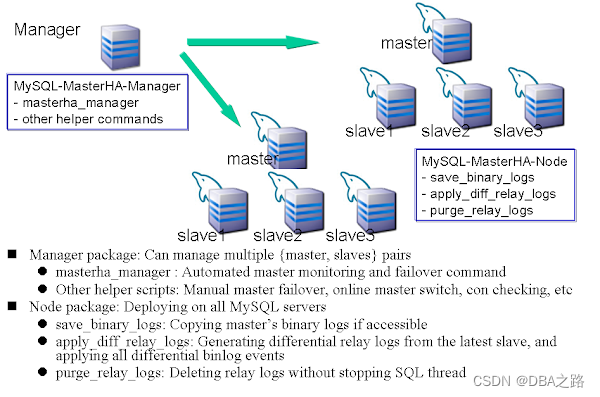
论文名称:《 A 2 A^2 A2-Nets: Double Attention Networks》
论文地址:https://arxiv.org/pdf/1810.11579.pdf
学习捕捉远距离关系对于图像/视频识别是基础性的。现有的CNN模型通常依靠增加深度来建模这些关系,这在很大程度上效率低下。在这项工作中,我们提出了“双重注意力块”,这是一种新颖的组件,它可以从输入图像/视频的整个时空空间聚合和传播有信息的全局特征,使得后续的卷积层可以高效地访问整个空间的特征。该组件设计了一个双重注意力机制的两个步骤,第一步通过二阶注意力池将整个空间的特征聚集到一个紧凑的集合中,第二步通过另一个注意力机制自适应地选择和分配特征到每个位置。所提出的双重注意力块易于采用,并可以方便地插入到现有的深度神经网络中。我们进行了大量的消融研究和实验证明其性能。在图像识别任务中,使用我们的双重注意力块装备的ResNet-50在ImageNet-1k数据集上胜过了更大的ResNet-152架构,参数数量减少了40%以上,FLOPs也减少了。在动作识别任务中,我们提出的模型在Kinetics和UCF-101数据集上取得了最先进的结果,并具有比最近的研究工作更高的效率。捕捉长距离关系是图像/视频识别的基础。现有的卷积神经网络 (CNN) 模型通常依赖于增加深度来建模这种关系,这种方法效率低下。在这项工作中,我们提出了 “双重注意力块”,这是一种新组件,它从输入图像/视频的整个时空中聚合和传播有用的全局特征,使后续的卷积层能够有效地访问整个空间的特征。该组件采用双重注意力机制,分两个步骤进行。第一步通过二阶注意力池化将整个空间的特征聚集到一个紧凑的集合中,第二步通过另一种注意力机制自适应地选择和分配特征到每个位置。所提出的双重注意力块易于使用,并且可以方便地插入现有的深度神经网络中。
我们在图像和视频识别任务上进行了广泛的消融研究和实验,以评估其性能。在图像识别任务中,装备了双重注意力块的 ResNet-50 在 ImageNet-1k 数据集上表现优于更大的 ResNet-152 架构,同时参数数量减少了超过40%,FLOPs 也更少。在动作识别任务中,我们的模型在 Kinetics 和 UCF-101 数据集上取得了最新的结果,效率显著高于近期的其他工作。
问题背景
在图像和视频识别领域,深度卷积神经网络(CNN)面临着有效捕获长距离关系的挑战。传统的CNN模型通常依赖增加网络深度来处理这些长距离关系,这会导致效率低下和计算成本增加。此外,局部感受野的局限性也可能导致信息传播不充分,从而影响网络的性能。因此,需要一种能够在保持低计算开销的同时有效捕获长距离关系的方法。
核心概念
本文提出了“双重注意力块”(Double Attention Block),也称为A2-Net。这是一种新的组件,能够从整个空间或时空中聚合和传播信息,帮助后续的卷积层更有效地访问全局特征。双重注意力块通过两步注意力机制实现其目标:第一步使用二阶注意力池化从整个空间中聚合特征,第二步通过另一个注意力机制自适应地选择和分配特征到每个位置。这种设计使得卷积层能够有效地感知整个空间,从而提高图像和视频识别的性能。
模块的操作步骤
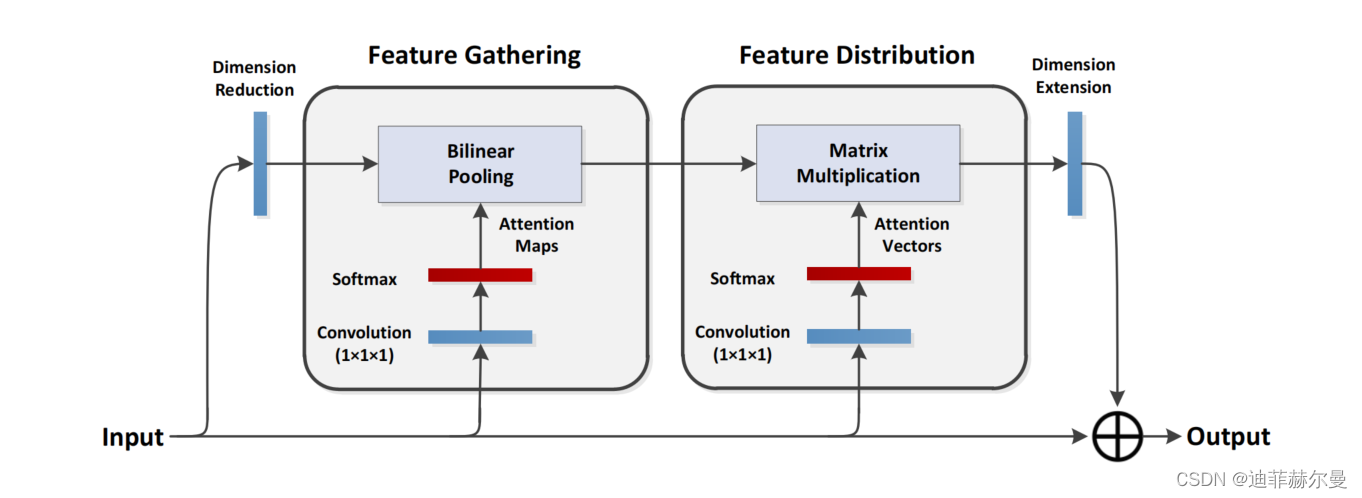
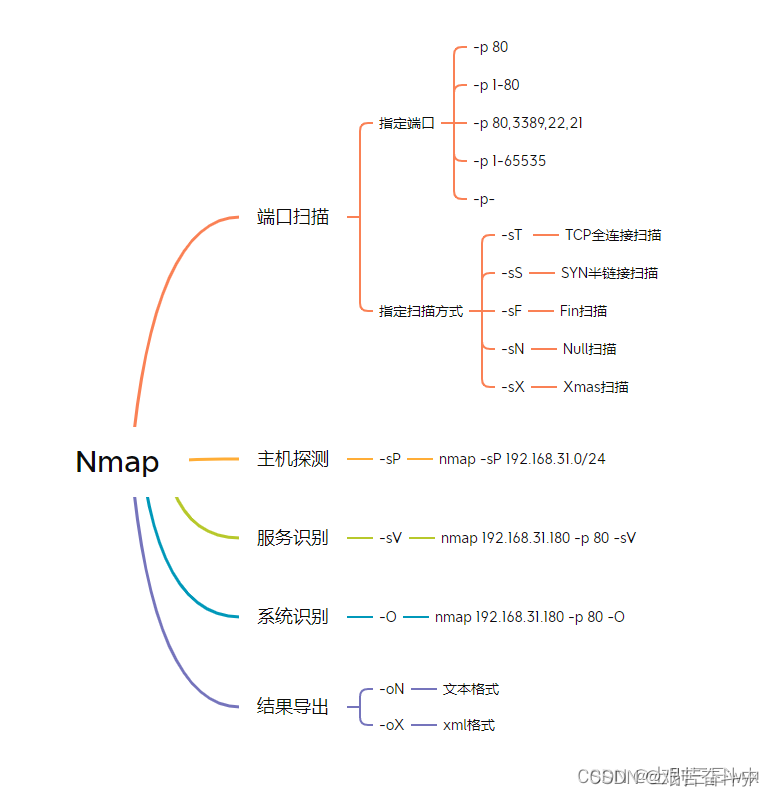
所提出的双重注意力块的计算图。所有卷积核的大小均为 1 × 1 × 1。我们将这个双重注意力块插入现有的卷积神经网络中,例如残差网络,以构成 A2-Net。
双重注意力块的操作步骤包括两个主要部分:特征聚合和特征分配。
- 在特征聚合部分,模块使用二阶注意力池化从整个空间中选择关键特征。与传统的平均池化或最大池化不同,二阶注意力池化能够捕获和保留更复杂的关系。
- 在特征分配部分,模块根据每个位置的局部特征自适应地分配特征,而不是像SENet那样将相同的全局特征分配到每个位置。这样,每个位置可以根据其需要接收不同的特征,从而增强整体性能。
文章贡献
本文的主要贡献在于提出了一种新的注意力机制,能够同时捕获长距离特征间的依赖关系,并以较低的计算和内存开销实现高效的特征分配。双重注意力块可以方便地插入现有的深度神经网络中,提高其性能。此外,通过在ImageNet-1k、Kinetics和UCF-101等数据集上的实验,作者证明了双重注意力块在图像和视频识别任务上的有效性。
实验结果与应用
在实验结果部分,本文通过对比不同网络架构、调整参数和测试各种场景,证明了双重注意力块在提高网络性能方面的有效性。在ImageNet-1k分类任务中,使用双重注意力块的ResNet-50超越了更大的ResNet-152,并显著降低了计算成本。在视频识别任务中,双重注意力块在Kinetics和UCF-101数据集上取得了最佳性能,表明其在不同视觉任务中的广泛适用性。
对未来工作的启示
双重注意力块的成功展示了通过高效注意力机制增强深度神经网络性能的潜力。未来的研究可以探索将双重注意力块与其他类型的神经网络结合,或将其用于其他任务,如自然语言处理和音频分析。此外,研究人员可以进一步优化这种机制,以提高其在移动设备和资源受限环境中的性能。
代码
import torch
from torch import nn
from torch.nn import init
from torch.nn import functional as F
class DoubleAttention(nn.Module):
def __init__(self, in_channels, c_m, c_n, reconstruct=True):
super().__init__()
self.in_channels = in_channels
self.reconstruct = reconstruct
self.c_m = c_m
self.c_n = c_n
self.convA = nn.Conv2d(in_channels, c_m, 1)
self.convB = nn.Conv2d(in_channels, c_n, 1)
self.convV = nn.Conv2d(in_channels, c_n, 1)
if self.reconstruct:
self.conv_reconstruct = nn.Conv2d(c_m, in_channels, kernel_size=1)
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode="fan_out")
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, h, w = x.shape
assert c == self.in_channels
A = self.convA(x) # b,c_m,h,w
B = self.convB(x) # b,c_n,h,w
V = self.convV(x) # b,c_n,h,w
tmpA = A.view(b, self.c_m, -1)
attention_maps = F.softmax(B.view(b, self.c_n, -1), dim=-1)
attention_vectors = F.softmax(V.view(b, self.c_n, -1), dim=-1)
# step 1: feature gating
global_descriptors = torch.bmm(
tmpA, attention_maps.permute(0, 2, 1)
) # b.c_m,c_n
# step 2: feature distribution
tmpZ = global_descriptors.matmul(attention_vectors) # b,c_m,h*w
tmpZ = tmpZ.view(b, self.c_m, h, w) # b,c_m,h,w
if self.reconstruct:
tmpZ = self.conv_reconstruct(tmpZ)
return tmpZ
if __name__ == "__main__":
input = torch.randn(64, 256, 8, 8)
model = DoubleAttention(in_channels=256, c_m=128, c_n=128, reconstruct=True)
output = model(input)
print(output.shape)