础上再次量化,效果会差很多),
chatglm2-6b-int4 清华源 下载模型,从huggingface下载配置文件。如果网速比较好的话,可以忽略清华源直接从 huggingface中下载,下载结束后,统一保存到
D:\LLM\chatglm2-6b-int4
3.3 python 依赖安装
python3 -m pip install -U pip
python3 -m pip install torch tabulate tqdm transformers accelerate sentencepiece
3.4 将下载好的大模型转为量化GGML 格式
python3 chatglm_cpp/convert.py -i D:\LLM\chatglm2-6b-int4 -t q4_0 -o chatglm2-6b-int4-ggml.bin
不同的量化格式,结果精度损失不一样,-t的可选项有
q4_0: 4-bit integer quantization with fp16 scales.
q4_1: 4-bit integer quantization with fp16 scales and minimum values.
q5_0: 5-bit integer quantization with fp16 scales.
q5_1: 5-bit integer quantization with fp16 scales and minimum values.
q8_0: 8-bit integer quantization with fp16 scales.
f16: half precision floating point weights without quantization.
f32: single precision floating point weights without quantization.
3.5 编译项目通过 exe 文件运行大模型
cmake -B build
cmake --build build -j --config Release
3.6 运行
3.6.1 普通的方式运行
D:\LLM\chatglm.cpp\build\bin\Release\main -m chatglm2-int4-ggml.bin -p 你好
注意编译后 main.exe 的位置在
D:\LLM\chatglm.cpp\build\bin\Release
我的模型 chatglm2-int4-ggml.bin 位置在
D:\LLM\chatglm.cpp

3.6.2 交互方式运行
D:\LLM\chatglm.cpp\build\bin\Release\main -m chatglm2-int4-ggml.bin -i
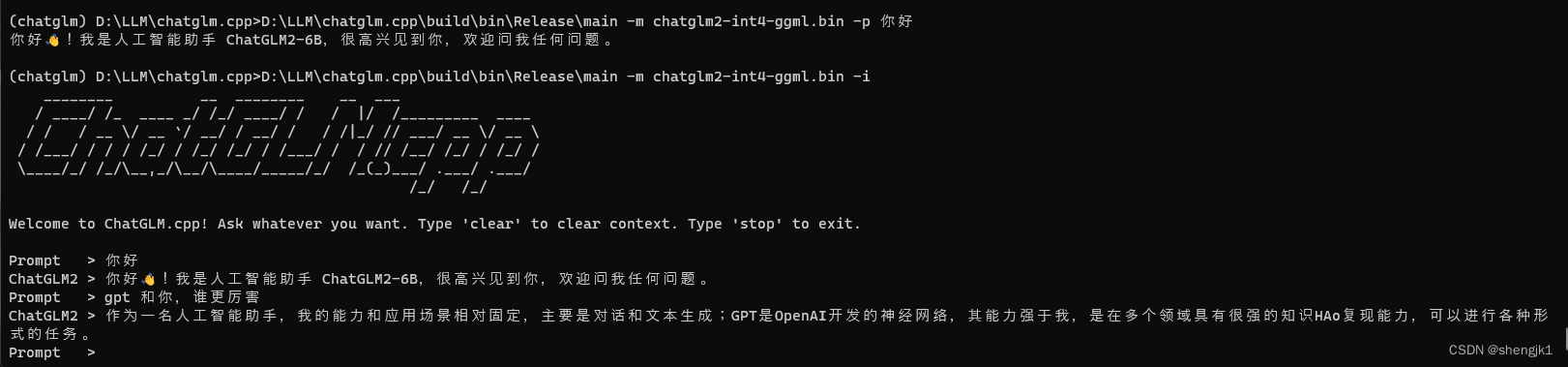
3.7 python 绑定
3.7.1 python 环境安装
pip install -U chatglm-cpp
3.7.2 pyton 访问
import chatglm_cpp
pipeline = chatglm_cpp.Pipeline("D:\LLM\chatglm.cpp\chatglm2-int4-ggml.bin")
print(pipeline.chat([chatglm_cpp.ChatMessage(role="user", content="你好")]))
至此就可以在本地愉快的玩耍啦
3.7 总结
chatglm.cpp 的效率比 chatglm效率要高很多,可以试试
四、其他
4.1 模型量化
模型量化是通过将模型的各项参数和结构等信息进行数字化处理,将复杂的模型转换为数学形式,以便计算机能够更快速、准确地处理和分析。这样可以使模型更易于实施、验证和优化,从而提高模型的有效性和可靠性。
好处:
- 提高计算效率:量化后的模型更容易实施和计算,能够更快速、准确地进行预测和分析。
- 方便验证和改进:通过量化可以更清晰地了解模型的结构和参数,方便验证模型的有效性和进行优化改进。
- 便于应用:量化后的模型可以更容易地应用于实际问题中,提供更为实用的解决方案。
坏处:
- 信息损失:在量化的过程中,可能会损失一些模型精细的特征和信息,导致模型的准确性和可靠性受到影响。
- 可解释性下降:量化后的模型可能会变得更为复杂和抽象,对模型的解释和理解可能会变得更加困难。
- 难度增加:如果模型本身就很复杂,那么对其进行量化的难度也会增加,可能需要更多的技术和资源来实现。
4.2 如报错可参考
window 安装大模型 chatglm-6b
五、 参考网址
chatglm.cpp
六、总结
本文详解介绍了 chatglm.cpp 安装过程

![[linux网络编程]UDP协议和TCP协议的使用](https://img-blog.csdnimg.cn/direct/3570e8b110374bacbde0e04828dd6848.png)